
前言
天下武功,唯快不破。在侦探的世界中,破案效率永远是衡量一名侦探能力的不二法门。作为推理界冉冉升起的新星,大侦探福尔摩斯·K凭借着冷静的头脑、严谨的思维,为我们展现了一场场华丽而热血的推理盛宴。
接下来,我们不仅仅是看客,还将追随福尔摩斯·K的脚步,体验一场身临其境的冒险。一起寻访产生数据库性能问题的根源,深度探索和解析数据库性能问题:
妙用调优“四剑客”,轻松完成金仓数据库KingbaseES的性能调优!
案情接入,问题初露端倪
案发时间
2022.10.26 晴
案发地点
X客户项目现场
案件描述
业务系统上线前出现性能问题,导致业务卡顿情况严重。
案情接入
由于生产环境不可随意改动,在现场支援的华生医生配置了与生产环境一致的测试环境,来进行初步的诊断。后续的性能优化方案也会先于测试环境验证,待性能达标之后,方可在生产环境上线。
_ | 生产环境 | 测试环境 |
环境 | Kylin Linux Advanced Server V10 128个CPU核心 754 GB内存 64 TB磁盘 | Kylin Linux Advanced Server V10 128个CPU核心 754 GB内存 64 TB磁盘 |
根据华生医生跟X客户的沟通,多个应用场景使用连接池连接到KingbaseES服务器,300并发,其中一个业务场景慢,吞吐量上不来,平均一个业务请求超过85秒。华生医生要在当日内完成对该业务场景的性能优化,使X客户的平均业务响应时间进入10秒,以保证业务系统按时上线。但在有限的时间内快速优化业务场景的性能,实非华生医生所长。于是,大侦探福尔摩斯·K便被召唤闪亮登场。
抽丝剥茧,探索服务器环境
魅影重重的故事已被华生医生初步解开谜底,然而,如何让“犯罪分子”——不正确的配置参数或低性能的SQL语句伏诛,依旧是一场酣畅淋漓的侦探冒险。
就这样,福尔摩斯·K携金仓数据库KingbaseES性能优化四剑客KWR、KSH、KDDM和KWR Diff踏上了性能调优之旅。
KWR:KES自动负载信息库(Automatic Workload Repertories),每小时自动采集性能指标生成快照,建立数据库时间模型、IO模型、等待事件、TOP SQL和操作系统统计等性能指标,为数据库性能调优提供指导。
KSH:KES活跃会话历史库(Active Session History),每秒自动采样活跃会话的等待事件、SQL语句、阻塞等会话信息,提供针对某个历史时间点的性能问题分析。
KDDM:KES自动诊断和建议(Automatic Database Diagnostic Monitor),基于KWR快照和数据库时间模型,给出内存、网络、IO和SQL性能优化建议。
KWR Diff:KWR差异报告,通过比较2段时间内KWR性能指标的差异,发现性能变化的趋势。
在和现场的华生简单对接后,福尔摩斯·K首先要排查一下服务器主机环境,并了解KES在该业务场景下的整体性能表现,确定性能优化目标。这通过KWR十分容易就能获得。
Step.1
产生KWR报告分析主机环境
配置KWR开关并让配置参数全局生效,迅速开启压测模拟约20分钟,生成KWR快照及报告:
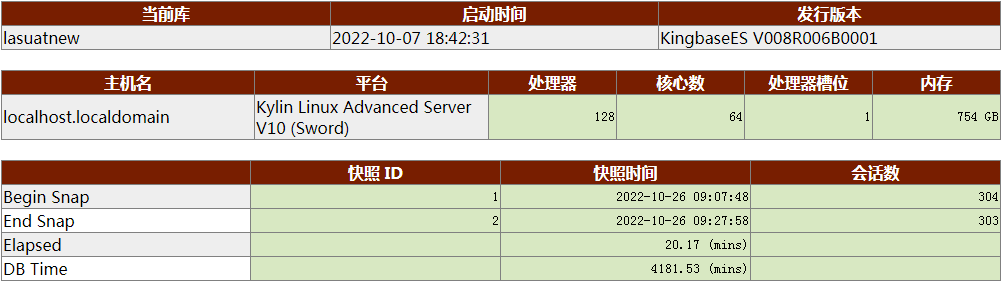
KES版本信息,主机CPU能力、内存容量、OS基本信息,客户端连接数跟华生描述的基本一致。
福尔摩斯·K通过KWR的主机统计报告,可排查主机环境的CPU、IO、内存、网络性能等性能指标是否存在问题:

主机CPU报告显示,用户态CPU占用92.50%,空闲仅6.67%,属于业务非常繁忙的情况。当然,如果CPU繁忙全部由KES服务器所造成,那就没有大的影响,并且说明X客户之前应该进行过一定程度的性能调优。
这一点通过负载分析报告里面的DB Time和DB CPU值很容易来判断:

每秒DB CPU为190.01,超过了主机的CPU核心数,对于300个并发客户端连接的负载来说正常。也说明绝大部分CPU负载都在KES服务器上,跟主机上的其他进程无关。
继续查看主机IO报告:
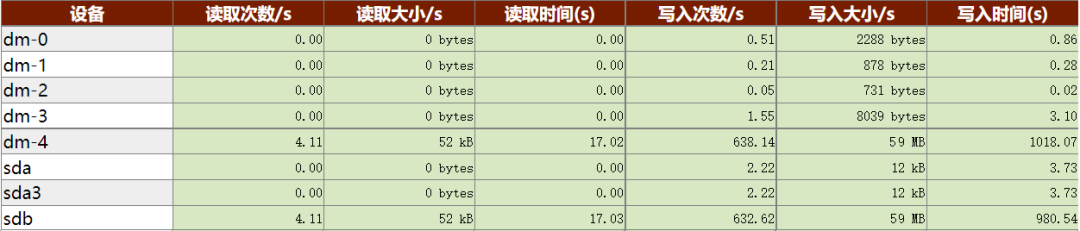
KWR报告显示,sdb磁盘每秒有59 MB的写操作,福尔摩斯·K熟练地在KSQL里输入了几条SQL查询,确认了KES数据目录正位于该磁盘上。再看其他磁盘均没有明显的IO操作。第一个线索隐隐约约出现了。但是这59 MB的磁盘IO到底来自哪里呢?
福尔摩斯·K暂时压下心头的疑云,留待后续进一步分析。
继续查看主机内存报告和主机网络报告,报告显示剩余内存充足(449 GB),网络也未发现异常指标。

条分缕析,拆解数据库实例
探索主机环境后,福尔摩斯·K暂时搁置了对磁盘IO问题的疑问,开始分析数据库实例。数据库实例重点关注负载分析报告、实例效率百分比报告、Top 10前台等待事件报告、时间模型统计报告等,并需要同时关注IO方面部分指标。
Step.2
分析前台等待事件
根据以往的经验,数据库产生性能问题时,往往会伴随着某几个等待事件较高的现象。因此,福尔摩斯·K在分析完操作系统环境后,优先查看了前台等待事件分类报告:

前台等待几乎都是IO等待,占数据库时间8.36 %,它们主要包括哪些等待事件,通过Top 10前台等待事件报告很容易查到:

报告显示这8.36%的IO等待事件,主要来自BufFileWrite(5.84%)和BufFileRead(2.52%),其他等待事件可以忽略。
福尔摩斯·K现在得到了第二条线索:2个跟IO相关的等待事件。
但是这2个等待事件的存在是否合理呢?目前还不能断然下结论,需要继续分析时间模型和数据库实例IO组成。
Step.3
分析KES时间模型
KES时间模型是性能分析不可或缺的关键指标,通过对数据库时间模型的拆解,能够知道数据的时间花费到哪里去了,也容易定位像软解析、硬解析等问题。
KES的数据库时间模型公式:DB Time = DB CPU + Foreground Wait Time,即:
数据库时间 = 数据库CPU时间 + 前台(客户端会话)等待时间,
前台等待时间 = 前台IO时间 + 前台网络读写时间 + 锁等待时间 + ...
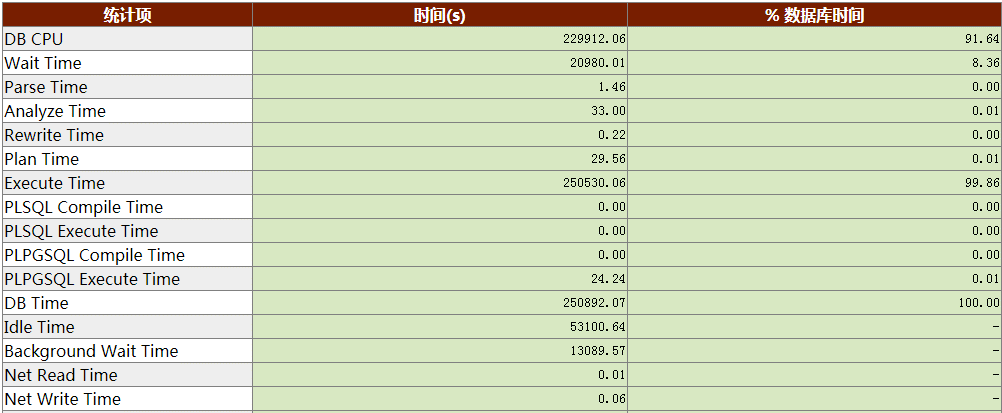
时间模型统计报告显示花费时间最多的是DB CPU,为91.64%,其次是前台等待时间,为8.36 %,没有发现SQL解析、执行计划缓存、网络读写等问题,因此,福尔摩斯·K只能按照常规从负载报告开始分析,从数据库实例全局了解一下可能的瓶颈点。
Step.4
分析KES负载
负载分析报告里提供了大量经过提炼的指标,包括数据库时间、前台等待事件、实例IO、解析计划执行次数、事务、元组、死锁、登录登出等。其中每秒那列的统计值很直观。
比如:每秒Transactions,等价于TPS,每秒Execute Calls,等价于QPS。
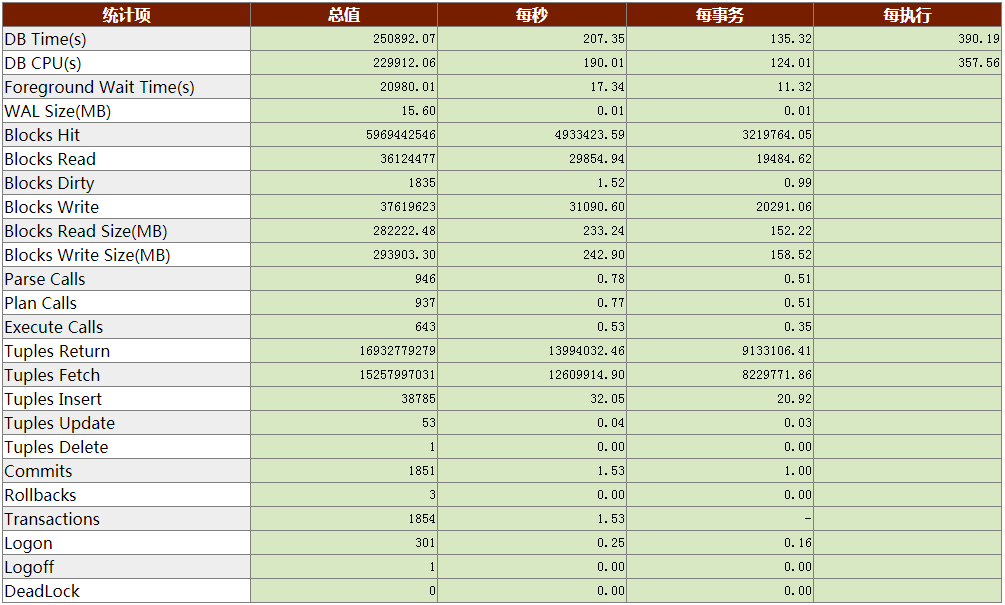
报告显示,数据库时间正常、前台等待事件较高,每秒17.34。
WAL日志(WAL Size)读写很低,难道是没有开WAL日志吗?福尔摩斯·K和华生带着疑惑跟客户确认了该业务场景的数据不生产WAL日志。
数据页(Block Read/Write Size)的读写较高,每秒读233.24 MB,每秒写242.90 MB,似乎存在点问题。这令福尔摩斯·K想起主机磁盘IO每秒59 MB的写操作,两个指标的异常让他渐渐摸到了问题的脉络。接下来需要分析一下该指标的合理性。
Step.5
多维度分析数据块读写的合理性
查看SQL类型统计报告,能够知道SQL负载特征:SELECT语句占了100%。没有增删改查SQL语句。

这不合情理!虽然查询语句也可能会读写磁盘,但是每秒50M+的读和写,引起了福尔摩斯·K深深的怀疑。报告显示读和写的数量相当,难道是数据页缓冲区不够?
检查实例效率百分比报告中的Buffer Hit(缓冲命中率)为100%。说明Shared buffer设置是足够的,几乎全部的数据页都能在数据缓冲区读到。

那么另一种可能就是临时表的读写了。但业务系统开发人员却反馈,该业务场景里几乎没有使用大的临时表。福尔摩斯·K第一次陷入了苦思:这50 MB的IO读写到底来自数据库哪里呢?
华生端来了2杯浓浓的咖啡,福尔摩斯喝了一口。突然间,灵光一闪,IO分析报告还没有看,虽然它并非一棵IO分解树,但是它也提供了共享块、本地块、临时块的IO统计等信息:

找到了!数据库中存在233.24 MB/s的读临时块,242.88 MB/s的写临时块。与负载分析报告里的IO读写一致,但是高于主机IO里的59 MB/s读写,这也是合理的,说明操作系统缓存了一部分KES发出的写盘请求。进一步分析,临时块不是临时表的读写,而是SQL语句在排序、Hash连接的时候使用的临时使用的磁盘空间。
检查快照期间参数配置报告,果然,搜索到work_mem为10240 kB,这是KES的默认配置。对于普通的查询是足够的,但对于存在大量复杂Hash join或者排序的SQL就会有所不足。

现在再回顾一下Step2里的两个前台等待事件:
BufFileWrite:等待3751万次,数据库时间占比:5.85 %。
BufFileRead:等待3534万次,数据库时间占比:2.52 %。
这两个等待事件一般意味着KES的work_mem不够,导致写临时磁盘了,并发越高性能影响越大。
内心的疑虑终于解开了!福尔摩斯·K也得到了第三条线索:客户端会话配置的work_mem不够。后面需要找到跟work_mem性能问题关联的SQL。
拨云见日,快速定位问题
在云山雾罩的迷案中抽丝剥茧,以严密推理拆解分析;在千丝万缕的疑难中拨云见日,以逻辑思维快速定位问题。
Step.6
定位问题SQL
福尔摩斯·K主要从TOP SQL报告中查看问题SQL,确认其中是否有Hash和排序方面的操作。TOP SQL报告由一系列按照执行时间、IO时间、返回元组数等排序的子报告组成,能按照多个维度检查资源消耗高的SQL语句的执行情况。
通过TOP SQL统计的按数据库时间排序的SQL语句报告,即可找出消耗数据库时间最多的SQL:

排在前两位的SQL分别占了76.36 %和24.64 %的数据时间,平均执行时间63.62秒和23.44秒,等待时间占比为8.67 %和7.52 %,应该就是BufFileRead和BufFileWrite两个等待事件。
为了验证这一点,福尔摩斯·K基于刚才的KWR快照生成了一份KDDM报告。不仅看到了等待事件,还看到了跟他们关联的SQL语句,确实是那两个执行时间长的SQL:

经过与X客户的研发人员沟通,这两条复杂SQL语句(主要是第一条SQL,第二条SQL为非关键SQL可以不关注)之前仅需要不到30秒左右就能执行完成,最近感觉越来越慢,有时候执行会超过2到3分钟。看来它就是问题SQL了,优化它是重中之重。
福尔摩斯·K从完整SQL列表报告里,很快找到了对应的SQL,生成的执行计划十分复杂,果然发现了里面存在不少Hash Join以及外部排序(external merge Disk),平均使用磁盘空间在32 MB左右,远远大于当前设置的10 MB。
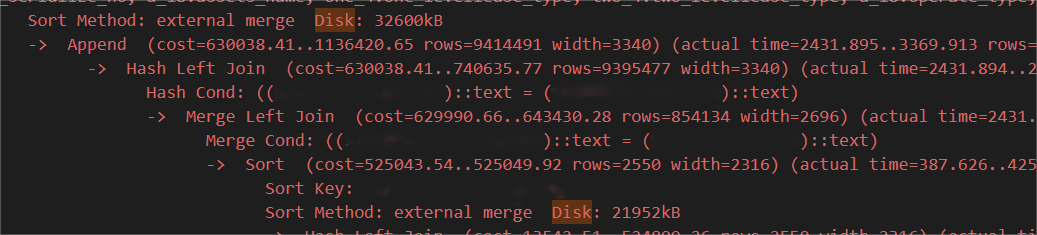
此时,性能瓶颈已经非常明确,即客户端会话进程的work_mem太小,导致了大量的磁盘排序操作。
Step.7
应用work_mem优化
将当前会话进程的work_mem设置为32 MB后,再观察问题SQL语句的执行计划,外部磁盘排序已经看不到了。然而,work_mem的修改会对每一个客户端会话进程都生效,不能设置过大,否则容易引起主机内存不够。这个问题却难不倒福尔摩斯·K,他伸了一个懒腰,大脑里飞快的计算着:300个会话,每个会话32 MB,一共需要9.375 GB内存,以极限情况1200个会话计算,最多需要37.5 GB内存。在可以接受范围之内。

福尔摩斯·K将数据库实例的work_mem参数配置成32 MB,重启服务器,跑性能负载,创建KWR快照并生成报告,KES实例IO中的临时文件读写降低到0.5 MB/s降低到0.02 %,DB CPU提升到 99.97%,时间模型等其他性能指标也无明显瓶颈。虽然没有完全消灭磁盘排序操作,但是现在的影响几乎可以不关注了。

两个执行时间最长的SQL语句的平均执行时间降到43.94秒和7.71秒:

站在一旁的华生对福尔摩斯·K佩服不已,心里想:待项目结束后,一定好好请教福尔摩斯·K,学个一招半招,再把KWR工具好好实践一下!
措置裕如,轻松调优SQL
福尔摩斯·K通过分析问题SQL的执行计划时发现了一个连接顺序的问题,还有一个优化器估算返回行数不准的问题,通过Hint轻松搞定,毕竟SQL优化是他最擅长的。
慢SQL的平均执行时间进一步优化到35.27秒。
Step.8
使用索引建议
剩下的优化空间在哪里呢?福尔摩斯·K又一次陷入了思考,刚才看KDDM报告并没有给出其他重要的建议,甚至连索引建议也没有,要是通过手工一个一个地分析表和索引估计一天分析不完......等等,刚才好像没有开索引建议开关!
打开索引建议开关后,重新压测,生成KDDM报告。果然,索引建议赫然在目:

按照KDDM的索引建议提示,和X客户的开发人员做了一个简单沟通,该索引原来是存在的,后来他们批量更新数据的时候,临时把索引删除后忘记加回来了。给目标表创建索引后,性能进一步提升到7.23秒。经过几次验证,客户应用场景平均响应降低到8.51秒,优化任务完成。
探本溯源,再会调优"四剑客"
在和客户确认系统性能指标达到预期,交付任务之后,华生拿来了小本本,热情地请教起福尔摩斯·K来:
华生:我之前也听说过KES的KWR、KSH、KDDM和KWR Diff调优组件,但平时用得少只会用KSH来看等待事件和它们关联的SQL语句,没想到KWR居然提供了那么多的性能指标和模型,而且使用它们调优确实和简单和直接。尤其是KDDM,能够直接定位问题并给出建议,太酷了!
福尔摩斯·K:是的,华生。有了高度集成化的KWR、KSH、KDDM、KWR Diff之后,在开始SQL优化之前几乎都可以用他们来先做数据库实例调优。这会节省DBA大量查询各种统计表和数据库日志的时间,你看我这次调优,基本没有查询它们。
华生:是的,那这些调优组件之间有啥区别和联系呢?
福尔摩斯·K:我这有一个总结表,你可以参考。
调优组件 | 使用场景 | 重点关注内容 |
KWR | 某一时间段持续性能问题分析 | 数据库负载、时间模型、等待事件等 |
KSH | 某一时刻突发性能问题分析 | 活跃会话的等待事件等 |
KDDM | 无需人工分析,直接给出调优建议 | 给出的各种建议 |
KWR Diff | 性能基准比较,或随时间变化的性能问题分析 | 同KWR |
这次调优没有使用到KSH,是因为不适合这次X客户的这种长周期性能问题场景。还有就是KWR Diff报告也很有用,调优前后产生一份KWR Diff报告,观察前后性能指标的差异,这对提升调优水平有很大帮助。
华生:总结得太好了!我要向我们组的小伙伴推广调优“四剑客”。

供稿:产品研发中心
编辑:四喜
校对:日尧
