https://zhuanlan.zhihu.com/p/401910162复制
原创:蒋院波
导语:本文从进程状态,进程启动方式,网络io多路复用纬度等方面知识,分享解决系统高负载低利用率的案例
前言:
趣头条SRE团队,从服务生命周期管理、混沌工程、业务核心链路治理、应急预案、服务治理(部署标准化、微服务化、统一研发框架、限流降级熔断),监控预警治理(黄金指标)入手,不断提升系统稳定率,完成符合标准化的服务上线99.99%可用性承诺SLA。
SRE除了是最好的业务partner,对运维生产环境遇到的疑难杂症的分析解决,是快速提升自身技术的良方妙药,下面是对一则系统高负载问题的处理过程总结和分享,希望能为有类似问题场景解决提供一种思路。
案例分享:
让我们先回顾一些OS基本知识:
(一)进程状态(man ps的解释直译)
PROCESS STATE CODES
Here are the different values that the s, stat and state output specifiers
(header "STAT" or "S") will display to describe the state of a process:
D uninterruptible sleep (usually IO) #不可中断睡眠 不接受任何信号,因此kill对它无效,一般是磁盘io,网络io读写时出现
R running or runnable (on run queue) #可运行状态或者运行中,可运行状态表明进程所需要的资源准备就绪,待内核调度
S interruptible sleep (waiting for an event to complete) #可中断睡眠,等待某事件到来而进入睡眠状态
T stopped by job control signal #进程暂停状态 平常按下的ctrl+z,实际上是给进程发了SIGTSTP 信号 (kill -l可查看系统所有的信号量)
t stopped by debugger during the tracing #进程被ltrace、strace attach后就是这种状态
W paging (not valid since the 2.6.xx kernel) #没有用了
X dead (should never be seen) #进程退出时的状态
Z defunct ("zombie") process, terminated but not reaped by its parent #进程退出后父进程没有正常回收,俗称僵尸进程复制我们平常top,ps看到最多的应该是S,R 这2个,Z和D应该很少见(因为io一般在很短的时间内完成),但今天的案例就和D相关;僵尸进程产生的原因是,子进程在退出过程中,按步退回资源后,就会进入Z状态,同时会给父进程发一个信号SIGCHLD,通知父进程来回收子进程,正常情况父进程会通过waitpid函数来捕捉,但如果父进程如果没有接收处理,就会变成Z状态
(二)进程启动的两种方式
fork: 子进程复制父进程所有的资源包括堆栈段、数据段,代码段(实际上是copy on write写时才复制), 子进程结构体(task_struct)除了pid,ppid,其余基本和父进程的结构体一致,默认情况下子进程会继承父进程所有打开的文件描述符fd(这是本文后面问题的关键之一),代码会从fork后那一行开始执行
exec: 在当前的shell环境中执行程序启动,新的可执行程序的代码被加载到当前进程的虚拟地址空间,因此数据段、代码段、堆栈段全部被覆盖,但pid保持不变,fd也默认被新进程继承
感兴趣的同学可以研究linux的内外命令,Linux的内建命令都使用exec方式(具体的内建命令可以用man exec查 或者type cmd确认),外部命令基本是fork+exec方式来启动进程
(三)cpu利用率和load average关系
现代OS基本都是多任务多用户操作系统,在我们人类看来是多个程序并行在运行,实际上在计算机硬件内部是并发执行,在某一个cpu核心上的多个任务实际是分时分片轮流执行,1s内切分成多片给各个进程使用(具体的分片配置是在内核编译阶段完成,可以使用grep CONFIG_HZ /boot/config-$(uname -r)命令查看当前内核时钟中断的频率),例如CONFIG_HZ=1000,即是1ms中断一次,每个进程至多跑出1ms后就要被动退出cpu,等待下一次调度。
cpu利用率反应的就是进程一段时间内占用cpu的比率。
这里多提一下,时钟中断的频率对进程有着非常大的影响,频率越小,分片就越大,进程所得的时间就越多,吞吐量自然就越大,频率越大,分片越小,时钟中断越频繁,响应任务就更快,因此业务对实时性要求高就适用高频率,如网络收发包程序,业务对吞吐量高就适用低频率,如计算型程序。
而负载反应的是在一段时间内 CPU正在处理以及等待 CPU处理的进程数、不可中断状态的任务之和的统计信息。
一般情况下:
cpu利用率高,负载会高;反过来不一定成立,也就是负载高,cpu利用率不一定高(下文的case就是这样)
当cpu运行队列数+等待运行+D进程 >= cpu核心数时,系统基本可以认为是满负载,超负载状态了,系统是一种不健康的状态,这种状态出现可能是cpu处理能力不足,也可能因为等待IO引起的
(四)网络IO(这里只讲同步IO)
一般网络编程中有三种网络模型,accept,select/poll,epoll
accept只能监听一个socket fd,因此当网络包量大时,效率非常低下;
select/poll可同时监听多个socket fd,提高了io读写能力,但因使用的主动轮询机制,所以效率也不高;
epoll可同时监听多个socket fd,同时使用了事件通知机制,有消息时立即处理,无消息时阻塞直到超时,nginx高性能的网络就是使用这种模型
好了,上面说了这么多,现在开始正式分享解决系统高负载过程:
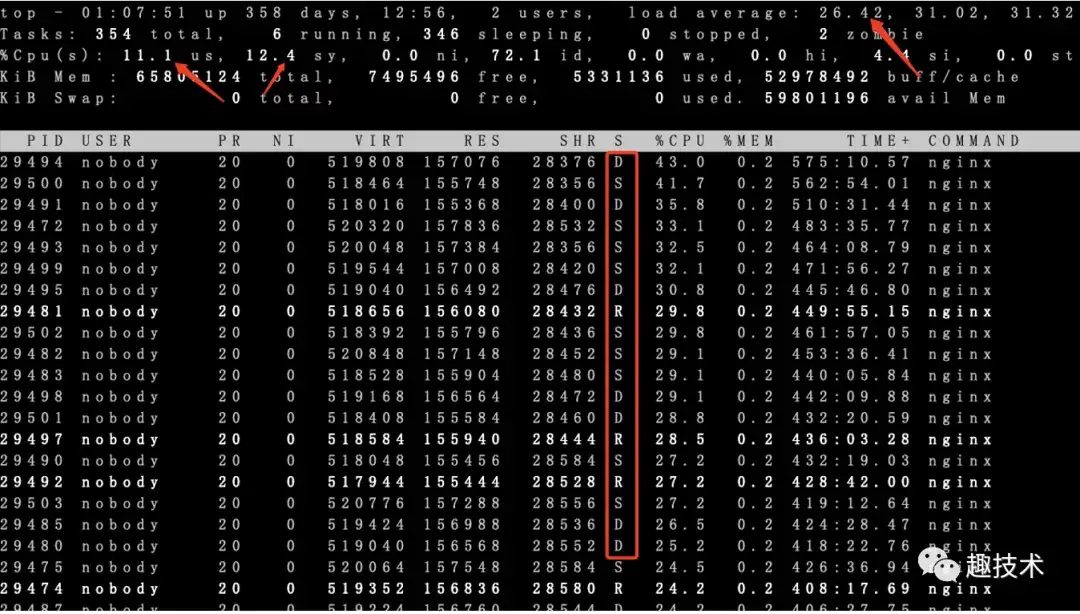
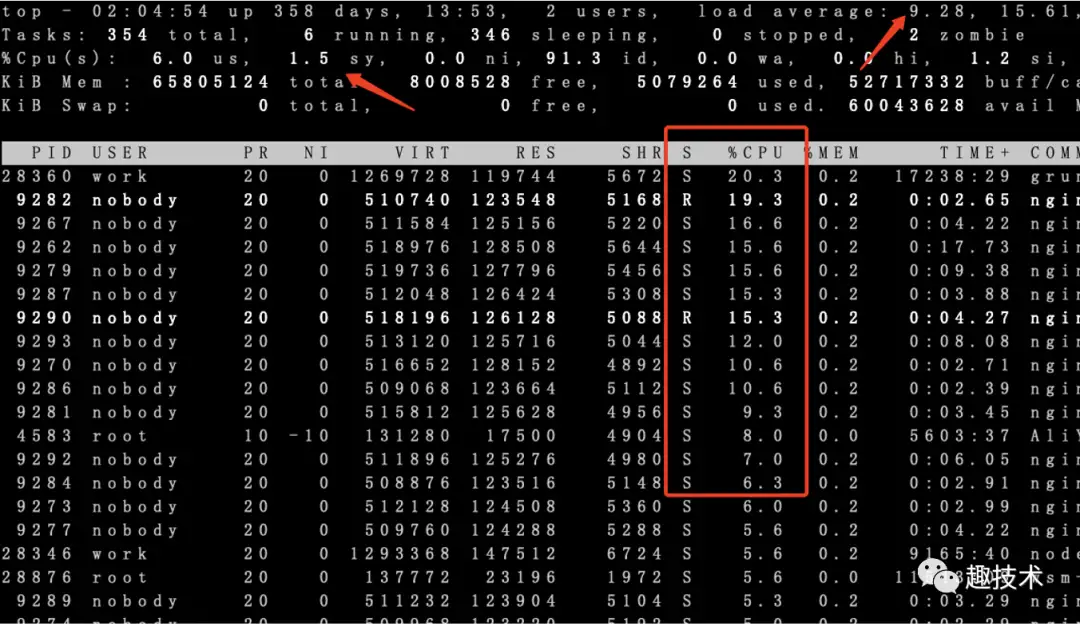
我们有一台nginx接入网关(演练环境)告警显示load比较高,上机器top看cpu利用率不高,但load average已经达到满负载,32核心的机器一分钟负载在30左右,同时可以看到nginx 32个worker 绝大部分处于D状态
一般情况下cpu相关的问题,使用排障利器strace, 使用strace -C -T -ttt -p pid -o strac.log可以既生成系统调用的统计信息,还能观察进程所有的调用过程
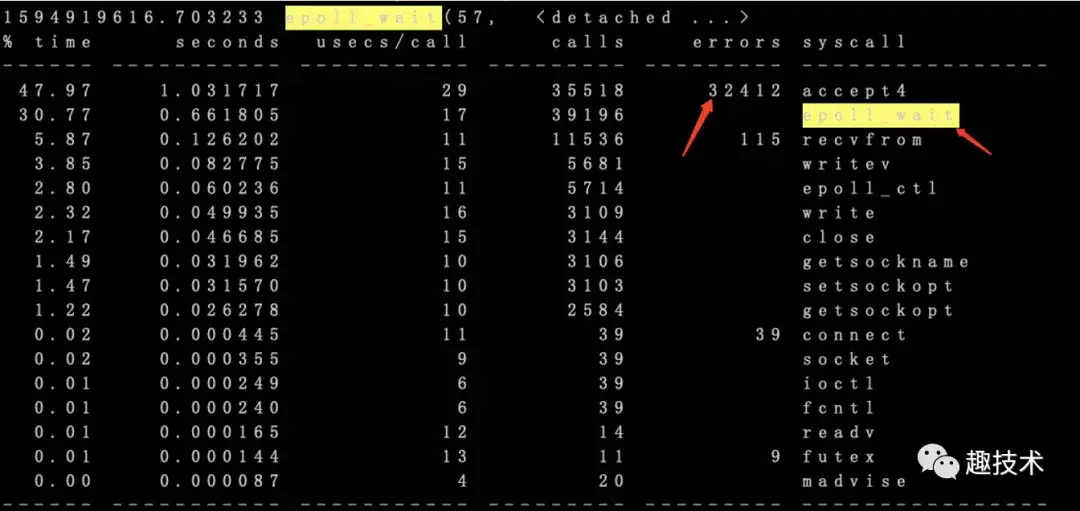
从统计信息有一个非常大的疑点,35518次的accept调用,居然有32412次返回失败,再去具体的跟踪记录看看过程:
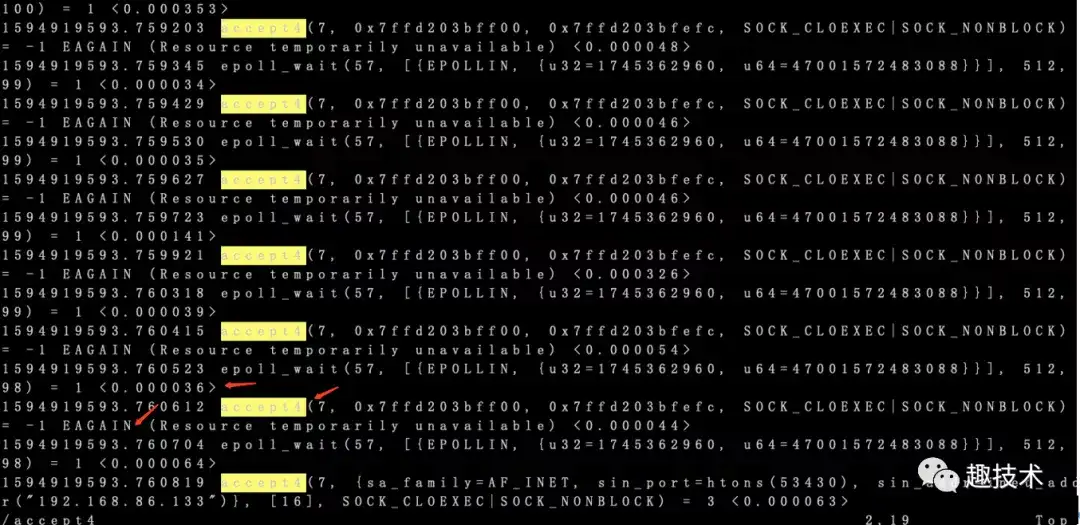
貌似每次epoll_wait阻塞一段时间后,有新的accept事件到来,但始终又读不到数据,这种情况就很像传说中的惊群效应:
所有的工作进程都在等待一个socket,当socket客户端连接时,所有工作线程都被唤醒,但最终有且仅有一个工作线程去处理该连接,其他进程又要进入睡眠状态。
这种频繁的睡眠和唤醒的操作带来的影响就是 cpu要不断地进行进程上下文切换(保存寄存器,压栈,出栈等),十分地消耗cpu资源,同样的请求量大小,线上生产环境和此机的数据对比如下:
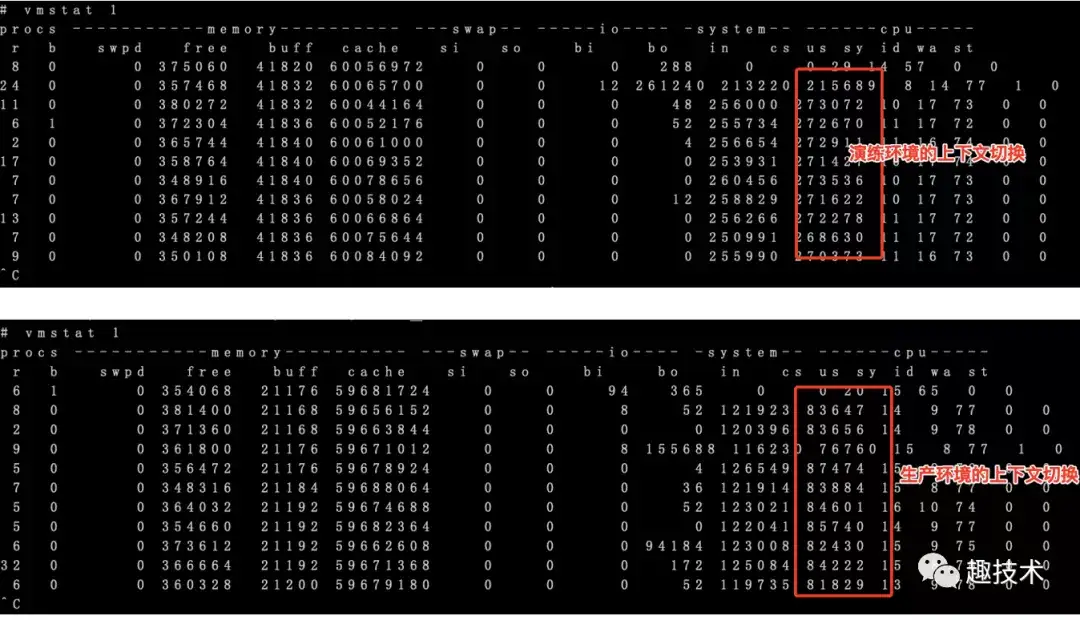
演练的上下文切换数据比生产大了3倍多,
另外注意它左边的In(中断数),演练环境的数据比生产大了一倍多,中断一般最多的情况就是网络包的到来,处理收包需要用软中断来处理,从下面的Metric指标看出,演练机器新连接数确实要比生产大许多,
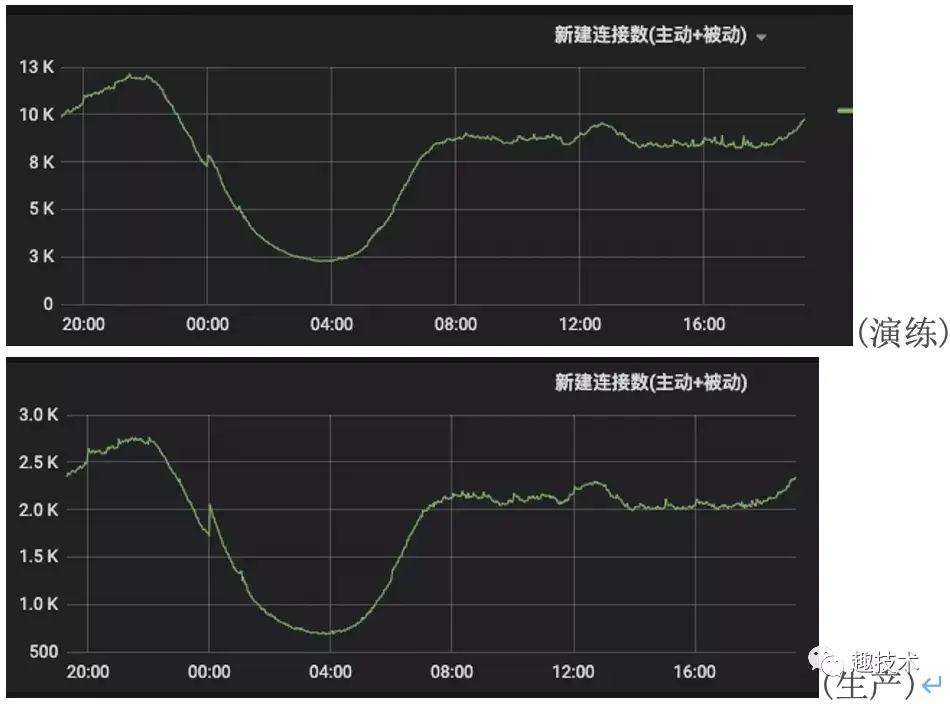
从网络的连接数和strace串起来的分析可推出:大量的新建连接引起的accept事件,引起惊群效应,cpu利用率浪费了(sys非常高),恶性循环。
那为什么nginx会有惊群现象呢?我们可以先从nginx架构模型分析:
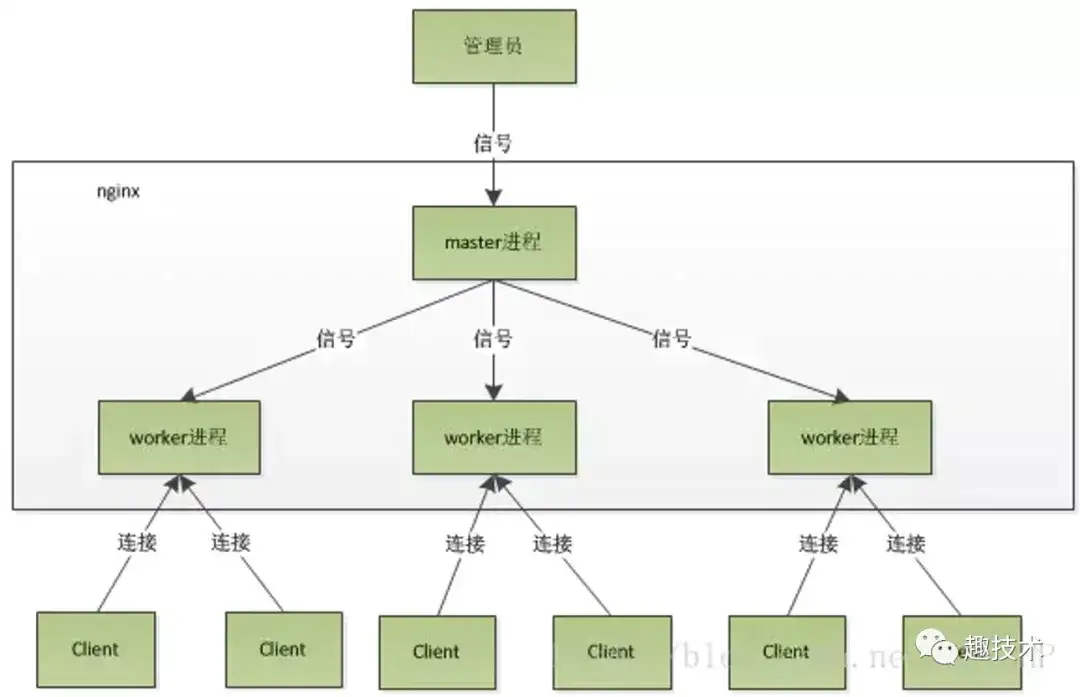
nginx使用master/worker模式,master创建socket fd后,根据cpu核心数fork出了32个worker,每个worker复制了master同一个fd,实际上
也就是32个work监听同一个accept事件,因而当一个新连接过来时,所有其它worker都被唤醒,进而产生惊群。
Nginx 处理惊群的解决办法是加锁,有一个参数accept_mutex,当accept_mutex=on时,只有争抢到锁的worker才会去建立连接,尝试在events中打开此功能后,再看一下负载后的情况:
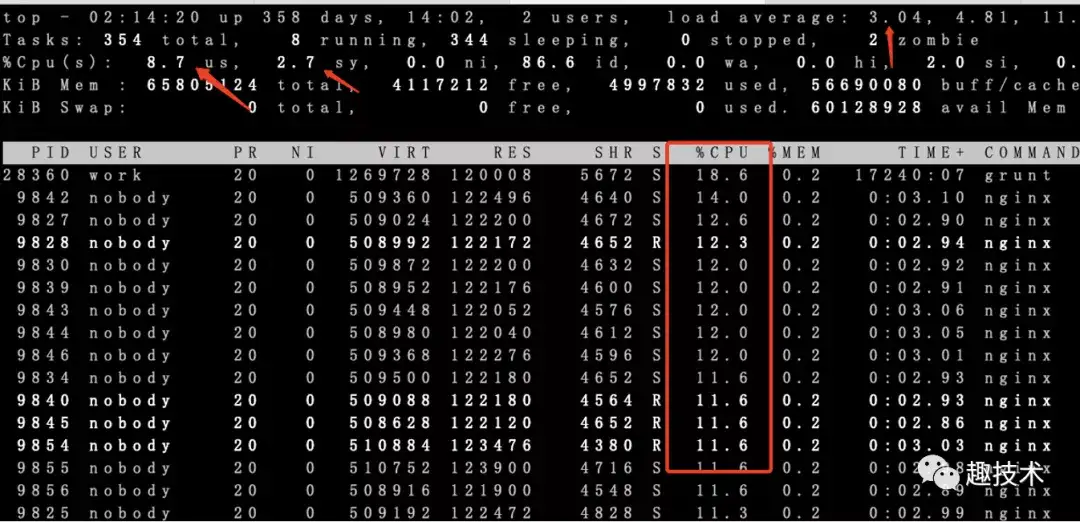
效果立即展现,cpu负载,sys,cpu利用率全部下降,d状态也不见了,但这里还有个问题,nginx每个worker的负载不均,
这个应该好理解,因为worker去争锁,所以大概率不会均匀。
针对epoll的惊群,linux内核其实最新出一个SO_REUSEPORT特性:
SO_REUSEPORT支持多个进程或者线程绑定到同一端口,提高服务器程序的性能,它有以下优势:
允许多个套接字 bind()/listen() 同一个TCP/UDP端口
每一个线程拥有自己的服务器套接字
在服务器套接字上没有了锁的竞争
内核层面实现负载均衡
nginx在1.9已经开始支持此特性,在http监听Port后加入 reuseport即可,打开后的效果如下:
cpu利用更加均衡,没有了锁,利用率也得到提升
实际上在解决问题后,一直还没有提及nginx出现D状态的原因,以及为什么以上两种方法都自动解决了这个D不出现。
前面提及过,D状态出现一般是IO,可能磁盘IO,也可能是网络IO,如果是磁盘io,iowait应该也能体现,但实际上不是
如果是网络IO,那么从tcp连接到收包的时延应该非常大,抓包分析几乎是us级的响应,
网络没有阻塞,当时一直聚焦在io上没有得到原因,最后只好再从Nginx的调用栈分析:
因为Nginx在惊群现象时,worker长期处于D状态,因此很容易通过几次/proc/pid/stack看出到底卡在哪里:
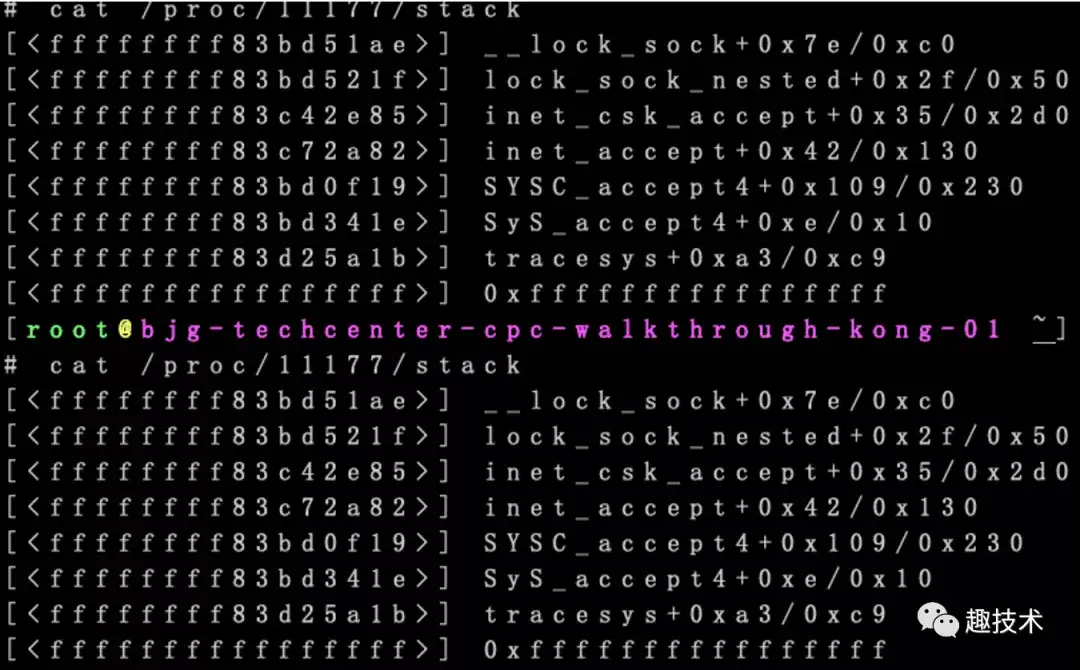
从此图看出主要卡在accept调用,这超乎我的想象,因为strace中看到的accept已经设置非阻塞nonblock,
1594919593.759203 accept4(7, 0x7ffd203bff00, 0x7ffd203bfefc, SOCK_CLOEXEC|SOCK_NONBLOCK) = -1 EAGAIN (Resource temporarily unavailable) <0.000048>
为什么卡在这里,查看__lock_sock后豁然开朗:
static inline void lock_sock(struct sock *sk)
{
lock_sock_nested(sk, 0);
}
void lock_sock_nested(struct sock *sk, int subclass)
{
might_sleep();
spin_lock_bh(&sk->sk_lock.slock);
if (sk->sk_lock.owned)
__lock_sock(sk);
sk->sk_lock.owned = 1;
spin_unlock(&sk->sk_lock.slock);
/*
* The sk_lock has mutex_lock() semantics here:
*/
mutex_acquire(&sk->sk_lock.dep_map, subclass, 0, _RET_IP_);
local_bh_enable();
}
static void __lock_sock(struct sock *sk)
{
DEFINE_WAIT(wait);
for (;;) {
prepare_to_wait_exclusive(&sk->sk_lock.wq, &wait,
TASK_UNINTERRUPTIBLE);
spin_unlock_bh(&sk->sk_lock.slock);
schedule();
spin_lock_bh(&sk->sk_lock.slock);
if (!sock_owned_by_user(sk))
break;
}
finish_wait(&sk->sk_lock.wq, &wait);
}
#define sock_owned_by_user(sk) ((sk)->sk_lock.owned)复制居然在accept中有设置TASK_UNINTERRUPTIBLE,因此惊群引起的大量accept调用失败时,就很容易看到此现象了,真相也大白了。
因此,我们在实际遇到问题时,还是需要熟悉依赖产品或者程序的特性,因此只有深度掌握好系统的各种特性,调优才会更加顺手。