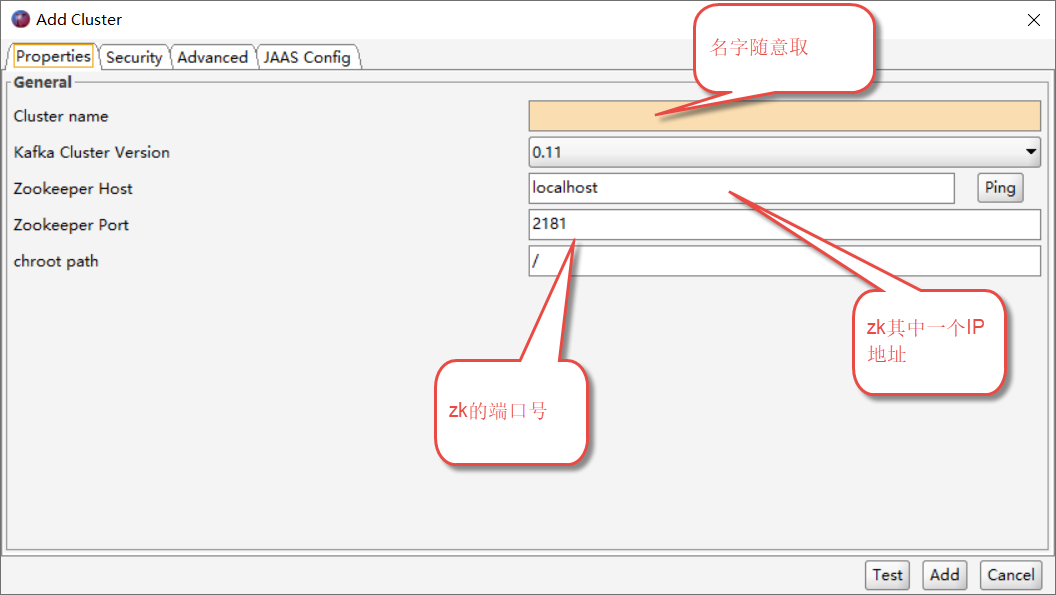
如果kafka 开启SASL_PLAINTEXT认证(用户名和密码认证)
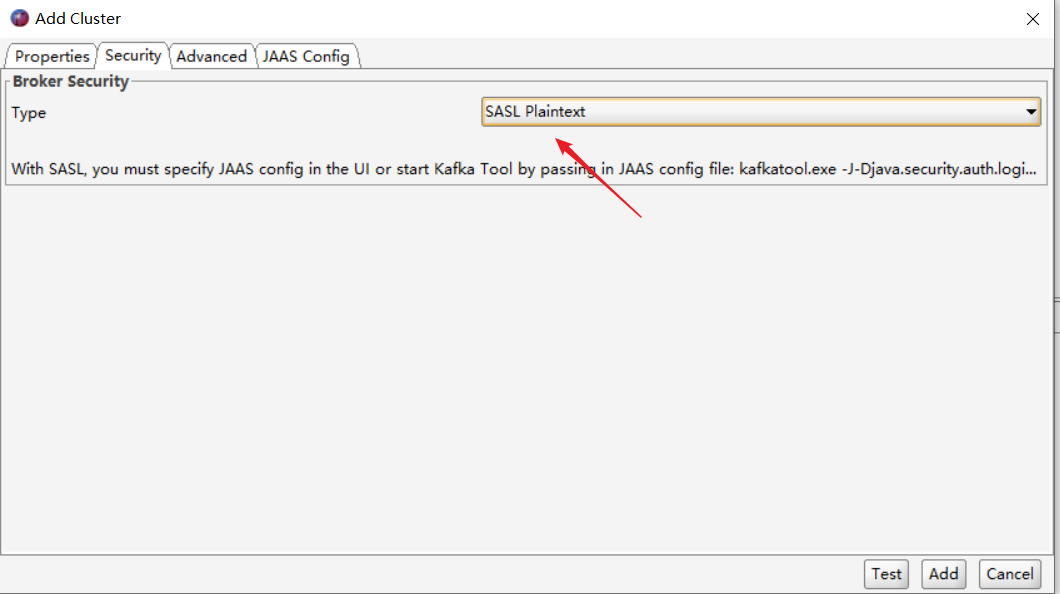
如果设置的是SASL Plaintext,则必须将sasl.mechanism客户端属性更改为PLAIN。可以在“高级”部分下的“ SASL机制”文本字段中输入此属性。

org.apache.kafka.common.security.plain.PlainLoginModule required username = "kafka" password = "123456";复制

相应的脚本也需要对应的进行修改
producer = KafkaProducer(
sasl_mechanism="PLAIN",
security_protocol='SASL_PLAINTEXT',
sasl_plain_username=self.username,
sasl_plain_password=self.password,
bootstrap_servers=self.bootstrap_servers,
value_serializer=lambda m: json.dumps(m).encode())复制
consumer = KafkaConsumer(self.topic,
sasl_mechanism="PLAIN",
security_protocol='SASL_PLAINTEXT',
sasl_plain_username=self.username,
sasl_plain_password=self.password,
bootstrap_servers=self.bootstrap_servers,
consumer_timeout_ms=5000,
group_id=group_id,
auto_offset_reset=auto_offset_reset,
enable_auto_commit=enable_auto_commit
)
if consumer.bootstrap_connected():
lk_kafka = []
for message in consumer:
msg = message.value.decode()
lk_kafka.append(msg)
log.warning("数据读取完成,数据读取超时,自动断开连接")
return lk_kafka
else:
log.error("连接kafka失败,请确认连接信息是否正确")复制