前言
kafka是常用MQ的一种,站在使用者的角度来看待,kafka以及所有的MQ应该是这样的:
(注意箭头的方向)
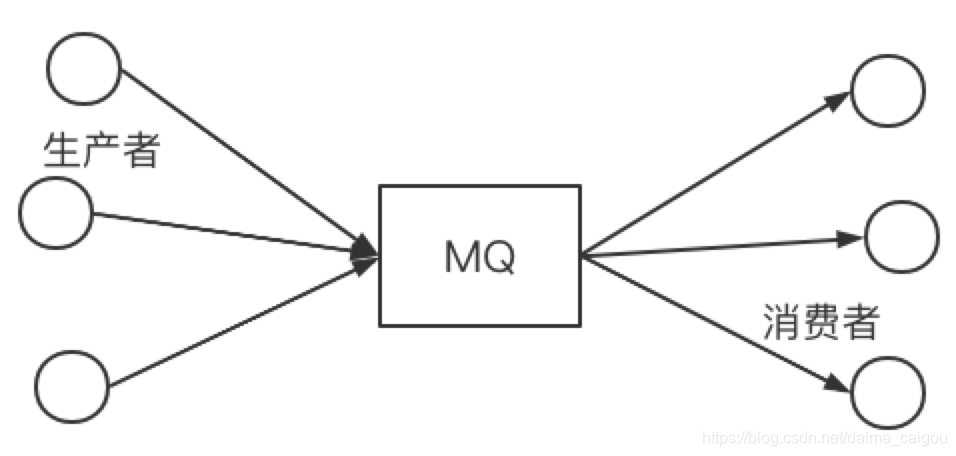
这个一点问题都没有,即使你站在MQ的开发者的角度,这个图也是没问题的,你就当它是这样的用就行。
但是,如果你是站在一个候选人或者面试官的角度,上面这个图就不行了,所以没法办,扣的就是细节,问的就是原理。
而上图,仅仅只能代表MQ的一种思想或者说理念。
Kafka版本查看
不得不说,就像个大傻叼,Kafka没提供直接方便查看的命令,且,命名也恶心的一逼。
笔者是Mac电脑,用brew方式安装的。
/usr/local/Cellar/kafka/2.2.1 通过这个安装目录结构就能看出,笔者目前用的是2.2.1版本
至于 /usr/local/Cellar/kafka/2.2.1/libexec/libs这个目录下的一堆东西,也可以分辨出来
2.12-2.2.1 前面的2.12说的是Scala版本,后面的是Kafka版本。
Kafka整体架构
Kafka cluster
站在运维的角度来看,Kafka集群就是这样的(忽略zk)
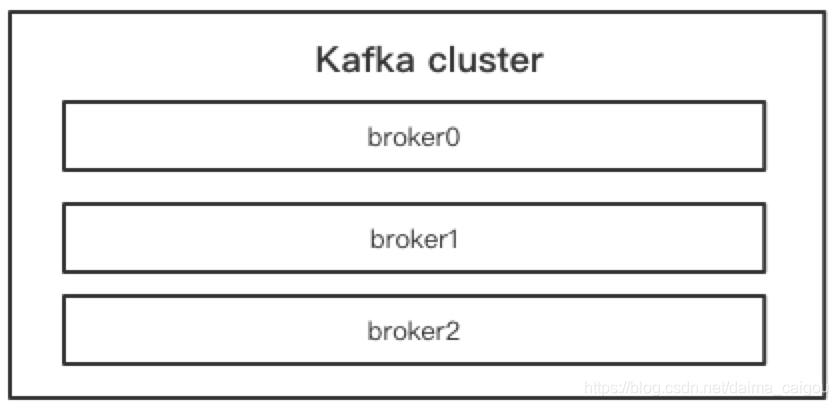
首先要明白,Kafka是以集群部署的方式对外提供服务的。
Kafka所说的这个broker就是我们说的集群中的一个实例,你理解为一个Kafka进程或者一台机器或者一个节点都行。
问题1:Kafka集群,消息数据如何存储的?
是像redis cluster这种,每个集群中的实例只存部分数据,所有实例加起来才是完整的redis数据?
还是像zk cluster这种,每个集群中的实例,数据都一样?
这里需要先介绍另一个Kafka中的概念:topic
topic是什么
在实际生产工作中,并不是一个场景使用这个Kafka集群,可能几个业务公用一个Kafka,这就出现来一个问题,我们好几方生产者,往同一套Kafka里塞各自的消息,我们好几方的消费者,咋区分这些消息哪些是我所需要的呢?
我们自己可以解决:生产者和消费者约定好一个标记,我们为这个消息打上这个标记,消费者只消费带有这个标记的消息。
所以消费者每次接到消息,都要判断
if msg.tag != "xxx" { return }...开始消费...复制这虽然解决了问题,但是不优雅。
所以Kafka解决了这个问题,Kafka在接收生产者的消息时,需要生产者指明,这个消息的topic是什么(生产者不指定topic,Kafka内部也会创建默认的topic),Kafka内部帮你们分类管理,而消费者消费时,只需要告诉Kafka,想消费哪个topic的消息,Kafka就只会给他这个topic的数据,其他topic的不用关心,他也消费不了。
topic翻译过来是:主题,也可以理解为类型、标记...... 他的作用就是Kafka分类管理消息的依据。
所以站在topic的角度来看,此时的Kafka应该是这样的:
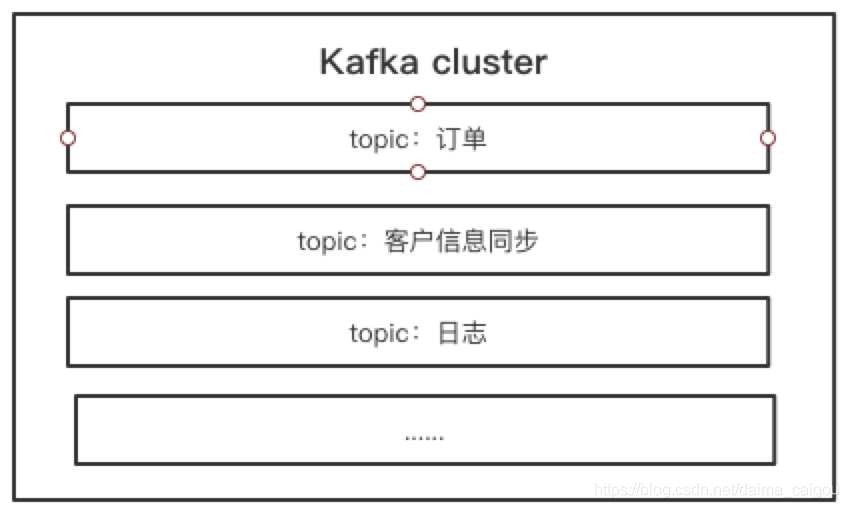
回答问题1
因为Kafka与redis或zk的不同点是,redis和zk里的数据是无属性的,说白了client连上就能操作所有的东西,数据是对所有client共享的(忽略某些权限控制等因素),不然为什么用redis或zk作为分布式锁的解决方案。
但是Kafka里的数据是有属性的,是有topic的,你不消费的topic里的数据你永远也拿不到。
所以我们回答Kafka中的消息数据是怎么存储的,需要站在一个topic的角度,
即:一整个topic的数据,在Kafka中是怎么存储的?
答案:类似redis cluster,每个partition里有一部分,全部加起来,才是一个完整的topic的数据。
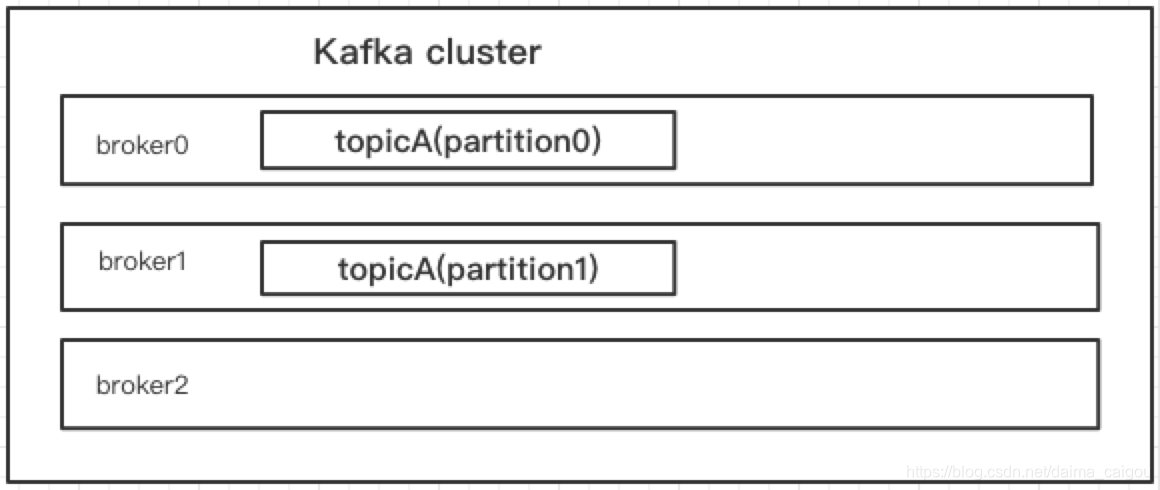
partition是什么
如图,我们看到,broker0和broker1这两个实例都有一部分属于topicA的数据,他们加起来就是完整的数据。
那么紧随topic后面的partition是什么意思呢?
partition翻译过来:隔板墙;分割;分治;瓜分。你就理解为分区就行了。
和其他集群中的分区概念差不多,就是说,既然数据被化整为零了,那总要知道哪一块的数据在哪吧?
还有,partition是物理的概念,topic是逻辑的概念。
就是说,你去部署Kafka集群的机器上,一定能找到partition的数据文件。
而topic只是对外(生产者和消费者)的一个概念。
再参考redis cluster,是不是每一个“区”,都是主从部署的?
Kafka中的partition也是一样的。为什么上图中有一些留白,因为实际上可能是这样的:
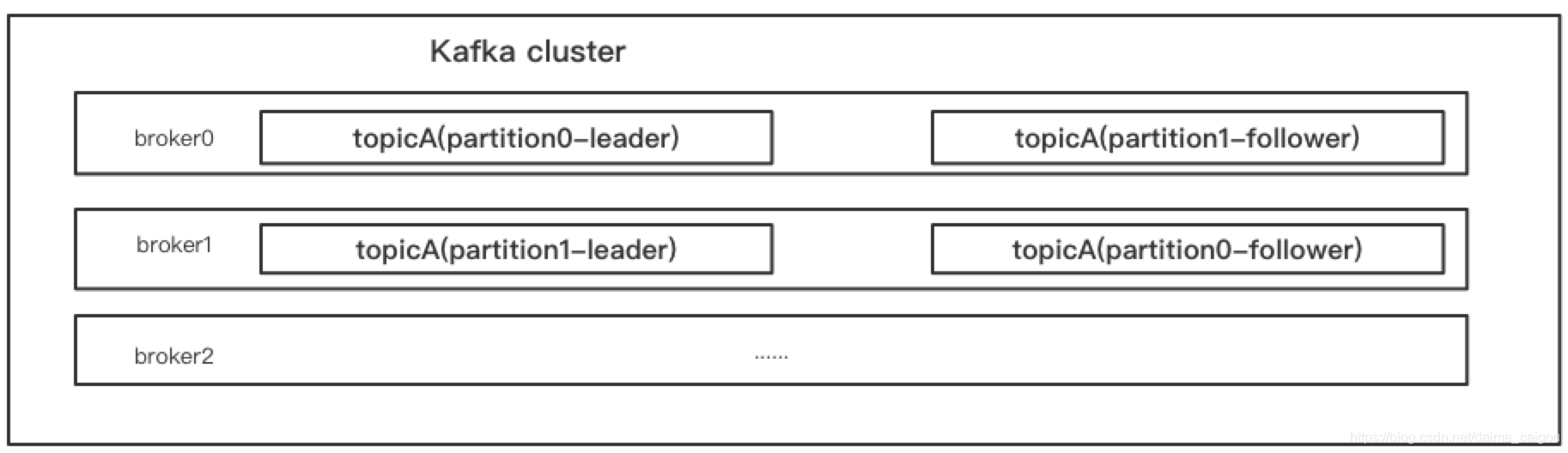
注意:
1、partition的leader和follower应在不同的broker上,因为在一个broker上的主从没有意义,一挂全挂。
2、partition的follower只作为副本,对外提供服务的只有leader
3、partition的数量可以为1
为什么要有partition的概念?
负载均衡 // TODO
多partition,多消费者,Kafka如何保证消费正确性?
我们知道topic只是一个逻辑的概念,实际真正消费数据的时候,还是要从各个partition中取数据。
假设就一个partition,多个消费者。假设多个partition,就一个消费者。
我相信就算我们自己实现Kafka的消费逻辑,也不会有啥问题。
问题是,真实的场景中,多个partition和多个消费者。Kafka怎么保证消费不出问题?
这就引出了一个概念:group
group是什么?
首先,group这个概念是针对消费者一方的,我们常说的就是:消费者组
是多个消费者,组成了一个组,作为一个大的消费群体,对一个topic进行消费。
一个consumer-group保证能消费到这个topic里的所有数据。
group如何保证消费正确性?
1、消费者group中的每个消费者,负责消费topic下不同的partition的数据
2、一个partition只能被一个group中一个消费者进行消费
如果理解了上述规定,那么结果显而易见
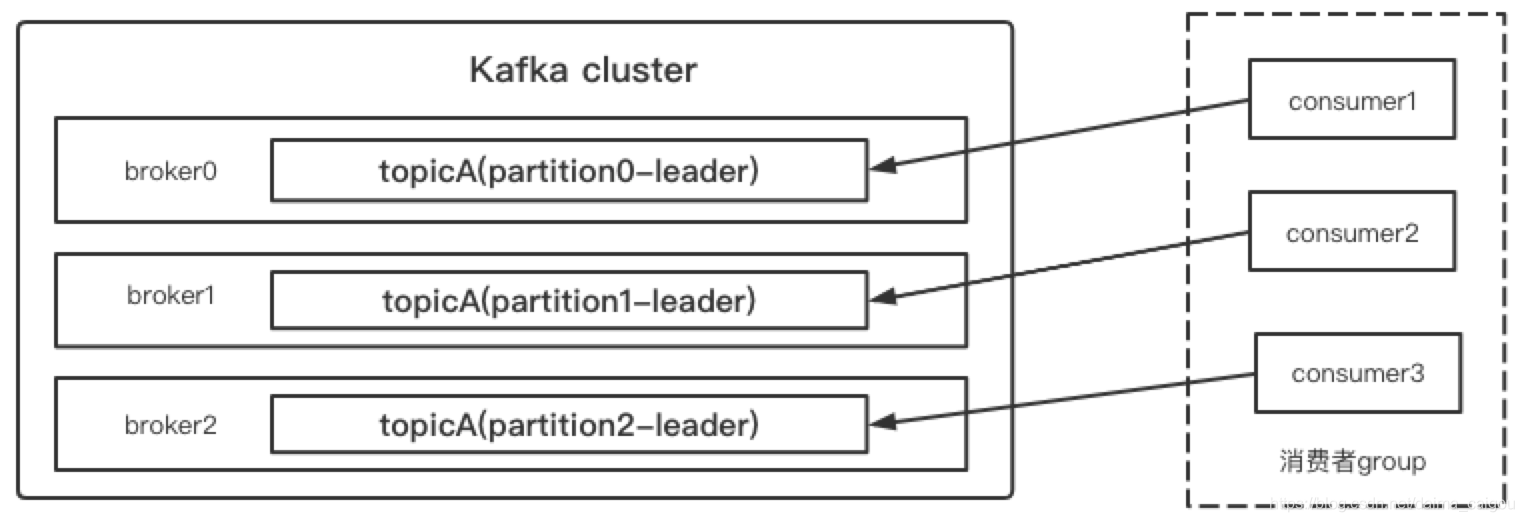
说白了:人人有饭吃,都别抢,自己吃自己的
这就是Kafka理想的消费模型:topic里面多少个partition,消费者group里就有多少个消费者
为什么?因为充分的利用了partition和consumer,没有资源浪费,提升消费速率(提升消费能力、提高并发)。
如果partition比consumer少,那就代表“有人没饭吃”
多余的消费者空转,浪费了资源,毫无意义
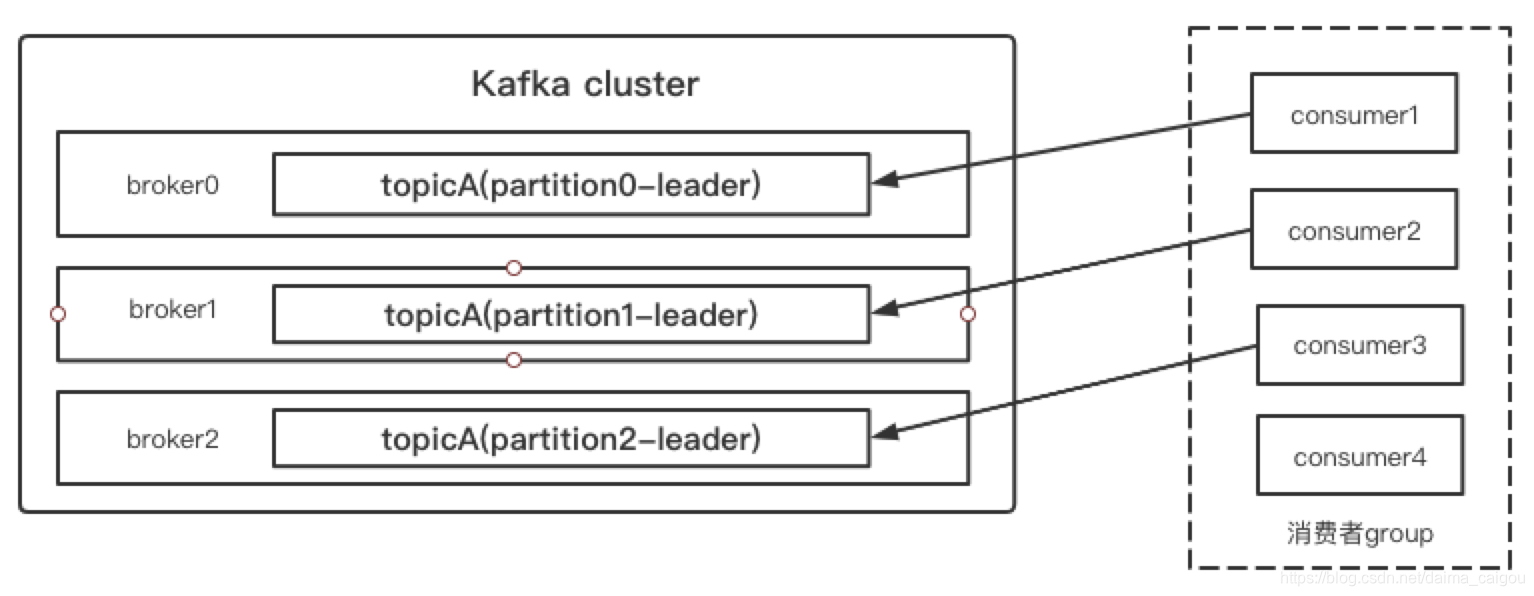
如果consumer比partition少,那就代表“有人吃撑了”
某些消费者“压力大”,从整体消费速度来说,效率下降了
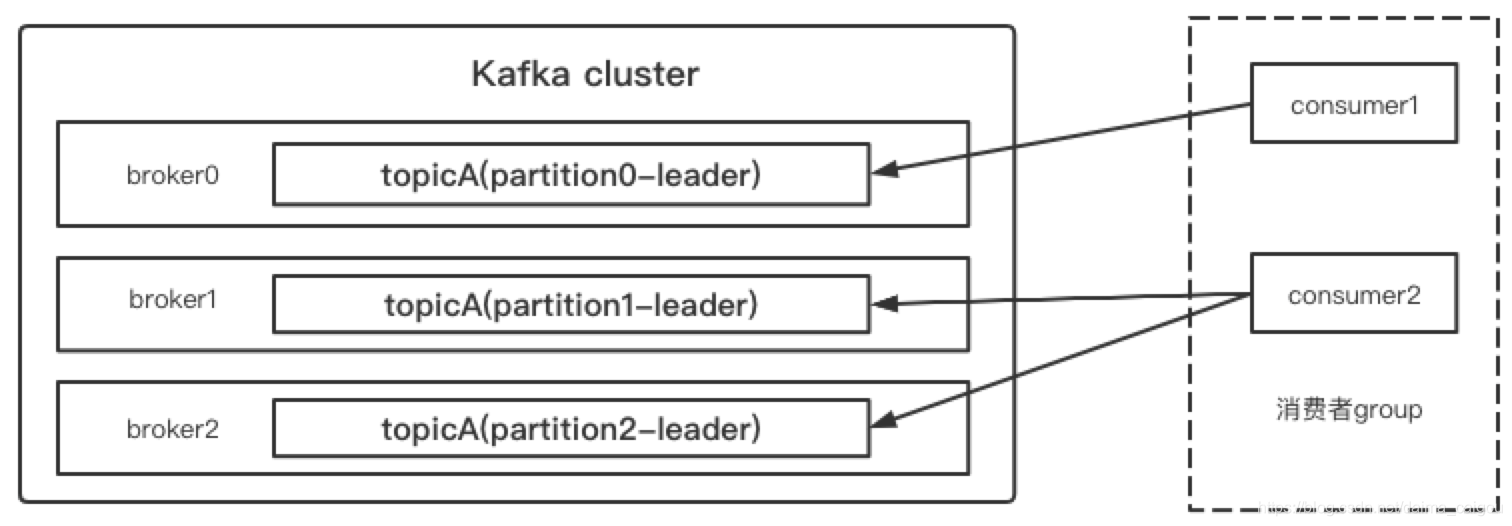
有时候,一个消费要被消费多次
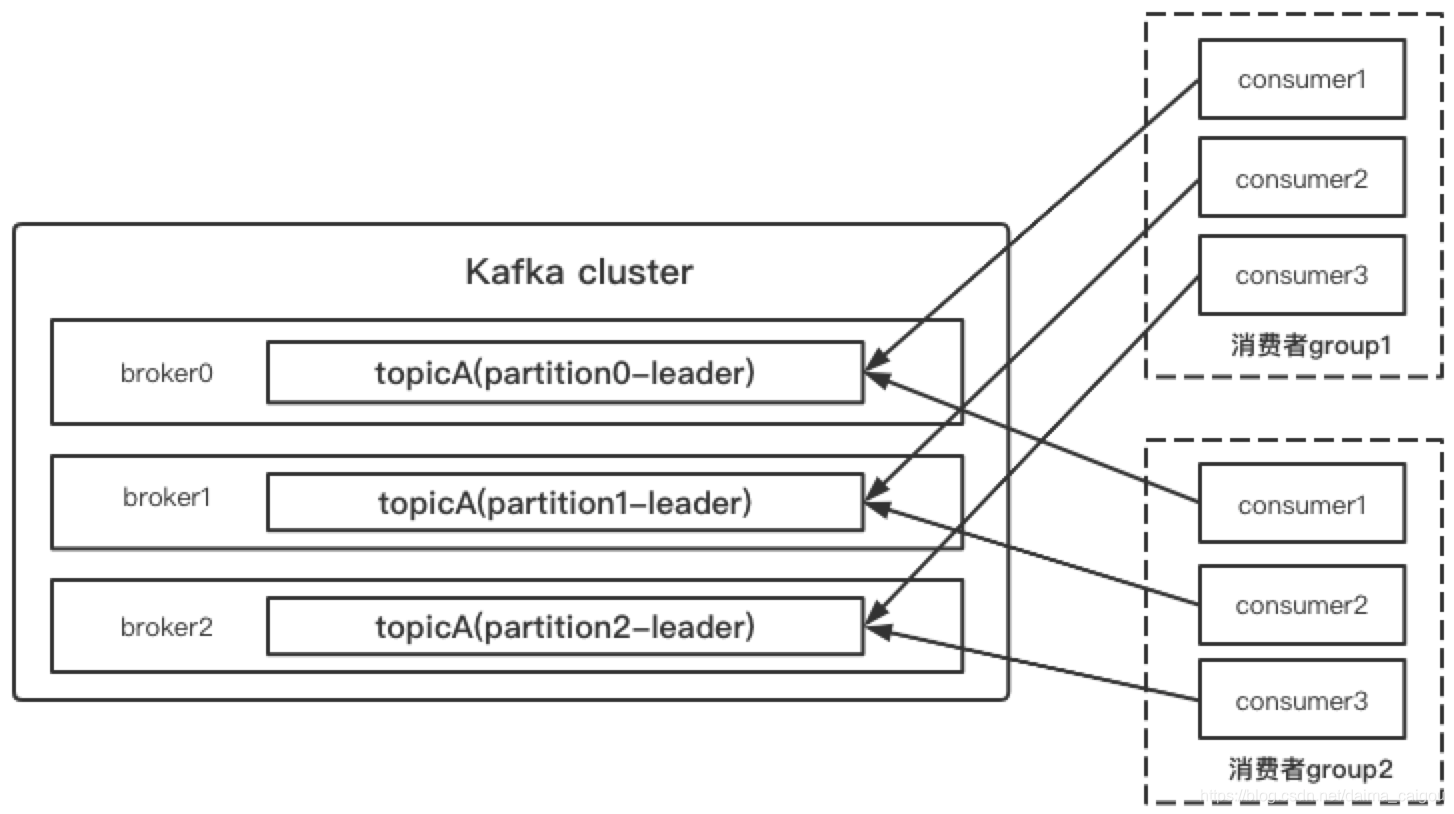
一个partition只能被一个group中一个消费者进行消费。再好好理解这句话。
生产者生产的消息,只发一次,其他业务,谁想要,随时自己加group去消费。
生产者不可能谁想要就发给谁一份,难道多个topic,里面的数据全部一样么,不可能这么做的,Kafka容量都不够。
所以,数据还是那一份数据,是通过不同的group来达到的这个效果。
这就是为什么说,consumer-group作为一个大的整体消费topic。
所谓消费消息,到底是Kafka push消息,还是consumer pull消息?
答案:consumer去Kafka那里pull消息
所以,Kafka并不是给消费者推送消息,可以把Kafka当成快递柜
快递员(producer)把物品(msg)放到柜子里(topic),你自己(consumer)去开柜子拿货。
为什么不采取Kafka push的方式?
每个消费者的消费能力不同,Kafka怎么控制push速率?
既然是push,那Kafka是不是要存一下所有消费者的地址列表,是否有必要?
过多的消费者是否影响push效率?
消费者可能随时增加或减少,如果消费者宕机,Kafka怎么知道?
zookeeper在Kafka中的作用?
1、存一些Kafka的信息、消费者的信息。
除了zookeeper这个znode是zk自带的,其他的都是Kafka创建的。
0.9版本之前,offset存储在zk
0.9版本之后,offset存储在Kafka
2、帮助Kafka构建集群,只要Kafka实例使用的是同一套zk,就能构建。
这里要看一下Kafka搭建集群的时候,配置文件的注意改动点
- #broker 的全局唯一编号,不能重复
- broker.id=0
-
- #配置连接 Zookeeper 集群地址
- zookeeper.connect=127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183
再对比一下zk搭建集群时配置文件怎么写的,就会明白。
为什么Kafka的配置文件不用写上所有broker的地址?
Kafka启动的实例需要向zk注册服务,通过zk来构建Kafka的集群。
3、kafka的哪些组件需要注册到zookeeper?
(1)Broker注册到zk
每个broker启动时,都会注册到zk中,把自身的broker.id通知给zk。
待zk创建此节点后,kafka会把这个broker的主机名和端口号记录到此节点。
(2)Topic注册到zk
当broker启动时,会到对应topic节点下注册自己的broker.id到对应分区的isr列表中;
当broker退出时,zk会自动更新其对应的topic分区的ISR列表,并决定是否需要做消费者的rebalance
(3)Consumer注册到zk
一旦有新的消费者组注册到zk,zk会创建专用的节点来保存相关信息。
如果zk发现消费者增加或减少,会自动触发消费者的负载均衡。
注意,producer不注册到zk
总结
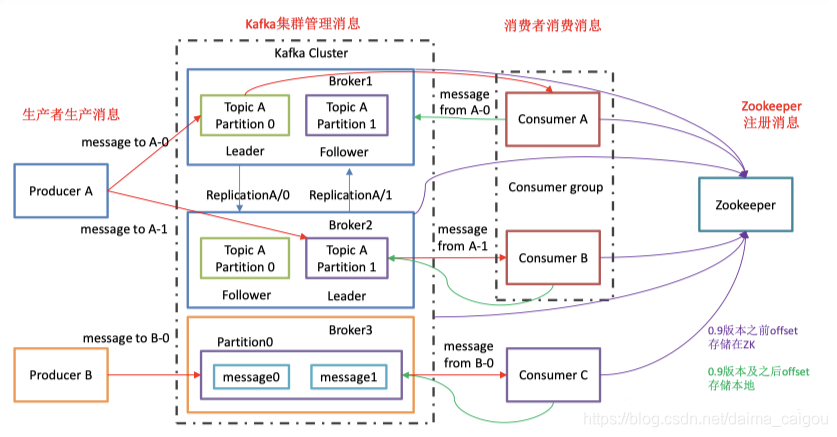
1)Producer :消息生产者,就是向 kafka broker 发消息的客户端;
2)Consumer :消息消费者,向 kafka broker 取消息的客户端;
3)Consumer Group(CG):消费者组,由多个 consumer 组成。
消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响。
所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
4)Broker :一台 kafka 服务器就是一个 broker。一个集群由多个 broker 组成。一个 broker 可以容纳多个 topic。
5)Topic :可以理解为一个队列,生产者和消费者面向的都是一个 topic;
6)Partition:为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服务器)上,
一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列;
7)Replica:副本,为保证集群中的某个节点发生故障时,该节点上的 partition 数据不丢失且 kafka 仍然能够继续工作,
kafka 提供了副本机制,一个 topic 的每个分区都有若干个副本, 一个 leader 和若干个 follower。
8)leader:每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对 象都是 leader。
9)follower:每个分区多个副本中的“从”,实时从 leader 中同步数据,保持和 leader 数据 的同步。
leader 发生故障时,某个 follower 会成为新的 leader。
10)offset:每条数据都有自己的 offset。
消费者组中的每个消费者,都会实时记录自己消费到了哪个 offset,以便出错恢复时,可从上次的位置继续消费。
msg的存储机制
Kafka的msg存储采用了分区(partition),分段(LogSegment)和稀疏索引这几个手段来达到了高效性。
0、非常重要
生产者的发送的消息,我就简称msg,而Kafka真正存的时候,是一个对象/结构体,msg只是其中一个属性。
1、Kafka中的消息都存文件里了,文件所在的文件夹是按照partition分的。
2、文件的后缀是 .log,非常的恶趣味,不知道的以为是Kafka本身的程序日志呢!
3、消息文件存储路径的配置也是恶趣味。
log.dirs=/opt/module/kafka/logs复制4、文件打开,因为消息都被序列化了,所以没法直接看,需要用Kafka命令查看。
5、partition是为了给消息分区,而到消息存储的时候,又给每个partition进行了分段(segment)
即,不是一个partition里的消息就存一个文件里,而是很多个文件。
6、分段的依据是可配置的
# log文件的大小,默认为1Glog.segment.bytes=1073741824 # offset索引文件或时间戳索引文件的大小log.index.size.max.bytes # 当前日志分段中消息的最大时间戳与当前系统的时间戳的差值允许的最大范围,毫秒维度log.roll.ms # 当前日志分段中消息的最大时间戳与当前系统的时间戳的差值允许的最大范围,小时维度。优先级比log.roll.ms低log.roll.hours 复制7、默认Kafka 只保留最近7天的数据
- #segment文件保留的最长时间,默认保留7天(168小时)超时将被删除
- log.retention.hours=168
8、消息是不断的额追加到segment文件末尾的,O(1)。
9、每个log文件都有配套的index文件和timeindex文件
segment的细节
topic:partition = 1:N
partition:segment = 1:N
虽然并不是很准确,但是从逻辑和物理2项综合的角度,我们的消息存储的最小单位就是segment。
1、每个segment对应了3部分(说2部分的都是老黄历了,0.10.1.0版本之前是2部分)
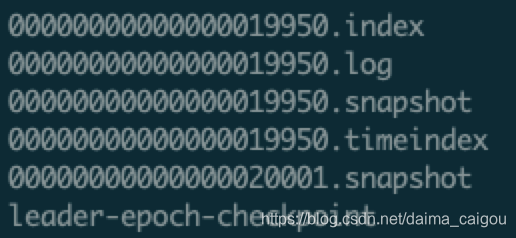
| 类别 | 作用 |
|---|---|
| .index | 偏移量索引文件 |
| .log | 日志文件 |
| .snapshot | 日志快照(snapshot文件并不是每个segment都有) |
| .timeindex | 时间戳索引文件 |
| leader-epoch-checkpoint | 用于副本同步的检查点文件 |
2、这些segment都在一个文件夹下面,文件夹命名规则:topic名称+分区序号。
比如下图中kafka-logs文件下的一个文件夹名:test_topic是topic名,0是partition序号。
3、同一个segment的文件名都是相同的。
4、文件命名规则:当前segment的第一条(offset最小)消息的offset命名
![]()
用命令查看index文件,第一条记录的真实offset(为什么强调真实,后面讲)就和文件名相同,由此可证。
但是,也并不是每个index文件的第一条记录的offset都是从文件名这个offset开始的。
![]()
这一点某些博客上说的是错误的,需注意。
5、log文件的结构

如图,开头记录了这个log文件从哪个offset开始记录的
之后就是一个个的消息对象了,别的属性我不知道,大家可以自行研究。
除了offset,我就认识payload(有效负载,咱也不懂为什么叫这个名字),因为ssq1这个值就是我测试代码中的msg。
你知道哪个是msg就行了,至于有些视频教程和博客中说的:
index文件存offset,log文件存消息。
懂得都懂,但很容易让初学者误解,log文件里也有offset啊,且index里存的offset是【相对offset】!
6、index文件的结构
稀疏索引。
4字节的相对位移(offset)和4字节的物理地址(postion)组成。
请注意:你用脚本查看文件,查看的这个offset值,并不是文件里真实存储的值。
真实存储的是【相对offset】,即相对于这个baseOffset(18528/文件名)的offset。
公式:相对offset + baseOffset = 真实offset

- # 默认4K,增加索引项字节间隔密度,会影响索引文件中的区间密度和查询效率
- # 讲人话就是:每隔4KB的消息建一条索引
- log.index.interval.bytes=4096
7、timeindex文件的结构
offset也是稀疏索引
时间戳占用8字节,【相对offset】占用4字节

- # createtime:定义消息中的时间戳是消息创建时间
- # logappendtime:日志追加时间
- log.message.timestamp.type
8、通过offset查找msg
1、通过SkipList定位segment(不是二分法)
2、对index文件进行二分查找,找到offset的区间
3、去log文件中对这一小段区间顺序查找,找到最终的消息
9、通过时间戳查找msg(例如:查找时间戳xxxx之后的消息)
1、逐一对比每个segment的最大时间戳,用于定位segment
说明:
segment的最大时间戳,就是timeindex文件的最后一条记录
对比的顺序是:从最早的segment开始
对比的规则是:最大时间戳要比xxxx大,结合对比顺序,就保证了,xxxx一定就在当前segment之中
2、对timeindex文件进行二分查找,进一步定位xxxx所在区间,并拿到区间对应的offset
3、用这个offset去index文件中定位log的区间
4、最后去log文件中查找
Kafka消息查找总结
首先,基于时间戳的查找和基于offset的查找流程是一样的。不同点在于
1、因为segment下的文件名都是offset,所以天然在定位segment这一步,基于offset查找就会方便。
2、最后去log中顺序查找的对比属性不同,基于offset肯定是对比offset属性,而基于时间戳肯定是对比时间属性
如图,笔者的配置
![]()
自然消息对象的LogAppendTime属性就会有值

3、timeindex文件和index文件中存的offset不是一一对应的,他们是各自记录自己的。所以笔者才会一直强调:定位区间。
日志刷盘原理
# 默认值为9223372036854775807,该参数的含义是刷新进磁盘累计的消息个数阈值log.flush.interval.messages # 默认值为null,表示多长时间间隔把内存中的消息刷新进磁盘,# 如果没有设置,则使用log.flush.scheduler.interval.mslog.flush.interval.ms # 默认值9223372036854775807,含义是检查日志被刷新进磁盘的频率。log.flush.scheduler.interval.ms复制根据默认配置,我怎么感觉这么不稳呢?隔这么老长时间才写入磁盘,消息容易丢啊。
在Linux系统中,当我们把数据写入文件系统之后,其实数据在操作系统的pagecache里面,并没有刷到磁盘上。
如果操作系统挂了,数据就丢失了。
一方面,应用程序可以调用fsync这个系统调用来强制刷盘
另一方面,操作系统有后台线程,定时刷盘。
频繁调用fsync会影响性能,需要在性能和可靠性之间进行权衡。
实际上,官方不建议通过上述的三个参数来强制写盘,认为数据的可靠性通过replica来保证,而强制flush数据到磁盘会对整体性能产生影响。
Kafka的持久性并非要求同步数据到磁盘,因为问题节点都是从副本中恢复数据。这样刷盘依赖操作系统及Kafka的后台刷盘机制。这样的好处是:无需调优、高吞吐量、低延时和可全量恢复。
消息的有序性
既然分了partition,那么生产者的消息还有序么?
Kafka只能保证每个partition有序,全局有序无法保证。
即:假设生产者依次发消息[1,2,3,4,5,6],Kafka中分了2个partition
partition0中的数据可能为:1(offset=0),3(offset=1),5(offset=2)
partition1中的数据可能为:2(offset=0),4(offset=1),6(offset=2)
每个partition内的offset,都是从0开始的。
partition只能保证进来的消息,都“排好队”并用offset标记上,给消费者时也是按照offset依次给。
就想要消息全局有序,是否能做到?
可以,只设置一个partition
这样生产者怎么发的消息,Kafka都会依次放入这一个partition里,就全局有序了。