https://zhuanlan.zhihu.com/p/261115166复制
Percolator - 分布式事务的理解与分析
概述
一个web页面能不能被Google搜索到,取决于它是否被Google抓取并存入了它的倒排索引。Google管理着万亿级别的倒排索引,并且每天都有着几十亿级别的数据更新。通过MapReduce批处理,可以高效地将整个数据库全量构建成倒排索引。但是对于增量数据来说,全量构建是不经济且不及时的。所以Google研发了Percolator,用于处理这些大规模的增量数据。
为了确保系统故障时的数据一致性,Percolator在BigTable的基础之上,提供了Snapshot Isolation语义的分布式事务能力。本文讨论的重点就在于:Percolator如何基于BigTable的单行事务和一个Timestamp Oracle(全局授时服务器,后称TSO)实现上述的分布式事务。
模型
Percolator实现分布式事务主要基于3个实体:Client、TSO、BigTable。
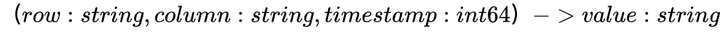
实际上Percolator存储一列数据的时候,会在BigTable中存储多列数据:

对于上表来说,它表示的是k1这一行,c1这一列数据的3个版本(timestamp分别为5、6、7)。
因为write列中,最新的数据是data@5,表明最新的一次commit_timestamp为5。所以看timestamp=5时,data列的数据为foobar。并且这一行这一列最新的数据也为:foobar。
在timestamp=7的时候,data列的数据被改为了barbaz,lock列也被标记为锁定,意味着此时有一个事务正在修改数据。一旦这个数据成功提交,在未来个某个timestamp上,会将它的write列写为7,并把7中的lock列清理掉。
可以看出,Percolator使用了lock和write这额外的2列来表达事务的状态。下面会具体说明,如何使用这2列作为元数据来实现分布式事务。
“写”事务
Percolator的分布式写事务是由2阶段提交(后称2PC)实现的。不过它对传统2PC做了一些修改,可见后文的“Percolator特色的2PC”。
一个写事务可以包含多个写操作,事务开启时,Client会从TSO处获取一个timestamp作为事务的开始时间(后称为start_ts)。在提交之前,所有的写操作都只是缓存在内存里。提交时会经过prewrite阶段和commit阶段。
Prewrite阶段
对于同一个写操作来说,data、lock、write列的修改由BigTable单行事务保证事务性。
由冲突检测的b可以推测:如果有多个并发的大事务,并且操作的数据有重合,则可能会频繁abort事务,这会是一个问题。在TiDB的改进中会谈到它们怎么解决这一问题。
Commit阶段
“读”事务
在早期的SQL标准中定义的四个事务隔离级别,只适用于基于锁的事务并发控制。后来有人写了一篇论文 A Critique of ANSI SQL Isolation Levels 来批判 SQL 标准对隔离级别的定义,并在论文里提到了一种新的隔离级别 —— Snapshot Isolation(快照隔离)。在Snapshot Isolation下,不会出现脏读、不可重复度和幻读的问题。并且读操作不会被阻塞,对于读多写少的应用,Snapshot Isolation是非常好的选择。所以,主流数据库都实现了Snapshot Isolation。更多关于Snapshot Isolation的内容和历史,可以查阅《Design Data-Intensive Applications》第7章第2节。
事务隔离级别,实际上规定的就是事务之间的可见行。对于Snapshot Isolation来说:事务只能看到早于它开始时刻之前提交的其他事务。
以下图为例:事务2看不到事务1的修改,因为事务1在事务2开始之后才提交;事务3可以看到事务1和事务2的修改,因为它们在事务3开始之前提交。PS:因为事务1和事务2是并发的,如果它们操作的数据有重合,则至少有一个事务会回滚。
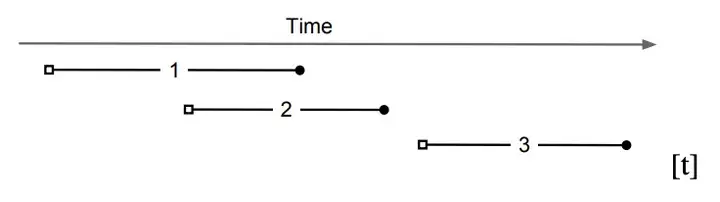
精确地获取事务的start_ts和commit_ts是很重要的。因为它关系着事务之间的可见行,以及决定了多个事务是否并行。Percolator使用Timestamp Oracle模块来提供start_ts和commit_ts。
分布式下snapshot-read存在的问题
尽管我们可以通过TSO获取到精确的start_ts和commit_ts,但还是可能出现一个小问题:事务实际执行的顺序可能和时间戳的顺序不一致!
举个例子:T1的commit_ts < T2的start_ts, T2执行Read的时候,T1还没commit完成。按照标准,T2应该需要可以读取到T1的更改,但实际上因为T1还没有commit。
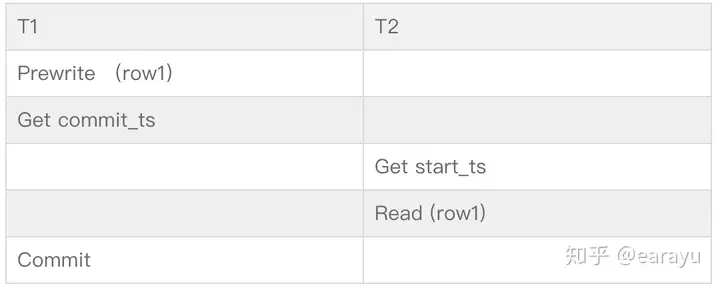
Percolator的解法是:
对于上面的例子来说,T2执行到Read时,发现row1被T1锁住了,就会等待直到T1 commit完成。这样T2就能读取到T1 commit的结果了,符合了snapshot-read的标准。
Percolator特色的2PC
不同于传统意义上的2PC,在Percolator中貌似看不到Transactional Coordinator的角色。其实只要是2PC都需要Coordinator,只是Percolator把Coordinator的职责作了更进一步的细分,从而不再需要一个中心化的节点。
在2PC中,最关键的莫过于Commit Point(提交点)。因为在Commit Point之前,事务都不算生效,并且随时可以回滚。而一旦过了Commit Point,事务必须生效,哪怕是发生了网络分区、机器故障,一旦恢复都必须继续下去。
传统的2PC的Commit Point在写本地磁盘的那一刻;Percolator 2PC的Commit Point在完成BigTable事务的那一刻。为什么会有这样的区别?因为传统的Coordinator是可恢复的,参与者可以在Coordinator恢复后去询问事务的结果。而Percolator Client很可能是不可恢复的,并且它的恢复也是没有意义的。
| 传统Coordinator | Percolator Client | |
| 发送Prewrite请求 | 无本质区别 | |
| 判定是否可以Commit | 无本质区别 | |
| 写Commit Log(提交点) | 写本地磁盘 | 写primary的write列 |
| 发送Commit请求 | 发送RPC | 写Secondary的write列 |
| rollback/roll-forward | coordinator发送RPC/participant主动查询 | 懒处理+通过lock和write列状态判断 |
PS:至于上文提到的,Percolator总是先操作primary,最重要的原因在于Percolator把“写primary的write列、清理lock列”作为了commit point。
故障恢复
首先明确一点:一个事务是否执行成功,只取决于Commit Point。一旦一个事务的Commit Point确定,所有写操作都最终必须确定且必须一致地接受。传统2PC从Coordinator处获取全局最终一致性,而Percolator的2PC就只能从data、lock、write这3列的状态来判断全局最终一致性了。如何从这几列数据判断出事务的提交状态,就是问题的关键所在。
事务崩溃的边界如何划分?
判断出事务的提交状态后,接着就是故障恢复。Percolator使用了懒处理的方式。一个事务执行时,会判断先前事务的状态,如果发现先前的事务故障了,则帮助它进行相应的故障恢复。这边是没有办法100%确定某个事务崩溃的,比如事务A因为网络分区而阻塞了,那阻塞多久算事务A失败呢?量变和质变的边界不是100%清晰。或者说,量变到质变的转化不是客观存在的,而是由第三方事务来决定的!Percolator只能猜测(原文suspect)一个事务失败,从而对它进行abort或者rollback/roll-forward。同时Percolator也采用了一个lightweight lock service来使这个猜测过程更迅速。
PS:回头可以发现,Percolator 2PC的commit阶段,会先判断primary上的锁是否还在。就是因为任意事务可能会被其他事务认为已经崩溃了,从而被abort。
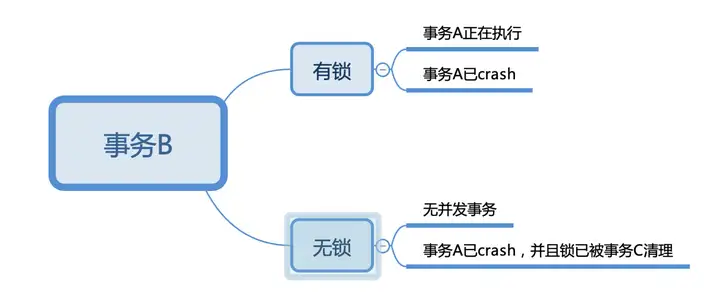
如何判断事务的最终状态
想象一下事务B正在执行,它要操作的一行数据只有可能是2种状态:有锁和无锁。有锁状态下,一定是有其他事务A并行,事务A可能正在运行,也有可能崩溃了。无锁状态下,可能是无其他事务并行,也有可能是事务崩溃并且锁已经被其他事务清理掉了。
PS:这里的有锁和无锁,全部指代的是primary的lock列是否有数据。如果事务B操作的是secondary,需要根据secondary的lock列寻址到相应的primary的lock列。
如下图:
TiDB的对“写-写冲突”的改进
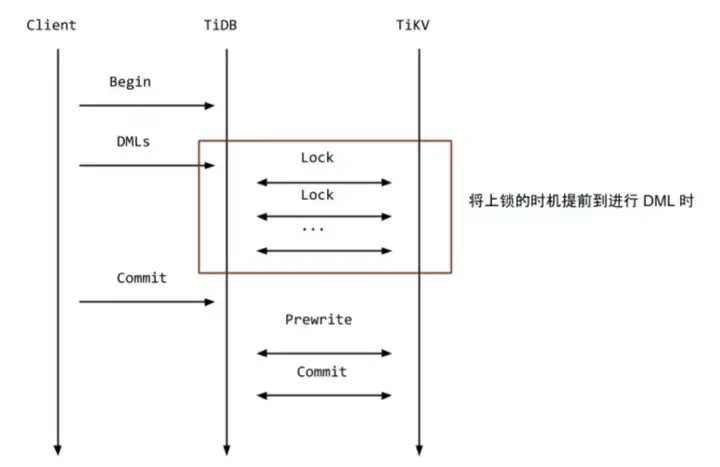
首先TiDB提供了良好的控制台工具,可以查看数据库的事务冲突数量、事务重试数量以及事务延迟。根据告警可以定位到数据,从而找到对应的代码,最终可以尝试通过修改代码解决问题。TiDB在v3.0.8之后也提供了悲观事务模型:会在每个 DML 语句执行的时候,加上悲观锁,用于防止其他事务修改相同 Key,从而保证在最后提交的 prewrite 阶段不会出现写写冲突的情况。
原先Percolator的DML语句只是缓存在内存里,直到Prewrite阶段才会进行冲突检测和加锁:
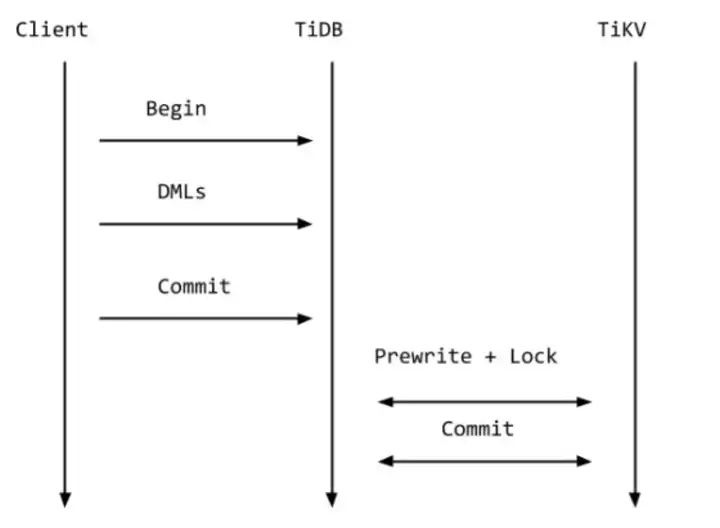
对于乐观锁的实现,TiDB官方描述如下:在悲观事务模型下,DML语句在最开始就必须进行冲突检测和加锁,这里的悲观锁的格式和乐观事务中的锁几乎一致,但是锁的内容是空的,只是一个占位符,待到 Commit 的时候,直接将这些悲观锁改写成标准的 Percolator 模型的锁,后续流程和原来保持一致即可。对于读请求,遇到这类悲观锁的时候,不用像乐观事务那样等待解锁,可以直接返回最新的数据即可(至于为什么,读者可以仔细想想)。
我的想法是:
在乐观模型下,Read看到锁必须等待是因为,Read不能确定是否会有一个commit_ts小于它start_ts的事务,会在它读取之后提交。
但在悲观模型下,Read看到的lock列可能只是一个占位符,也可能是Percolator模型的锁。如果是一个占位符的话,那表示此时该事务的commit_ts必定还没有获取,所以无需等待该事务。如果是Percolator模型的锁的话,则还需要像原本一样处理。
为了避免悲观事务模型引入的死锁,TiDB实现了一个死锁检测机制。事务1对A上了锁后,如果另外一个事务2对A进行等待,那么就会产生一个依赖关系:事务2依赖事务1,如果此时事务1打算去等待B(假设此时事务2已经持有了B的锁),那么死锁检测模块就会发现一个循环依赖,然后中止(或者重试)这个事务就好了,因为这个事务并没有实际的prewrite和commit,所以这个代价是比较小的。
总结
Percolator基于BigTable单行事务实现的分布式事务,其实是一个乐观事务模型。只有在事务提交时,才会检测写-写冲突。Percolator事务模型的优点在于原理简单方便理解,不再需要一个中心化的单独Coordinator,而是把Coordinator角色的职责进行细分,把能持久化的部分交给BigTable处理,后续也不再依赖Client的恢复。但它的缺点也是显而易见的:Client和BigTable之间的RPC、BigTable和ChunkServer之间的RPC都会比较耗费网络资源。TSO是一个中心化的点。并发事务很多的时候,会占用很多内存。并发大事务可能会频繁冲突,而重试有可能会导致雪崩效应(这时候就用悲观事务模型会更好)。懒处理事务crash导致一个事务的延迟可能会比较高。
不过Percolator论文只是指明了大的方向,很多细节应该也还是存在优化空间的。
彩蛋
在Percolator中,start_ts在事务最开始的时候获取,而Snapshot Isolation隔离级别决定了该事务只能看到commit_ts先于start_ts的事务的修改。
于是对于TiDB来说,下面2个并行的事务,T2能看到的记录只有5行,因为它的start_ts早与T1的commit_ts。
但是对于MySQL来说,它能看到6行。因为它的start_ts开始于第一条SQL语句执行的那一刻。
| T1 | T2 |
| Begin | |
| select count(*); -> 5 | Begin |
| insert; | |
| select count(*); MySQL -> 6 TiDB -> 5 |
|
| commit; | |
| commit |
| T1 | T2 |
| Begin | |
| select count(*); -> 5 | Begin |
| insert; | |
| select count(*); MySQL -> 6 TiDB -> 5 |
|
| commit; | |
| commit |
| T1 | T2 |
| Begin | |
| select count(*); -> 5 | Begin |
| insert; | |
| select count(*); MySQL -> 6 TiDB -> 5 |
|
| commit; | |
| commit |
| T1 | T2 |
| Begin | |
| select count(*); -> 5 | Begin |
| insert; | |
| select count(*); MySQL -> 6 TiDB -> 5 |
|
| commit; | |
| commit |
| T1 | T2 |
| Begin | |
| select count(*); -> 5 | Begin |
| insert; | |
| select count(*); MySQL -> 6 TiDB -> 5 |
|
| commit; | |
| commit |
| T1 | T2 |
| Begin | |
| select count(*); -> 5 | Begin |
| insert; | |
| select count(*); MySQL -> 6 TiDB -> 5 |
|
| commit; | |
| commit |
| T1 | T2 |
| Begin | |
| select count(*); -> 5 | Begin |
| insert; | |
| select count(*); MySQL -> 6 TiDB -> 5 |
|
| commit; | |
| commit |
| T1 | T2 |
| Begin | |
| select count(*); -> 5 | Begin |
| insert; | |
| select count(*); MySQL -> 6 TiDB -> 5 |
|
| commit; | |
| commit |
| T1 | T2 |
| Begin | |
| select count(*); -> 5 | Begin |
| insert; | |
| select count(*); MySQL -> 6 TiDB -> 5 |
|
| commit; | |
| commit |
参考资料
Large-scale Incremental Processing Using Distributed Transactions and Notifications
Bigtable: A Distributed Storage System for Structured Data