https://book.tidb.io/session2/chapter2/lightning-internal.html复制
TiDB Lightning 工具支持高速导入 Mydumper 和 CSV 文件格式的数据文件到 TiDB 集群,导入速度可达每小时 300 GB,是传统 SQL 导入方式的 3 倍多。它有两个主要的目标使用场景:大量新数据的快速导入,以及全量数据恢复。
本节将介绍 TiDB Lightning 工具的工作原理。
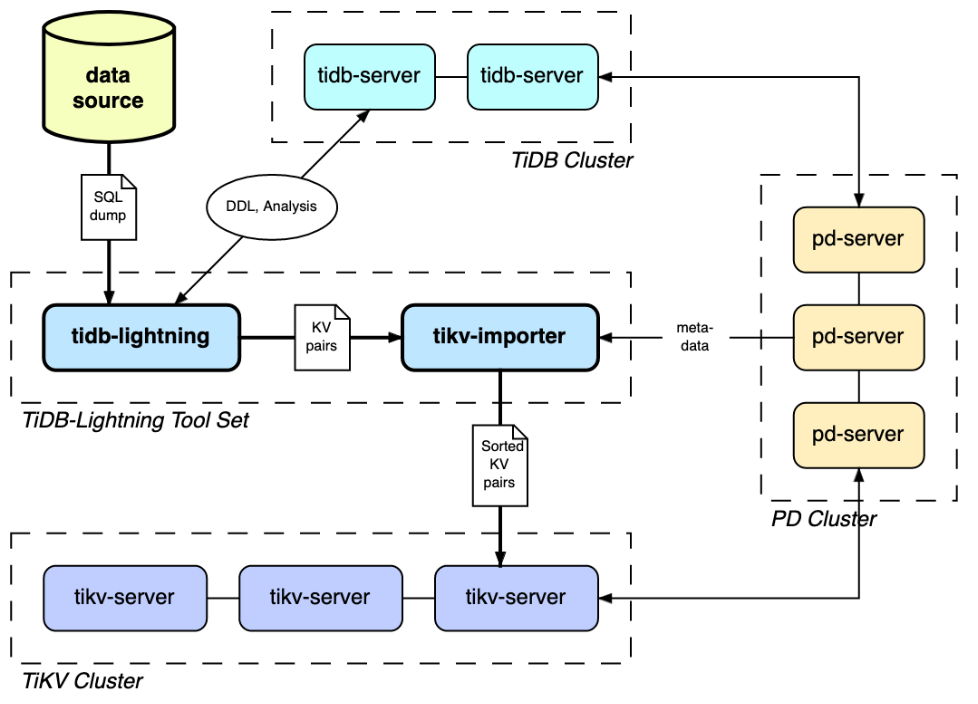
如上图所示,TiDB Lightning 工具包含两个组件:
那么,为什么要把一个流程拆分成两个组件呢?
总体而言,TiDB Lightning 工具的设计思路是,绕过 SQL 层,在线下将数据文件转化为键值对,并生成排好序的 SST 文件,直接推送到 TiKV 层的 RocksDB 里。这种批处理方式可以绕过 TiDB 层复杂的 SQL 和 事务处理,省却 TiKV 层线上排序等耗时步骤,提升数据导入过程的整体效率。
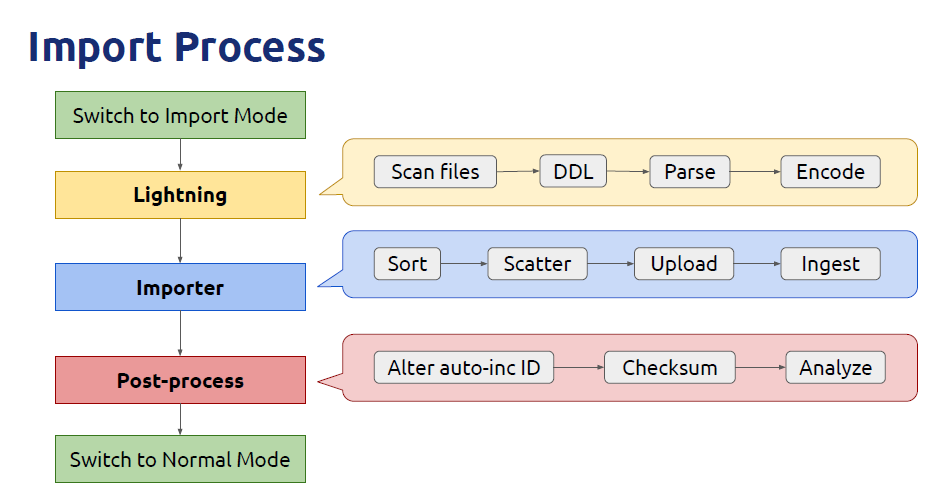
ANALYZE TABLE 命令更新表和索引的统计信息,为后续 TiDB 生成正确的 SQL 执行计划做好准备。同时,tidb-lightning 会调整表的 AUTO_INCREMENT 值防止后续新增数据时发生冲突。表的自增 ID 是通过行数的上界估计值得到的,与表的数据文件总大小成正比。因此,最后的自增 ID 通常比实际行数大得多。考虑到 TiDB 中自增 ID 不一定是连续分配的,这种状况是可接受的。一旦目标 TiKV 集群切换到导入模式,整个数据导入阶段该集群将被 tidb-lightning 独占,无法对外提供正常服务。tidb-lightning 会修改下列集群配置以提高数据导入速度:
write stall triggers,使写速度优先于读速度。数据导入完成后,tidb-lightning 会自动把 TiKV 集群切换回“普通模式”。
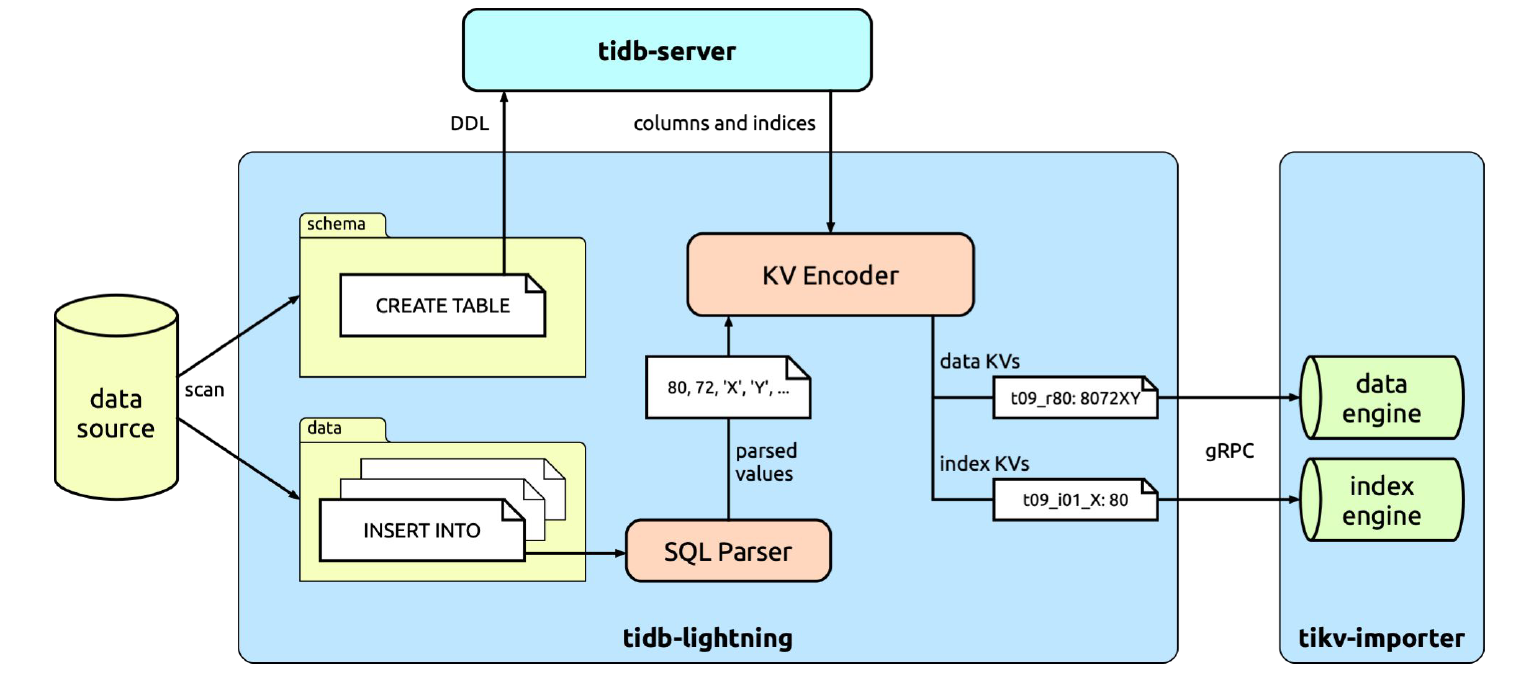
tidb-lightning 会扫描数据文件,区分出结构文件(包含 CREATE TABLE 语句)和数据文件(包含 INSERT 语句)。结构文件的内容会直接发送到 TiDB,用于建立数据库和表。然后,tidb-lightning 会并发处理数据文件。这里,我们来具体看一下一张表的导入处理过程。
每张表的数据文件内容都是规律的 INSERT 语句,如下所示:
INSERT INTO `tbl` VALUES (1, 2, 3), (4, 5, 6), (7, 8, 9);
INSERT INTO `tbl` VALUES (10, 11, 12), (13, 14, 15), (16, 17, 18);
INSERT INTO `tbl` VALUES (19, 20, 21), (22, 23, 24), (25, 26, 27);
复制tidb-lightning 会找出每一行的位置,并分配一个行号,这样即使没有定义主键的表也能够区分每一行。tidb-lightning 会直接借助 TiDB 实例把 SQL 转换为键值对,称为“键值编码器”(KV encoder)。与外部的 TiDB 集群不同,键值编码器是寄存在 tidb-lightning 进程内的,并使用内存存储;每执行完一个 INSERT 之后,tidb-lightning 可以直接读取内存获取转换后的键值对(这些键值对包含数据及索引),并发送到 tikv-importer。
tidb-lightning 把数据文件拆分成多个能并发执行的小任务。下面的配置选项可以帮助调节这些任务的并发度:
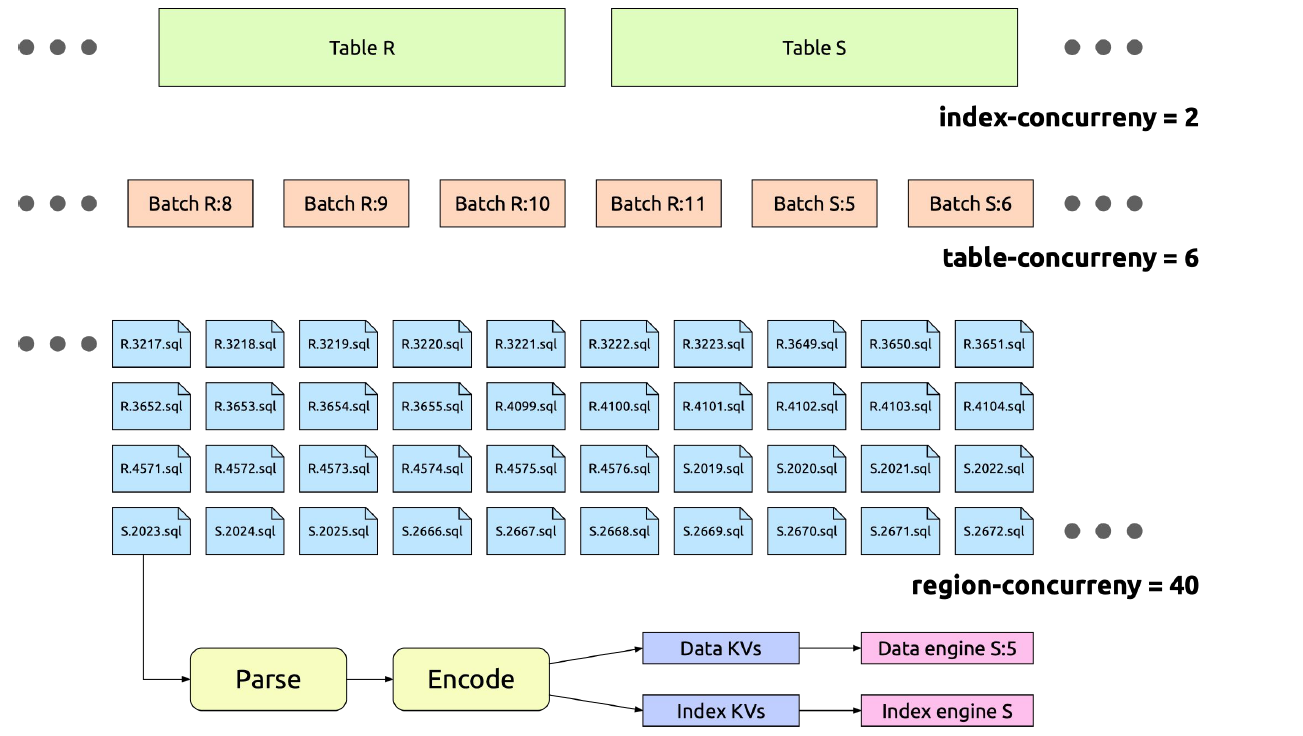
batch-size:对于很大的表,比如超过 5 TB 的表,如果一次性导入,可能会因为 tikv-importer 磁盘空间不足导致失败。tidb-lightning 会按照 batch-size 的配置对一个大表进行切分,导入过程中每个批次使用单独的引擎文件。batch-size 不应该小于 100 GB,太小的话会使 region balance 和 leader balance 值升高,导致 Region 在 TiKV 不同节点之间频繁调度,浪费网络资源。
table-concurrency:同时导入的批次个数。如上所述,每个表会按照 batch-size 切分成多个批次。
index-concurrency:并行的索引引擎文件个数。table-concurrency + index-concurrency 的总和必须小于 tikv-importer 的 max-open-engines 配置。
io-concurrency:并发访问磁盘的 I/O 线程数。由于磁盘内部缓存容量有限,过高的并发度容易引发频繁的 cache miss,导致 I/O 延迟增大。因此,不建议将该值调整得太大。
block-size:默认值为 64 KB。tidb-lightning 会一次性读取一个 block-size 大小的数据文件,然后进行编码。
region-concurrency:每个批次的内部线程数。每个线程要执行读文件、编码和发送到 tikv-importer 等步骤。
io-concurrency 控制并发读取。region-conconcurrency 配置。block-size 为 64 KB,则单一 CPU 核每秒最多完成 1.28 MB 数据的编码处理。当 region-concurrency 设置为 60,则整体编码处理的极限速度约为每秒 75 MB。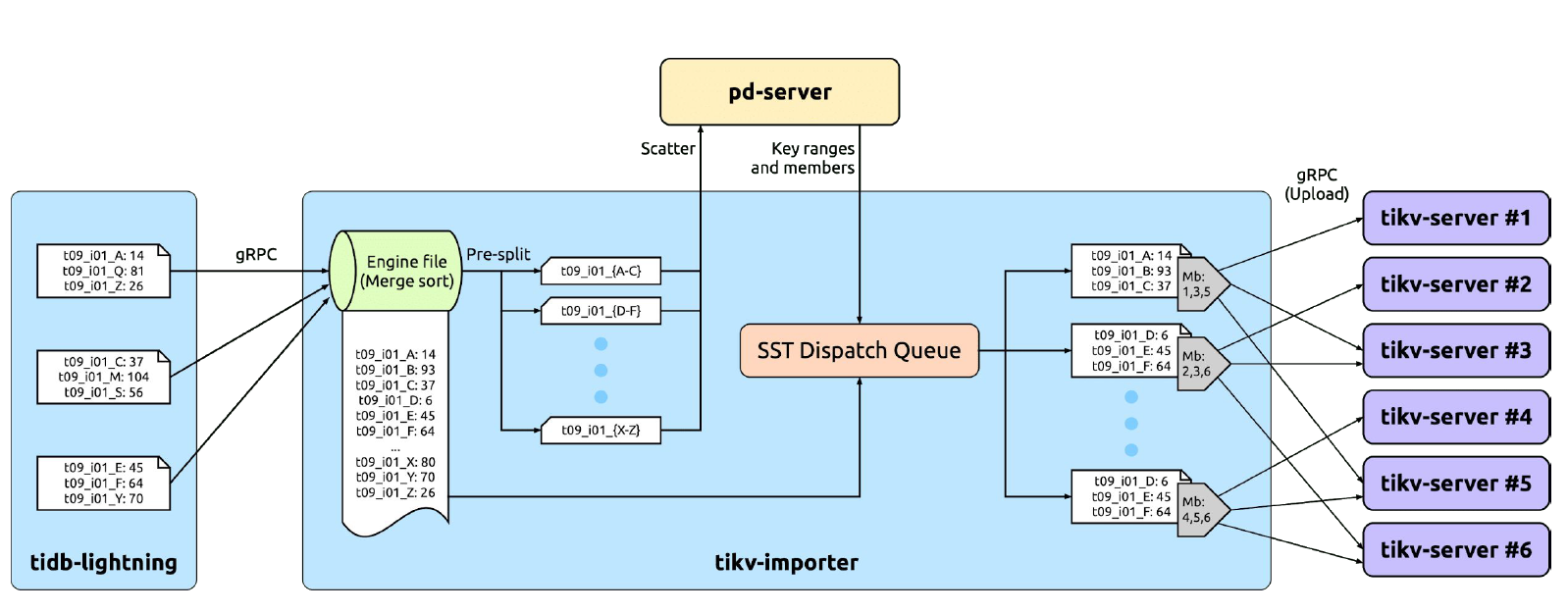
因异步操作的缘故,tikv-importer 得到的原始键值对注定是无序的。所以,tikv-importer 要做的第一件事就是要排序。这需要给每个表划定准备排序的储存空间,我们称之为引擎文件。
对大数据排序是个解决了很多遍的问题,我们在此使用现有的答案:直接使用 RocksDB。一个引擎文件就相等于一个本地 RocksDB,并大量写入操作做了配置上的优化。排序就相当于将键值对全部写入到引擎文件里,然后 RocksDB 就会自动帮我们合并、排序,最终得到 SST 格式的文件。
SST 文件包含整个表的数据和索引,和 TiKV 的储存单位 Region 比起来实在太大了。所以接下来要切分成合适的大小(默认为 96 MB)。tikv-importer 会根据要导入的数据范围预先把 Region 分裂好,然后借助 PD 把这些分裂出来的 Region 分散调度到不同的 TiKV 实例上。
最后,tikv-importer 将 SST 上传到对应 Region 的每个副本上,通过 Leader 发起 Ingest 命令,把 SST 文件导入到 Raft group 里。这样就完成了一个 Region 的导入过程。
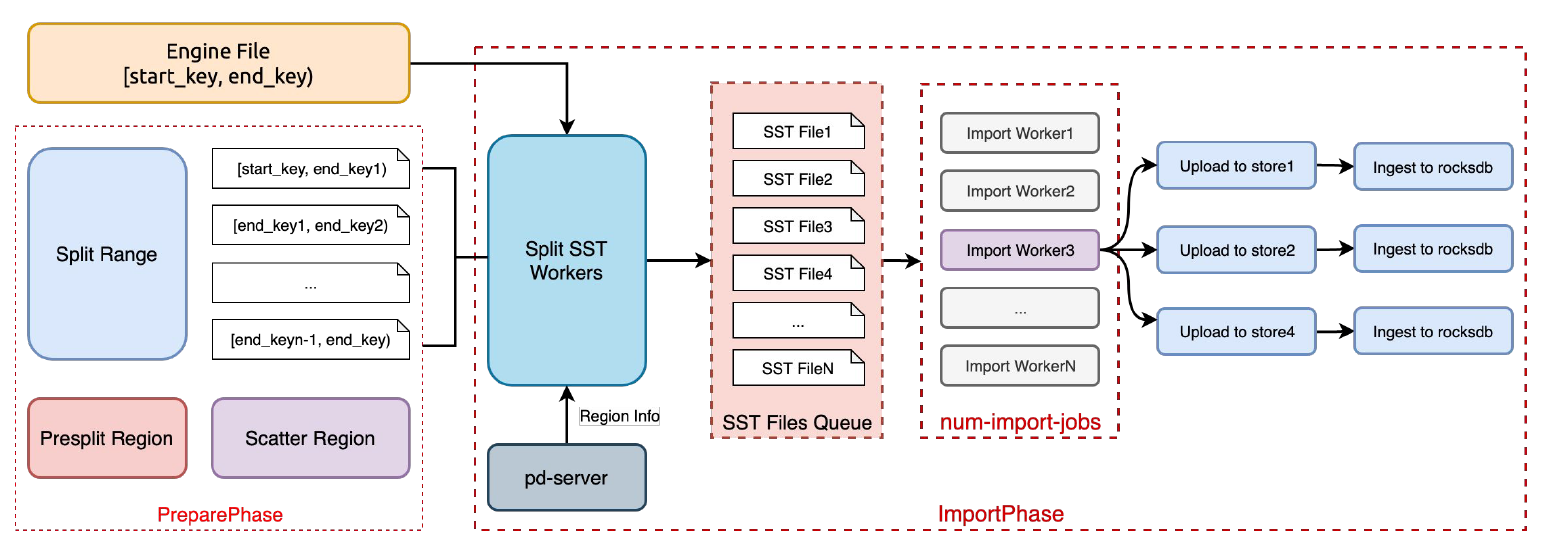
max-open-engines:表示 tikv-importer 上可以同时打开的最大引擎文件数量。如果运行单个 tidb-lightning 实例,该配置不应小于 tidb-lightning 的 index-concurrency + table-concurreny;多个 Lightning 实例并行运行的状况下,不能小于所有实例的 index-concurrency + table-concurreny 总和。请注意,引擎文件会消耗磁盘空间,需要根据 tikv-importer 节点的磁盘容量合理配置本参数。一个数据引擎文件的磁盘空间占用等于 tidb-lightning 中 batch-size 大小;索引引擎文件的大小可参考后面”量化指标“一节提供的思路进行估算。num-import-jobs:一个 batch-size 大小的数据写入到引擎文件后,会有若干个线程负责将其导入 TiKV。这个参数控制同时进行导入的线程数量,通常使用默认配置即可。region-split-size:一个引擎文件可能会很大(比如 100 GB),很难一次性导入到 TiKV。需要把引擎文件切分成多个较小的 SST 文件,SST 文件不会超过region-split-size 值。通常,不建议低于 96 MB,因为SST 切分过小会导致 Ingest 的吞吐量小。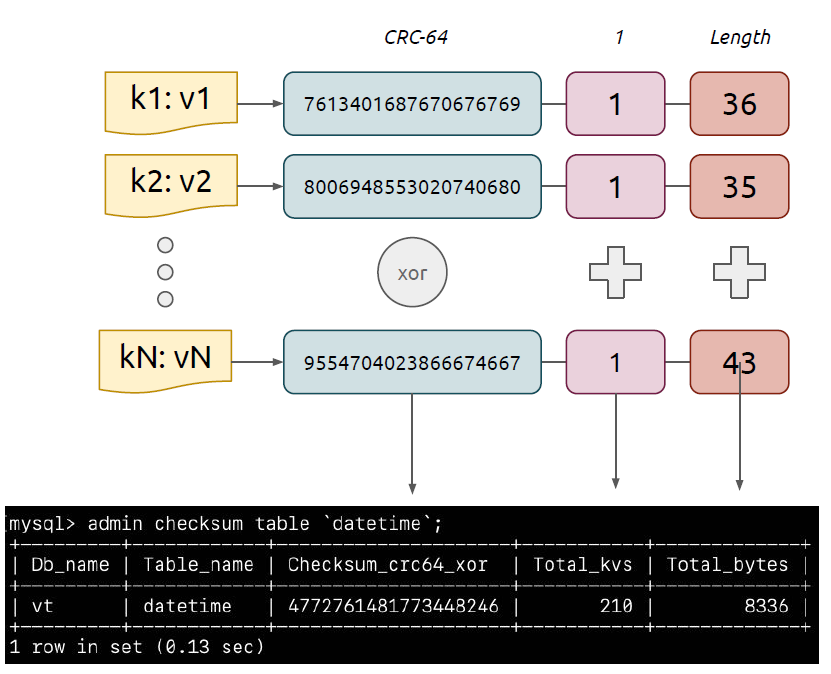
完成数据导入后会自动执行数据校验以确保数据完整性。tidb-lightning 会在每个表完成导入后,对比导入前后的 Checksum 确认二者是否一致。
一个表的 Checksum 是透过计算键值对的哈希值产生的。因为键值对分布在不同的 TiKV 实例上,这个 Checksum 函数应该具备结合性;另外,tidb-lightning 传送键值对之前它们是无序的,所以 Checksum 也不应该考虑顺序,即服从交换律。也就是说, Checksum 计算并不是简单地针对整个 SST 文件计算 SHA-256。
我们的解决办法是这样的:先计算每个键值对的 CRC64,然后用 XOR 结合在一起,得出一个 64 位元的校验数字。为降低 Checksum 值冲突的概率,我们同时会计算键值对的数量和大小。在下面两个地方分别计算来比对表中 3 个指标的和:
ADMIN CHECKSUM TABLE `xxxx`;
复制数据校验结束后,tidb-lightning 会重新计算表的统计信息,并更新表的自增值:
ANALYZE TABLE `xxxx`;
ALTER TABLE `xxxx` AUTO_INCREMENT=123456;
复制数据导入开始前须确保以下两点:
一个表只能接受一个 tidb-lightning 实例导入,多个 tidb-lightning 实例不能同时导入数据到同一张表。同一个数据文件若需要使用多个 tidb-lightning 实例并行导入,应该修改白名单配置以确保一个表只接受一个 tidb-lightning 实例导入。
下面给出的一些公式和计算方法可以帮助我们计算数据导入过程中的资源使用量。 这里,我们假定 tidb-lightning 和 tikv-importer 之间的交互过程不是性能瓶颈所在。
假定 tikv-importer 节点使用万兆网卡(理论带宽上限为 10 gbps),则编码速度最高达到每秒 300 MB 时就会耗尽全部带宽。这就是使用 TiDB Lightning 工具导入数据的理论上限速度。
max-speed = bandwidth (1.2 GB/s) / replicas (3)
复制tidb-lightning 的内存占用很低,几乎可以忽略;tikv-importer 的内存占用取决于引擎文件个数和导入线程数。
ram-usage = (max-open-engines (8) × write-buffer-size (1 GB) × 2)
+ (num-import-jobs (24) × region-split-size (512 MB) × 2)
复制tikv-importer 的磁盘空间使用量基本上取决于最大的 N 个表, 其中 N = max(index-concurrency, table-concurrency)。实际的磁盘空间使用量还和这些表的索引数量以及索引字段构成相关。假定需要导入 20 张表,其中有一张 5 TB 的大表。考虑到该表的索引键值对需要在 tikv-importer 上先进行全量排序后再上传到 TiKV 中,所以需要保证 tikv-importer 的本地磁盘空间至少可以保存对应的索引引擎文件。索引引擎文件在磁盘上的大小主要由表结构里的索引数量决定;当然,如果索引中的字段以整数类型为主,则索引引擎文件会更小一些。这里提供一个经验值:一个包含 5 个索引、体积为 4 TB 的表,对应的索引引擎文件体积约为 2 TB。
一般而言,目标 TiKV 集群的磁盘容量可以按照数据文件体积的 4 倍来估算。例如,数据文件体积为 5 TB,则目标 TiKV 集群至少要预留 20 TB 可用空间。如果单表内重复数据较多,最终 TiKV 的压缩比也会较大,则相应地容量要求会降低。