https://zhuanlan.zhihu.com/p/437657452复制
1993年,Intel公司推出了奔腾处理器,该类型处理器拥有两条执行流水线,和当时的处理器相比,可以同时执行两条指令,实现超标量性能。1996年,P6系列处理器中的奔腾II处理器引入了英特尔MMX技术,这是是最早的SIMD扩展指令。后续又相继推出了SSE、SSE2、SSE3、SSSE3和SSE4指令。2008年,Intel公司宣布将推出全新的Sandy Bridge微架构,并将引入AVX指令集。此后,Intel公司相继推出了AVX2和AVX512指令集扩展。
MMX技术定义了一种简单灵活的SIMD执行模型,可以用来处理64位的打包数据,该模型为IA-32架构增加了以下功能,同时保持与所有IA-32应用程序和操作系统代码的向后兼容性:
SSE扩展增强了SIMD执行模型,主要是通过增加了128位的XMM寄存器,实现支持128位的向量处理能力。高级矢量扩展(AVX)在XMM寄存器基础上将寄存器扩展到256位,引入了256位的向量处理能力。AVX指令集接口直接映射到AVX指令集和其他的增强的128位单指令多数据指令。AVX指令在架构上和SSE系列指令相似,不过AVX提供了超越前几代128位SIMD扩展的若干增强特性,主要包括下面几点:
大多数的AVX指令的命名格式如下所示:
命名中的各个条目说明如下:

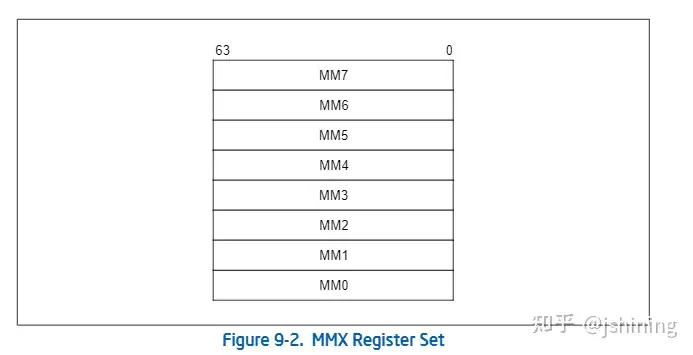
MMX指令使用的是64位MMX寄存器,如下图所示:
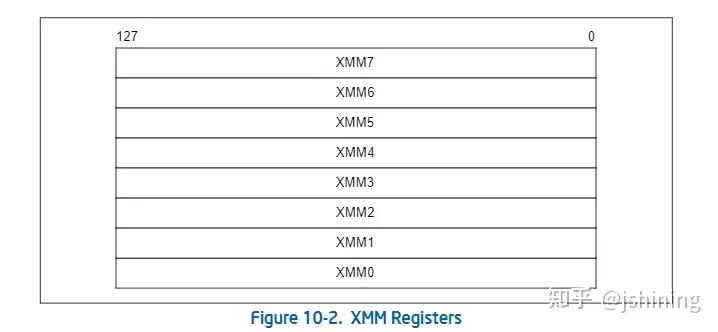
SSE扩展中新增的XMM寄存器如下所示:
AVX包含16个256位宽的YMM寄存器(YMM0-YMM15)YMM寄存器的低128位可称为XMM寄存器。寄存器的结构如下图所示:

AVX扩展中的寄存器使用三种C语言类型的数据结构作为操作数的类型,如下所示:
除了常见的加法、减法和乘法等算术运算,AVX还支持很多其他指令,包括位运算指令、比较指令、加载存储指令、类型转换指令等。这里取部分难懂的指令说明其用法。
shuffle系列指令的一种格式是_mm256_shuffle_epi8,该指令语法如下图所示:
具体功能是将寄存器按照128位分区,对分区内的元素按照索引进行重排,图示如下:

permute系列指令的一种格式是_mm256_permute4x64_epi64,指令语法如下图所示:
实现的功能是根据imm8将新向量赋值。

broadcast系列指令的一种格式是_mm_broadcastb_epi8,指令语法如下图所示:
功能是将输入向量最低位赋值到输出向量,如下图所示:
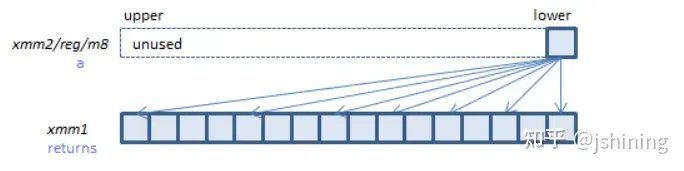
blend系列指令的一种格式是_mm256_blendv_epi8,指令语法如下图所示:
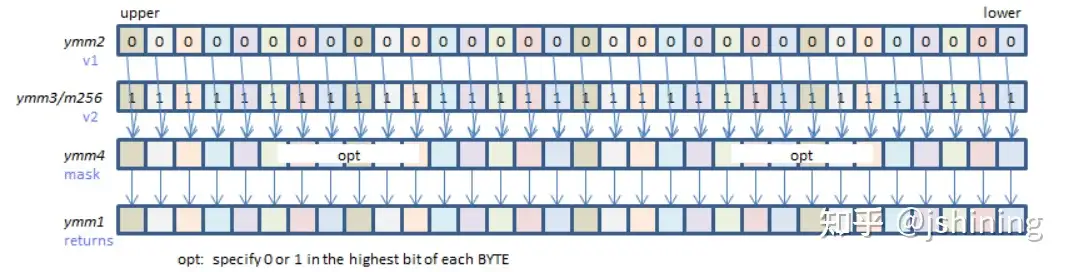
功能是按照mask元素最高位的0或1标签将a或b中的元素填充到输出向量中,如下图所示:
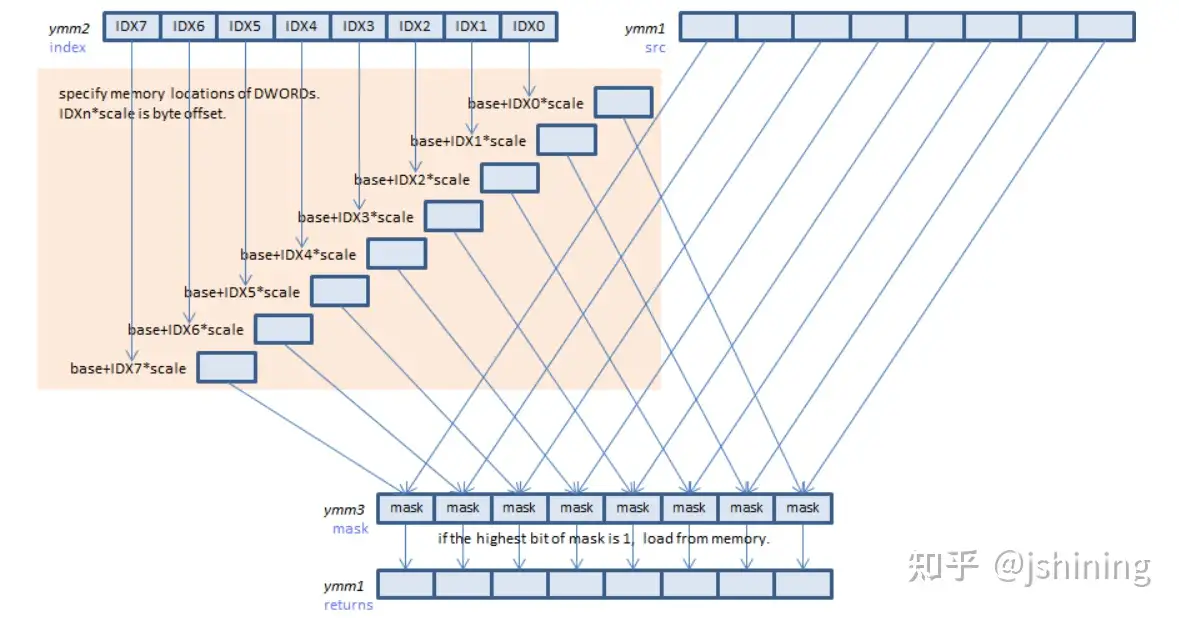
gather系列指令的一种格式是_mm256_i32gather_epi64,指令语法如下图所示:
功能是按照索引向量从指定地址加载数据,scale指定值范围是1、2、4、8。功能图如下所示:
以上就是intel指令集中较为复杂的指令的简单介绍,详细使用可参见官网相关文档。
Intel指令集的方便之处就是可在Windows平台验证,借用VS即可验证每个指令的功能。本文档只是简单介绍其发展和基本指令。