https://zhuanlan.zhihu.com/p/103968892复制
LSM-Tree (Log Structured Merge Tree),日志结构合并树。它在 1996 年由论文《The Log-Structured Merge-Tree (LSM-Tree) 》[1]首次提出,但真正得到广泛应用是在 2006 年Google Bigtable 论文之后,论文中提到 Bigtable 使用的数据结构就是 LSM-Tree。
目前,LSM-Tree 已经被广泛应用于一些流行的的 Key-Value 型存储引擎中,如 Bigtable、Cassandra、HBase、RocksDB[2]、LevelDB、ScyllaDB[3]等。LSM 已经成为基于磁盘的 Key-Value 型存储引擎的标配。
我们知道,磁盘的顺序读写性能要比随机读写性能高2个数量级以上。日志结构指的就是日志形式的追加写(Append Only),它是顺序写。
LSM-Tree 相比于传统的 B+ 树存储引擎,具有更高的写入性能。通过把磁盘随机写转换为顺序写,来大幅提升写入性能。代价是,牺牲了部分读性能及写放大问题。这么说,并不是说 B+ 树不存在写放大,它实际也存在写放大问题。我们稍后再研究这个问题。
我们先看看原始论文中描述的 LSM-Tree 结构,再看看实际存储引擎中的实现。
LSM-Tree 由两个或甚至更多的分层数据结构组成[1]。一种比较简单的两层 LSM-Tree 结构如下[1]:
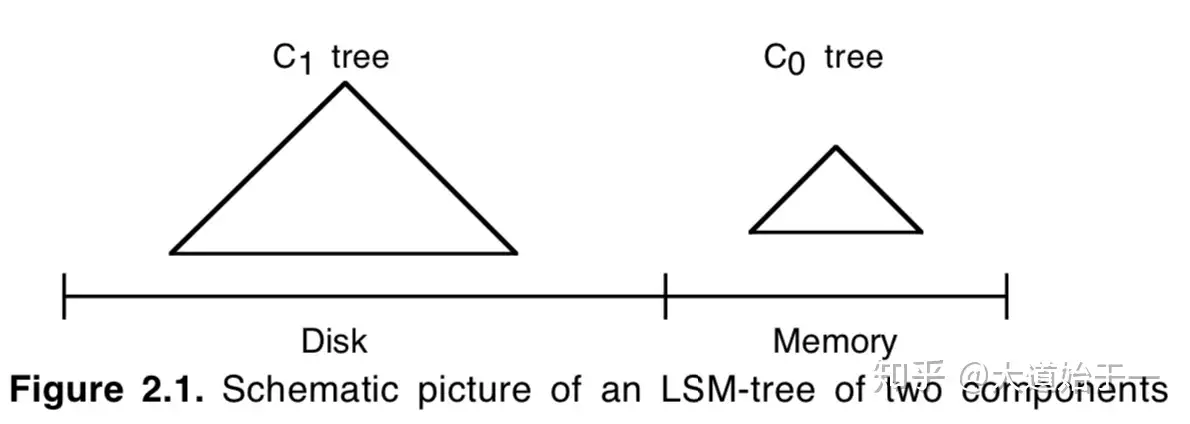
图中,C0 层常驻内存。 C1 层在磁盘上。C0 层保存最近更新的索引项,通常可以使用红黑树、跳表、B 树等实现。当插入操作导致 C0 的大小达到一定的阈值之后,它会与 C1 合并到磁盘上。LSM树的性能源于这样一个事实,即每个组件都根据其底层存储介质的特性进行了调优,并且使用一种类似于归并排序的算法,以滚动批次的方式有效地跨介质合并数据[1]。
多层 LSM-Tree 结构如下:
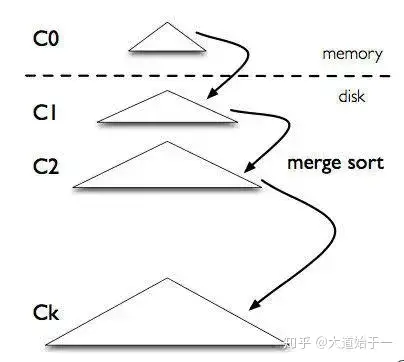
C0 层常驻内存,保存了所有最近写入的 Key-Value,这个内存结构是有序的,并且可以随时原地更新,同时支持随时查询。C1 ~ Ck 层都在磁盘上,每一层都是一个在 key 上有序的结构。
写请求首先被写入 WAL(Write Ahead Log)日志(通常用于故障恢复),再写入 C0,如果 C0 大小达到阈值,就会把 C0 层与 C1 层合并写入新的 new-C1,类似于归并算法,这个过程就是合并(Compaction)。合并的 new-C1 顺序写入磁盘。同理,C1 达到一定阈值之后,会与下层 C2 合并,依次逐层合并。合并过程可以异步进行,这样不用阻塞写操作。
由写入可以知道,最新的数据在 C0 层,最旧的数据在 Ck 层。查询指定的 key 时,会先查 C0 再查 C1,最后查 Ck。所以,LSM-Tree 对读不太友好,也就是存在读放大。
原始论文中,在磁盘上使用类 B 树来组织文件。但是实际系统,大多采用
来组织文件。
下面以经典的 LevelDB[4]为例,看一下 LSM-Tree 的实际实现。
LevelDB LSM-Tree 结构如下图所示。LSM-Tree 由三个数据结构组成:内存表分为 Memtable 和 ImmutableTable,磁盘上的 SSTable 文件。
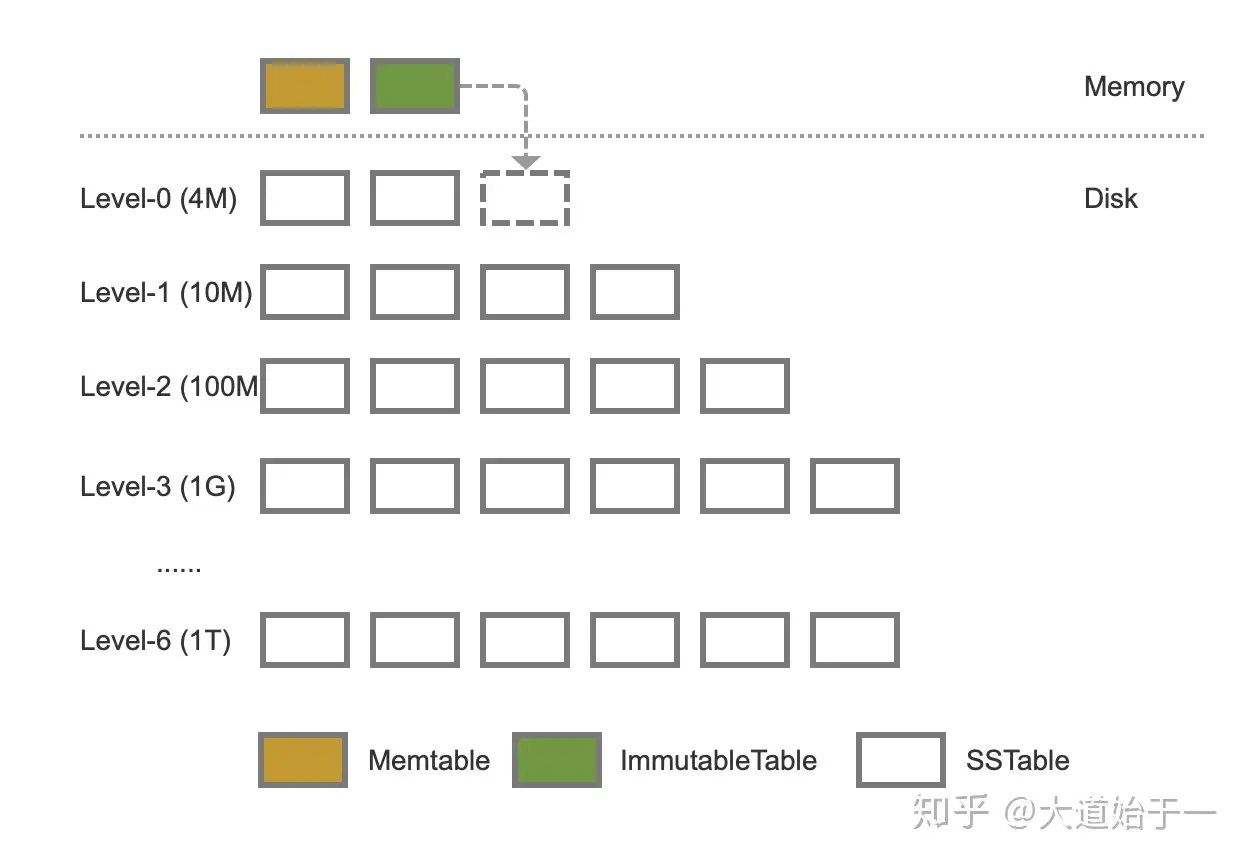
内存表:
SSTable 文件:
实际上,LevelDB 在写 Memtable 之前,会先写 log 文件(大小也为 4MB,它并不是无限增长),log 文件以日志追加(Append Only)的方式保存最近的更新,Memtable 相当于 log 的副本,log 文件可用于故障恢复。LevelDB 官方文档有几处混淆不清,比如 Level-0 层的 SSTable 文件并不是由 log 文件直接转换而来,而是由 Memtable 写入,不然如何保证 SSTable 文件中键的顺序。
SSTable 文件存储按 Key 排序的条目(Entry),每一个 Entry 是 Key-Value 对或指定 Key 的删除标记(Deletion Marker)。
当 Level-0 文件个数超出指定阈值(默认 4 个,每个 1MB 大小)时,将所有 Level-0 的 SSTable 文件 与 Level-1 有交集的 SSTable 文件进行合并,然后生成新的 Level-1 SSTable 文件(每 2MB 生成一个新 SSTable)。
Level-0 层 SSTable 的 key range 会存在重叠。原因是,Level-0 的 SSTable 文件由 ImmutableTable 直接生成,但是不同的 ImmutableTable 之间没办法保证 key 不重叠。
对于 Level-i (i > 0) 层,每一层的大小超过 10� MB(Level-1 层 10MB,Level-2层 100MB...)时,选择 Level-i 层中的一个 SSTable 文件与 Level-(i+1) 层所有存在交集的 SSTable 文件进行合并,生成新的 Level-(i+1) 层 SSTable 文件(有交集的文件不超过 10 个),合并完成之后,丢弃掉旧的 SSTable 文件(包括 Level-i 层和 Level-(i+1) 层的)。合并过程中,会处理删除和覆盖旧值的情况。
在合并过程中,有两种情况会触发生成一个新的 SSTable 文件:
对于合并性能,我们看下官方文档中对性能的描述。
对于进行 Level-0 合并时,最多从 Level-0 读取 4 个 1MB 大小的文件,以及最坏情况下从 Level-1 层读取 10MB 大小。那么读是 14MB,写也是 14MB。
对于 Level-i (i > 0) 合并时,会从 Level-i 层选择一个 2MB 大小的文件,以及最坏情况下从Level-(i+1) 层选择 12 个 2MB大小的文件,其中 10 个是因为上下层最多重叠10个文件,额外2个文件是由于上下两层文件边界往往不对齐导致的。那么读是 26MB,写也是26MB。
假设磁盘 IO 速率为 100MB/s (现代驱动器的大致范围),最坏的情况下合并成本大约为 0.5s。如果限制一下写入磁盘速率到 10%,那么合并可能需要 5s。又或者用户以 10MB/s 的速率写入 Memtable,那么 Level-0 每秒需要大约 50 个 1MB的文件,Level-1 则需要生成 5 个(5 x 10MB)文件,这势必会大大增加 Compaction 的代价。
如果我们将后台写入限制为很小的值,比如100MB/s速度的10%,那么压缩可能需要5秒。如果用户以10MB/s的速度写入,我们可能会构建许多0级文件(~50来容纳5*10MB)。由于每次读取时合并更多文件的开销,这可能会显著增加读取的成本。
LSM-Tree 虽然写入性能很好,但也存在一些问题。
Write Amplification (WA),写放大是指实际写的数据量大于用户需要的数据量。写放大是由于合并引起的。
写放大是 LevelDB 的硬伤,RocksDB 通过把参数 10 变成动态可调来缓解写放大问题。
写放大会降低 Flash 磁盘(SSD)的寿命。
Read Amplification (RA),读放是指实际读的数据量大于用户需要的数据量。LevelDB 查询数据时,会按照数据新鲜读排序,依次从 Memtable > ImmutableTable > L0 > L1 > ...中查询,尤其是查询的 key 不存在时,会导致每次都会查询到最后一层。一般结合布隆过滤器 (bool filter) 来降低读放大问题。
所有的写入都是顺序写 (Append-Only) 的,不是原地更新 (in-place update) ,所以过期数据不会马上被清理掉。LSM-Tree 是通过合并来减少空间放大,但是引入了写放大问题。
由于本人的理解能力有限,如理解有误,请大家多多指正。