https://zhuanlan.zhihu.com/p/621480049复制
ClickHouse是一种OLAP类型的列式数据库管理系统,这里有两个概念:OLAP、列式数据库。这两个概念会在接下来做介绍,ClickHouse完美的实现了OLAP和列式数据库的优势,因此在大数据量的分析处理应用中Clickhouse表现很优秀。
国内阿里云在全托管服务上使用ck、思科在流量分析上使用ck、虎牙在视频流的分析上使用ck、腾讯在通讯的日志记录上和大数据的数据处理上使用ck、喜马拉雅在音频共享上使用ck,还有更多的国内外厂商开始使用ck。
clickhouse在官方文档https://clickhouse.com/docs/en/intro/上有一些教程文档。
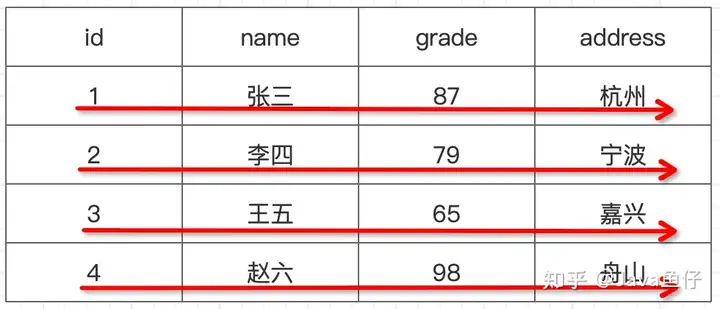
在传统的行式数据库中,数据在数据库中都会按行存储,常见的MySQL、Oracle、SQL Server等数据库都是行式数据库。行式数据库的存储方式如下
在列式数据库中,数据是以列进行存储的,列式数据库更适合于OLAP场景,常见的列式数据库有hbase、clickhouse、Vertica等。列式数据库的存储方式如下
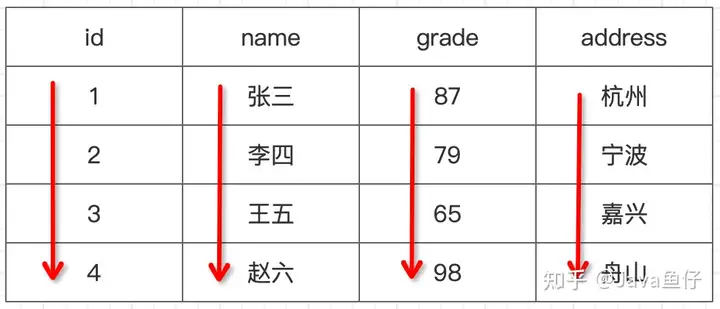
不同的存储结构适用于不同的业务场景,列式数据库适合数据分析类型的场景,比如上面的例子中要统计成绩的中位数,在行数据库中,需要将四行数据都遍历出来,取出成绩;而在列式数据库中,只需要将成绩这一列的数据取出来就可以进行分析计算。
列式数据库的优势如下;
1、针对分析类查询,通常只需要读取表的一小部分列。在列式数据库中你可以只读取你需要的数据。例如,如果只需要读取100列中的5列,这将帮助你最少减少20倍的I/O消耗。
2、由于数据总是打包成批量读取的,所以压缩是非常容易的。同时数据按列分别存储这也更容易压缩。这进一步降低了I/O的体积。
3、由于I/O的降低,这将帮助更多的数据被系统缓存。
OLAP和OLTP是针对不同场景的两种数据库实现。有关OLAP和OLTP的介绍可以讲好几个小时,简单来讲: OLTP全称是On-line Transaction Processing,是一种联机事务型数据库,典型的数据库就是关系型数据库,OLTP关注的是对业务数据的增删改查,面向用户的事务操作,追求效率的最优解。但是遇到需要对数据进行分析的场景,OLTP类型的数据库就不占优势了。
OLAP全称是On-Line Analytical Processing,是一种联机分析处理数据库,一般用于数据仓库或者大数据分析处理,这种类型的数据库在事务能力上很弱,但是在分析的场景下很强大。
OLAP型数据库有一些关键性的场景:
1、绝大多数是读请求
2、数据以相当大的批次(> 1000行)更新,而不是单行更新;或者根本没有更新。
3、已添加到数据库的数据不能修改。
4、对于读取,从数据库中提取相当多的行,但只提取列的一小部分。
5、宽表,即每个表包含着大量的列
6、查询相对较少(通常每台服务器每秒查询数百次或更少)
7、对于简单查询,允许延迟大约50毫秒
8、列中的数据相对较小:数字和短字符串(例如,每个URL 60个字节)
9、处理单个查询时需要高吞吐量(每台服务器每秒可达数十亿行)
10、事务不是必须的
11、对数据一致性要求低
12、每个查询有一个大表。除了他以外,其他的都很小。
13、查询结果明显小于源数据。换句话说,数据经过过滤或聚合,因此结果适合于单个服务器的RAM中
从官网中,我们可以整理出ClickHouse的特性,或者说ClickHouse的优点。
1、真正的列式数据库管理系统
2、优秀的数据压缩能力
3、数据的磁盘存储,降低设备预算
4、多核心并行处理,ClickHouse会使用服务器上一切可用的资源,从而以最自然的方式并行处理大型查询。
5、多服务器分布式处理
6、支持SQL,降低学习成本
7、向量引擎,数据不仅仅按列存储,同时还按向量(列的一部分)进行处理,这样可以更加高效地使用CPU。
8、实时的数据更新,数据可以持续不断地高效的写入到表中,并且写入的过程中不会存在任何加锁的行为。
9、索引,按照主键对数据进行排序,这将帮助ClickHouse在几十毫秒以内完成对数据特定值或范围的查找。
10、适合在线查询
11、支持近似计算
12、自适应的join算法,JOIN多个表,它更倾向于散列连接算法,如果有多个大表,则使用合并-连接算法。
13、支持数据复制和数据完整性
14、角色的访问控制。
ClickHouse的缺点在于:
1、没有完整的事务支持。
2、缺少高频率,低延迟的修改或删除已存在数据的能力。仅能用于批量删除或修改数据。
3、ClickHouse不适合通过检索单行的点查询。
对于ClickHouse的使用,官方提供了命令行客户端、JDBC驱动、ODBC驱动、C++客户端。同时社区中还有很多第三方库可以使用,因此在应用上的会便利很多。
整型类型包含有符号整数型和无符号整数型,整型的范围会跟在数据类型之后。 有符号整型:
Int8 — \[-128 : 127]
Int16 — \[-32768 : 32767]
Int32 — \[-2147483648 : 2147483647]
Int64 — \[-9223372036854775808 : 9223372036854775807]
Int128 — \[-170141183460469231731687303715884105728 : 170141183460469231731687303715884105727]
Int256 — \[-57896044618658097711785492504343953926634992332820282019728792003956564819968 : 57896044618658097711785492504343953926634992332820282019728792003956564819967]
复制无符号整型:
UInt8 — \[0 : 255]
UInt16 — \[0 : 65535]
UInt32 — \[0 : 4294967295]
UInt64 — \[0 : 18446744073709551615]
UInt128 — \[0 : 340282366920938463463374607431768211455]
UInt256 — \[0 : 115792089237316195423570985008687907853269984665640564039457584007913129639935]
复制在ck中,也可以通过一些别名来代替整型
Int8 — TINYINT, BOOL, BOOLEAN, INT1.
Int16 — SMALLINT, INT2.
Int32 — INT, INT4, INTEGER.
Int64 — BIGINT.
复制字符串可以任意长度的。它可以包含任意的字节集,包含空字节,在定义时,通过关键字String定义类型为字符串。
ClickHouse中浮点数有Float32和Float64两种,对应于C语言中的float和double。 ClickHouse在官网上建议尽可能以整数形式存储数据,对浮点数进行计算可能引起四舍五入的误差。
ClickHouse通过Date32和DateTime64存储时间,Date32只存储年月日,支持1900-01-01到2299-12-31,插入数据时可传入'2100-01-01'的格式,也可传入单位为秒的时间戳。比如:
INSERT INTO test VALUES (4102444800, 1), ('2100-01-01', 2);
复制数据库在ck中是用于存放表的目录,创建方式和传统的SQL语法一样
CREATE DATABASE [IF NOT EXISTS] db_name;
复制其中IF NOT EXISTS属于可选项,比如创建一个名为ck_test的数据库
CREATE database if not exists ck_test;
复制ck中使用drop删除指定的数据库,drop会删除数据库中的所有表,然后删除数据库本身
DROP DATABASE [IF EXISTS] db [ON CLUSTER cluster]
复制ON CLUSTER cluster表示是否删除所有集群下的数据库
在ck中创建表的方式有很多,结构化语句建表是最常见的方式之一。
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [NULL|NOT NULL] [DEFAULT|MATERIALIZED|EPHEMERAL|ALIAS expr1] [compression_codec] [TTL expr1],
name2 [type2] [NULL|NOT NULL] [DEFAULT|MATERIALIZED|EPHEMERAL|ALIAS expr2] [compression_codec] [TTL expr2],
...
) ENGINE = engine
复制在属性字段中:
dt Date CODEC(ZSTD)指定压缩方法。通过ENGINE可以指定表所用到的引擎,比如最常用的MergeTree。 通过PRIMARY KEY(expr1[, expr2,...])]可以定义表的主键。 例子:
create table user
(
id UInt32,
name String,
grade UInt32,
address String
)
ENGINE = MergeTree
PRIMARY KEY(id)
ORDER BY id
复制除了结构化方式建表之外,ck还提供了更多创建表的方式 从另一张表中创建表:
CREATE TABLE [IF NOT EXISTS] [db.]table_name AS [db2.]name2 [ENGINE = engine]
复制例子:
CREATE TABLE user2 AS user
复制通过select语句建表:
CREATE TABLE [IF NOT EXISTS] [db.]table_name[(name1 [type1], name2 [type2], ...)] ENGINE = engine AS SELECT ...
复制例子:
CREATE TABLE user3 ENGINE = MergeTree PRIMARY KEY(id)
AS select * from user;
复制ck中使用ALTER对表结构进行修改
ALTER TABLE [db].name [ON CLUSTER cluster] ADD|DROP|RENAME|CLEAR|COMMENT|{MODIFY|ALTER}|MATERIALIZE COLUMN ...
复制例子:
ALTER table user add column sex String;
复制使用drop命令删除表
DROP [TEMPORARY] TABLE [IF EXISTS] [db.]name [ON CLUSTER cluster]
复制例子:
drop table user3
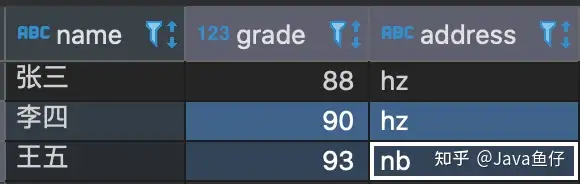
复制OLAP型数据库的一种特性是数据以相当大的批次(> 1000行)更新,而不是单行更新;或者根本没有更新;绝大多数是读请求。因此查询操作是ck最主要的应用。 ck中的查询方法和使用MySQL基本一致,ck支持用 SQL 语法查询执行各种操作。 首先插入一些测试数据:
INSERT into user values(1,'张三',88,'hz','男'),(2,'李四',90,'hz','男'),(3,'王五',93,'nb','女')
复制查询所有的数据
select * from user
复制还可以对列名进行查询,比如查询所有列名中带a的数据
select columns('a') from user
复制
按地区进行聚合,统计每个地区的平均分
select address,AVG(grade) from user group by address复制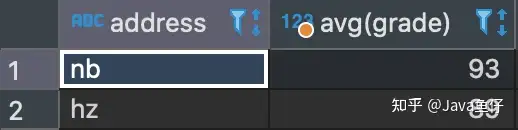
更多的SQL语法操作看https://clickhouse.com/docs/zh/