一、 节拍率与CPU时间
前一篇说到,Linux 作为一个多任务操作系统,将每个 CPU 的时间划分为很短的时间片,再通过调度器轮流分配给各个任务使用,因此造成多任务同时运行的错觉。
为了维护 CPU 时间,Linux 通过事先定义的节拍率(内核中表示为 HZ),触发时间中断,并使用全局变量 Jiffies 记录了开机以来的节拍数。每发生一次时间中断,Jiffies 的值就加 1。
1. 内核节拍率
节拍率 HZ 是内核的可配选项,不同的系统可能设置不同,可以通过查询 /boot/config 内核选项来查看。
grep 'CONFIG_HZ=' /boot/config-$(uname -r)复制![]()
例如我的测试服务器节拍率设置成了1000,即每秒触发 1000 次时间中断。
2. 用户空间节拍率
不过,用户空间程序并不能直接访问内核节拍率。为了方便用户空间程序,内核还提供了一个用户空间节拍率 USER_HZ,它固定为 100(每秒触发100次时间中断)。这样,用户空间程序就不需要关心内核中 HZ 被设置成了多少,因为它看到的总是固定值 USER_HZ。
3. CPU时间
Linux 通过 /proc 虚拟文件系统,向用户空间提供了系统内部状态的信息,而 /proc/stat提供的就是系统的 CPU 和任务统计信息。比方说,如果你只关注 CPU 的话,可以执行下面的命令

第一列表示的是 CPU 编号,如 cpu0、cpu1 ,而第一行没有编号的 cpu ,表示的是所有 CPU 的累加。其他列则表示不同场景下 CPU 的累加节拍数,它的单位是 USER_HZ,也就是 10 ms(1/100 秒),所以这其实就是不同场景下的CPU 时间。
各列含义如下:
- user(通常缩写为 us),代表用户态 CPU 时间。它不包括下面的 nice 时间,但包括了 guest 时间。
- nice(通常缩写为 ni),代表低优先级用户态 CPU 时间,也就是进程的 nice 值被调整为 1-19 之间时的 CPU 时间。这里注意,nice 可取值范围是 -20 到 19,数值越大,优先级反而越低。
- system(通常缩写为 sys),代表内核态 CPU 时间。
- idle(通常缩写为 id),代表空闲时间。注意,它不包括等待 I/O 的时间(iowait)。
- iowait(通常缩写为 wa),代表等待 I/O 的 CPU 时间。
- irq(通常缩写为 hi),代表处理硬中断的 CPU 时间。
- softirq(通常缩写为 si),代表处理软中断的 CPU 时间。
- steal(通常缩写为 st),代表当系统运行在虚拟机中的时候,被其他虚拟机占用的 CPU时间。
- guest(通常缩写为 guest),代表通过虚拟化运行其他操作系统的时间,也就是运行虚拟机的 CPU 时间。
- guest_nice(通常缩写为 gnice),代表以低优先级运行虚拟机的时间。
二、 CPU使用率
1. 定义与计算
通常所说的 CPU 使用率,就是除了空闲时间外的其他时间占总 CPU 时间的百分比,用公式来表示就是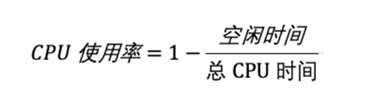
根据这个公式,我们就可以从 /proc/stat 中的数据,很容易地计算出 CPU 使用率。当然,也可以用每一个场景的 CPU 时间,除以总的 CPU 时间,计算出每个场景的 CPU 使用率。但是/proc/stat是开机以来的节拍数累加值,所以直接算出来的,是开机以来的平均 CPU 使用率,一般没啥参考价值。
事实上,为了计算 CPU 使用率,性能工具一般都会取间隔一段时间(比如 3 秒)的两次值,作差后,再计算出这段时间内的平均 CPU 使用率,即

现在,我们知道了系统 CPU 使用率的计算方法,那进程的呢?跟系统的指标类似,Linux也给每个进程提供了运行情况的统计信息,也就是 /proc/[pid]/stat。
各种各样的性能分析工具已经帮我们计算好了CPU使用率。不过要注意的是,性能分析工具给出的都是间隔一段时间的平均 CPU 使用率,所以要注意间隔时间的设置,特别是用多个工具对比分析时,你一定要保证它们用的是相同的间隔时间。
比如,对比一下 top 和 ps 这两个工具报告的 CPU 使用率,默认的结果很可能不一样,因为 top 默认使用 3 秒时间间隔,而 ps 使用的却是进程的整个生命周期。
2. 查看 CPU 使用率
top 和 ps 是最常用的性能分析工具:top 显示了系统总体的 CPU 和内存使用情况,以及各个进程的资源使用情况。ps 则只显示了每个进程的资源使用情况。
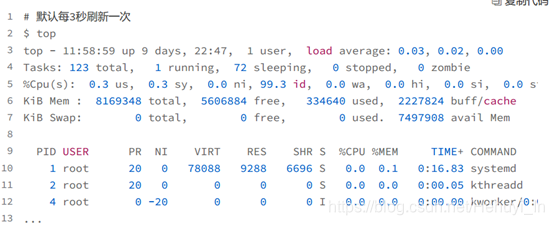
这个输出结果中,第三行 %Cpu 就是系统的 CPU 使用率,具体每一列的含义上一节都讲过,只是把 CPU 时间变换成了 CPU 使用率。top 默认显示的是所有 CPU 的平均值,这个时候你只需要按下数字 1 ,就可以切换到每个 CPU的使用率了。
空白行之后是进程的实时信息,每个进程都有一个 %CPU 列,表示进程的CPU 使用率。它是用户态和内核态 CPU 使用率的总和,包括进程用户空间使用的 CPU、通过系统调用执行的内核空间 CPU 、以及在就绪队列等待运行的 CPU。在虚拟化环境中,它还包括了运行虚拟机占用的 CPU。
到这里我们可以发现, top 并没有细分进程的用户态 CPU 和内核态 CPU。那要怎么查看每个进程的详细情况呢?你应该还记得上一节用到的 pidstat 吧,它正是一个专门分析每个进程 CPU 使用情况的工具。
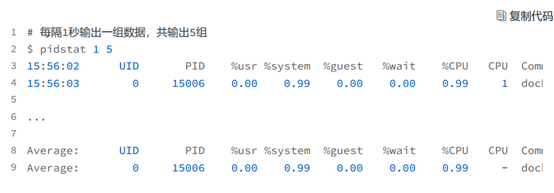
下面的 pidstat 命令,就间隔 1 秒展示了进程的 5 组 CPU 使用率,包括:
- 用户态 CPU 使用率 (%usr);
- 内核态 CPU 使用率(%system);
- 运行虚拟机 CPU 使用率(%guest);
- 等待 CPU 使用率(%wait);
- 总的 CPU 使用率(%CPU)。
最后的 Average 部分,还计算了 5 组数据的平均值。
三、 perf分析CPU使用率过高问题
perf 是 Linux 2.6.31 以后内置的性能分析工具。它以性能事件采样为基础,不仅可以分析系统的各种事件和内核性能,还可以用来分析指定应用程序的性能问题。
1. perf top
第一种常见用法是 perf top,类似于 top,它能够实时显示占用 CPU 时钟最多的函数或者指令,因此可以用来查找热点函数,使用界面如下所示:
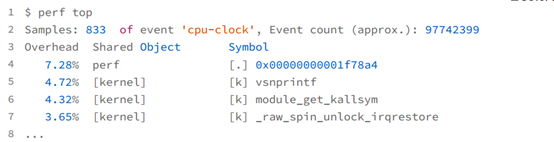
输出结果中,第一行包含三个数据,分别是采样数(Samples)、事件类型(event)和事件总数量(Event count)。比如这个例子中,perf 总共采集了 833 个 CPU 时钟事件,而总事件数则为 97742399。采样数需要我们特别注意。如果采样数过少(比如只有十几个),那下面的排序和百分比就没什么实际参考价值了。
再往下看是一个表格式样的数据,每一行包含四列,分别是:
- 第一列 Overhead ,是该符号的性能事件在所有采样中的比例,用百分比来表示。
- 第二列 Shared ,是该函数或指令所在的动态共享对象(Dynamic Shared Object),如内核、进程名、动态链接库名、内核模块名等。
- 第三列 Object ,是动态共享对象的类型。比如 [.] 表示用户空间的可执行程序、或者动态链接库,而 [k] 则表示内核空间。
- 最后一列 Symbol 是符号名,也就是函数名。当函数名未知时,用十六进制的地址来表示。
以上面的输出为例,我们可以看到,占用 CPU 时钟最多的是 perf 工具自身,不过它的比例也只有 7.28%,说明系统并没有 CPU 性能问题。
虽然实时展示了系统的性能信息,但它的缺点是并不保存数据,也就无法用于离线或者后续的分析,需要用到下面的工具。
2. perf record 和 perf report
perf record 则提供了保存数据的功能,保存后的数据,需要你用 perf report 解析展示。在实际使用中,我们还经常加上 -g 参数,开启调用关系的采样,方便根据调用链来分析性能问题。

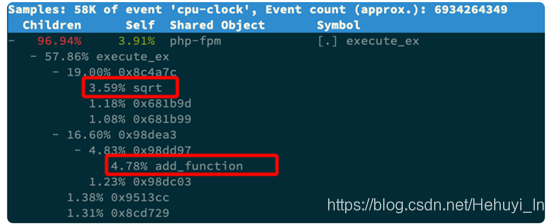
下面是分析一段php函数的perf report,你会发现,调用关系最终到了 sqrt 和 add_function,可以找到这两个函数相关代码进行分析。
四、 CPU高却找不到对应进程?
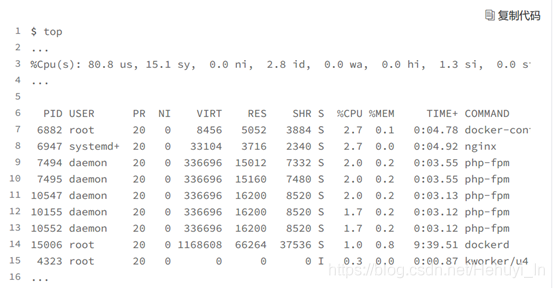
如下图,top可以看到系统的整体 CPU 使用率是比较高的:用户 CPU 使用率(us)已经到了 80%,系统 CPU 为 15.1%,而空闲 CPU(id)则只有 2.8%。但是CPU 使用率最高的进程也只不过才 2.7%,看起来并不高。
运行 pidstat 命令发现也是一样
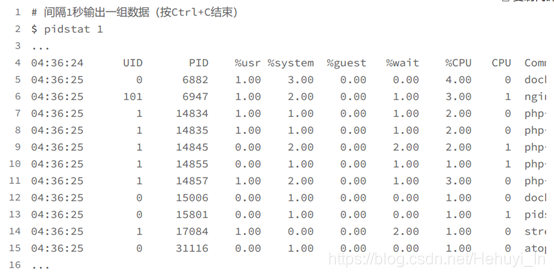
会出现这种情况,很可能是因为前面的分析漏了一些关键信息。你可以先暂停一下,自己往上翻,重新操作检查一遍。或者,我们一起返回去分析 top 的输出,看看能不能有新发现。我们回到第一个终端,重新运行 top 命令,并观察一会儿:
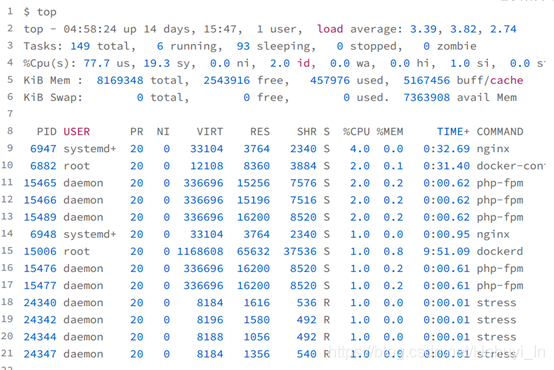
这次从头开始看 top 的每行输出,咦?Tasks 这一行看起来有点奇怪,就绪队列中居然有6 个 Running 状态的进程(6 running),是不是有点多呢?你有没有发现, Nginx 和所有的 php-fpm 都处于 Sleep(S)状态,而真正处于 Running(R)状态的,却是几个stress 进程,并且这几个进程pid一直在变。
进程的 PID 在变,这说明什么呢?在我看来,要么是这些进程在不停地重启,要么就是全新的进程,这无非也就两个原因:
- 第一个原因,进程在不停地崩溃重启,比如因为段错误、配置错误等等,这时,进程在退出后可能又被监控系统自动重启。
- 第二个原因,这些进程都是短时进程,也就是在其他应用内部通过 exec 调用的外面命令。这些命令一般都只运行很短的时间就会结束,你很难用 top 这种间隔时间比较长的工具发现(上面的案例,我们碰巧发现了)。
至于 stress,我们前面提到过,它是一个常用的压力测试工具。它的 PID 在不断变化中,看起来像是被其他进程调用的短时进程。要想继续分析下去,还得找到它们的父进程。要怎么查找一个进程的父进程呢?
用 pstree 就可以用树状形式显示所有进程之间的关系:
pstree | grep stress复制

从这里可以看到,stress 是被 php-fpm 调用的子进程,并且进程数量不止一个(这里是 3个)。找到父进程后,我们能进入 app 的内部分析了,应该去看看它的源码(这里略了,详细参考原文)。
经过检查,发现有错误消息 mkstemp failed: Permission denied ,以及 failed run completed in 0s。原来 stress 命令并没有成功,它因为权限问题失败退出了。看来,我们发现了一个 PHP 调用外部 stress 命令的 bug:没有权限创建临时文件。
从这里我们可以猜测,正是由于权限错误,大量的 stress 进程在启动时初始化失败,进而导致用户 CPU 使用率的升高。
分析出问题来源,下一步是不是就要开始优化了呢?当然不是!既然只是猜测,那就需要再确认一下,这个猜测到底对不对,是不是真的有大量的 stress 进程。该用什么工具或指标呢?
我们前面已经用了 top、pidstat、pstree 等工具,没有发现大量的 stress 进程。那么,还有什么其他的工具可以用吗?
还记得上一期提到的 perf 吗?它可以用来分析 CPU 性能事件,用在这里就很合适。依旧在第一个终端中运行 perf record -g 命令 ,并等待一会儿(比如 15 秒)后按 Ctrl+C 退出。然后再运行 perf report 查看报告:
# 记录性能事件,等待大约15秒后按 Ctrl+C 退出perf record -g# 查看报告perf report复制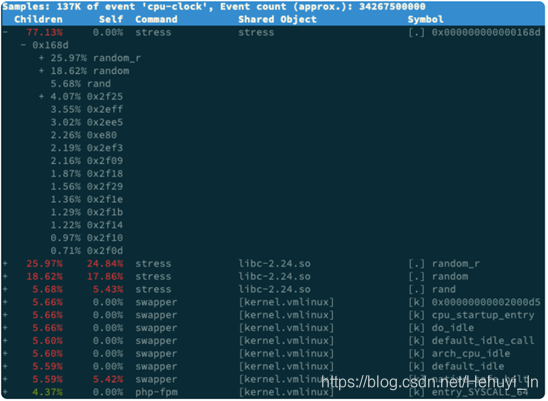
你看,stress 占了所有 CPU 时钟事件的 77%,而 stress 调用调用栈中比例最高的,是随机数生成函数 random(),看来它的确就是 CPU 使用率升高的元凶了。随后的优化就很简单了,只要修复权限问题,并减少或删除 stress 的调用,就可以减轻系统的 CPU 压力。
当然,实际生产环境中的问题一般都要比这个案例复杂,在你找到触发瓶颈的命令行后,却可能发现,这个外部命令的调用过程是应用核心逻辑的一部分,并不能轻易减少或者删除。这时,你就得继续排查,为什么被调用的命令,会导致 CPU 使用率升高或 I/O 升高等问题。这些复杂场景的案例,我会在后面的综合实战里详细分析。
五、 短时进程监控 execsnoop
execsnoop 是一个专为短时进程设计的工具。它通过 ftrace 实时监控进程的 exec() 行为,并输出短时进程的基本信息,包括进程 PID、父进程 PID、命令行参数以及执行的结果。
比如,用 execsnoop 监控上述案例,就可以直接得到 stress 进程的父进程 PID 以及它的命令行参数,并可以发现大量的 stress 进程在不停启动。
# 按 Ctrl+C 结束execsnoop#输出PCOMM PID PPID RET ARGSsh 30394 30393 0stress 30396 30394 0 /usr/local/bin/stress -t 1 -d 1sh 30398 30393 0stress 30399 30398 0 /usr/local/bin/stress -t 1 -d 1sh 30402 30400 0stress 30403 30402 0 /usr/local/bin/stress -t 1 -d 1sh 30405 30393 0stress 30407 30405 0 /usr/local/bin/stress -t 1 -d 1...复制execsnoop 所用的 ftrace 是一种常用的动态追踪技术,一般用于分析 Linux 内核的运行时行为,后面课程我也会详细介绍并带你使用。
六、 小结
碰到常规问题无法解释的 CPU 使用率情况时,首先要想到有可能是短时应用导致的问题,比如有可能是下面这两种情况。
- 第一,应用里直接调用了其他二进制程序,这些程序通常运行时间比较短,通过 top 等工具也不容易发现。
- 第二,应用本身在不停地崩溃重启,而启动过程的资源初始化,很可能会占用相当多的CPU。
对于这类进程,我们可以用 pstree 或者 execsnoop 找到它们的父进程,再从父进程所在的应用入手,排查问题的根源。
评论补充:
- 可以用 perf record -ag -- sleep 2;perf report 一步到位
- http://blog.bruceding.com/420.html 这个是之前的优化经历,通过 perf + 火焰图,定位热点代码,结合业务和网络分析,最终确定问题原因