https://tidb.net/book/book-rush/features/tiflash-code/tiflash-deltatree复制
TiFlash 是 TiDB 的分析引擎,是 TiDB HTAP 形态的关键组件。TiFlash 源码阅读系列文章将从源码层面介绍 TiFlash 的内部实现。希望读者在阅读这一系列文章后,能够对 TiFlash 内部原理有一个清晰的理解,更熟悉 TiFlash 各个流程及概念,甚至能对 TiFlash 进行源码级别的编程开发。在上一期源码阅读中,我们介绍了 TiFlash 的计算层。从本文开始,我们将对 TiFlash 各个组件的设计及实现进行详细分析。
本文作者:施闻轩,TiFlash 资深研发工程师
PingCAP 自研的 DeltaTree 列式存储引擎是让 TiFlash 站在 Clickhouse 巨人肩膀上得以实现可更新列存的关键。本文分为两部分,主要介绍 DeltaTree 存储引擎的设计细节及对应的代码实现。Part 1 部分主要涉及写入流程,Part 2 主要涉及读取流程。
本文基于写作时最新的 TiFlash v6.1.0 设计及源码进行分析。随着时间推移,新版本中部分设计可能会发生变更,使得本文部分内容失效,请读者注意甄别。TiFlash v6.1.0 的代码可在 TiFlash 的 git repo 中切换到 v6.1.0 tag 进行查看。
TiFlash 关键的底层抽象都复用了 Clickhouse 已有的抽象概念,而非完全用 TiDB 抽象概念进行替代。本节首先介绍读者通常接触到的 TiDB 抽象概念在 TiFlash 中的形态及对应关系,以便读者在进一步深入 TiFlash 代码后不会产生混淆。
在 TiDB、TiKV 及 TiFlash 代码中,我们将在 TiDB 中通过 CREATE TABLESQL 语句创建出来的表称为「逻辑表」。例如,以下语句将会创建一个「逻辑表」:
CREATE TABLE foo(c INT);复制对应地,我们将实际存储数据的表称为「物理表」。对于非分区表,物理表与逻辑表相同。对于分区表,各个分区才是这张逻辑表的物理表。TiKV 及 TiFlash 由于主要涉及数据存取,因此它们绝大多数时候都在与物理表打交道、不关注逻辑表。
以下会创建一个逻辑表,且具有 4 张物理表、在这 4 张物理表上存储了实际数据:
CREATE TABLE bar ( id INT NOT NULL, store_id INT NOT NULL)PARTITION BY RANGE (store_id) ( PARTITION p0 VALUES LESS THAN (6), PARTITION p1 VALUES LESS THAN (11), PARTITION p2 VALUES LESS THAN (16), PARTITION p3 VALUES LESS THAN (21));复制小知识
可以通过 TiDB HTTP API 查看内部表结构。例如,对于前文示例中创建的
foo表及bar表,查询出来的表结构如下:
curl http://127.0.0.1:10080/schema/test/foo{ "id": 65, "name": { "O": "foo", "L": "foo" }, "cols": [...], ...}❯ curl http://127.0.0.1:10080/schema/test/bar{ "id": 67, "name": { "O": "bar", "L": "bar" }, "cols": [...], "partition": { ..., "definitions": [ { "id": 68, "name": { "O": "p0", "L": "p0" }, ... }, { "id": 69, "name": { "O": "p1", "L": "p1" }, ... }, { "id": 70, "name": { "O": "p2", "L": "p2" }, ... }, { "id": 71, "name": { "O": "p3", "L": "p3" }, ... } ], }, ...}复制通过上述查询结果可知,
foo表的逻辑表 ID 为 65,由于没有分区,因此它的物理表 ID 也是 65。bar表的逻辑表 ID 为 67,它具有四个物理表,ID 分别是 68、69、70、71,这四个分区对应的物理表存储了bar表中的数据。
TiFlash 中我们维持了 Clickhouse 的表抽象概念。每一张 TiDB 中的物理表都会对应地在 TiFlash 中创建出一张 Clickhouse 表来存储数据,并指定存储引擎为 DeltaTree,关系如下所示:
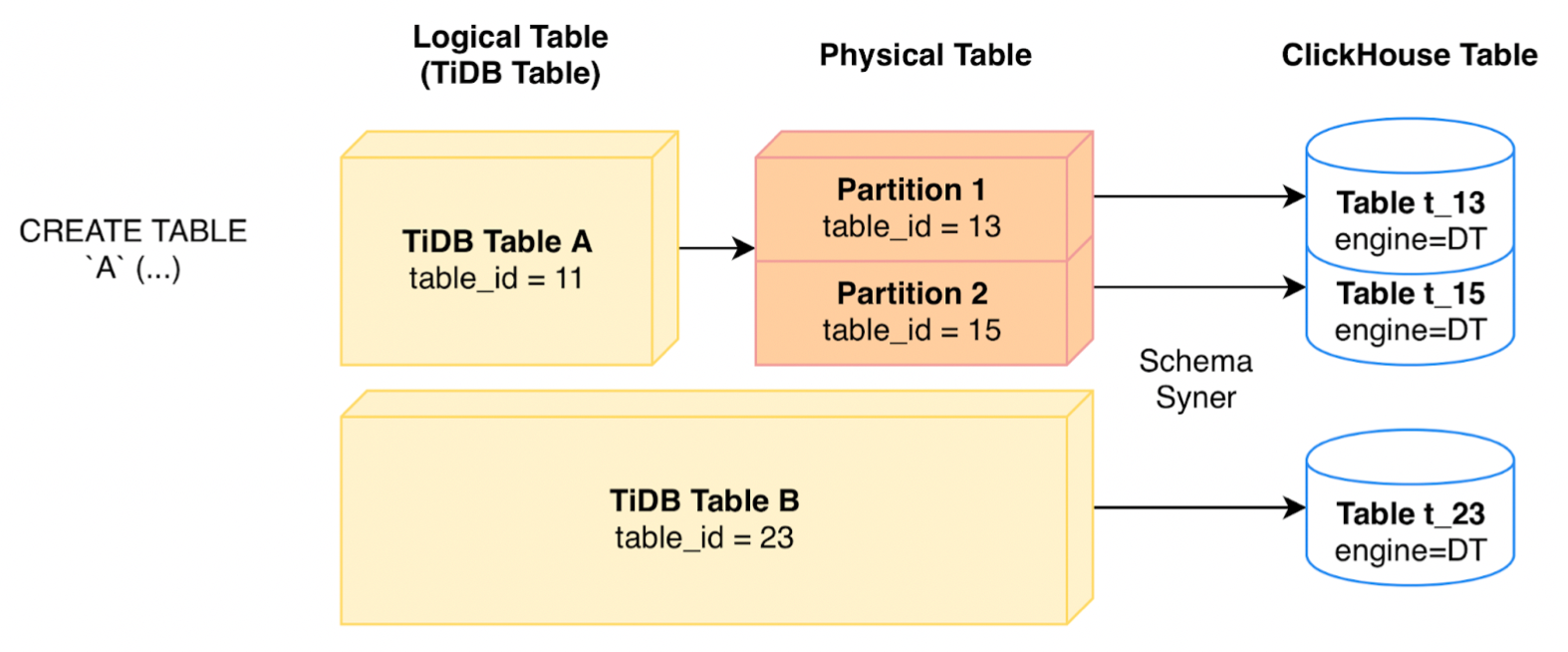
例如,一个 ID = 13 的物理表会在 TiFlash 中对应 t_13表。
每张 DeltaTree 引擎的 TiFlash 表内部都对应了一个 StorageDeltaMerge实例(参见 StorageDeltaMerge.h):
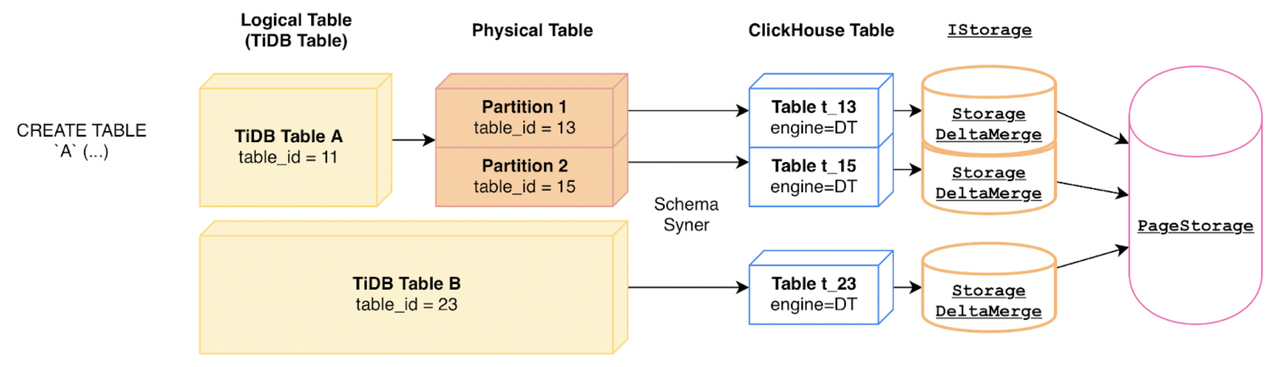
备注 1:DeltaMerge 是 DeltaTree 的前称。由于 DeltaMerge 与 TiDB 的 Data Migration 产品有一样的缩写 DM,因此 DeltaMerge 目前已统一改称 DeltaTree。代码中还未完全清理干净,欢迎感兴趣的小伙伴参与贡献。 备注 2:PageStorage 是一个 TiFlash 的抽象存储层,DeltaTree 引擎的一部分数据通过 PageStorage 模块进行存储。本文不对 PageStorage 模块做详细分析,这将由源码解读系列的其他文章进一步展开。
熟悉 TiDB 的读者可能会对 TiDB Region 这个概念比较熟悉。Region 是 TiDB 数据分片(Sharding)的基本单位,一张物理表的数据将会切分到一个或多个 Region 中,从而实现数据分片存储及计算。在 TiFlash 存储引擎层面,由于 Region 的存在,因此每个 TiFlash 表实际上会存储对应 TiDB 物理表的一部分数据。
以下图为例,假设部署了两个 TiFlash 节点。若设置了 employee 表的 TiFlash 副本数为 1,则这两个 TiFlash 节点各将存储 employee 表的约 50% 数据:
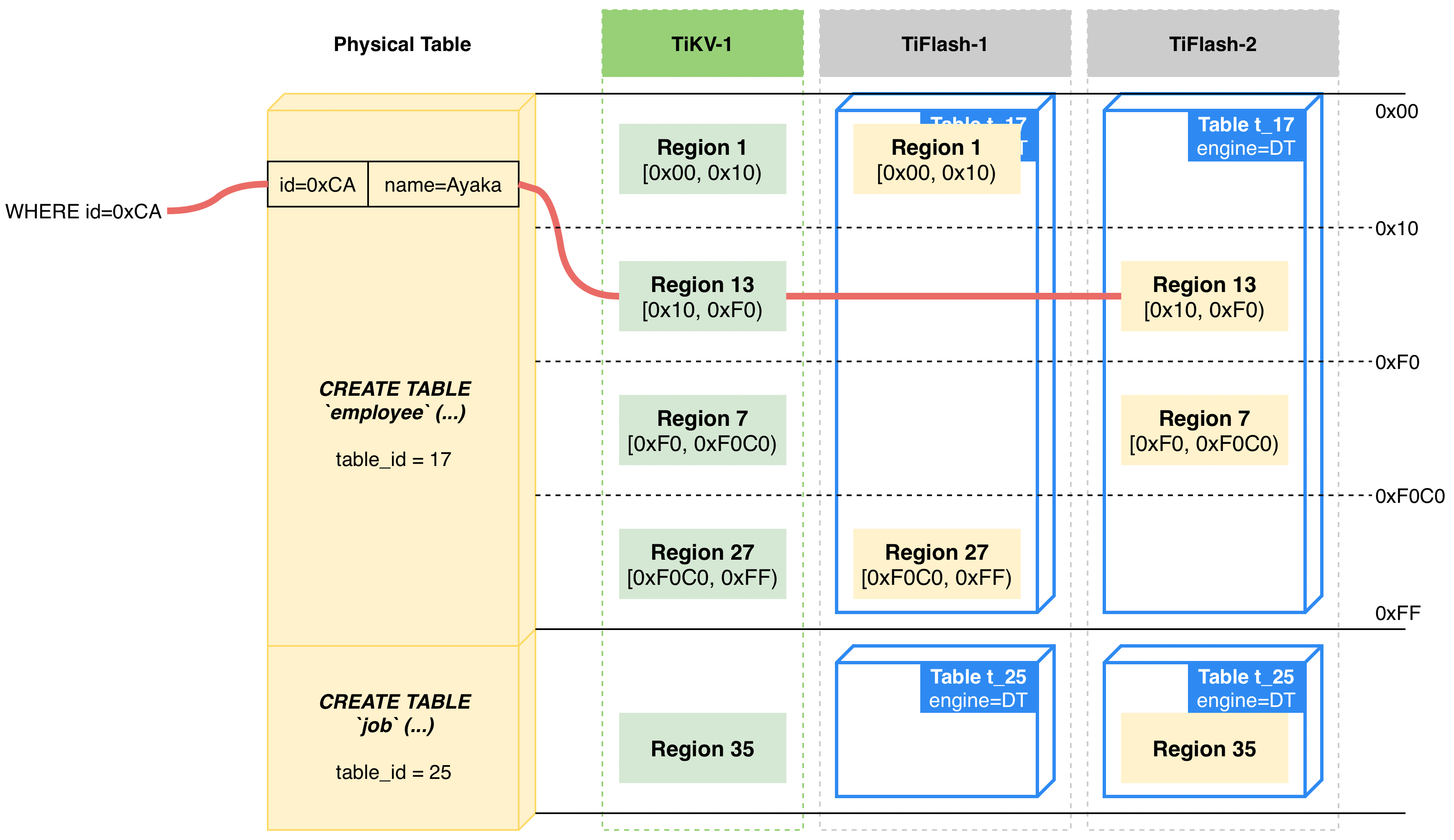
同样的,假设 job 表设置的 TiFlash 副本数也为 1,由于它只有一个 Region,因此 job 表的数据会落在其中一个 TiFlash 节点上,其余 TiFlash 节点上没有数据。
在 TiDB 产品(TiDB、TiKV 及 TiFlash)代码中会频繁出现 Handle 一词。为了兼容 MySQL 语法,在 TiDB 产品中通过 SQL 语句指定的主键不一定是物理数据中的主键。代码中将 SQL 语句指定的主键称为 Primary Key,而物理数据对应的「真正的」、物理主键称为 Handle。
TiDB 产品中有以下几种不同的 Handle:
1.CommonHandle(自 v5.0+ 版本引入)
创建表时若指定主键为 聚簇索引(Clustered Index) ,且主键不是 INT 类型,则该主键对应于 CommonHandle,例如:
-- 指定 VARCHAR 类型的聚簇索引主键CREATE TABLE …(id VARCHAR PRIMARY KEY CLUSTERED);-- 指定聚簇索引联合主键CREATE TABLE …(… , PRIMARY KEY (a, b) CLUSTERED);复制各模块代码中往往会采用 is_common_handle == true代表这种情况。
2.IntHandle
创建表时若指定为 INT 或 UNSIGNED INT 类型(INT 的不同种类如 BIGINT、TINYINT 等也包括在内)的主键,则这个主键对应于 IntHandle,例如:
-- 指定 INT 类型主键CREATE TABLE …(id INT PRIMARY KEY);-- 指定 UNSIGNED INT 类型主键CREATE TABLE …(id INT UNSIGNED PRIMARY KEY);复制各模块代码中往往会采用 is_common_handle == false && pk_is_handle == true代表这种情况。
3.TiDB 隐式主键
若创建表时没有指定主键,或没有开启聚簇索引,则 TiDB 内部会创建一个名为 _tidb_rowid的隐式主键,并自动管理该隐式主键的值:
-- 指定 VARCHAR 类型非聚簇索引主键CREATE TABLE …(id VARCHAR PRIMARY KEY);-- 指定 INT 类型非聚簇索引主键CREATE TABLE …(id INT PRIMARY KEY NONCLUSTERED);-- 不指定主键CREATE TABLE …(name VARCHAR);复制各模块代码中往往会采用 is_common_handle == false && pk_is_handle == false代表这种情况。
小知识 1
通过 TiDB HTTP API 查看内部表结构时可以了解这张表的主键类型:
mysql> CREATE TABLE yo(id INT PRIMARY KEY);❯ curl http://127.0.0.1:10080/schema/test/yo{ "id": 73, "name": { "O": "yo", "L": "yo" }, "pk_is_handle": true, "is_common_handle": false, ...}复制小知识 2 可以直接通过 SQL 语句查询出 TiDB 隐式主键的值,甚至可以参与运算(如置于 WHERE 子句中):
mysql> CREATE TABLE characters (name VARCHAR(32));Query OK, 0 rows affected (0.06 sec)mysql> INSERT INTO characters VALUES ("Klee"), ("Kazuha");Query OK, 2 rows affected (0.00 sec)Records: 2 Duplicates: 0 Warnings: 0mysql> SELECT *, _tidb_rowid FROM characters;+--------+-------------+| name | _tidb_rowid |+--------+-------------+| Klee | 1 || Kazuha | 2 |+--------+-------------+2 rows in set (0.00 sec)mysql> select * from characters where _tidb_rowid=2;+--------+| name |+--------+| Kazuha |+--------+1 row in set (0.00 sec)复制TiFlash 的 DeltaTree 引擎实现了 Clickhouse 数据表的标准存储引擎接口 IStorage,允许直接通过 Clickhouse SQL 进行访问,这样即可在不引入 TiDB 及 TiKV 的情况下直接对表上的数据进行简单的读写,对集成测试和调试都提供了很大的便利。Clickhouse 存储引擎上标准的读写是通过 BlockInputStream及 BlockOutputStream实现的,分别对应写入和读取,DeltaTree 也不例外。写入和读取的基本单位是 Block(请参见 Block.h)。 Block以列为单位组织数据,这些列合起来构成了若干行数据。
当然,DeltaTree 引擎本身也需要服务于从 TiKV Raft 协议同步而来的数据写入,及来自 TiFlash MPP 引擎的数据读取。
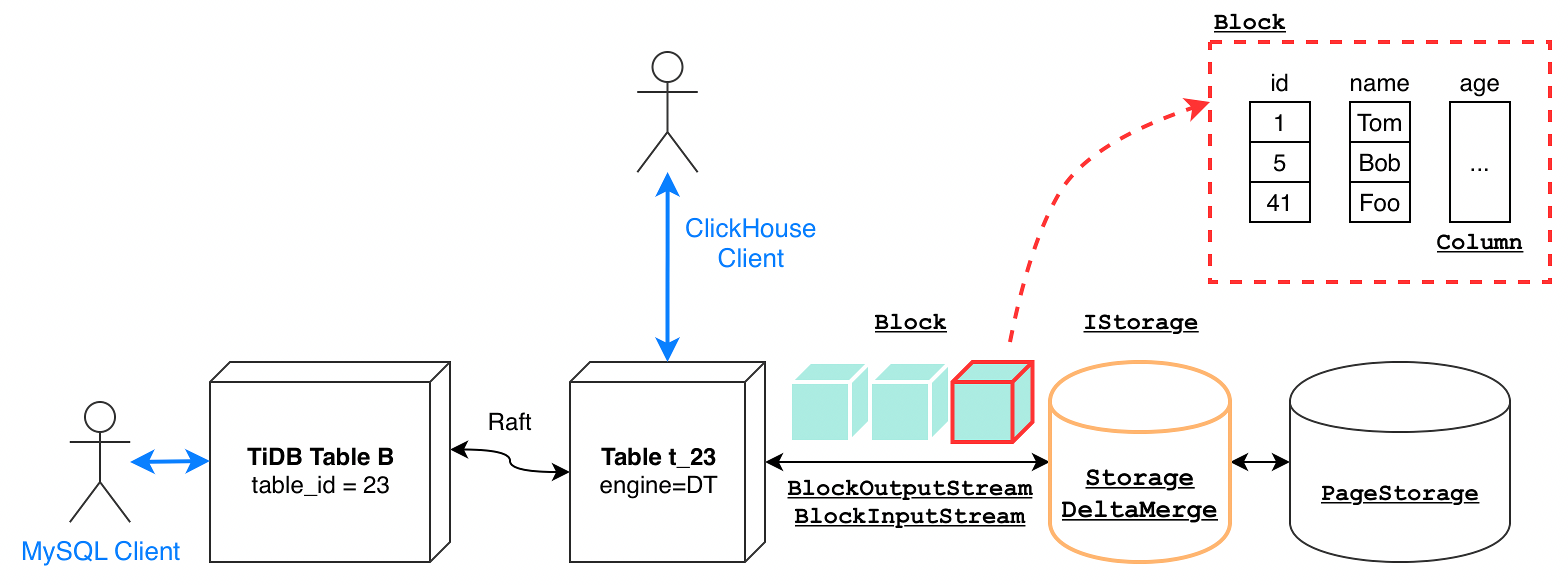
StorageDeltaMerge是 DeltaTree 存储引擎的最外层包装(参见 StorageDeltaMerge.h),它提供了以下接口来实现上述两类分别来自 TiDB 和 Clickhouse Client 的读写需求:
StorageDeltaMerge::read() → BlockInputStreamStorageDeltaMerge::write(Block)StorageDeltaMerge::ingestFiles()。并不是所有数据都需要通过 Raft Log 进行增量同步,例如在追加新副本时,往往就通过直接传递副本上全量数据(Raft Snapshot)的方式进行副本数据写入。StorageDeltaMerge::read() → BlockInputStreamStorageDeltaMerge::write() → BlockOutputStreamDeltaTree 引擎由一组 Segment 构成,Segment 会按需进行分裂及合并。DeltaTree 存储的所有数据都按 Handle 列(物理主键)进行值域切分,切分为不同的 Segment(参见 Segment.h)。
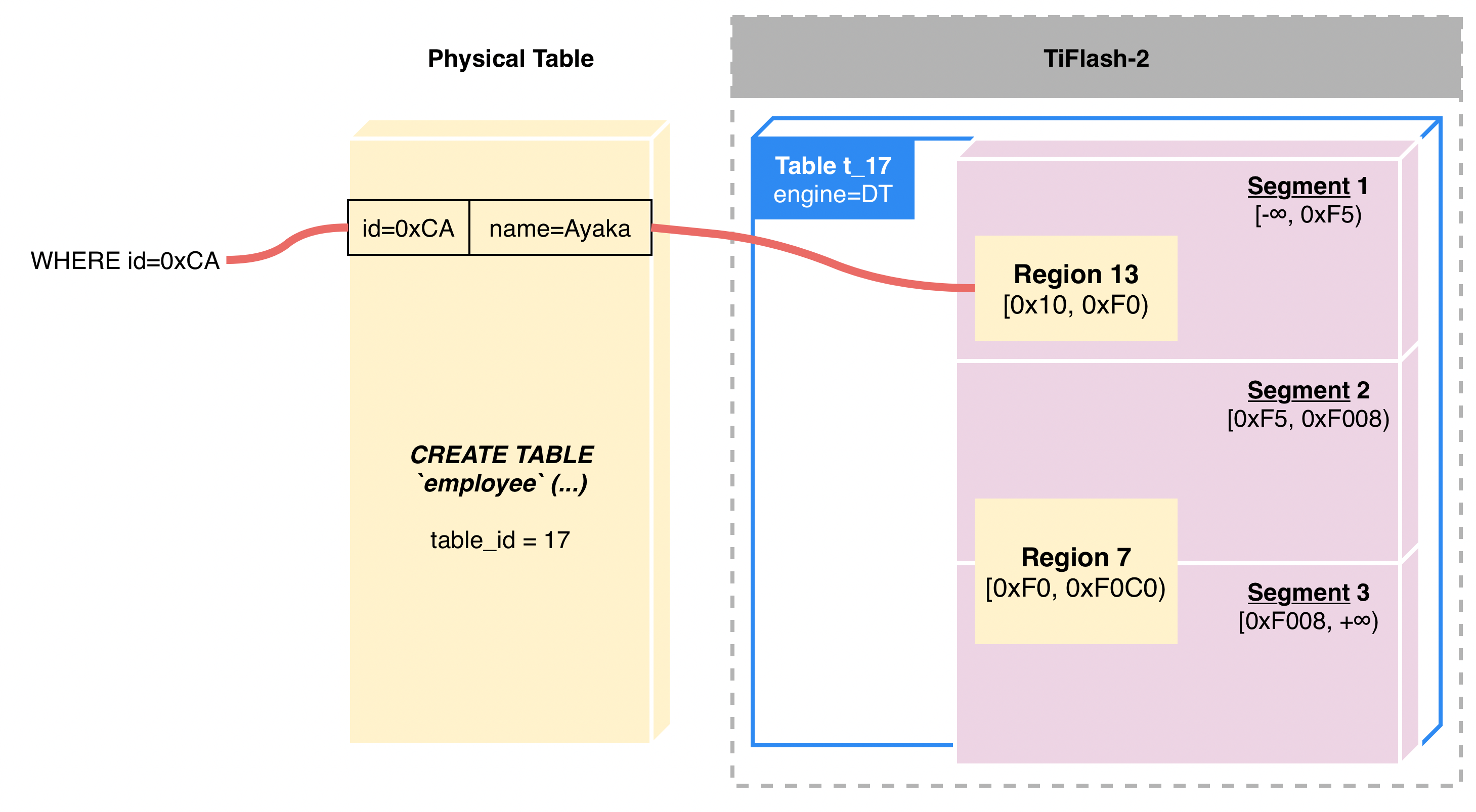
Segment 形式上与 Region 有些类似,都是在依据 Handle 进行值域切分。TiFlash 的 Segment 单位较大,以便能够一次性对比较大的 Column 数据进行批量处理。一个 Segment 往往可以达到 500MB(可通过 dt_segment_limit_size及 dt_segment_limit_rows参数控制),相对应地,Region 一般则不超过 96MB。
注意,Segment 本身与 Region 没有直接的对齐关系。例如一个 Segment 可以包含一个完整的 Region,或包含很多个 Region,也可能包含了一个 Region 的一部分。
在内存中,我们简单地使用一棵红黑树记载所有 Segment:Map<EndHandle, SegmentPtr>,Map 的 Key 为该 Segment 的 EndHandleKey。这使得我们能非常轻易地基于 Handle 找到它对应的 Segment。
单个 Segment 内部进一步按时域分为两层,一层是 Delta Layer(参见 DeltaValueSpace.h),一层是 Stable Layer(参见 StableValueSpace.h)。可以简单地想象成是一个两层的 LSM Tree:
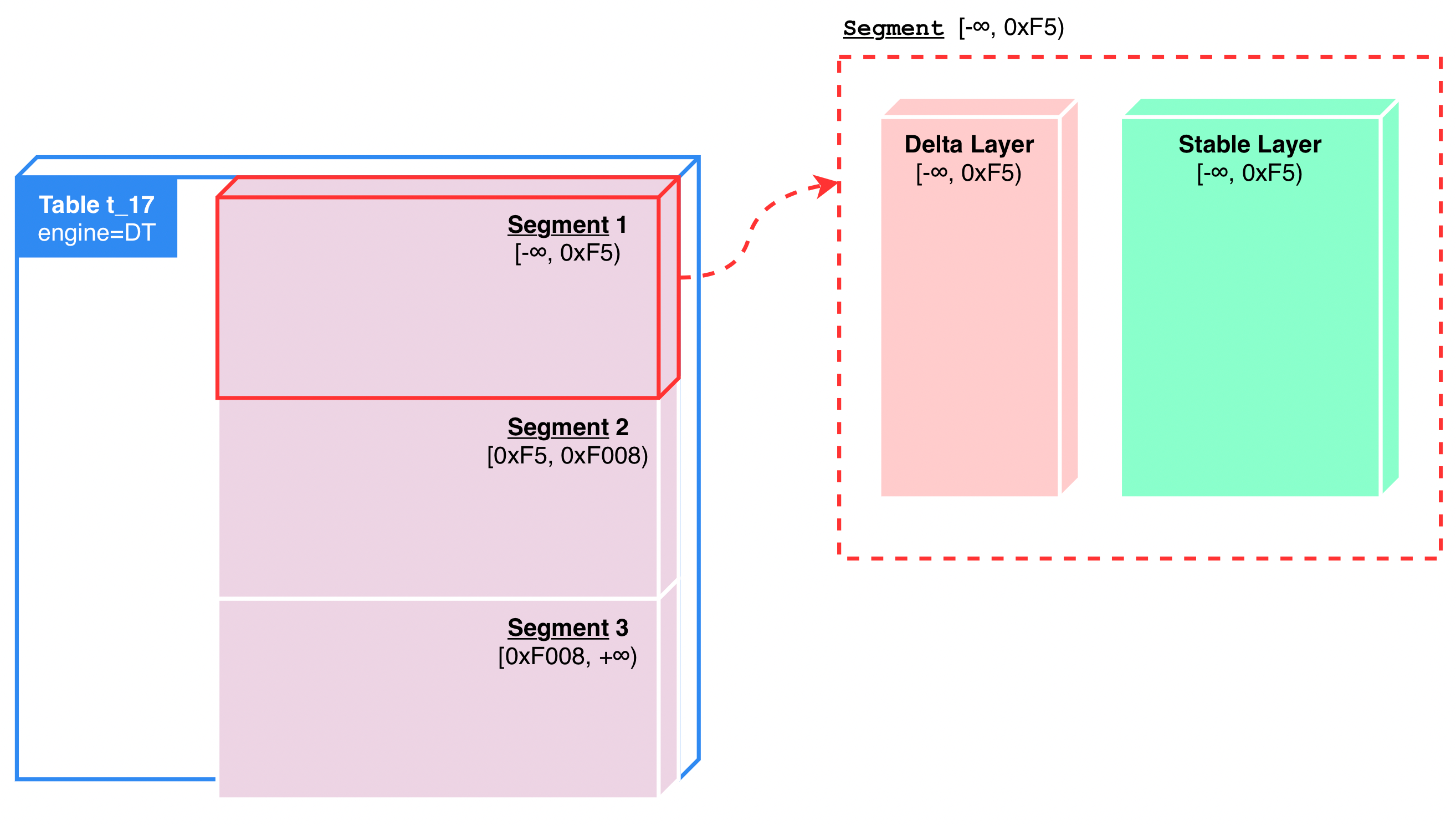
Delta Layer 及 Stable Layer 在值域上是重叠的,它们都会包含整个 Segment 值域空间中的数据。新写入或更新的数据存储在 Delta Layer 中,定期 Compaction 形成 Stable Layer。其中单个 Segment 内的 Delta Layer 一般占 Segment 内数据的 5% 左右、剩余在 Stable Layer 中。
由于 Delta Layer 主要存储新写入的数据,与写入密切相关,而绝大多数需要读取的数据又在 Stable Layer 中,因此这种双层设计给予了我们分别进行优化的空间,这两层我们采用了不同的存储结构。Delta Layer 主要面向写入场景进行优化,而 Stable Layer 则主要面向读取场景进行优化。
为了与 TiDB 的 MVCC 兼容,除了用户在建立 TiDB 表指定的列以外,DeltaTree 实际还会额外存储以下两列数据:
该列存储了从 TiKV 同步而来的行数据中记载的 commit_ts 的值,即 MVCC 版本号。通过读取的时候按照该列进行过滤,TiDB 就能在访问 TiKV 及 TiFlash 时获得一致的快照隔离级别数据。若对同一行数据进行了多次更新,那么它们将产生不同的 MVCC 版本号。不同版本的相同行的数据将在 GC 的时候被清理。
该列为 1 时代表对应行的数据被删除。例如在 TiDB 中执行 DELETE 语句后,每一个删除的行在同步到 TiFlash 上后都成为了 Delete mark = 1 的列数据。这些数据会存储在表中,以便在读的时候对其进行过滤。这些数据会在 GC 的时候被清理。
与写入有关的流程大致如下:
1.写入时接受 Block 为单位的数据,数据置于内存中,对应结构为 MemTableSet(参见 MemTableSet.h)
2.DeltaTree 后台定期将内存中的 MemTableSet 写入到磁盘上(这个过程称为 Flush),形成磁盘上持久化了的 Delta 层数据
实际上,Delta 层数据并非是直接操作文件、存储在文件系统中,而是通过 PageStorage 模块进行存储。 PageStorage 是一层简单的对象存储层,提供了诸如快照、回滚、合并小 IO 等功能,针对 Delta 层数据高频 IO 等特性进行了优化。PageStorage 模块的详细设计分析将在源码阅读的后续文章中做详细介绍,本文不做展开。
3.DeltaTree 后台定期将磁盘上 Delta 层的数据与磁盘上 Stable 层的数据进行合并(这个过程称为 Merge Delta,也称为 Major Compaction),并写入磁盘,形成新的 Stable 层数据
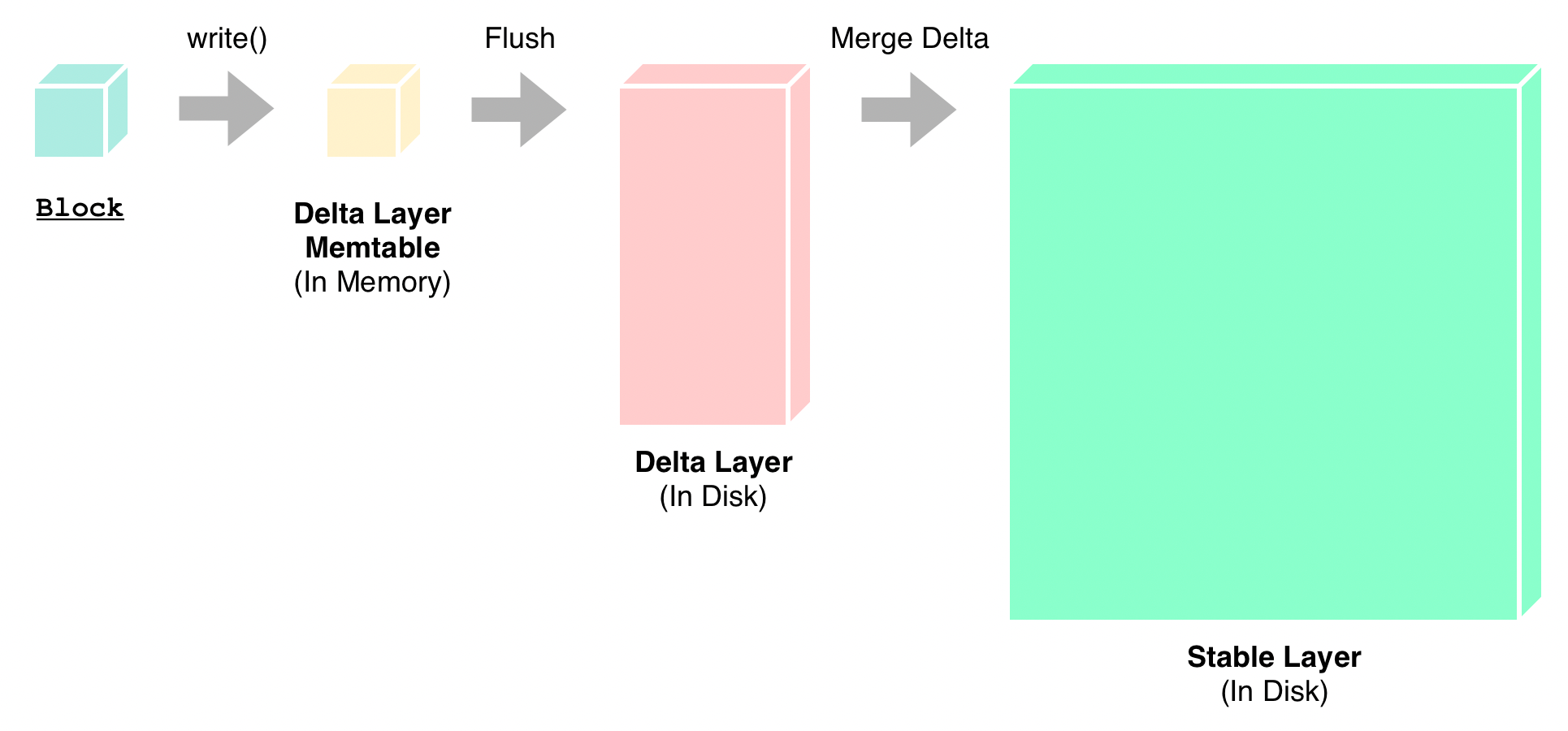
该流程与标准的 LSM Tree 比较相似。
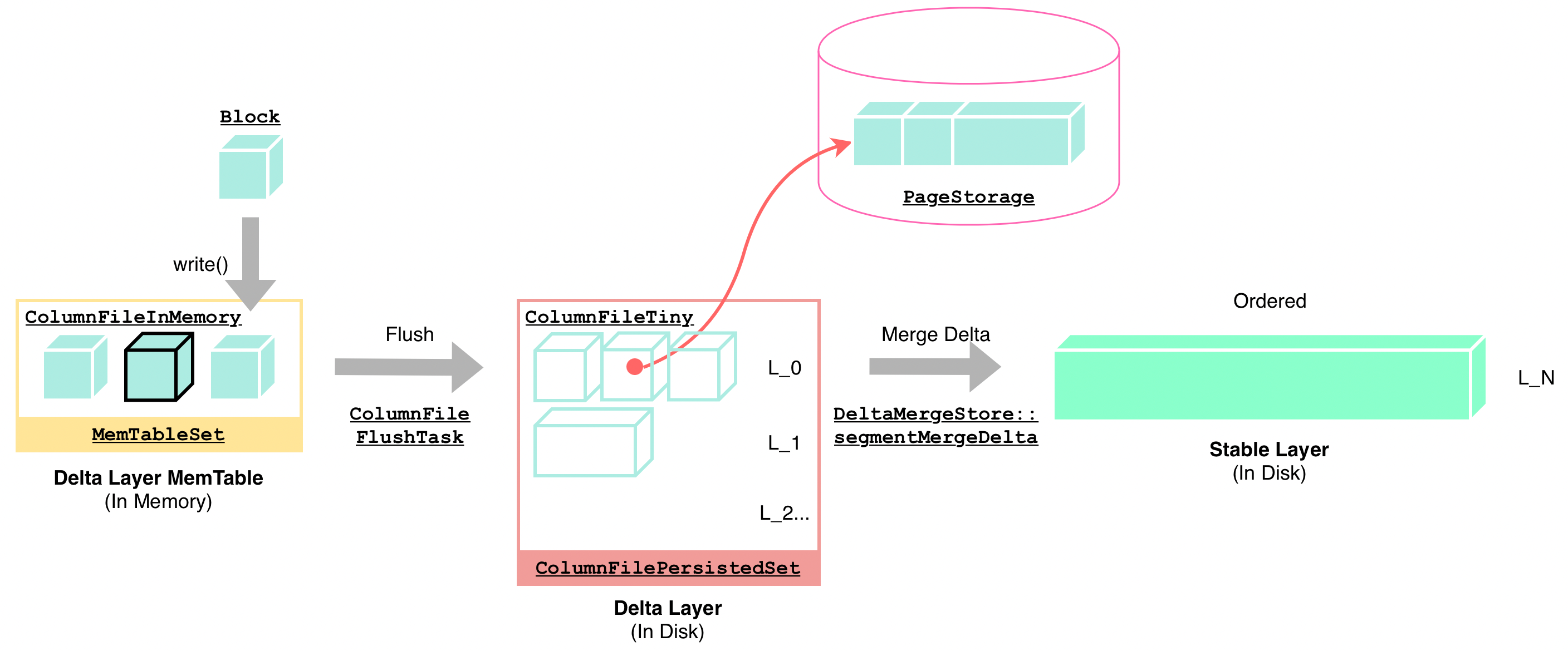
DeltaTree 引擎对 Delta Layer 及 Stable Layer 采用了不同的结构,分别针对写入和读取场景进行针对性优化。在 Delta Layer 中,数据的粒度是 ColumnFile。
除了上述两种 ColumnFile 以外,还有其他 ColumnFile 也比较重要,以下是一个 ColumnFile 的总体列表:
该结构包含 Block 数据,数据在内存中、尚未被持久化。参见 ColumnFileInMemory.h。
大多数对 DeltaTree 引擎的写入操作都会封装为 ColumnFileInMemory 进行后续处理。
它仅仅是一个虚类,代表了所有继承自它的 ColumnFile 的数据都已经持久化在了磁盘中。参见 ColumnFilePersisted.h。
继承自 ColumnFilePersisted。它指向一个已经存储于磁盘上的 DMFile 数据,参见 ColumnFileBig.h。DMFile 是 Stable 层数据的基本格式,后边将进行详细解释。
在接受来自 Raft 层的全量数据快照(Raft Snapshot)时,构建的就是 ColumnFileBig 而非 ColumnFileInMemory。除此以外,Major Compaction 过程也会构建 ColumnFileBig。
继承自 ColumnFilePersisted。如前文所述,它指向一个已经存储在了 PageStorage 中的 Delta 层 Block 数据,参见 ColumnFileTiny.h。
在 Flush 过程中,ColumnFileInMemory 会在将数据持久化后将自己转化为 ColumnFileTiny 来标记自己的数据已经被持久化了。除此以外,若写入过程收到的数据块较大,也会直接构造出 ColumnFileTiny,从而节约内存使用。
继承自 ColumnFilePersisted。它代表在一个 Handle 范围内所有数据都被清除了,参见 ColumnFileDeleteRange.h。例如,在加入新 TiFlash 节点后,其他 TiFlash 节点上副本的数据会被重新调度、以达到分布均匀的状态。此时会有 Region 副本在某些 TiFlash 节点上被擦除。这种范围内无差别的数据擦除便是通过 ColumnFileDeleteRange 来实现的,避免了普通的数据删除过程中需要先读取、再写入删除标记这种低效率的方式。
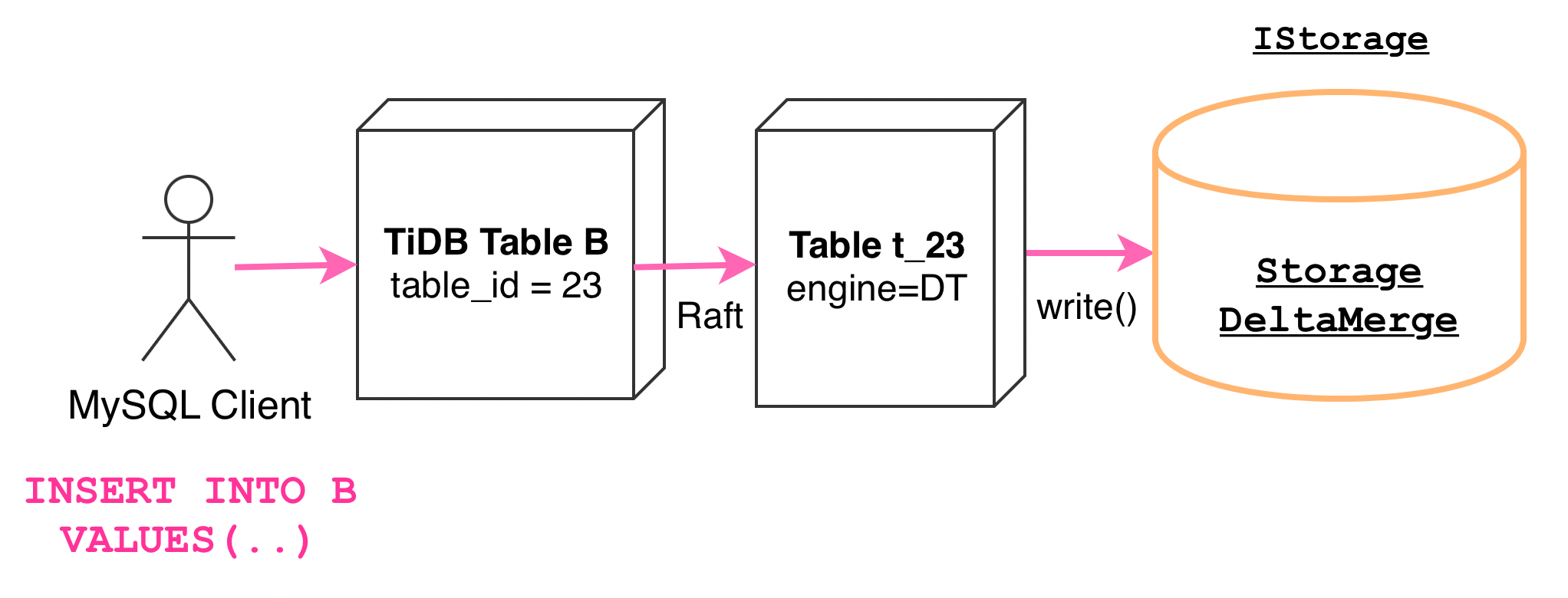
DeltaTree 对外提供的写入接口中会做这些事情:
1.对收到的 Block 进行排序。
排序方式是 (Handle, Version)。这个排序方式与 TiKV 一致,使得 TiFlash 能保持和 TiKV 一样的数据先后顺序。
2.对 Block 按照 Segment 值域进行切分,并写入到各个 Segment 的 MemTableSet 中。
在写入的过程中,若当前 Segment 已积压的数据过多了,写入会被阻塞(Write Stall)并等待 Segment 完成更新。例如,可能用户猛烈地写入了大批数据,积压了大量数据来不及进行 Flush 或进行 Compaction。
若不需要 Write Stall,则 Block 数据会被写入到一个已有的、位于 MemTableSet 的 ColumnFileInMemory 中,或 Block 数据比较大的话,则写入到一个 ColumnFileTiny 中、再加入 MemTableSet。
3.尝试对 Segment 进行更新。
例如,尝试触发 Flush、Compaction、Segment 的合并和分裂等。
此时,单次写入操作便已完成。详情可参见 DeltaMergeStore::write(Block)函数了解详细实现。
需要注意的是,在前台写入路径上,数据写入到内存 MemTableSet 中就写入完毕、可以返回了,后续涉及磁盘 IO 的 Flush 及 Merge Delta 操作都是后台操作,不会对写入延迟产生直接影响。另外,由于 IO 发生在 Flush 阶段,而非写入阶段,因此这也起到了对于高频写入减少 IO 的效果。
既然写入返回时数据还没写入到磁盘上,那么此时掉电了怎么办?实际上由于 TiFlash 从 TiKV Raft log 同步数据,因此 Raft log 即为 TiFlash 数据的 WAL。在掉电后,从上次已经完成 Flush 操作的 Raft Apply 位置恢复数据即可。
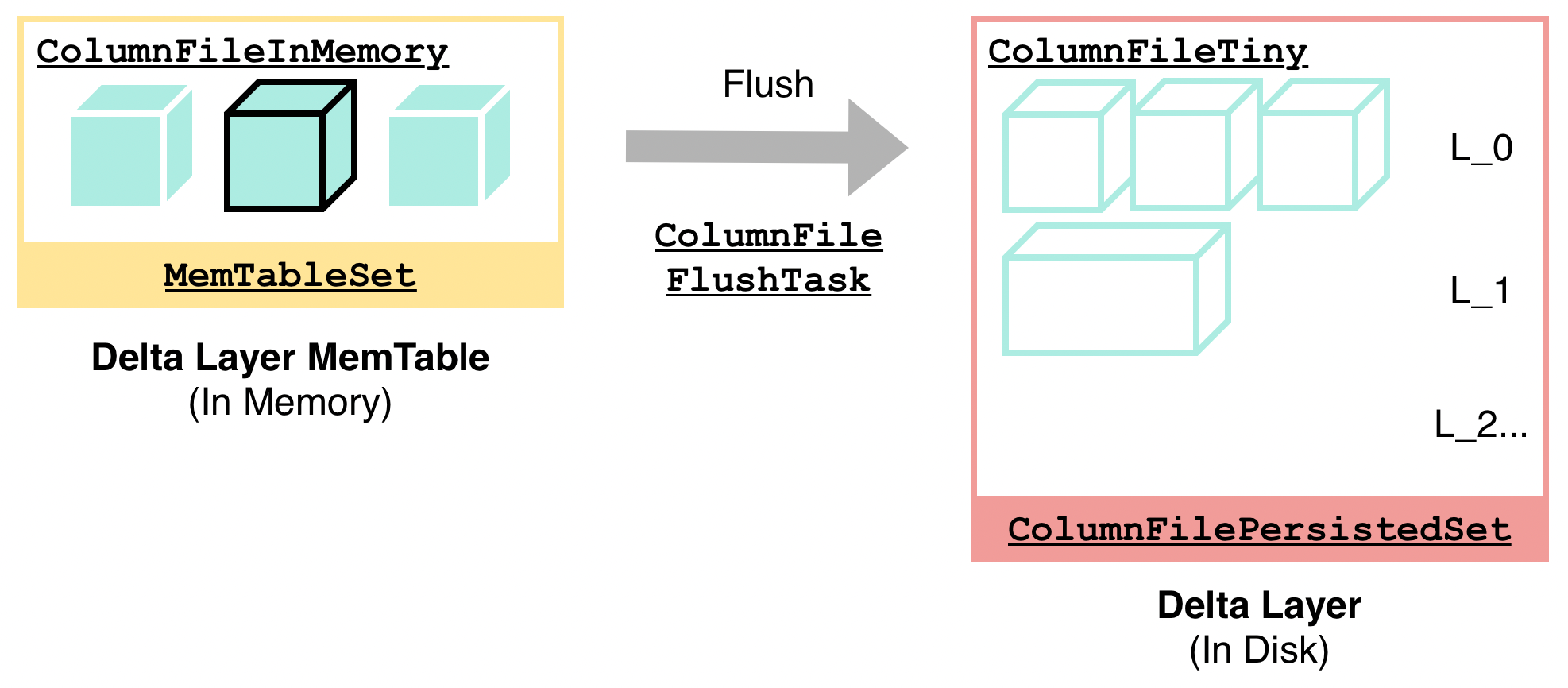
通过 Flush 过程,内存中的数据会被写入到 Delta Layer 的持久化存储(PageStorage)中,步骤如下:
在上述过程中,有一个比较有意思的设计是,DeltaTree 会采用类似于乐观锁的方式,尽可能减少上锁时间,并采用事后回退的方式处理冲突。例如,多个 Flush 可能同时发生——一个 Flush 在前台写入中触发,一个 Flush 在后台触发。在这个情况下,只有一个 Flush 会完成并成功修改内存结构。通过这种设计,整个结构上锁的时间内去除了可能有显著延迟的 IO 等操作,从而缩短了整个结构的上锁时间,提高了性能。读者会在接下来的其他 DeltaTree 的步骤中频繁地见到这种上锁模式。
详细可参见 DeltaValueSpace::flush函数及 ColumnFileFlushTask.h。
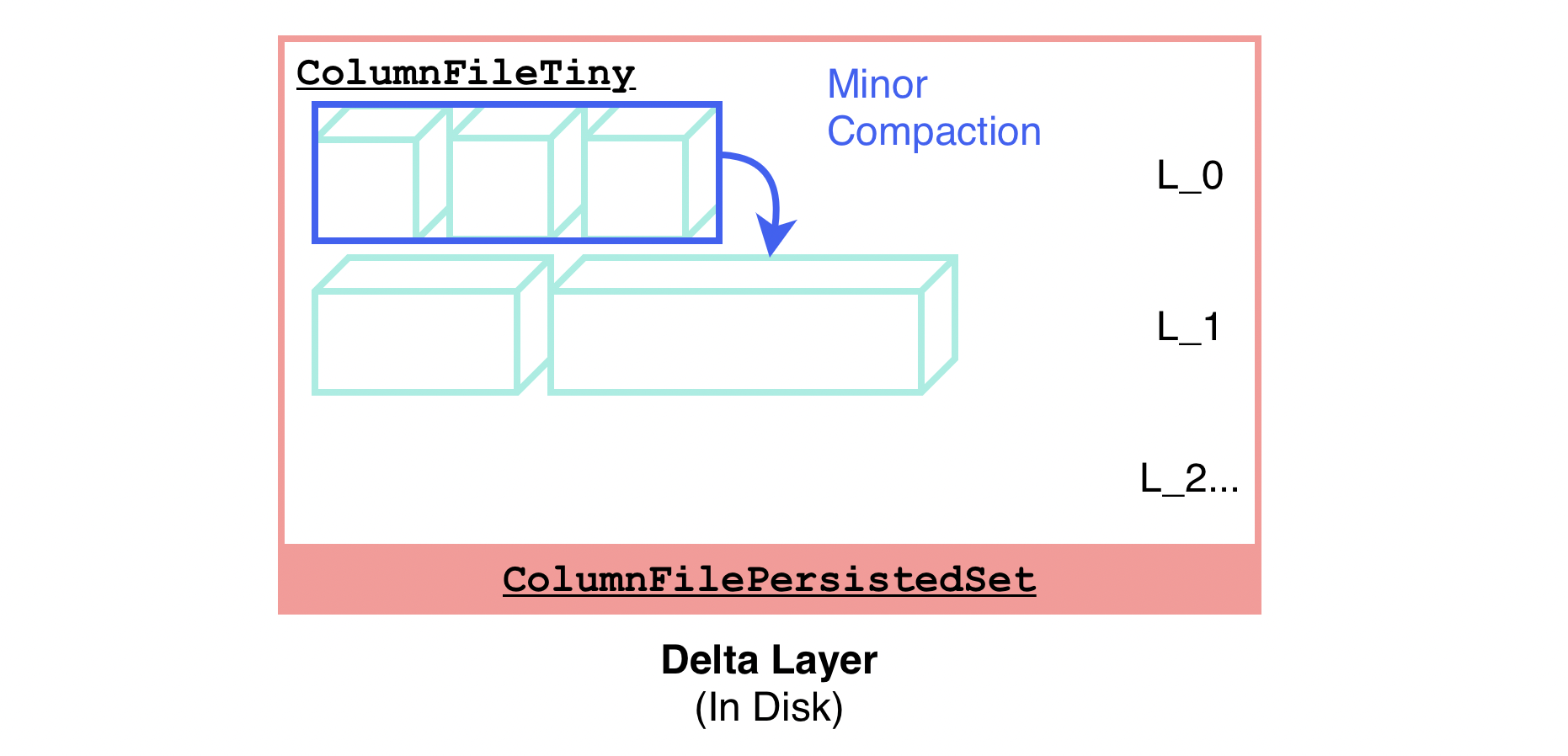
ColumnFilePersistedSet 可能会包含比较多的零碎小数据块,这些小数据块直到触发 Major Compaction(即 Merge Delta)时才会被清理、合并,这会对读的过程带来比较高的 IOPS。为了节约读 IOPS,DeltaTree 后台会持续对零碎的、小的 ColumnFileTiny 进行合并,合成一个大的 ColumnFileTiny,这个过程称为 Minor Compaction。
DeltaTree 的 Minor Compaction 过程会形成类似于 LSM Tree 的多层结构,与 LSM Tree 有些相似,但不完全一致。例如,在当前设计中,Delta Layer 每一层的每一个 ColumnFileTiny 都不保证有序(合并 ColumnFileTiny 时仅仅是简单地数据头尾相接),而且各层的 ColumnFileTiny 之间也会有值域重叠。因此,在发起读请求的时候,事实上这些 ColumnFileTiny 实际上都有可能需要被读取到。
Minor Compaction 过程如下,同样也是 Lock + Prepare + Lock & Apply 的模式:
详细可参见 DeltaValueSpace::compact函数。
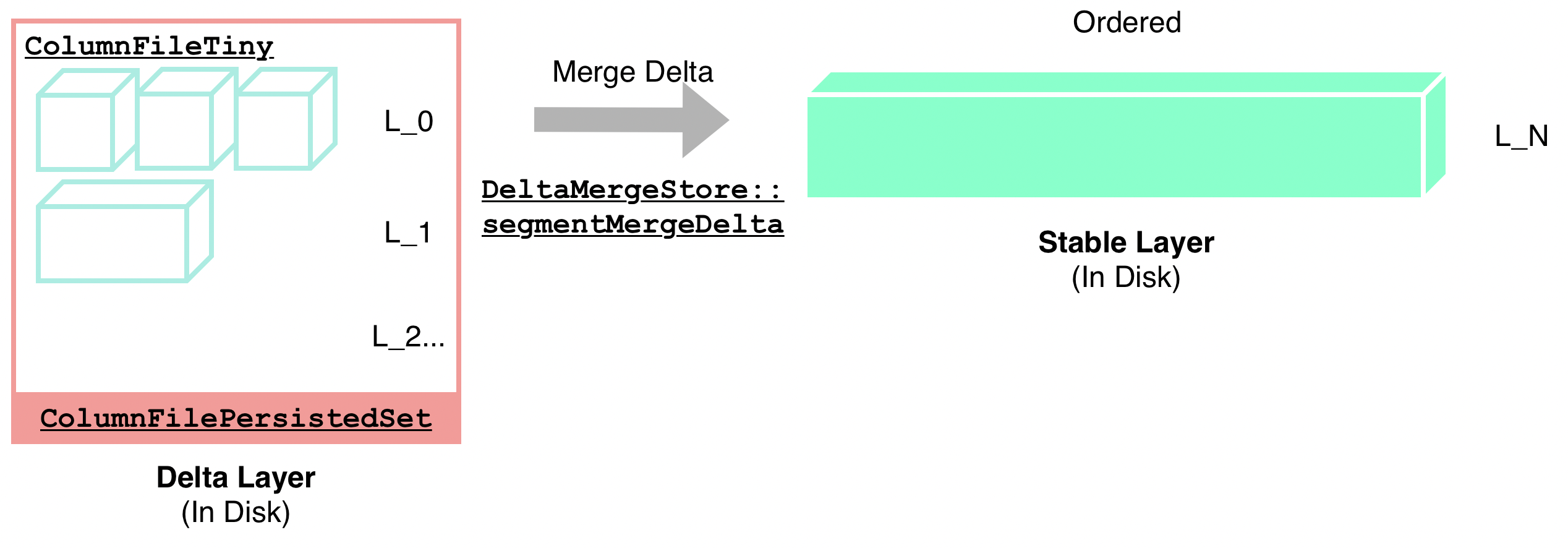
Delta 层已持久化的增量更新数据与 Stable 层已持久化的、面向读优化的大部分数据进行合并的过程称为 Merge Delta,它也是整个 DeltaTree 存储引擎最主要的数据整理操作(Major Compaction)。在这个过程中,该 Segment 的整个 Stable 层数据会与整个 Delta 层数据进行合并,替换生成一个新的 Stable 层数据,步骤如下:
详细可参见 DeltaMergeStore::segmentMergeDelta函数。
Stable 层的数据按照 (Handle, Version) 排序,并切分了多个 Pack 作为 IO 粒度(每个 Pack 大约是 8192 行,通过 dt_segment_stable_pack_rows参数控制)。单一列内数据相邻地存储在一起,总体逻辑结构如下图所示:
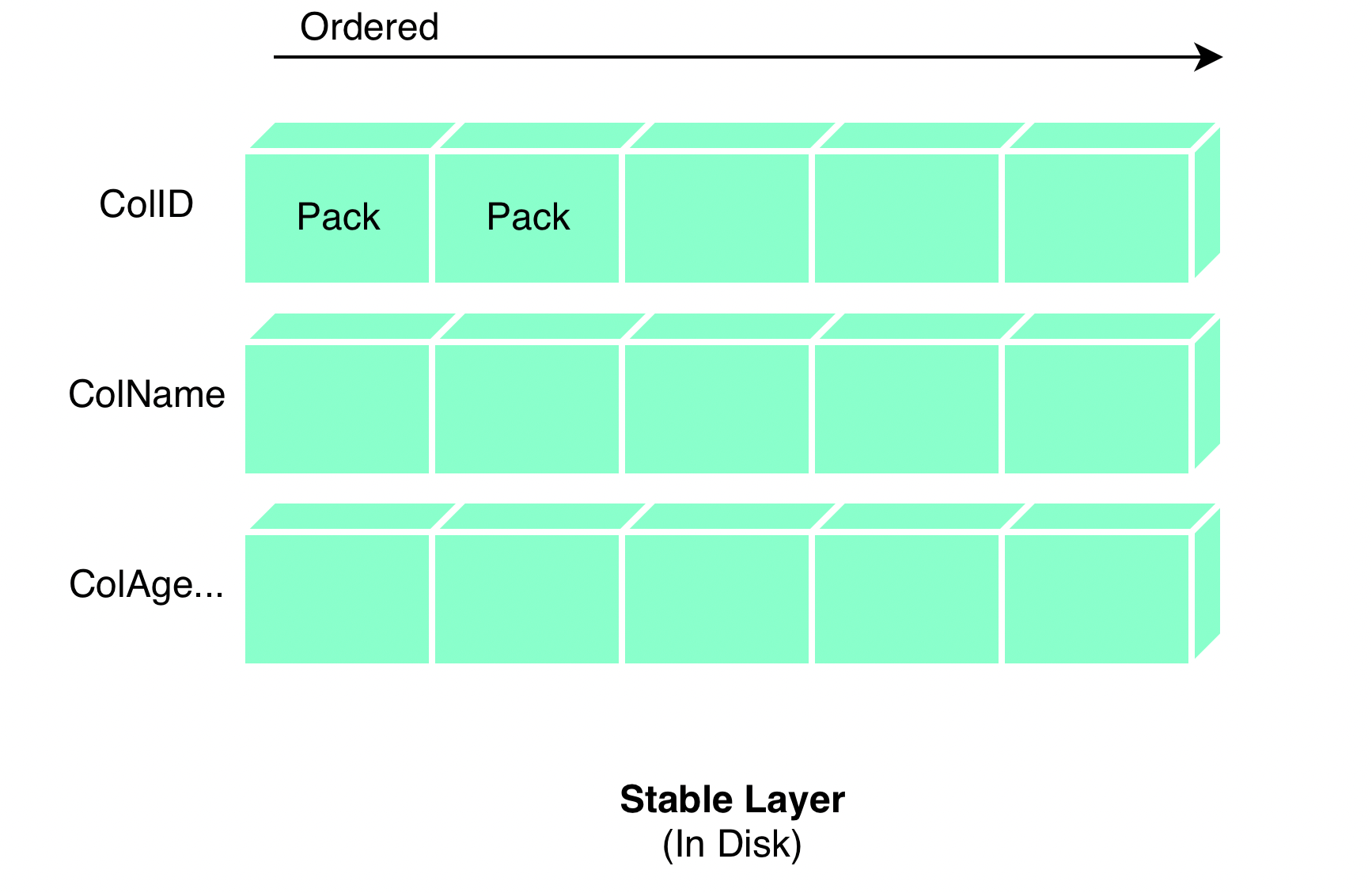
不同于 Delta 通过 PageStorage 在磁盘上存储数据,Stable 层直接将上述结构及数据存储在磁盘文件上,该存储格式被称为 DMFile。虽然名字中有个 file,但 DMFile实际是一个文件夹,其内部包含的文件如下所示:
存储了每个 Pack 的信息,例如 pack 中实际有多少行等等。详细可参见 PackStats结构。
记录了 DMFile 的格式(例如 V1、V2)等。
记录了该 DMF 的一些配置信息,目前主要包含各个数据文件的 Checksum 方式等配置。详细可参见 DMChecksumConfig结构。
压缩存储了 col_id 列的数据。默认情况下压缩方式是 LZ4,可通过 dt_compression_method参数进行配置。
标记文件,存储了各个 Pack 在 .dat 文件中的 offset。在读取数据内容时,可以通过这个标记文件中记录的偏移信息,跳过并只读取特定 Pack 的数据。详细可参见 MarkInCompressedFile结构。
索引文件,目前 DeltaTree 只支持 Min Max 索引,该文件会存储 col_id 列在各个 Pack 区间上的最大最小值。在查询时,一些列上的查询条件可通过这里的 Min Max 索引跳过不需要的 Pack,从而减少 IO。详细可参见 MinMaxIndex结构。
对一个系统加深理解的最好方法莫过于动手实践了。由于 TiFlash 保留了 Clickhouse Client 兼容的 SQL 查询接口,因此可以通过这个内部接口来对本文中描述的各种概念进行实验。
启动包含 TiFlash 的 TiDB 集群后,可以通过 tiup tiflash client快捷地通过 Clickhouse SQL 接口连入 TiFlash:
# Start Server$ tiup playground nightly# Run TiFlash Client$ tiup tiflash client --host 127.0.0.1复制连入后,你可以执行大部分 Clickhouse SQL 语句(推荐仅进行查询语句),例如 SELECT、SHOW TABLES等,也可以执行 TiFlash 特有的 Clickhouse SQL 语句,如:
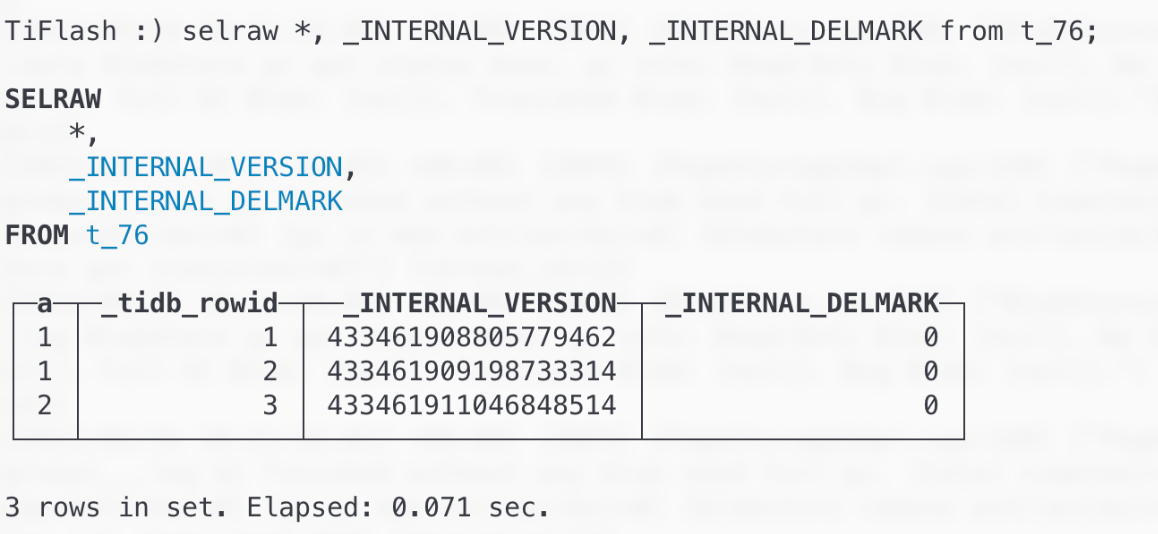
除了 SELRAW语句以外,DBGInvoke也是一个常用的内部语句,本文不作详细展开,读者可在 TiFlash 源码中搜索 > DBGInvoke查询到在各个测试文件中是如何调用 DBGInvoke语句查询或操作内部结构的。
本文主要针对 DeltaTree 引擎写入过程中涉及到的各个模块及其设计进行了分析。由于篇幅原因,从 DeltaTree 引擎中读数据的过程及相应优化将在下一篇中进行分析,读者可关注 TiFlash 源码解读的后续更新。另外,本文也仅仅是呈现了一个 TiFlash 给出的「答案」,即存储引擎设计成什么样可以支撑可更新、可高频写入、可进行高性能 OLAP 分析这些需求。至于这个「答案」本身是如何的得出来的、背后的设计思路及取舍并没有涵盖。我们将在下一期 TiFlash 源码阅读中给出详细的介绍。