kafka配置jmx_exporter
点击:https://github.com/prometheus/jmx_exporter,选择下面的jar包下载:

将下载好的这个agent jar包上传到kafka的broker节点所在服务器上,每个broker都需要,比如上传到如下路径:
/opt/agent/jmx_prometheus_javaagent-0.16.1.jar复制修改kafka启动脚本: bin/kafka-server-start.sh,增加java agent配置如下:
JMX_EXPORTER_OPTS="-javaagent:/opt/agent/jmx_prometheus_javaagent-0.16.1.jar=9095:/opt/agent/kafka_broker.yml"export KAFKA_JMX_OPTS="$KAFKA_JMX_OPTS $JMX_EXPORTER_OPTS"复制这两行代码可以添加在脚本首部。
这里指定了9095作为端口,jmx_exporter用到的kafka_broker.yml 配置如下:https://github.com/xxd763795151/kafka-exporter/blob/main/kafka_broker.yml
将kafka每个broker都这样配置,重启kafka。
Prometheus配置
修改prometheus的配置prometheus.yml,增加如下配置:
- job_name: 'kafka' metrics_path: /metrics static_configs: - targets: ['kafka1:9095', 'kafka2:9095', 'kafka3:9095'] labels: env: "test"复制
p.s. 注意job_name不要修改,值就是"kafka",要不我下面的grafana不能直接用,还需要每个面板依次修改。
Grafana配置
下面的Grafana面板我已经配置好,可以直接拿来用,之后可以根据需要增加或删除相关面板:https://github.com/xxd763795151/kafka-exporter/blob/main/grafana.json
贴几个截图:
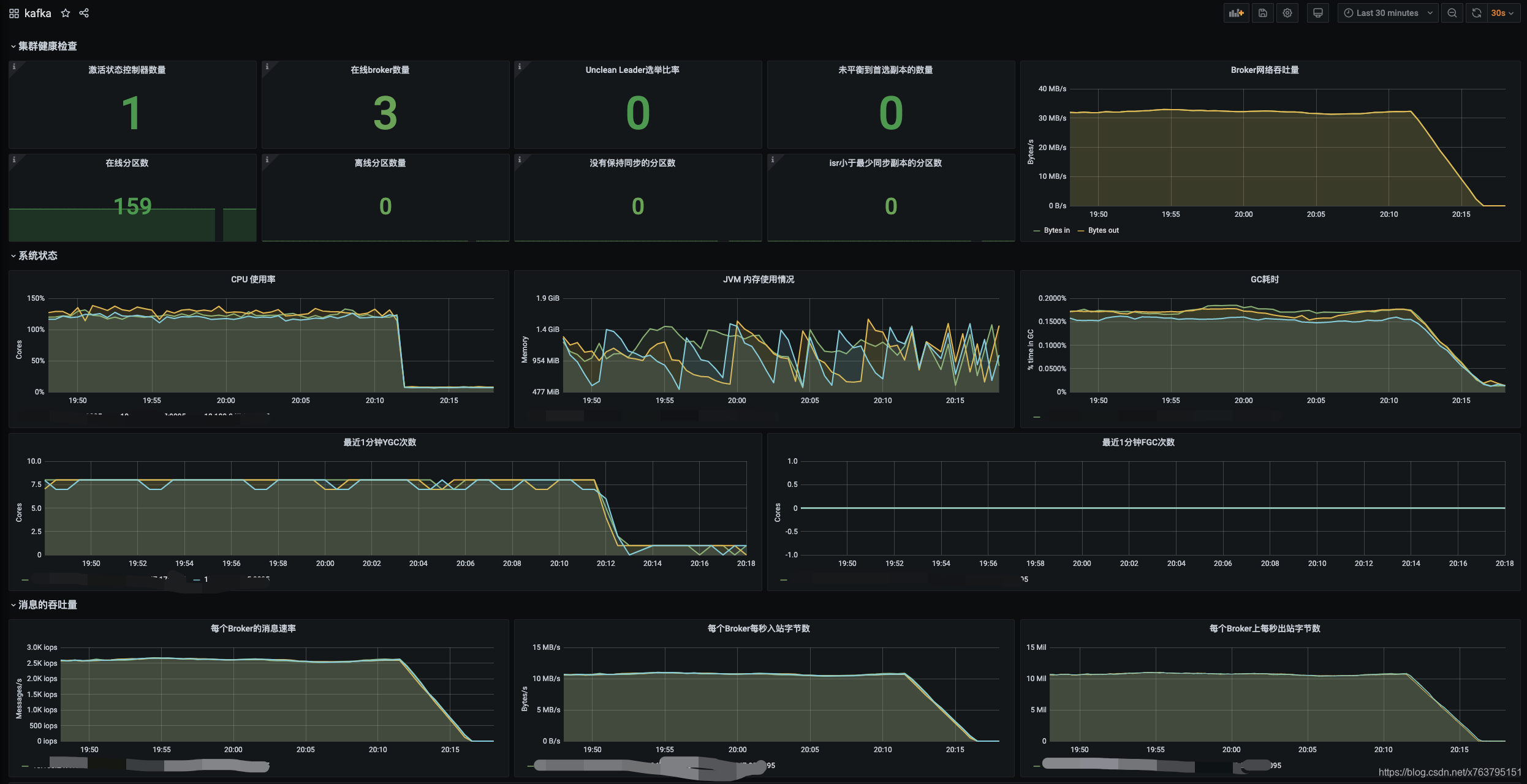
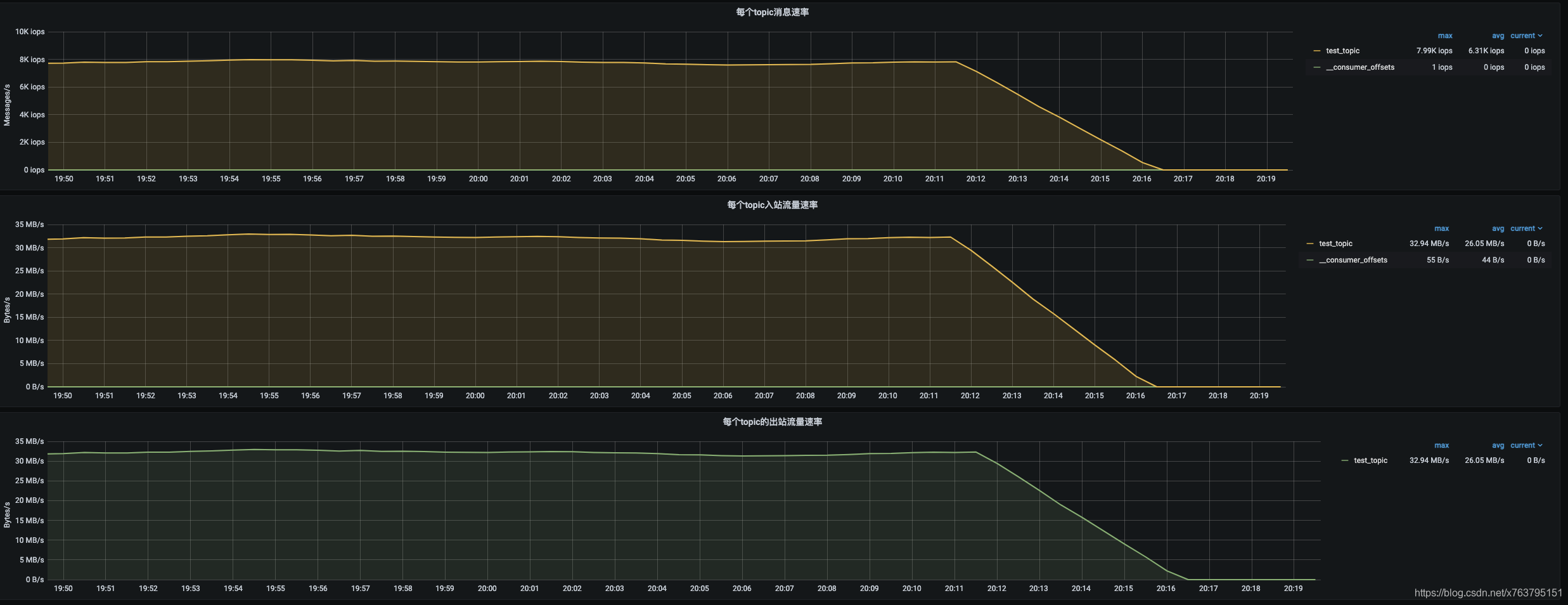

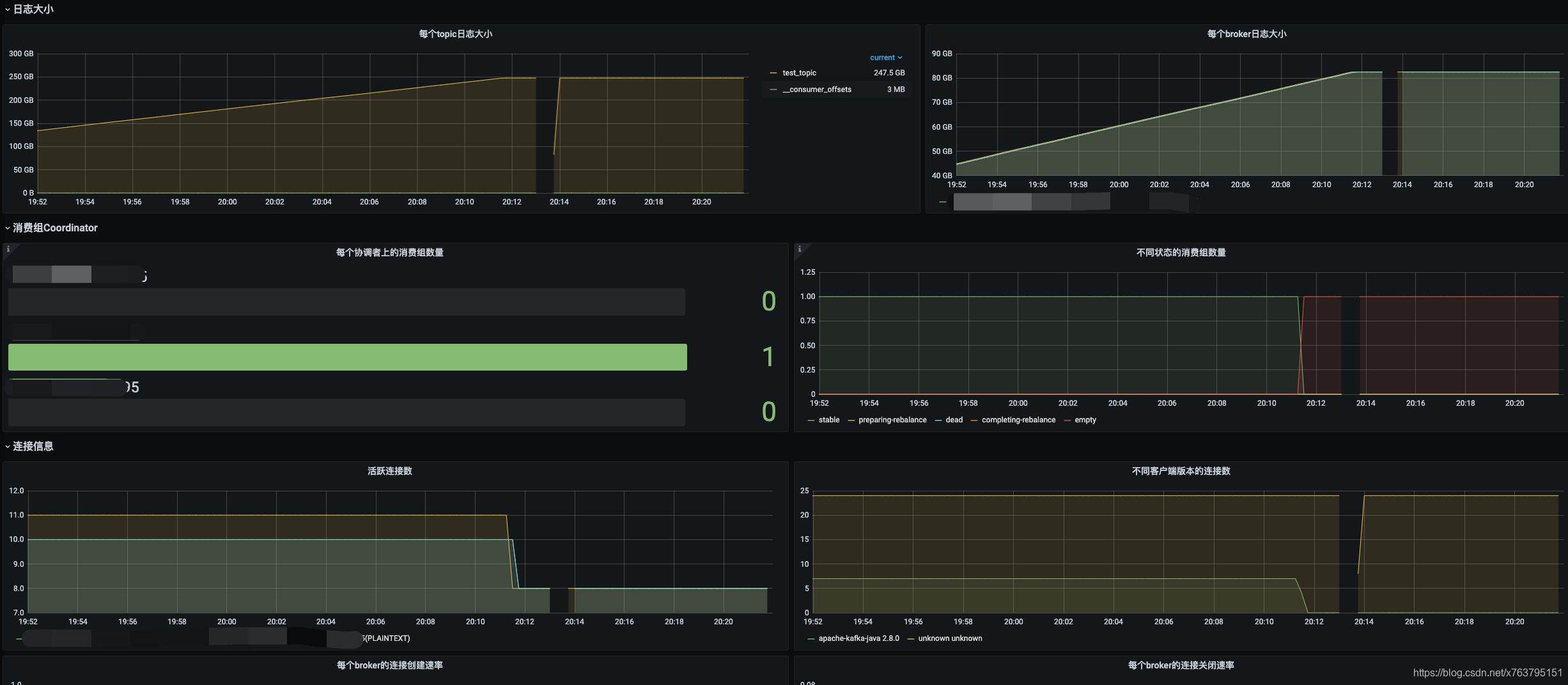
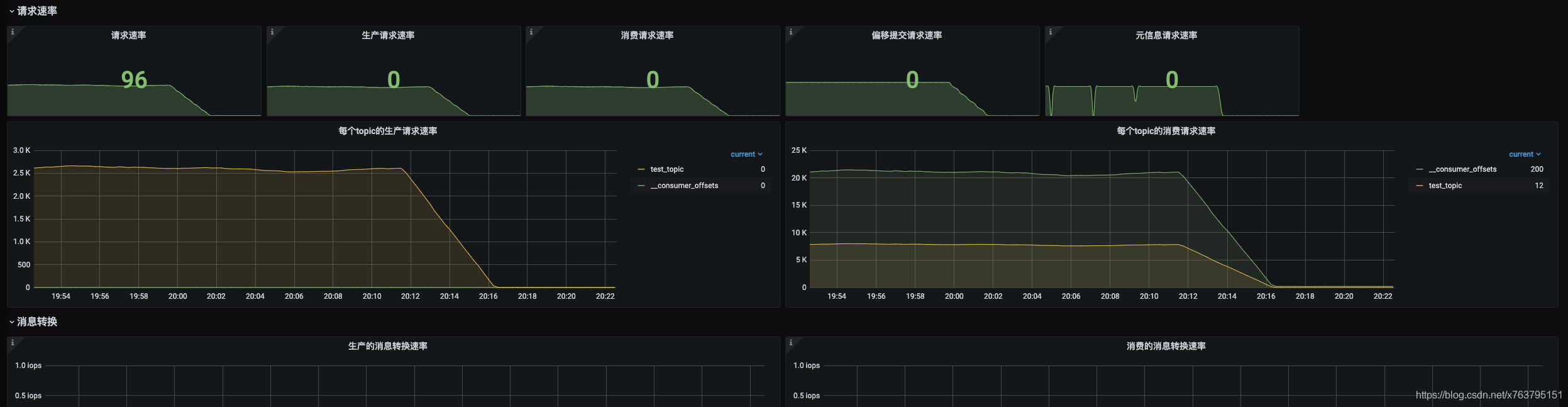
消息积压
在kafka的broker端无法直接获取消息积压等指标信息,这些数据在消费端上,我们也不太可能去连接所有的消费端获取监控信息。
所以,我单独写了一个kafka-exporter可以获取消息积压的监控指标:https://github.com/xxd763795151/kafka-exporter
点击这个链接进入github仓库后,根据说明进行部署并配置启动后,然后在prometheus.yml增加如下配置:
- job_name: 'kafka-exporter' metrics_path: /prometheus static_configs: - targets: ['kafka-expoter-host:9097'] labels: env: "test"复制
上面的grafana配置里已经包含了消息积压的面板:
 如果后续有其它指标在jmx里不提供,也可以继续补充kafka-exporter,刮取更多需要的metrics。
如果后续有其它指标在jmx里不提供,也可以继续补充kafka-exporter,刮取更多需要的metrics。
告警
最新的配置代码会提交在这里: https://github.com/xxd763795151/kafka-exporter/blob/main/kafka_alert.yml
示例如下:
groups: - name: Kafka测试集群告警 rules: - alert: "kafka集群,出现脑裂" expr: sum(kafka_controller_kafkacontroller_activecontrollercount{env="test"}) by (env) > 1 for: 0m labels: severity: warning annotations: description: '激活状态的控制器数量为{{$value}},集群可能出现脑裂' summary: '{{$labels.env}} 集群出现脑裂,请检查集群之前的网络' - alert: "kafka集群没有活跃的控制器" expr: sum(kafka_controller_kafkacontroller_activecontrollercount{env="test"}) by (env) < 1 for: 0m labels: severity: warning annotations: description: '激活状态的控制器数量为{{$value}},没有活跃的控制器' summary: '{{$labels.env}} 集群没有活跃的控制器,集群可能无法正常管理' - alert: "kafka节点挂了" expr: count(kafka_server_replicamanager_leadercount{env="test"}) by (env) < 3 for: 0m labels: severity: warning annotations: description: '{{$labels.env}} 集群的节点挂了,当前可用节点:{{$value}}' summary: '{{$labels.env}} 集群的节点挂了' - alert: "kafka集群出现leader不在首选副本上的分区" expr: sum(kafka_controller_kafkacontroller_preferredreplicaimbalancecount{env="test"}) by (env) > 0 for: 1m labels: severity: warning annotations: description: '{{$labels.env}} 集群出现leader不在首选副本上的分区,数量:{{$value}}' summary: '{{$labels.env}} 集群出现leader不在首选副本上的分区,分区副本负载不均衡,考虑使用kafka-preferred-replica-election脚本校正' - alert: "kafka集群离线分区数量大于0" expr: sum(kafka_controller_kafkacontroller_offlinepartitionscount{env="test"}) by (env) > 0 for: 0m labels: severity: warning annotations: description: '{{$labels.env}} 集群离线分区数量大于0,数量:{{$value}}' summary: '{{$labels.env}} 集群离线分区数量大于0' - alert: "kafka集群未保持同步的分区数大于0" expr: sum(kafka_server_replicamanager_underreplicatedpartitions{env="test"}) by (env) > 0 for: 0m labels: severity: warning annotations: description: '{{$labels.env}} 集群未保持同步的分区数大于0,数量:{{$value}}' summary: '{{$labels.env}} 集群未保持同步的分区数大于0,可能丢失消息' - alert: "kafka节点所在主机的CPU使用率过高" expr: irate(process_cpu_seconds_total{env="test"}[5m])*100 > 50 for: 10s labels: severity: warning annotations: description: '{{$labels.env}} 集群CPU使用率过高,主机:{{$labels.instance}},当前CPU使用率:{{$value}}' summary: '{{$labels.env}} 集群CPU使用率过高' - alert: "kafka节点YCG太频繁" expr: jvm_gc_collection_seconds_count{env="test", gc=~'.*Young.*'} - jvm_gc_collection_seconds_count{env="test", gc=~'.*Young.*'} offset 1m > 30 for: 0s labels: severity: warning annotations: description: '{{$labels.env}} 集群节点YCG太频繁,主机:{{$labels.instance}},最近1分钟YGC次数:{{$value}}' summary: '{{$labels.env}} 集群节点YCG太频繁' - alert: "kafka集群消息积压告警" expr: sum(consumer_lag{env="test"}) by (groupId, topic, env) > 20000 for: 30s labels: severity: warning annotations: description: '{{$labels.env}} 集群出现消息积压,消费组:{{$labels.groupId}},topic:{{$labels.topic}},当前积压值:{{$value}}' summary: '{{$labels.env}} 集群出现消息积压' - alert: "kafka集群网络处理繁忙" expr: kafka_network_socketserver_networkprocessoravgidlepercent{env="test"} < 0.3 for: 0s labels: severity: warning annotations: description: '{{$labels.env}} 集群网络线程池不太空闲,可能网络处理压力太大,主机:{{$labels.instance}},当前空闲值:{{$value}}' summary: '{{$labels.env}} 集群网络处理繁忙' - alert: "kafka集群IO处理繁忙" expr: kafka_server_kafkarequesthandlerpool_requesthandleravgidlepercent_total{env="test"} < 0.3 for: 0s labels: severity: warning annotations: description: '{{$labels.env}} 集群IO线程池不太空闲,可能处理压力太大,需要调整线程数,主机:{{$labels.instance}},当前空闲值:{{$value}}' summary: '{{$labels.env}} 集群IO处理繁忙'复制

末语
我从grafana 官方上搜索了几个dashboard,但指标实在太少。感谢从这篇博文里找到的grafana配置可以参考,提供了很多指标的面板,可以让我对着kafka官方监控jmx说明进行整理,让我在grafana面板的配置上,省了一半的功夫:
https://www.confluent.io/blog/monitor-kafka-clusters-with-prometheus-grafana-and-confluent/