https://zhuanlan.zhihu.com/p/618947904 通用预训练语言模型.复制
ChatGPT 正在迅速发展与传播,新的大型语言模型 (LLM) 正在以越来越快的速度开发。就在过去几个月,有了颠覆性的 ChatGPT 和现在的 GPT-4。明确定义,GPT 代表(Generative Pre-trained Transformer),是底层语言模型,而 ChatGPT是为会话设计的具体实现。比尔·盖茨 (Bill Gates) 回顾 OpenAI 的工作时说,“人工智能时代已经开始”。如果感到难以跟上快速变化的步伐,那么并不孤单。就在刚才,超过 1000 名研究人员签署了一份请愿书,要求在未来六个月内暂停训练比 GPT-4 更强大的 AI 系统。
尽管技术成就显着,但它们仍然是闭门造车。尽管它的名字,OpenAI 长期以来一直受到一些人的批评,因为它没有发布他们的模型,甚至被一些人称为 ClosedAI。研究人员和爱好者都在努力寻找开源替代品。
如果错过了最近的发展,应该看看 Meta 的 LLaMA ( GitHub ),它应该优于 GPT-3。它是在 GNU 许可下获得许可的,虽然它不是严格开源的,但可以在注册后获得权重。这种开放显然是为了 LLaMA 的利益,社区很快就继续开发它。它很快以 llama.cpp 的形式移植到 C/C++,斯坦福大学的研究人员将其扩展到一个指令跟随模型,例如 ChatGPT,并将其命名为 Alpaca。还有 GPT4All,这篇博文是关于它的。
首先,来反思一下社区在短时间内开发开放版本的速度有多快。为了了解这些技术的变革性,下面是各个 GitHub 仓库的 GitHub 星数。作为参考,流行的 PyTorch 框架在六年内收集了大约 65,000 颗星。下面的图表是大约一个月。
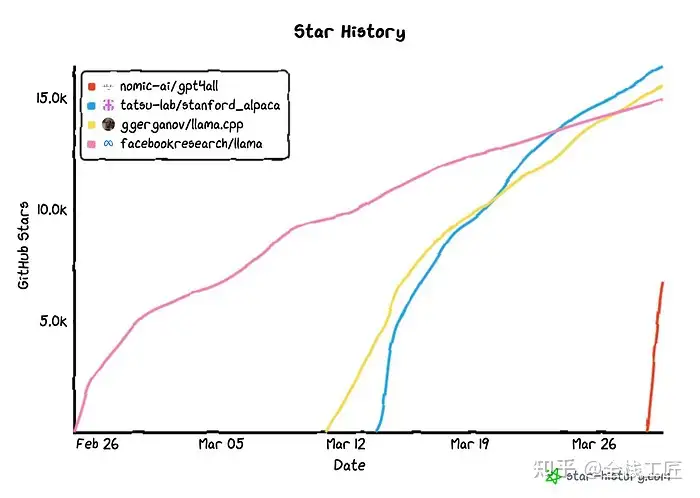
但现在,来更深入地介绍 GPT4All。这是 Nomic AI 的助手式聊天机器人,刚刚公开发布。
如何基于现有的语言模型(如 LLaMA)创建类似 ChatGPT 的助手式聊天机器人?答案可能会大吃一惊:与聊天机器人互动并尝试了解它的行为。就 gpt4all 而言,这意味着从公开可用的数据源收集各种问题和提示样本,然后将它们交给 ChatGPT(更具体地说是 GPT-3.5-Turbo)以生成 806,199 个高质量的提示生成对。接下来,整理数据并删除低多样性响应,并确保数据涵盖广泛的主题。训练数据后,发现他们的模型比同类产品表现更好。
对我来说,其中一个主要吸引力在于作者发布了模型的量化 4 位版本。这是什么意思?实际上,在模型中以降低的精度而不是全精度执行某些操作,因此可以拥有更紧凑的模型。虽然像 ChatGPT 这样的模型在 Nvidia 的 A100 等专用硬件上运行,这是一款配备高达 80 GB RAM 的硬件怪兽,价格为 15,000 美元,但对于 GPT4All,意味着可以在消费级硬件上执行该模型。
运行 GPT4All 的说明很简单,只要安装了正在运行的 Python,按照 GitHub 存储库上的设置说明进行操作即可。
4.2 Gb 的大小,完全下载需要一定的时间在 M1 MacBook Pro 上对此进行了测试,这意味着只需导航到 chat- 文件夹并执行 ./gpt4all-lora-quantized-OSX-m1。
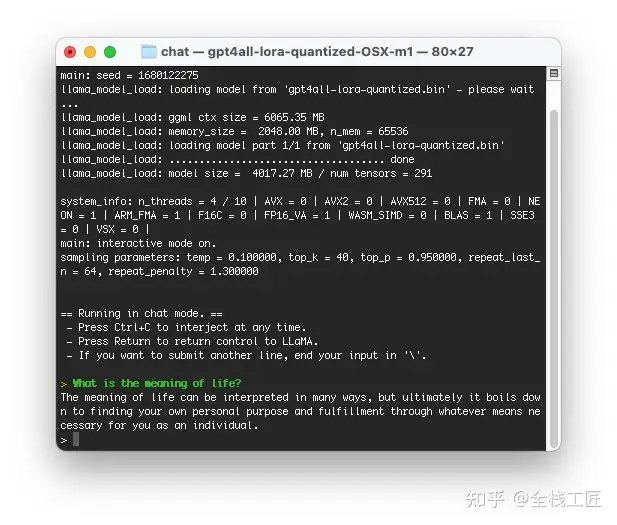
设置一切应该需要几分钟,下载是最慢的部分,结果是实时返回的。
现在,准备运行的 GPT4All 量化模型在基准测试时表现如何?虽然有详尽的基准测试集,但以下是可以预期的一些快速见解:

虽然有一些明显的错误(NLP -> NLU),但实际上对输出感到非常惊讶。
可以尝试一些更有创意的东西,比如诗歌:

发现这确实非常有用,同样,考虑到这是在 MacBook Pro 笔记本电脑上运行的。虽然它可能不在 GPT-3.5 甚至 GPT-4 级别,但它肯定有一些魔力。
使用 GPT4All 时,请牢记作者的使用注意事项:
GPT4All 模型重量和数据仅用于研究目的并获得许可,禁止任何商业用途。GPT4All 基于 LLaMA,具有非商业许可。辅助数据是从 OpenAI 的 GPT-3.5-Turbo 收集的,其使用条款禁止开发与 OpenAI 进行商业竞争的模型。
此外,请注意 ChatGPT 具有多项安全功能。
开源项目和社区努力在实施技术和加速创意方面非常强大。GPT4All 就是一个显着的体现。从根本上说,这为闭源模型的业务方面提供了一个有趣的视角。如果提供 AI 作为服务,那么需要多长时间才能让爱好者对 AI 进行足够长的探索以能够模仿它?对于 GPT4All 的案例,论文中有一个有趣的注释:花了四天的时间,GPU 成本 800 美元,OpenAI API 调用 500 美元,这具有足够的吸引力。
关于文件 gpt4all-lora-quantized.bin 的下载问题,可以通过下面的链接下载: