正文
TiKV占用内存超过的解决过程
背景
为了后去TiDB的极限数据.
晚上在每台服务器上面增加了多个TiKV的节点.
主要方式为:
每个NVME的硬盘增加两个TiKV的进程.
这样每个服务器两个磁盘, 共计4个TiKV的进程
因为TiKV其实会使用尽可能多的缓存:
storage.block-cache 表示RocksDB 多个 CF 之间共享 block cache 的配置选项。
当开启时,为每个 CF 单独配置的 block cache 将无效。
shared
是否开启共享 block cache。
默认值:true
capacity
共享 block cache 的大小。
默认值:系统总内存大小的 45%
单位:KB|MB|GB
复制
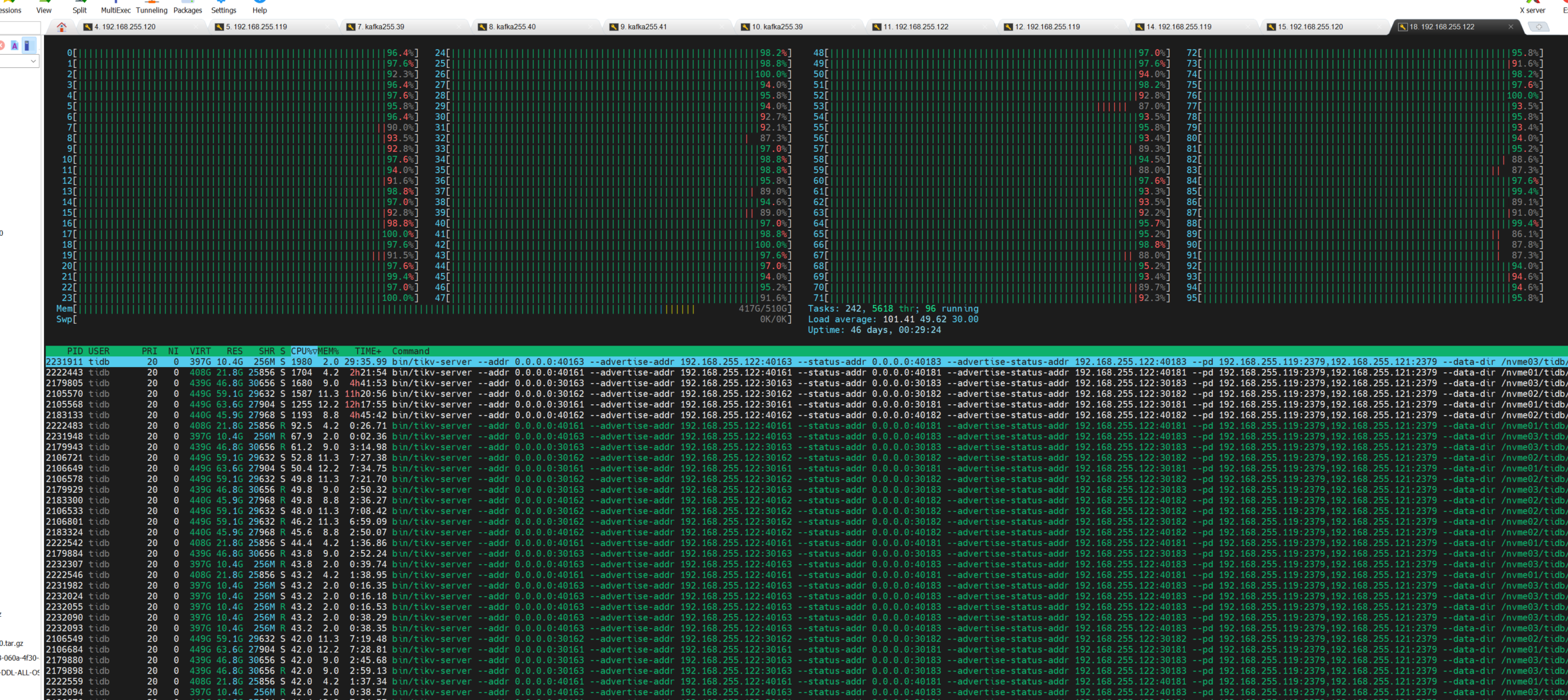
问题现象
因为这种情况下:
我一个机器四个TiKV甚至还要多. 导致 block cache里面的内容其实可能大于总体内存.
直接导致内存爆满, CPU也爆高,机器宕机.
现象为:
复制
解决方案
1. 修改配置文件:
tiup cluster edit-config erptidb
在tikv 下面增加配置主要为:
server_configs:
tidb:
enforce-mpp: true
mem-quota-query: 64294967296
tikv:
storage.block-cache.capacity: 32G
注意这个内存可以进行一下自己的计算和选择
2. 执行部分处理
tiup cluster reload erptidb -N someip:20160
3. 注意tikv的重启非常慢. 可能会有问题. 建议如果是测试环境时
执行 第二步里的设置之后就会出现reconfig了.
然后可以看看tidb的安装目录下面的 tikv-20160/config 下面的toml 文件
就会看到配置被分发了
然后可以执行 systemctl restart tikv-20160
注意如果自己的tikv比较多. 端口不一样, 服务可能也是不一样的, 需要单独重启.
复制
注意事项
其实不建议这样处理
重启tikv 如果日志没有落盘的话可能会出现问题
导致数据库宕机.
建议至少要备份一下数据库.
注意需要先进行测试验证, 再修改.
复制