01
背景
某tidb集群收到告警,TIKV 节点磁盘使用率85%以上,联系业务无法快速删除数据,于是想到扩容TIKV 节点,原先TIKV 节点机器都是6TB的硬盘,目前只有3TB的机器可扩,也担心region 均衡后会不会打满3TB的盘,PD 调度策略来看应该是会根据不同存储机器的资源配置和使用情况进行打分,region balance 优先根据leader score 和region score 往分低的机器均衡数据来让不同节点机器的数据处于一种均衡状态,但是PD 有时候也不是智能的,会出现偏差,导致某个节点磁盘打满也未可知,这时候就需要人为干预了,我就遇到了在不同存储节点扩容tikv导致小存储容量节点磁盘差点打满的情况,所以一般建议优先相同存储容量的盘进行扩容。
02
集群环境
Tidb:5节点
PD:3节点
TIKV:10节点 6TB 硬盘
集群总量:45TB ,每个TIKV 4.5TB
03
实施分析过程
由于业务不断增长,整个集群使用率接近80%,业务无法删除数据,于是决定扩容tikv节点,没有6TB的大盘机器,所以扩容了1个3TB的TIKV节点,可以考虑调整 PD 调度参数 region-schedule-limit 以及 leader-schedule-limit 来控制调度速度,调大可加快均衡速度,但是对业务会产生一定影响,过小速度会慢点,不着急的话默认值就行。
扩容TIKV
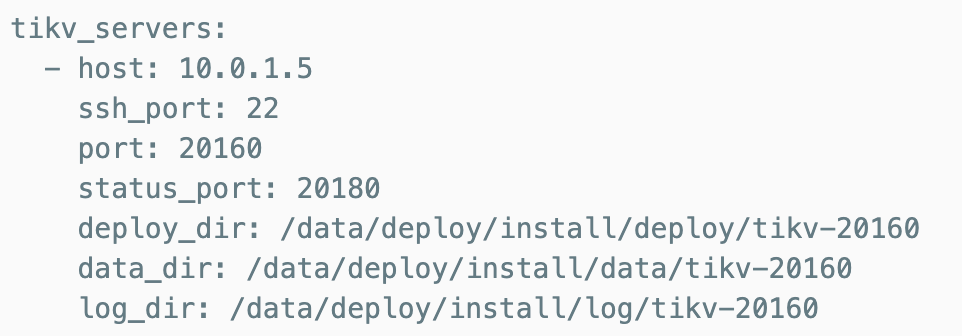
tiup cluster scale-out <cluster-name> scale-out.yaml
扩容完成后,经过一天一夜,收到告警,新扩容的机器磁盘已经90%,并基本维持在这个量级,比较纳闷,难道是错怪PD了,可能PD有参数限制智能使用磁盘的90%就不往该节点均衡数据了。
查阅官方文档发现下面参数low-space-ratio,确实是可以设置每个节点tikv的磁盘最大使用率。
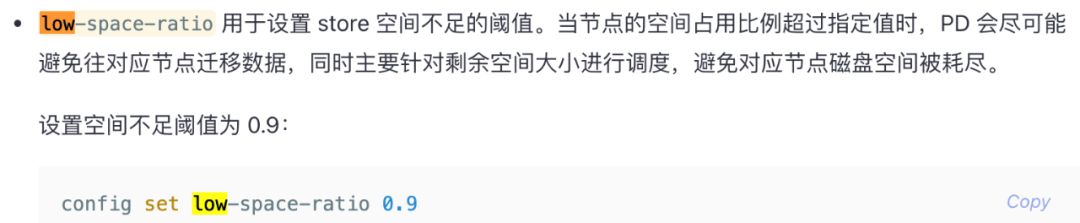
确实是错怪PD了,以为它调度策略出现了偏差,回过头来看这个参数不能针对某个节点进行设置,生效的是所有节点,因为该集群6TB盘使用率在80%左右,所以也不好设置低于80%的参数,对我来说意义不大了,那就得需要寻找其它策略去均衡迁移数据了。
查看PD 监控

Store Region score 差不多是6TB 盘的一半左右,那三个163w的是相隔1天扩容的3个节点,看的出score 更低。
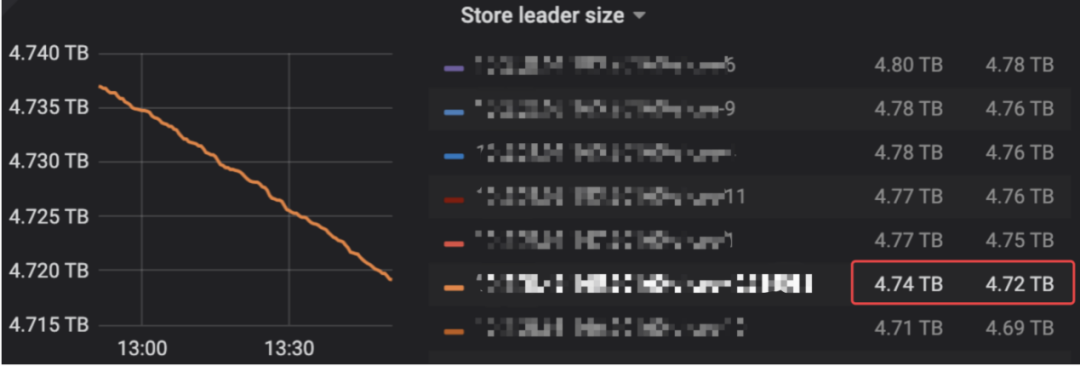
这里leader size 显示大小和原先6TB 盘接近,显示超过本身3TB 盘大小。
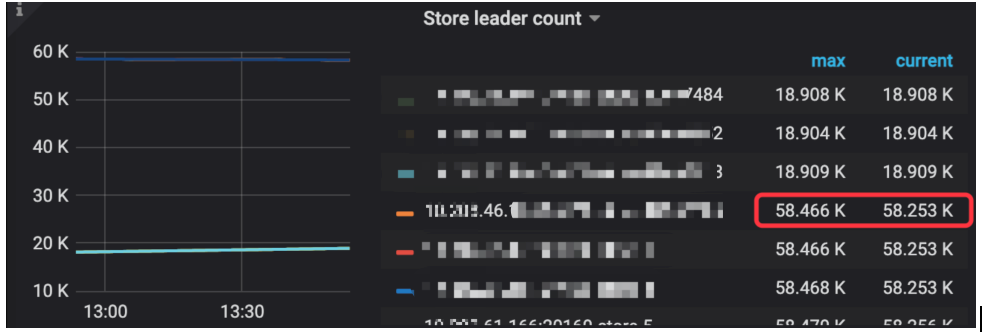
Store leader count 显示大小和原先存在的6TB TIKV 节点一样大。

显示Store Region size 是6.89TB ,实际硬盘使用在2.7TB 左右,为啥差距这么大呢?
监控指标store region zize 和 leader region size 大小取值的计算方式,由于多版本和 TiKV会压缩数据导致实际落盘存储大小和监控显示指标差距比较大,当超过500GB 数据采用zstd高压缩方式,压缩比大约3倍。
摘录 tidb-in-action的一段 :

至此就明白了上面监控数值显示大小和实际硬盘存储大小区别了,数据写入首先写入到rocksdb,然后由rocksdb进行落盘操作的。
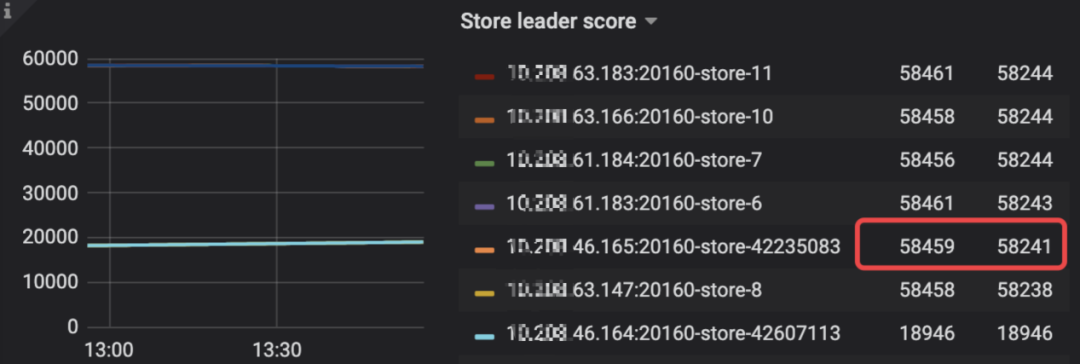
Store leader score 分数已和原先的Tikv 节点近似,说明store leader 已均衡,但是region score 还偏低,还会持续有其它节点数据balance 过来,于是开始调整PD region_weight,leader_weight 参数来控制每个tikv 节点的分数,比如分别调整为0.5。
pd-ctl -i-u http://ip:2379
》store
》
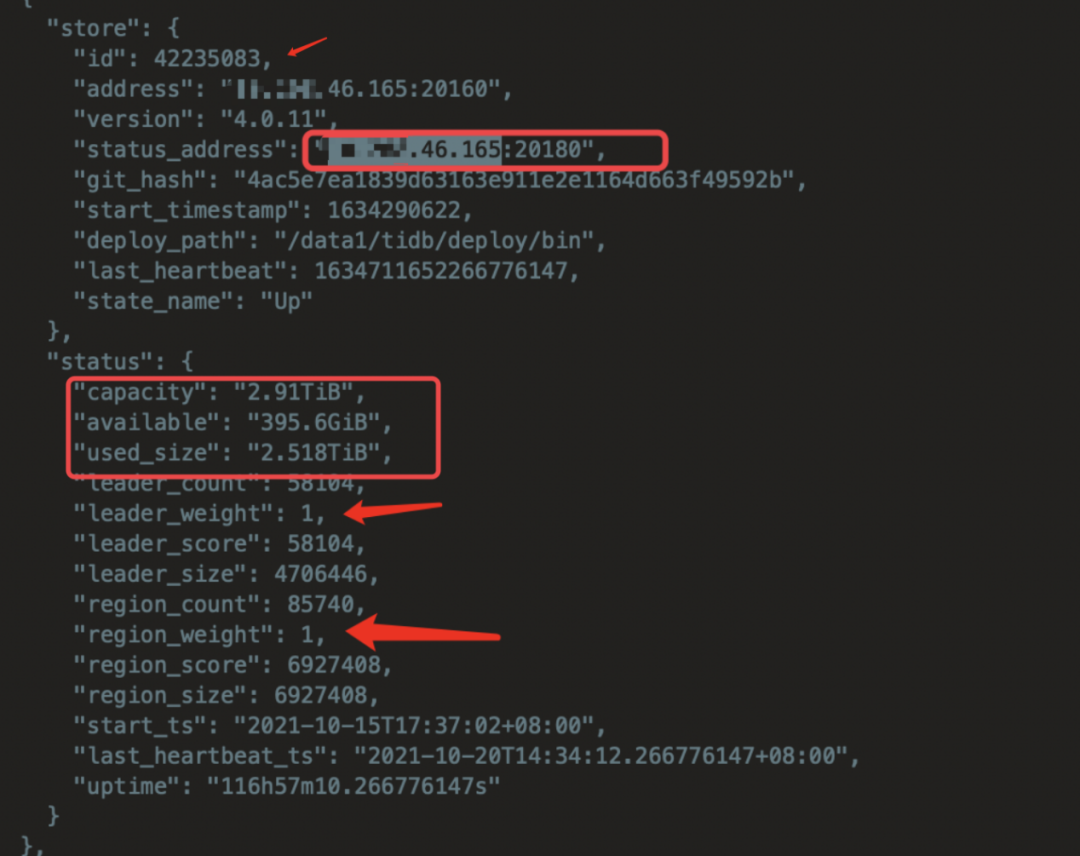
》store weight 42607484 0.5 0.5

官方文档也给出说明了,因为新扩容磁盘容量大约为旧TIKV 节点的一半,所以我暂时通过调整权重来让新扩容的节点来存储旧集群数据量的一半。

调整后过12小时后再看,发现磁盘使用率已经降低到70%左右,说明参数起作用了,再逐步把region 转移到其它机器上。

04
总结
日常运维中还需要加强对Tidb 各个组件内部调度原理的学习,仔细研读官方文档,不然出事难免慌张,不知所措,感谢PingCap提供asktug 这个平台让我们可以搜索到很多实践运维案例,少走很多弯路。