https://zhuanlan.zhihu.com/p/368440685复制
本文的数据来自网络,部分代码也有所参照,这里做了注释和延伸,旨在技术交流,如有冒犯之处请联系博主及时处理。
ERROR 1055 (42000): Expression #1 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'trial.B.dname' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by
编写SQL时需要如下错误,即出现错误 ERROR 1055,SELECT列表不在GROUP BY语句内且存在不函数依赖GROUP BY语句的非聚合字段'trial.B.dname',这是和sql_mode=only_full_group_by不兼容的(即不支持)。

Way 1: 临时关闭only_full_group_by模式,这种方法通过修改系统变量,重启数据库后失效。首先查看下当前的sql_mode:
show VARIABLES LIKE 'sql_mode';复制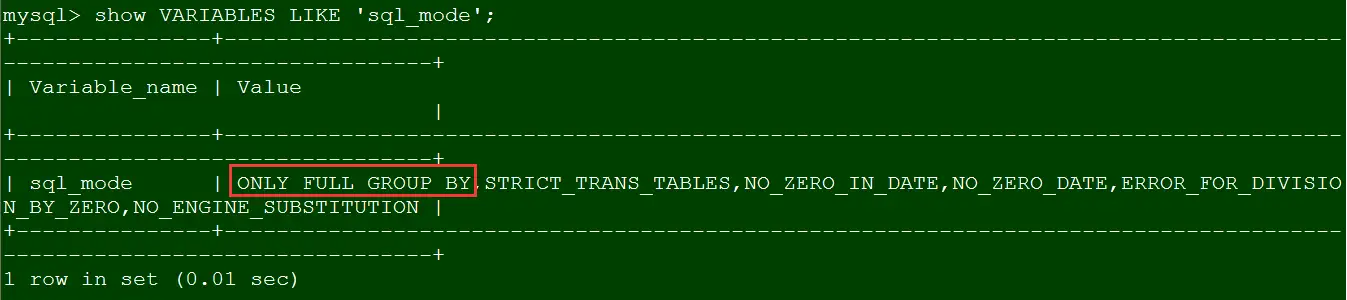
set global sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION';复制注:修改后需在新的回话里验证原SQL。
Way2:永久关闭only_full_group_by模式,这种方法需要在mysql的配置文件里修改,然后重启。
Step 1 找到配置文件/etc/my.cnf(或则关联文件夹找到mysql-server.cnf)
Step 2: 在上述文件内的[mysqld]后追加
sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION'
Step 3:保存配置文件后,重启Mysql即可。
啥,这就这么结束?!来来,我们来拉拉mysql的groupby和sql_mode only_full_group_by模式。开始之前我们得来些料。
首先我们先了解下SQL92标准里关于group by的定义。
SQL-92 and earlier does not permit queries for which the select list, HAVING condition, or ORDER BY list refer to nonaggregated columns that are not named in the GROUP BY clause.
简单的说:SQL-92里 SELECT、HAVING、ORDER后的非聚合字段必须和GROUP BY后的字段保持完全一致。来个例子瞧瞧呗?如下以sql server2019为例:
--正确的”姿势”
SELECT B.dname,B.deptno,MAX(sal) FROM emp A
JOIN dept B
ON A.deptno = B.deptno
GROUP BY B.deptno,B.dname;
--错误的“姿势”
SELECT B.dname,B.deptno,MAX(sal) FROM emp A
JOIN dept B
ON A.deptno = B.deptno
GROUP BY B.deptno;复制
但是我们经常看到MYSQL的SELECT列表的字段并不在GROUP BY后,这又是咋回事?话不多说,先上几个案例。
-- Msyql:
-- Case 1(此脚本在sql server里报错)
SELECT B.deptno,B.dname,MAX(sal) FROM emp A
JOIN dept B
ON A.deptno = B.deptno
GROUP BY B.deptno;复制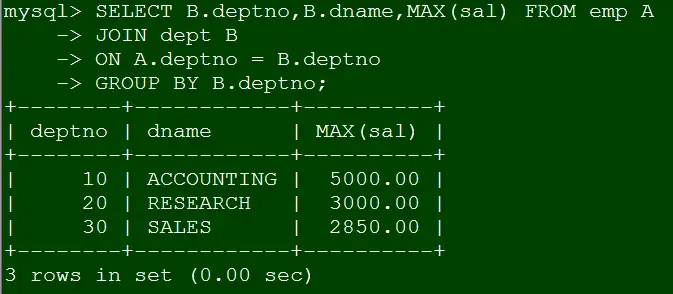
但为什么mysql就能支持呢?
SQL:1999 and later permits such nonaggregates per optional feature T301 if they are functionally dependent on GROUP BY columns: If such a relationship exists between name and custid, the query is legal. This would be the case, for example, were custid a primary key of customers.
SQL 99登场,这里即是定义了新的标准,如果group by后面的字段是主键(唯一键),而且非聚合字段是函数依赖group by后字段的,那么可以将这些非聚合字段放在SELECT、HAVING、ORDER BY的语句之后。
MySQL implements detection of functional dependence. If the ONLY_FULL_GROUP_BY SQL mode is enabled (which it is by default), MySQL rejects queries for which the select list, HAVING condition, or ORDER BY list refer to nonaggregated columns that are neither named in the GROUP BY clause nor are functionally dependent on them.
Mysql 实现了这种检测函数依赖,这时ONLY_FULL_GROUP_BY SQL 模式登场,mysql里SQL mode设置了这种模式那么如果 group by后的不补全字段或是无函数依赖的字段时非聚合字段放在SELECT、HAVING、ORDER BY的语句之后是不支持的。
有点绕,我们直接开启个案例来说明ONLY_FULL_GROUP_BY有何魔力。
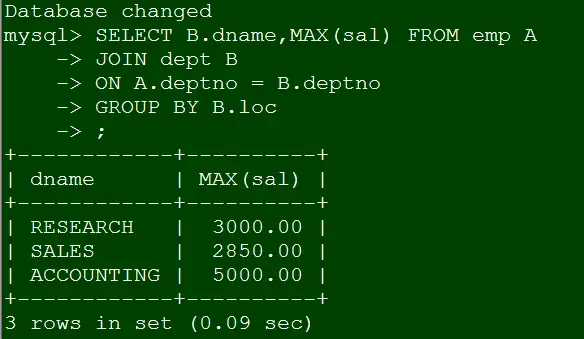
-- Case 2:
SELECT B.dname,MAX(sal) FROM emp A
JOIN dept B
ON A.deptno = B.deptno
GROUP BY B.loc复制
原因分析,这里group by后的字段loc并没有定义为主键或则唯一键,所以在sql mode是ONLY_FULL_GROUP_BY模式下报错(即不支持)。
我们再来个简单些的例子,即只涉及一张表。
Case 3:
--创建一张无主键、唯一键的表,插入4条记录(id字段的值不重复)。
CREATE TABLE `test_04251019` (
`id` int DEFAULT NULL,
`name` varchar(10) DEFAULT NULL,
`addr` varchar(12) DEFAULT NULL,
`memo` varchar(40) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO `test_04251019` VALUES ('1', 'hanmeimie', 'Guangzhou', 'Fullbakup');
INSERT INTO `test_04251019` VALUES ('2', 'lilei', 'Guangzhou', 'in increament');
INSERT INTO `test_04251019` VALUES ('4', 'Tom', 'Shanghai', 'no more');
INSERT INTO `test_04251019` VALUES ('5', 'John', 'Shanghai', 'no more_5');
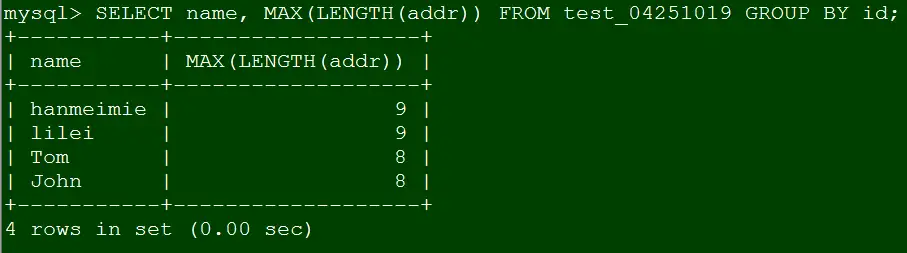
此时我们仿照Case 2写个简单点的聚合语句
SELECT name, MAX(LENGTH(addr)) FROM test_04251019 GROUP BY id;复制

原因分析,此时id的值虽然不重复,但是未在表定义里体现(比如id定义为主键)。
-- Case 4:
CREATE TABLE `test_04251019_key` (
`id` int NOT NULL,
`name` varchar(10) DEFAULT NULL,
`addr` varchar(12) DEFAULT NULL,
`memo` varchar(40) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
INSERT INTO test_04251019_key(id,name,addr,memo)
SELECT id,name,addr,memo FROM test_04251019;
COMMIT;
ALTER TABLE test_04251019_key ADD id_2 int NOT NULL;
UPDATE test_04251019_key SET id_2 = 100+id;
ALTER TABLE test_04251019_key ADD CONSTRAINT unique_id_2 UNIQUE(id_2);
SELECT name, MAX(LENGTH(addr)) FROM test_04251019_key GROUP BY id;
SELECT name, MAX(LENGTH(addr)) FROM test_04251019_key GROUP BY id_2;复制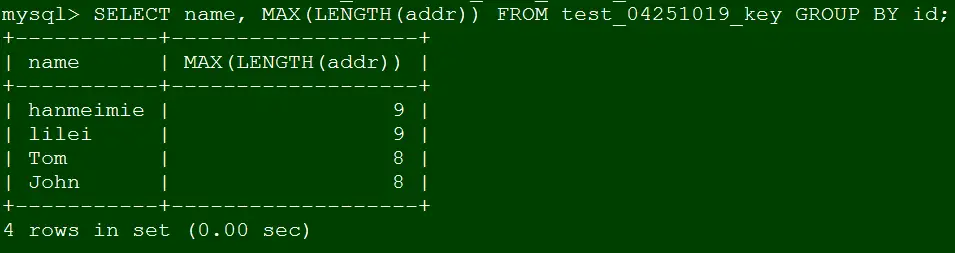
分析:此时不报错id、id_2字段分别定义为主键、唯一键,那么name作为非聚合字段和id、id_2有依赖依赖关系,所以语法支持。
一眼不合,我们就关闭。那么我们来关闭only_full_group_by模式,这里通过修改系统变量的方式。
set global sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION';
show variables like 'sql_mode';复制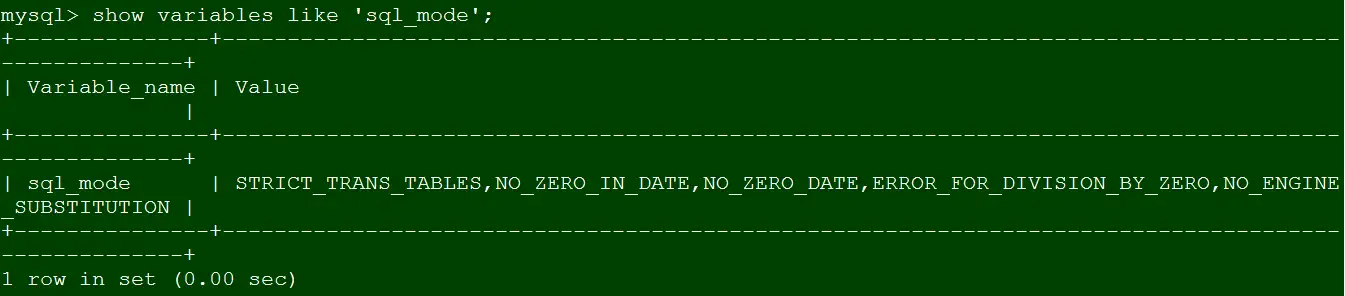
这时我们来验证Case 2和Case 3都神奇的不报错了。
-- Case 5:追加案例,针对case 3,如果我们往test_04251019里插入一条记录
INSERT INTO test_04251019 VALUES(5,'Jim','Shanghai2','no more_5_2');
-- 再执行
SELECT name, MAX(LENGTH(addr)) FROM test_04251019 GROUP BY id;复制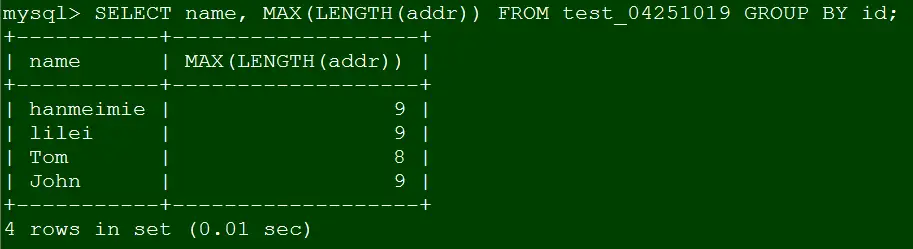
那么Jim这条记录对应的GROUP BY统计去哪儿了?
无
敲黑板
Mysql里的sql mode=only_full_group_by模式是对SQL92 group by的扩展,即对应SQL1999的标准。
SQL92 group by里要求SELECT、HAVING、ORDER BY语句后的字段需要与GROUP BY后的字段严格一致。
Myslq里sql mode=only_full_group_by模式SELECT、HAVING、ORDER BY语句后的字段可以不跟GROUP BY后的字段严格一致,但是GROUP BY的字段需是主键或唯一键时可以写非聚合字段。
Myslq里sql mode非only_full_group_by模式时在表的定义不严格的情况下(如无明确的主键且数据重复时作为GROUP BY后的字段 )执行结果难以解释。
更多详细细节,详见官网Mannul。复制