https://tidb.net/blog/ad45bad9#6%E6%80%BB%E7%BB%93复制
随着tidb使用场景的越来越多,接入的业务越来越重要,不由得想试验下tidb组件的高可用性以及故障或者灾难如何恢复,恢复主要涉及的是pd组件和tikv组件,本文主要涉及tikv组件,
pd组件请参考另外一篇文章《pd集群多副本数据丢失以及修复实践》pd集群多副本数据丢失以及修复实践
tidb版本:5.2.1
$ cat tidb-test.yaml
global:
user: "tidb"
ssh_port: 22
deploy_dir: "/data/tidb/tidb-deploy"
data_dir: "/data/tidb/tidb-data"
pd_servers:
- host: 10.12.16.225
- host: 10.12.16.226
- host: 10.12.16.227
tidb_servers:
- host: 10.12.16.225
- host: 10.12.16.226
- host: 10.12.16.227
tikv_servers:
- host: 10.12.16.224
- host: 10.12.16.225
- host: 10.12.16.226
- host: 10.12.16.227
- host: 10.12.16.228
monitoring_servers:
- host: 10.12.16.228
grafana_servers:
- host: 10.12.16.228
alertmanager_servers:
- host: 10.12.16.228复制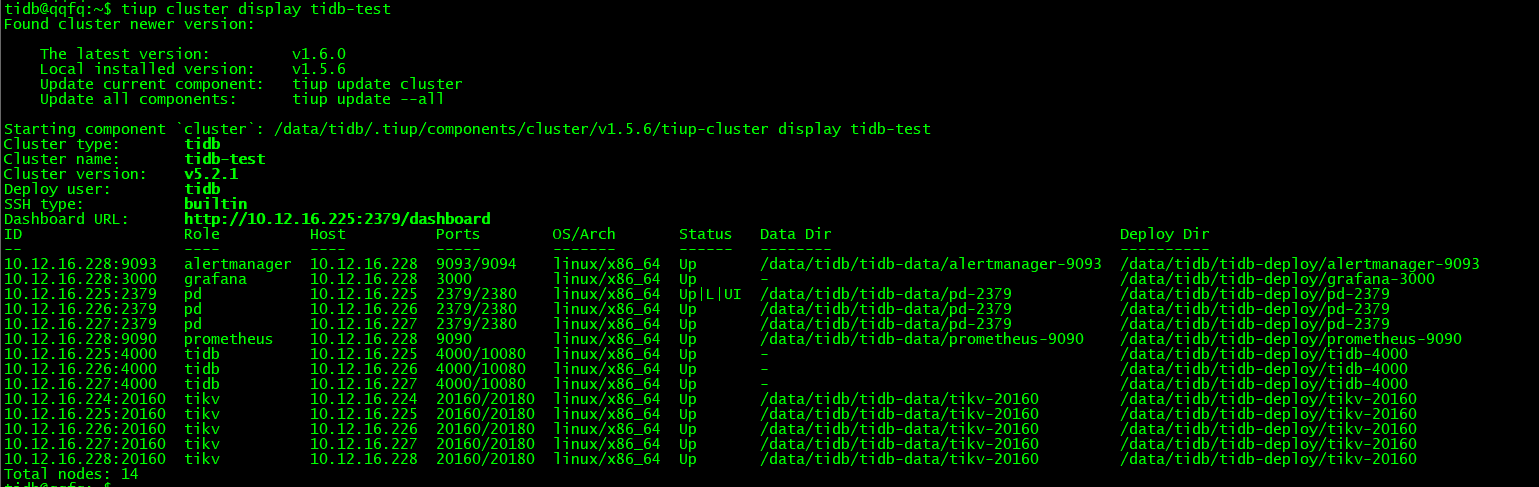
replica=3
防止tiup部署后,在破坏掉tikv实例后,tikv-server被自动拉起来,影响试验效果,需要做如下修改
1、在/etc/systemd/system/tikv-20160.service中去掉 Restart=always或者改Restart=no,
2、执行systemctl daemon-reload 重新加载
CREATE TABLE `t_test` (
`name` varchar(200) DEFAULT '',
`honor` varchar(200) DEFAULT ''
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin /*T! SHARD_ROW_ID_BITS=4 PRE_SPLIT_REGIONS=4 */
mysql> desc t_test;
+-------+--------------+------+------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+--------------+------+------+---------+-------+
| name | varchar(200) | YES | | | |
| honor | varchar(200) | YES | | | |
+-------+--------------+------+------+---------+-------+
2 rows in set (0.00 sec)
mysql> select count(*) from t_test;
+----------+
| count(*) |
+----------+
| 1024288 |
+----------+
1 row in set (3.68 sec)复制过程略
提示:
此种场景也是最常见的场景,replica>=3的时候,不会影响业务读写,也不会丢失数据,只需要扩容新TiKV节点,缩容下线故障节点即可。
如果是3*TiKV集群,必须只能先扩容,否则此时即便强制缩容下线故障节点,数据也不会发生replica均衡调度,因为无法补齐三副本。
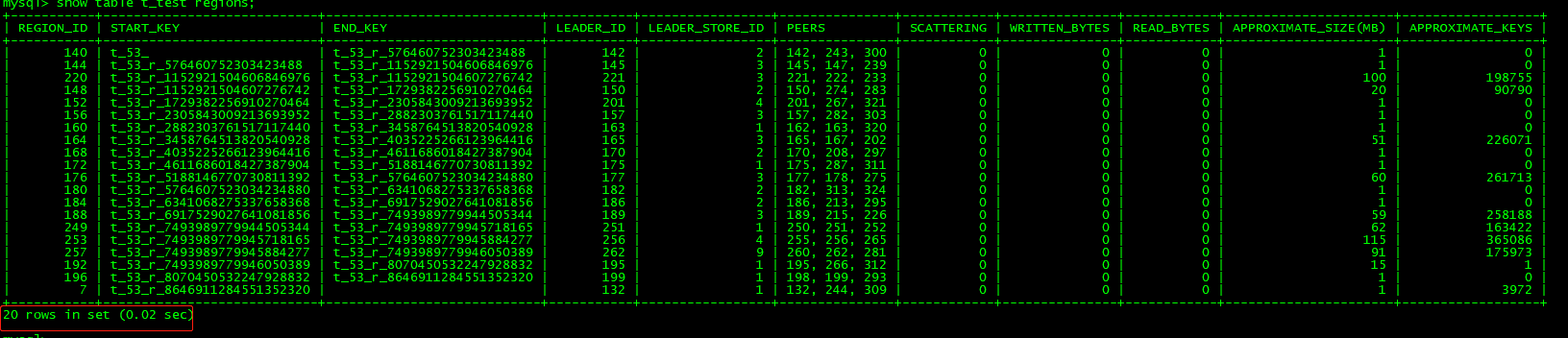
mysql> select STORE_ID,ADDRESS,LEADER_COUNT,REGION_COUNT from information_schema.TIKV_STORE_STATUS ;
+----------+--------------------+--------------+--------------+
| STORE_ID | ADDRESS | LEADER_COUNT | REGION_COUNT |
+----------+--------------------+--------------+--------------+
| 1 | 10.12.16.228:20160 | 12 | 25 |
| 2 | 10.12.16.225:20160 | 11 | 33 |
| 4 | 10.12.16.226:20160 | 9 | 14 |
| 3 | 10.12.16.227:20160 | 6 | 38 |
| 9 | 10.12.16.224:20160 | 7 | 25 |
+----------+--------------------+--------------+--------------+
5 rows in set (0.01 sec)复制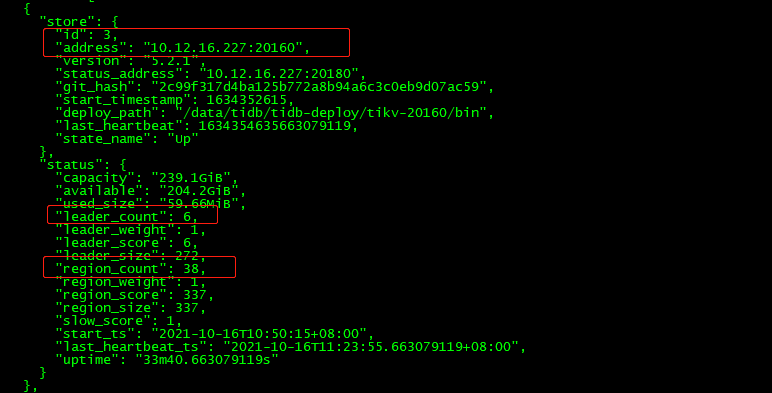
同时损坏的TiKV节点是10.12.16.227:20160和10.12.16.228:20160
在10.12.16.227(store_id=3)和10.12.16.228(store_id=1)上分别执行
$ cd /data/tidb/tidb-data/
$ ls
monitor-9100 pd-2379 tikv-20160
$ rm -rf tikv-20160
$ ls
monitor-9100 pd-2379复制查看集群状态:

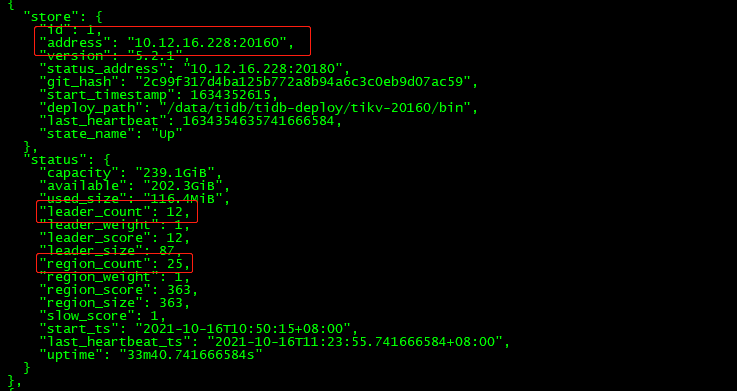
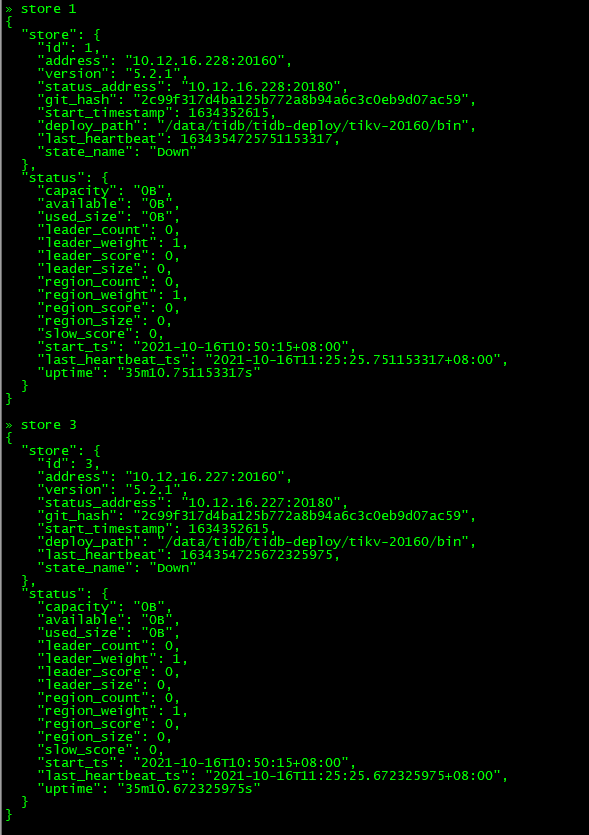
查看store_id=3和store_id=1的状态:
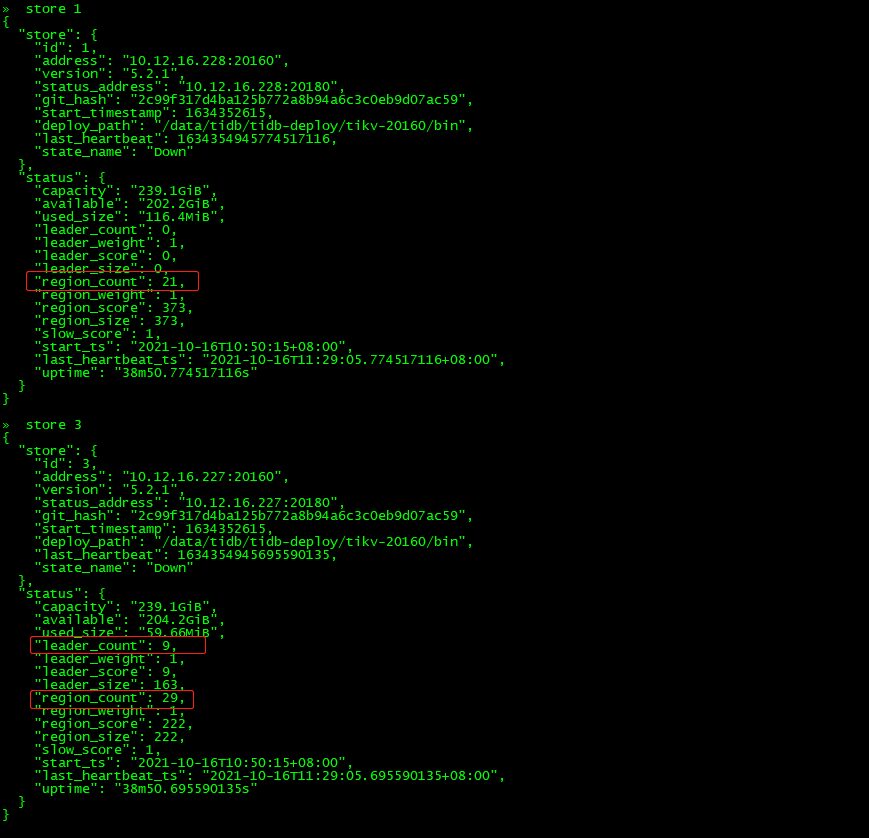
可以发现30分钟过后(store的状态从disconnecting–》down),store 1和3上的region的leader和replica还存在,并不是因为store是down状态,其上面的regionleader和replica进行切换和调度,那是因为部分region同时失去两个副本,导致无法发生leader选举。
mysql> select count(*) from t_test;
ERROR 9002 (HY000): TiKV server timeout复制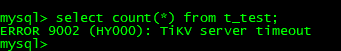
tidb查询发现hang住直到超时
关闭调度原因:防止恢复期间出现其他的异常情况
关闭调度方法:config set region-schedule-limit、replica-schedule-limit、leader-schedule-limit、merge-schedule-limit 这4个值
» config set region-schedule-limit 0
» config set replica-schedule-limit 0
» config set leader-schedule-limit 0
» config set merge-schedule-limit 0复制检查大于等于一半副本数在故障节点(store_id in(1,3))上的region,并记录它们的region id
$ ./pd-ctl region --jq='.regions[] | {id: .id, peer_stores: [.peers[].store_id] | select(length as $total |map(if .==(1,3) then . else empty end)|length>=$total-length)}'复制
$ tiup cluster stop tidb-test -N 10.12.16.224:20160
$ tiup cluster stop tidb-test -N 10.12.16.225:20160
$ tiup cluster stop tidb-test -N 10.12.16.226:20160复制
清理方法:
在正常的tikv(已经关闭掉)上执行命令:
$ ./tikv-ctl --data-dir /data/tidb/tidb-data/tikv-20160 unsafe-recover remove-fail-stores -s 1,3 --all-regions复制执行命令在输出的结尾有success字样,说明执行成功
清理原因:在正常tikv上清理掉region peer落在故障tikv(1和3)peer
$ tiup cluster restart tidb-test -R pd复制查看store 1和store 3
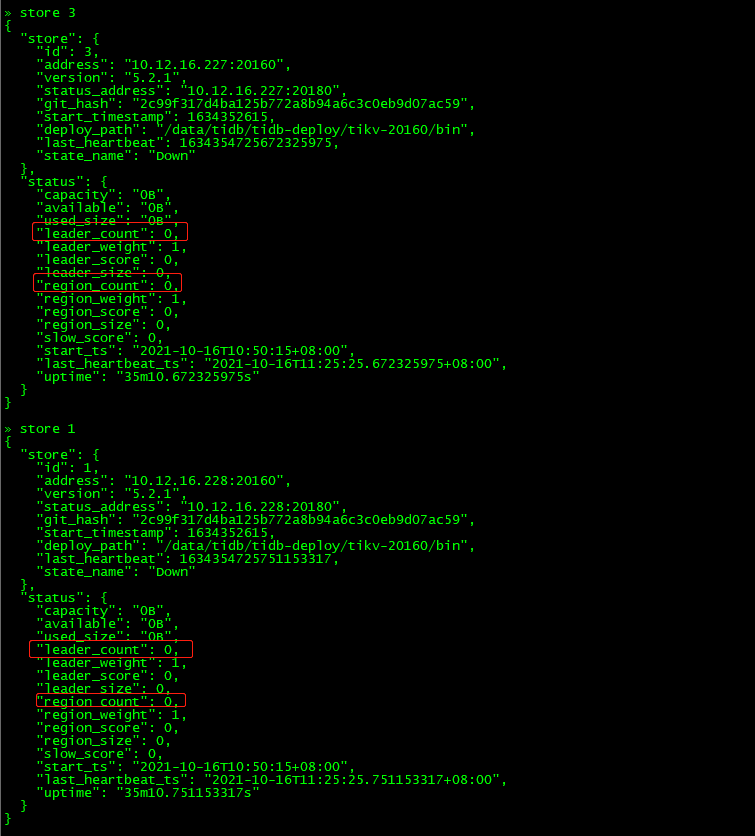
发现上面的leader_count和region_count都变成0,如果pd集群不重启,则不会消失。
$ tiup cluster start tidb-test -N 10.12.16.224:20160
$ tiup cluster start tidb-test -N 10.12.16.225:20160
$ tiup cluster start tidb-test -N 10.12.16.226:20160复制
查看副本数为2的region:
$ ./pd-ctl region --jq='.regions[] | {id: .id, peer_stores: [.peers[].store_id] | select(length==2) } '复制{"id":36,"peer_stores":[2,9]}
{"id":140,"peer_stores":[2,9]}
{"id":249,"peer_stores":[2,4]}
{"id":46,"peer_stores":[2,9]}
{"id":168,"peer_stores":[2,9]}
{"id":176,"peer_stores":[2,9]}
{"id":188,"peer_stores":[4,9]}
{"id":48,"peer_stores":[9,2]}
{"id":184,"peer_stores":[2,9]}
{"id":26,"peer_stores":[2,9]}
{"id":152,"peer_stores":[4,2]}
{"id":52,"peer_stores":[2,4]}
{"id":40,"peer_stores":[4,2]}
{"id":253,"peer_stores":[4,9]}
{"id":44,"peer_stores":[2,9]}复制查看只有单副本的region:
$ ./pd-ctl region --jq='.regions[] | {id: .id, peer_stores: [.peers[].store_id] | select(length==1) } '复制{"id":42,"peer_stores":[2]}
{"id":62,"peer_stores":[9]}
{"id":192,"peer_stores":[9]}
{"id":180,"peer_stores":[2]}
{"id":196,"peer_stores":[2]}
{"id":60,"peer_stores":[9]}
{"id":160,"peer_stores":[2]}
{"id":164,"peer_stores":[4]}
{"id":54,"peer_stores":[9]}
{"id":172,"peer_stores":[2]}
{"id":220,"peer_stores":[2]}
{"id":7,"peer_stores":[9]}
{"id":50,"peer_stores":[9]}
{"id":144,"peer_stores":[9]}
{"id":156,"peer_stores":[2]}
{"id":38,"peer_stores":[2]}
{"id":56,"peer_stores":[2]}复制config set region-schedule-limit 2048
config set replica-schedule-limit 64
config set leader-schedule-limit 4
config set merge-schedule-limit 8复制$ ./pd-ctl region --jq='.regions[] | {id: .id, peer_stores: [.peers[].store_id] | select(length as $total |map(if .==(1,3) then . else empty end)|length>=$total-length)}' 复制输出为空
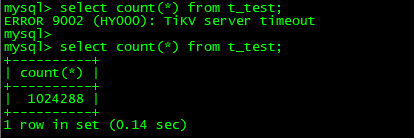
查看只有单副本的region:


发现store 1和3还是存在(状态为Down),需要在集群中剔除掉
删除掉store 1和3
» store delete 1
Success!
» store delete 3
Success!复制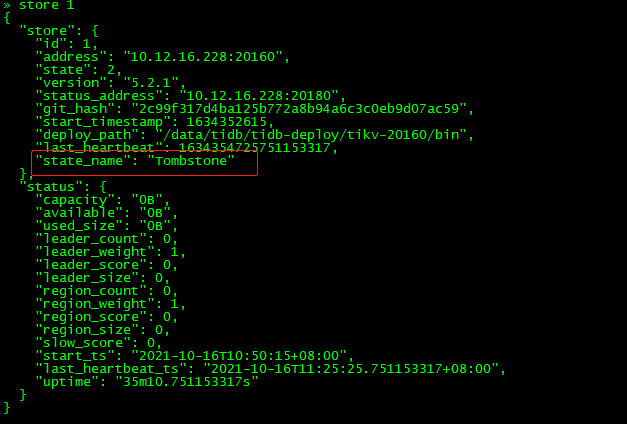

$ tiup cluster prune tidb-test复制$ tiup cluster display tidb-test复制
至此,双副本同时丢失的情景已经修复完毕
$ ./pd-ctl region --jq='.regions[] | {id: .id, peer_stores: [.peers[].store_id] | select(length==3) } '复制{"id":220,"peer_stores":[2,9,497041]}
{"id":249,"peer_stores":[2,4,497042]}
{"id":7,"peer_stores":[9,497041,497042]}
{"id":36,"peer_stores":[2,9,497041]}
{"id":140,"peer_stores":[2,497042,497041]}
{"id":144,"peer_stores":[9,497042,2]}
{"id":156,"peer_stores":[2,4,497042]}
{"id":168,"peer_stores":[2,9,497042]}
{"id":176,"peer_stores":[2,497042,4]}
{"id":188,"peer_stores":[497042,9,497041]}
{"id":38,"peer_stores":[2,9,497041]}
{"id":46,"peer_stores":[9,2,497041]}
{"id":50,"peer_stores":[9,497041,497042]}
{"id":48,"peer_stores":[2,9,497041]}
{"id":56,"peer_stores":[9,497041,497042]}
{"id":184,"peer_stores":[2,9,497041]}
{"id":152,"peer_stores":[4,9,497041]}
{"id":192,"peer_stores":[9,497042,497041]}
{"id":26,"peer_stores":[497042,497041,2]}
{"id":42,"peer_stores":[2,9,497042]}
{"id":62,"peer_stores":[9,497041,497042]}
{"id":180,"peer_stores":[2,9,497042]}
{"id":196,"peer_stores":[2,497041,497042]}
{"id":22,"peer_stores":[4,497042,9]}
{"id":52,"peer_stores":[4,497042,9]}
{"id":148,"peer_stores":[4,9,497041]}
{"id":40,"peer_stores":[4,9,497042]}
{"id":160,"peer_stores":[2,9,497041]}
{"id":164,"peer_stores":[4,497041,497042]}
{"id":253,"peer_stores":[4,2,497042]}
{"id":257,"peer_stores":[4,9,497041]}
{"id":34,"peer_stores":[4,497041,497042]}
{"id":58,"peer_stores":[4,497042,9]}
{"id":60,"peer_stores":[9,497041,497042]}
{"id":44,"peer_stores":[2,9,497041]}
{"id":54,"peer_stores":[9,497041,497042]}
{"id":172,"peer_stores":[497041,9,497042]}复制mysql> select count(*) from t_test;
+----------+
| count(*) |
+----------+
| 1024288 |
+----------+
1 row in set (0.14 sec)
mysql> select count(*) from t_test;
+----------+
| count(*) |
+----------+
| 1024288 |
+----------+
1 row in set (0.14 sec)复制模拟10.12.16.226:20160 10.12.16.227:20160 10.12.16.228:20160三个tikv节点同时挂掉
在226、227、228上执行:
$ cd /data/tidb/tidb-data
$ ls
monitor-9100 pd-2379 tikv-20160
$ rm -rf tikv-20160
$ ls
monitor-9100 pd-2379复制查看集群状态:
$ tiup cluster display tidb-test复制
config set region-schedule-limit 0
config set replica-schedule-limit 0
config set leader-schedule-limit 0
config set merge-schedule-limit 0复制mysql> select STORE_ID,ADDRESS,LEADER_COUNT,REGION_COUNT,STORE_STATE_NAME from information_schema.TIKV_STORE_STATUS order by STORE_STATE_NAME;
+----------+--------------------+--------------+--------------+------------------+
| STORE_ID | ADDRESS | LEADER_COUNT | REGION_COUNT | STORE_STATE_NAME |
+----------+--------------------+--------------+--------------+------------------+
| 497041 | 10.12.16.228:20160 | 2 | 25 | Disconnected |
| 497042 | 10.12.16.227:20160 | 2 | 26 | Disconnected |
| 4 | 10.12.16.226:20160 | 12 | 13 | Disconnected |
| 2 | 10.12.16.225:20160 | 11 | 19 | Up |
| 9 | 10.12.16.224:20160 | 10 | 28 | Up |
+----------+--------------------+--------------+--------------+------------------+
5 rows in set (0.00 sec)复制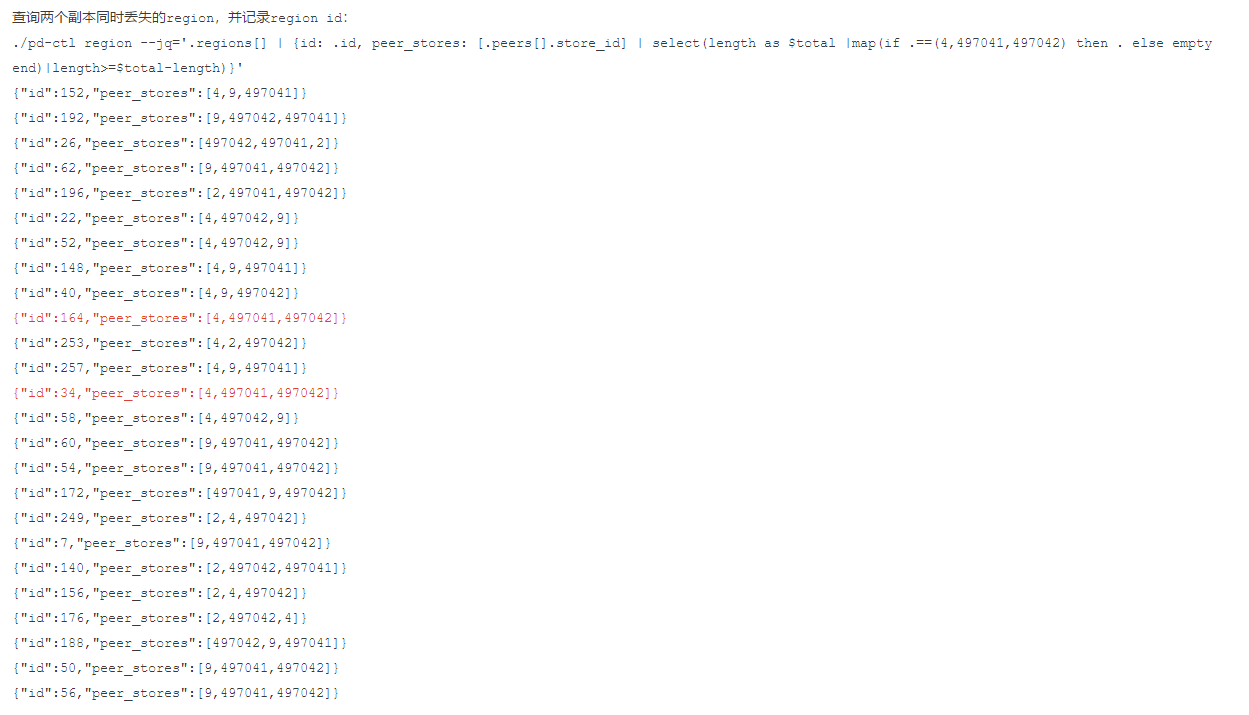
$ tiup cluster stop tidb-test -N 10.12.16.224:20160
$ tiup cluster stop tidb-test -N 10.12.16.225:20160
$ tiup cluster display tidb-test复制
清理方法:
在正常的tikv(已经关闭掉)上执行命令:
$ ./tikv-ctl --data-dir /data/tidb/tidb-data/tikv-20160 unsafe-recover remove-fail-stores -s 4,497041,497042 --all-regions复制执行命令在输出的结尾有success字样,说明执行成功
清理原因:在正常tikv上清理掉region peer落在故障tikv(4,497041,497042)peer
$ tiup cluster restart tidb-test -R pd复制$ tiup cluster start tidb-test -N 10.12.16.224:20160
$ tiup cluster start tidb-test -N 10.12.16.225:20160
$ tiup cluster display tidb-test 复制
config set region-schedule-limit 2048
config set replica-schedule-limit 64
config set leader-schedule-limit 4
config set merge-schedule-limit 8复制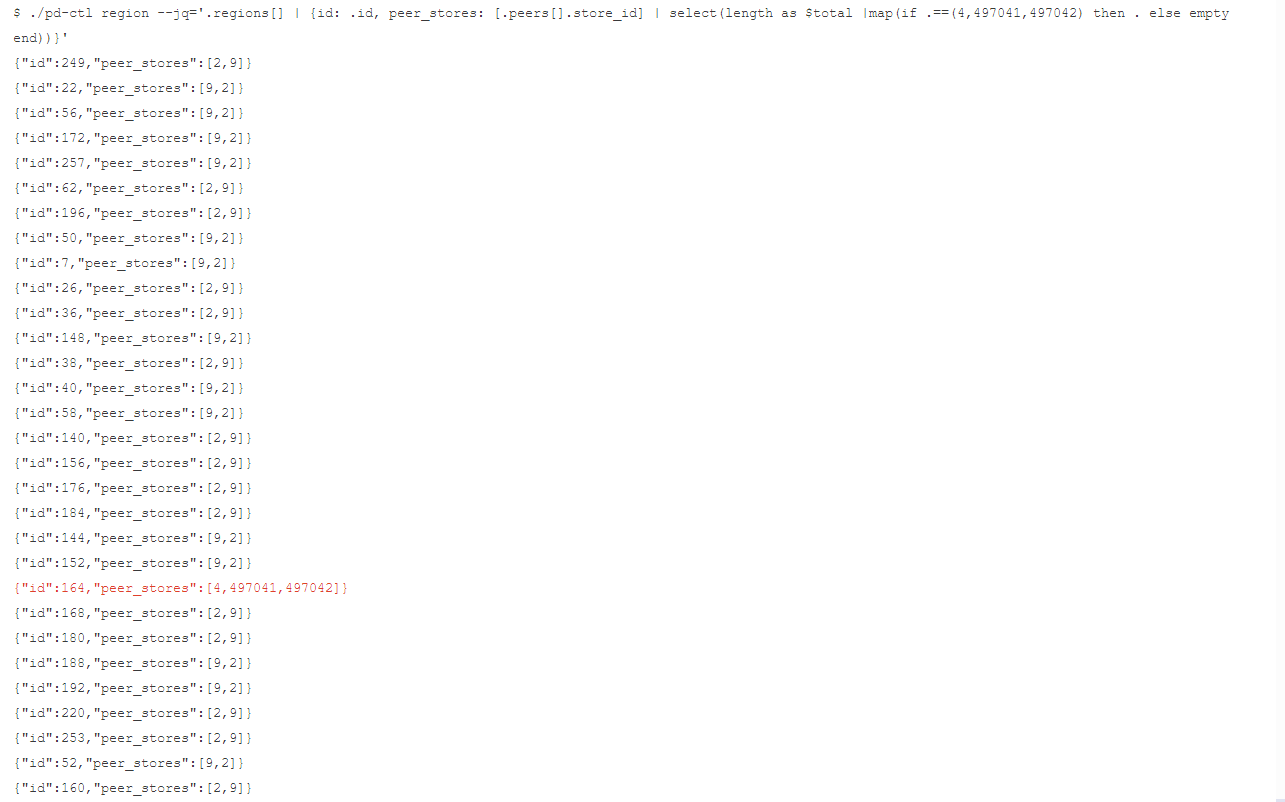
mysql> select count(*) from t_test;
ERROR 9005 (HY000): Region is unavailable复制
$ ./pd-ctl region --jq='.regions[] | {id: .id, peer_stores: [.peers[].store_id] | select(length as $total |map(if .==(4,497041,497042) then . else empty end)|length>$total-length)}'复制{"id":164,"peer_stores":[4,497041,497042]}复制
停止10.12.16.225:20160 tikv实例(可以是其他任意正常的tikv实例)
$ ./tikv-ctl --data-dir /data/tidb/tidb-data/tikv-20160 recreate-region -p 127.0.0.1:2379 -r 164复制命令输出结尾有success字样,说明创建成功
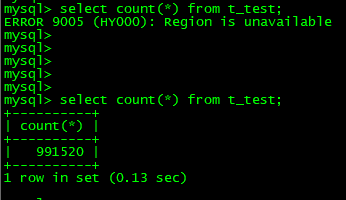
$ tiup cluster display tidb-test 复制
» store delete 4
Success!
» store delete 497041
Success!
» store delete 497042
Success!复制如果通过tiup cluster display tidb-test执行命令发现226、227、228上的store状态为up,说明开启了自动拉起
$ tiup cluster prune tidb-test复制1、如果region的单个副本丢失(小于replica一半的情况下),集群是不会丢失数据,此场景是绝大多数用户tikv挂掉场景;
2、如果region多副本(副本数大于replica/2)丢失,如果开启sync-log=true则不会丢失数据,否则可能会丢失数据;
3、如果region所有副本丢失,此时必定会丢失数据,需要进行破坏性修复;
4、如果单机多tikv实例部署,一定需要打label,否则主机挂掉,region的多副本或者全部副本可能会丢失,从而导致丢失数据;