TiKV节点缩容不掉,通常遇到的情况:
-
1、经常遇到的情况是:3个节点的tikv集群缩容肯定会一直卡着,因为没有新节点接受要下线kv的region peer。
-
2、另外就是除缩容tikv外,剩下的KV硬盘使用情况比较高,到达schedule.high-space-ratio=0.6的限制,导致该tikv的region无法迁移。
但是今天要讨论的是:我先执行了扩容,然后再进行的缩容,仍然卡着就说不过去了。
问题现场
版本:TiDB v5.2.1 情况说明:这个tidb是有tiflash节点的,并且这个集群是一路从3.X升级到5.2.1版本 问题现场:为了下线一个3kv集群中的一个kv,我们在24号扩容了一个新kv,然后扩容完毕后,下线某个kv,都过了2天,该kv还是处于pending offline的状态,看监控leader+reigon已经切走了,为啥该kv的状态仍然没有tombstone?
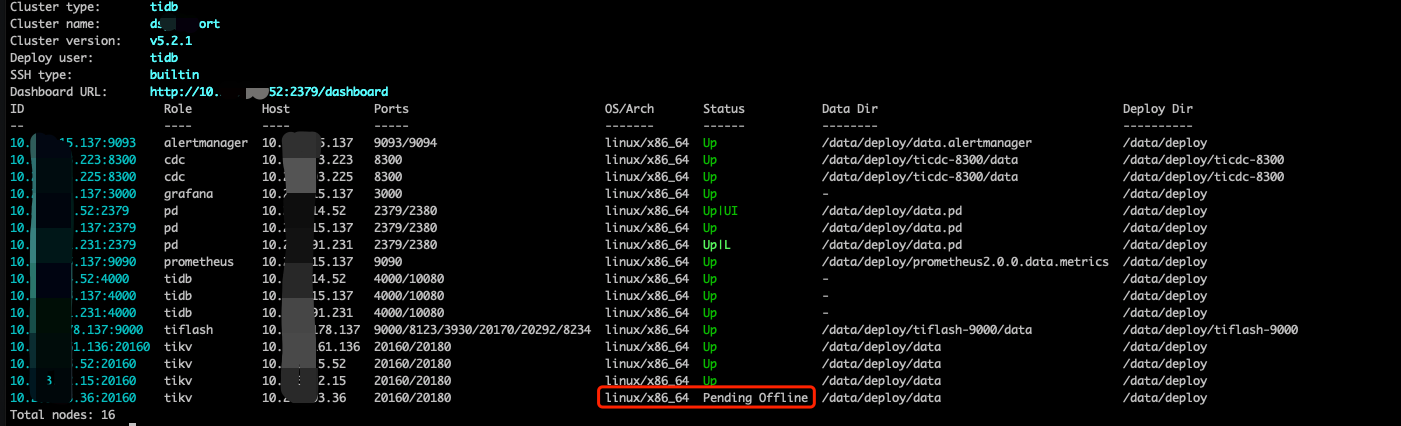
下图是扩容和缩容tikv的监控,从下图可以发现扩容和缩容都已经完毕了。

问题排查
(1)先看看有缩容问题的TIKV节点日志
查看日志发现有:KvService::batch_raft send response fail报错,查了下asktug,发现这些报错指向一个4.X的bug:raft 大小限制的过大,超过 gRPC 传输通信限制导致 raft message 卡住的问题,所以影响了 region 的调度。将 TiKV 集群的 raft-max-size-per-msg 这个配置调小,降低 raft message 大小来看是否能恢复 region 调度。
如果其他人的4.X版本遇到这个问题可以通过上面方式搞定,但是目前我已经升级到了5.2.1,所以上面方法不适合解决我的这个问题。相关的报错日志如下:
- $ grep 'ERROR' tikv.log
- [2022/03/28 09:34:38.062 +08:00] [ERROR] [kv.rs:729] ["KvService::batch_raft send response fail"] [err=RemoteStopped]
- [2022/03/28 09:34:38.062 +08:00] [ERROR] [kv.rs:729] ["KvService::batch_raft send response fail"] [err=RemoteStopped]
- [2022/03/28 09:34:38.227 +08:00] [ERROR] [pd.rs:83] ["Failed to send read flow statistics"] [err="channel has been closed"]
- [2022/03/28 09:34:38.261 +08:00] [ERROR] [kv.rs:729] ["KvService::batch_raft send response fail"] [err=RemoteStopped]
- [2022/03/28 09:34:38.261 +08:00] [ERROR] [kv.rs:729] ["KvService::batch_raft send response fail"] [err=RemoteStopped]
- [2022/03/28 09:34:55.711 +08:00] [ERROR] [server.rs:1030] ["failed to init io snooper"] [err_code=KV:Unknown] [err="\"IO snooper is not started due to not compiling with BCC\""]
(2)查看节点情况,发现该节点除了状态为Offline外,leader_count/region_count都为0,为啥都为0了,等了2天还是pending offline?没有变tombstone?
- tiup ctl:v5.2.1 pd -u http://pd-ip:2379 store 5
- {
- "store": {
- "id": 5,
- "address": "xxxx:20160",
- "state": 1,
- "version": "5.2.1",
- "status_address": "xxxxx:20180",
- "git_hash": "2c99f317d4ba125b772a8b94a6c3c0eb9d07ac59",
- "start_timestamp": 1648465247,
- "deploy_path": "/data/deploy/bin",
- "last_heartbeat": 1648517045511041818,
- "state_name": "Offline"
- },
- "status": {
- "capacity": "0B",
- "available": "0B",
- "used_size": "0B",
- "leader_count": 0,
- "leader_weight": 1,
- "leader_score": 0,
- "leader_size": 0,
- "region_count": 0,
- "region_weight": 1,
- "region_score": 0,
- "region_size": 0,
- "slow_score": 0,
- "start_ts": "2022-03-28T19:00:47+08:00",
- "last_heartbeat_ts": "2022-03-29T09:24:05.511041818+08:00",
- "uptime": "14h23m18.511041818s"
- }
- }

(3)查看有问题tikv节点的region信息。
结果发现不得了的结果,这个不能成功下线的tikv store 5,竟然还有一个id为434317的region,这个region没有leader,有3个voter(在store 5 、1 、 4上)和2个Learner(在tiflash store 390553和390554上),并且这2个tiflash store还是集群升级前4.0.9版本的store id,并且之前对tikv/tiflash节点执行过scale-in --force等暴力下线的操作,至于该region为啥没有选出leader,一则可能是bug,二则可能是暴力下线tikv/tiflash导致。
也就是说:这个没有leader的region:434317,因为他在store_id:5 上还有记录,这个问题成为了阻碍该tikv一直卡到offline状态无法成功下线的原因。
- $ tiup ctl:v5.2.1 pd -u http://pd-ip:2379 region store 5
- {
- "count": 1,
- "regions": [
- {
- "id": 434317,
- "start_key": "748000000000002DFFB95F720000000000FA",
- "end_key": "748000000000002DFFB95F728000000003FF3F16990000000000FA",
- "epoch": {
- "conf_ver": 7,
- "version": 4204
- },
- "peers": [
- {
- "id": 434318,
- "store_id": 1,
- "role_name": "Voter"
- },
- {
- "id": 434319,
- "store_id": 4,
- "role_name": "Voter"
- },
- {
- "id": 434320,
- "store_id": 5,
- "role_name": "Voter"
- },
- {
- "id": 434321,
- "store_id": 390553,
- "role": 1,
- "role_name": "Learner",
- "is_learner": true
- },
- {
- "id": 434322,
- "store_id": 390554,
- "role": 1,
- "role_name": "Learner",
- "is_learner": true
- }
- ],
- "leader": {
- "role_name": "Voter"
- },
- "written_bytes": 0,
- "read_bytes": 0,
- "written_keys": 0,
- "read_keys": 0,
- "approximate_size": 0,
- "approximate_keys": 0
- }
- ]
- }
(4)查看下该region对应的库表信息,看是否对业务有影响,执行后发现是个空region:
- $ curl http://tidb-server-ip:10080/regions/434317
- {
- "start_key": "dIAAAAAAAC25X3I=",
- "end_key": "dIAAAAAAAC25X3KAAAAAAz8WmQ==",
- "start_key_hex": "748000000000002db95f72",
- "end_key_hex": "748000000000002db95f7280000000033f1699",
- "region_id": 434317,
- "frames": null
- }
问题已经定位,下面是如何解决了
问题解决
(1)使用pd-ctl,看看是否能让434317选出leader,或者通过添加peer,删除peer等方式解决问题。
执行尝试如下
- // 把 Region 434317 的 leader 调度到 store 4
- $tiup ctl:v5.2.1 pd -u http://pd-ip:2379 operator add transfer-leader 434317 4
- Failed! [500] "cannot build operator for region with no leader"
-
- // 在 store 1094772 上新增 Region 434317 的副本
- $tiup ctl:v5.2.1 pd -u http://pd-ip:2379 operator add add-peer 434317 1094772
- Failed! [500] "cannot build operator for region with no leader"
-
- // 移除要下线 store 5 上的 Region 434317 的副本
- $ tiup ctl:v5.2.1 pd -u http://pd-ip:2379 operator add remove-peer 434317 5
- Failed! [500] "cannot build operator for region with no leader"
发现通过pd-ctl折腾的这条路走不通,因为要想实现上述操作,需要在region有leader的情况下才能操作。
(2)那我使用pd-ctl去把这个store delete如何?
- tiup ctl:v5.2.1 pd -u http://pd-ip:2379 store delete 5
- Success!
看到Sucess很激动,但是pd-ctl store一看,store 5还是在记录里面。发现这一招也不管用。
(3)tiup scale-in --force强制/暴力下线该tikv如何?
tiup cluster scale-in dsp_report -N 10.203.93.36:20160 --force执行完毕,tiup里面确实没了。虽然说眼不见心不烦,但是pd-ctl store查看tikv信息还是有,崩溃!
(4)最后只能祭出tikv-ctl工具,来删除这个region,因为我上文提到了这个region本是空reigon,删除也不影响业务。具体tikv-ctl的使用和介绍就不详细说明了,可以参见我之前的公众号文章:TiDB集群恢复之TiKV集群不可用
./tikv-ctl --db /data/deploy/data/db tombstone -r 434317 --force这么操作后,整个世界安静了,我的“强迫症”也得到满足,这个region终于“干净”了。
PS:其他人遇到类似的问题,该排查方案可以参考;也可以先停止下线操作,先升级到高阶版本后再尝试缩容的,这里告诉大家一个小妙招:我如何收回正在执行的scale-in呢?看下面:
curl -X POST http://${pd_ip}:2379/pd/api/v1/store/${store_id}/state?state=Upstore的状态转换
最后这个小结讲讲Store状态,TiKV Store 的状态具体分为 Up,Disconnect,Offline,Down,Tombstone。各状态的关系如下:
-
Up:表示当前的 TiKV Store 处于提供服务的状态。
-
Disconnect:当 PD 和 TiKV Store 的心跳信息丢失超过 20 秒后,该 Store 的状态会变为 Disconnect 状态,当时间超过 max-store-down-time 指定的时间后,该 Store 会变为 Down 状态。
-
Down:表示该 TiKV Store 与集群失去连接的时间已经超过了 max-store-down-time 指定的时间,默认 30 分钟。超过该时间后,对应的 Store 会变为 Down,并且开始在存活的 Store 上补足各个 Region 的副本。
-
Offline:当对某个 TiKV Store 通过 PD Control 进行手动下线操作,该 Store 会变为 Offline 状态。该状态只是 Store 下线的中间状态,处于该状态的 Store 会将其上的所有 Region 搬离至其它满足搬迁条件的 Up 状态 Store。当该 Store 的 leadercount 和 regioncount (在 PD Control 中获取) 均显示为 0 后,该 Store 会由 Offline 状态变为 Tombstone 状态。在 Offline 状态下,禁止关闭该 Store 服务以及其所在的物理服务器。下线过程中,如果集群里不存在满足搬迁条件的其它目标 Store(例如没有足够的 Store 能够继续满足集群的副本数量要求),该 Store 将一直处于 Offline 状态。
-
Tombstone:表示该 TiKV Store 已处于完全下线状态,可以使用 remove-tombstone 接口安全地清理该状态的 TiKV。
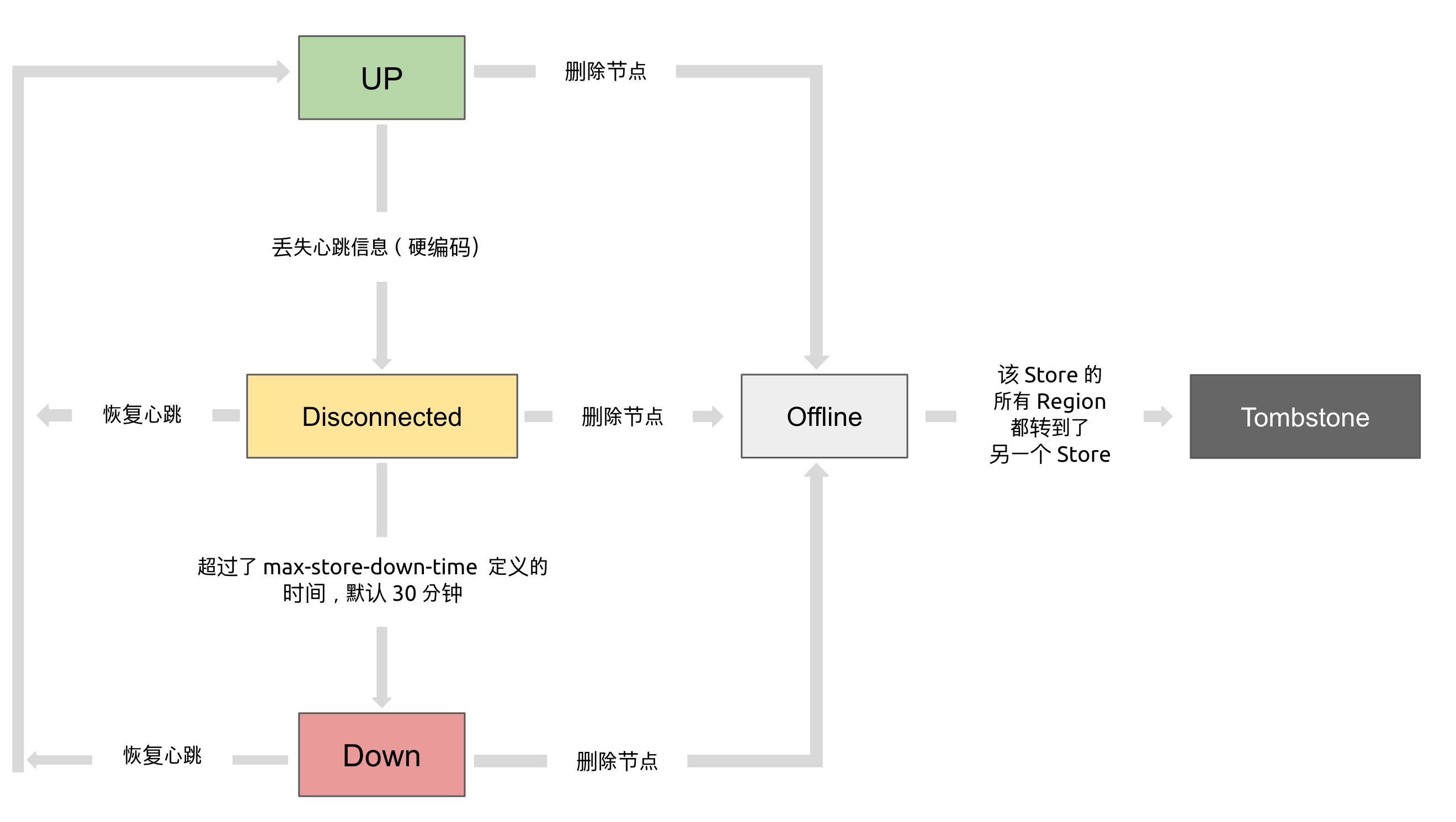
本小节来自官网:https://docs.pingcap.com/zh/tidb/stable/tidb-scheduling#%E4%BF%A1%E6%81%AF%E6%94%B6%E9%9B%86
本人作者:@代晓磊_360
发表时间:2022/4/25 原文链接:https://tidb.net/blog/ec7009ac