https://tidb.net/blog/4b5451bb?utm_source=tidb-community&utm_medium=referral&utm_campaign=repost#%E5%8F%82%E8%80%83%E8%B5%84%E6%96%99复制
很喜欢TiDB的设计哲学,比如,数据库就活该要么OLAP,要么OLTP么,为嘛就不能兼顾一下?数据量大了后,就一定要反人类的分库分表么?你当分库分表好玩么?分库一时爽,维护火葬场!
尤其在一些中小型团队里,为了数据分析搞一套Hadoop,约等于为了喝牛奶,从牛崽开始养一头奶牛。一路上明坑暗坑不断。
考虑到学习成本,迁移成本(高度兼容MySQL-但不是100%),运维成本(支持Ansible-团队有Ansible运维经验),使用成本(相比Hadoop),硬件成本(相比Hadoop),收益(不用分开分表,支持OLAP和OLTP,支持分布式事务,支持TiSpark,支持TiKV,自带同步工具)等。
好了,疑似广告的一段话说完了,回归正题,介绍是如何悲催的遇上整栋大厦停电,并且恰好TiKV文件损坏,以及如何在TiDB各位大佬的远程文字指导下,一步步把心态从删库跑路,转变成说不定还有救,以及,我擦,真救回来的坎坷心路旅程。
因为TiDB之前是别的同事负责,刚接过来不久,对TiDB整个的掌握还很初级。真·面向故障学习!
全文主要是对本次事故的回溯,琐碎细节较多,介意的可以直接看最后。
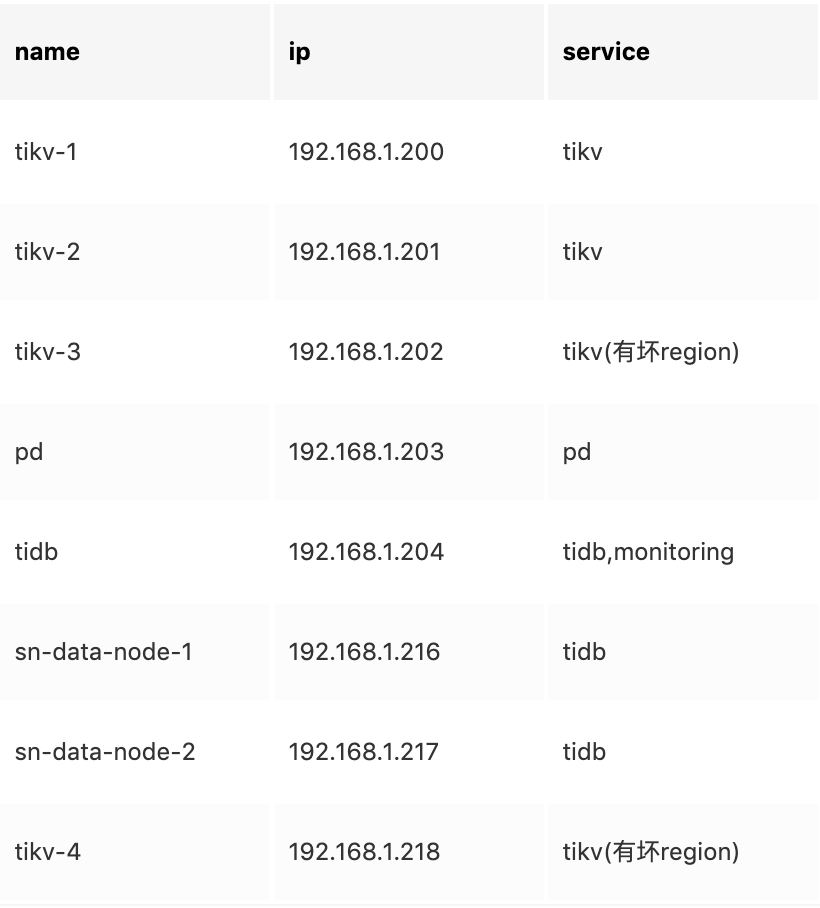
集群环境
上午coding正嗨,突发性停电
ansible-playbook start.yml
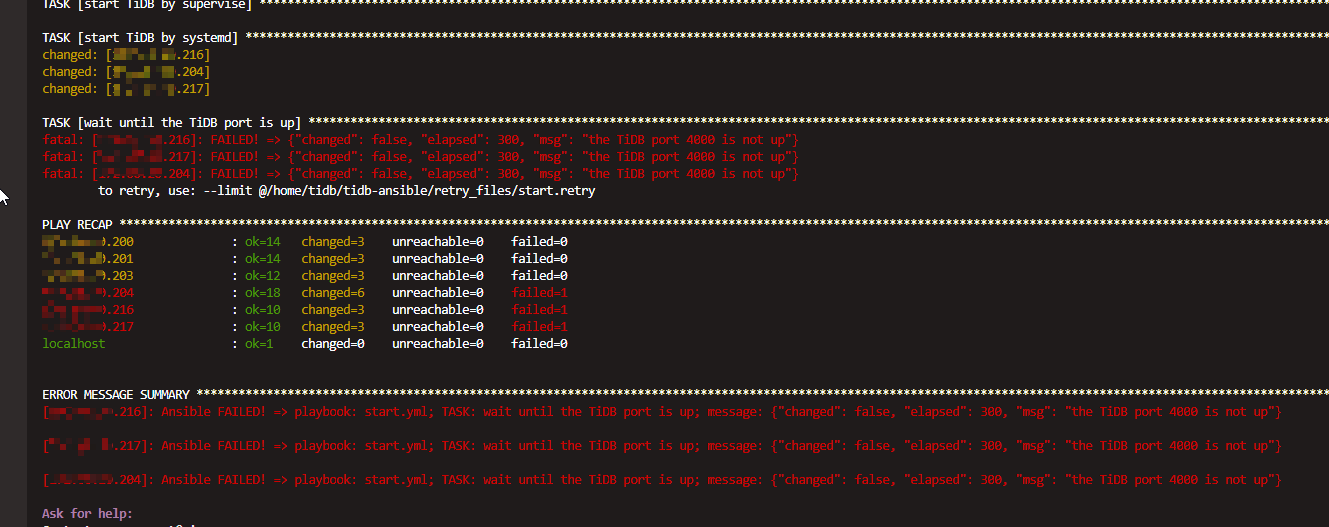
事情有点不妙,但是扔不死心的, stop and start 一通后,仍是这个结果。事情有点大条。
好在之前偷偷潜伏到TiDB的官方群里,没事就听各位大佬吹水打屁,多少受了点熏陶。撸起袖子,开搞。
先看官方文档
好吧,跟没看区别不大。
既然是TiDB起不来,就先看TiDB的日志(实际上应该看http://prometheus:9090/targets ,因为不太熟悉,所以走了弯路,为嘛不看Grafana,是因为TiDB那卡到后,Ansible就自动退出了,没有起Grafana)
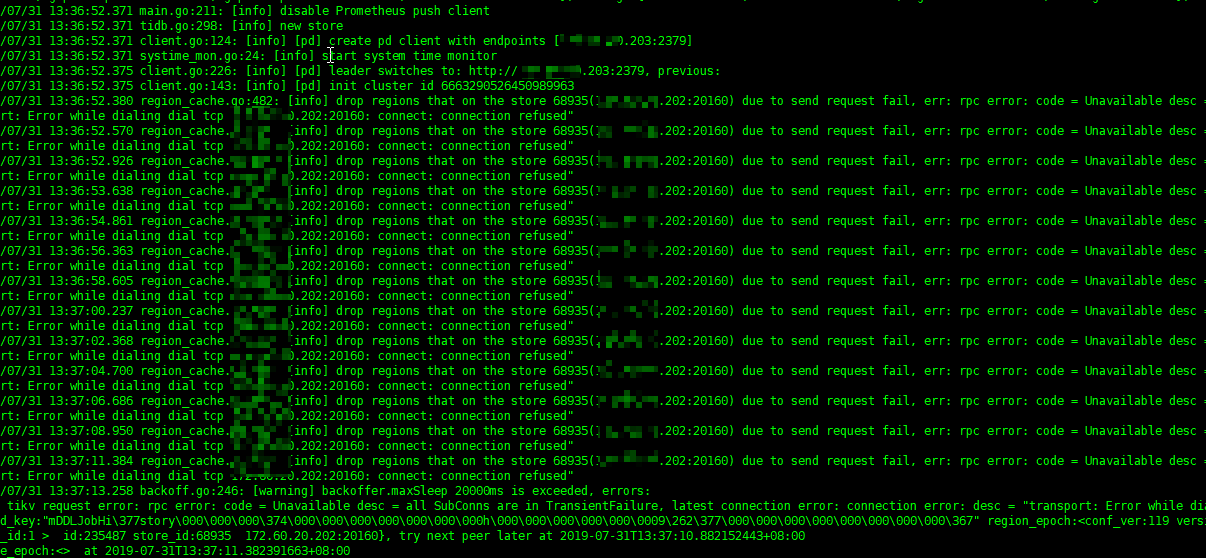
暴露的是连接两个TiKV报错,这是前期比较关键的线索,起码有初步排查方向了。
df -i df -h 来看,都很充足。

群内 @张曾钧@PingCAP 大佬开始介入,并且开始了将近8个小时的细心和耐心的指导,讲真,PingCAP团队是我见过最热心耐心的团队,素未蒙面,但乐于助人[呲牙]
此时,通过看官方文档,尝试性,试了下Prometheus可以打开,
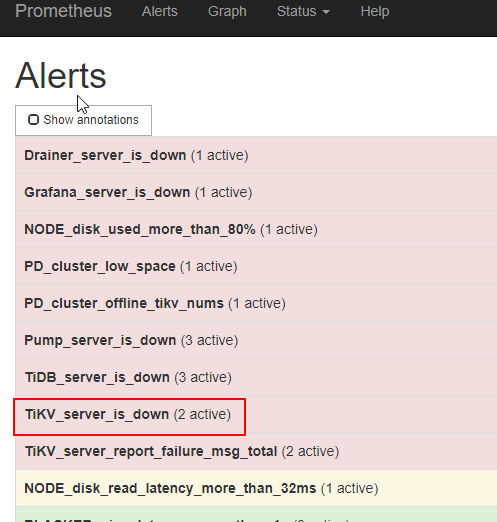
能看出有两个TiKV down掉,正好是上面两个。PS ,我是事后才发现的,当时我一直认为TiKV是起来的[捂脸]
小结: Round 1 以找出两个TiKV down结束,效率低到羞愧。
注意,下面如无特殊说明,一律是TiKV关掉状态下,执行命令。
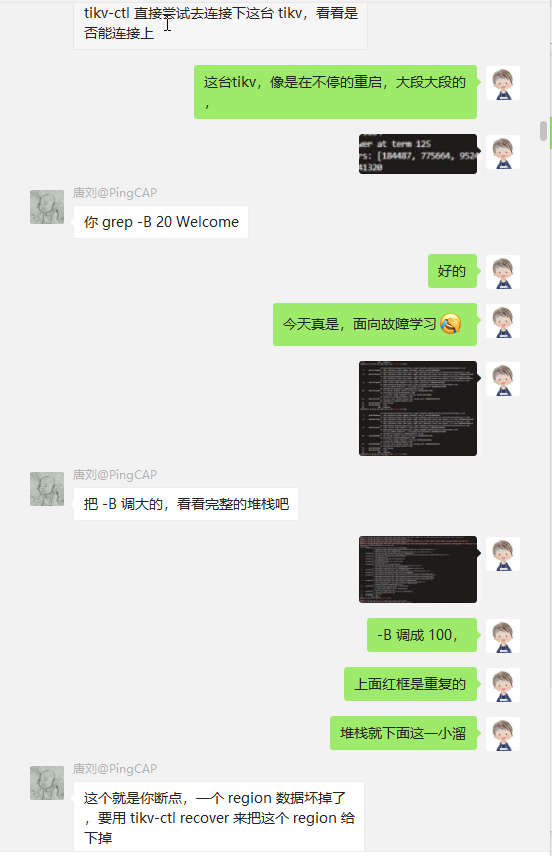
使用@唐刘@PingCAP的方法 grep -B 50 Welcome ,开始接触事发原因了。
更多的grep的方法(-A -B -C),参考 man grep 或者 GREP(1) ,因为tikv启动会打印Welcome,所以有理由认为,每次的Welcome之前的,肯定是上次退出的原因。

至此,出现了第一个坏掉的region。
./pd-ctl store -d -u http://127.0.0.1:2379

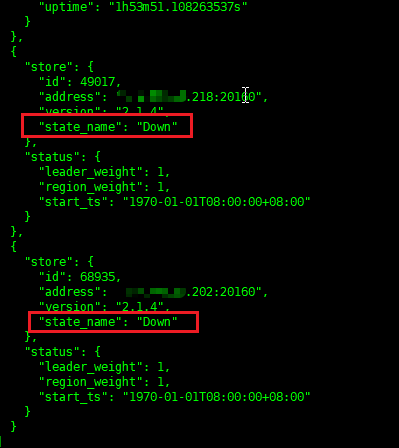
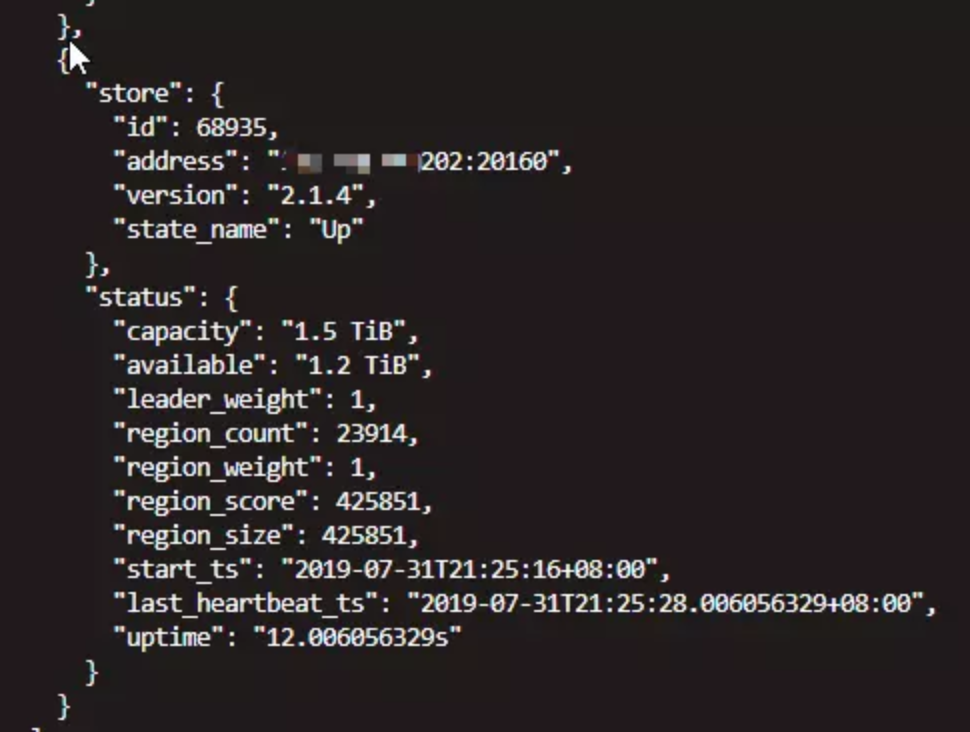
找到挂掉的两个TiKV的store id,跟上图的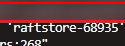 68935能对起来。
68935能对起来。
此时救苦救难的 大佬 提供了 TiKV Control 使用说明#恢复损坏的-mvcc-数据
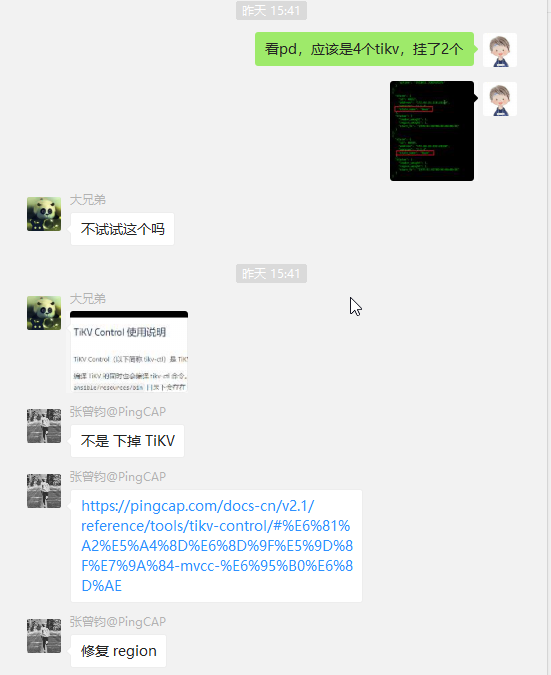
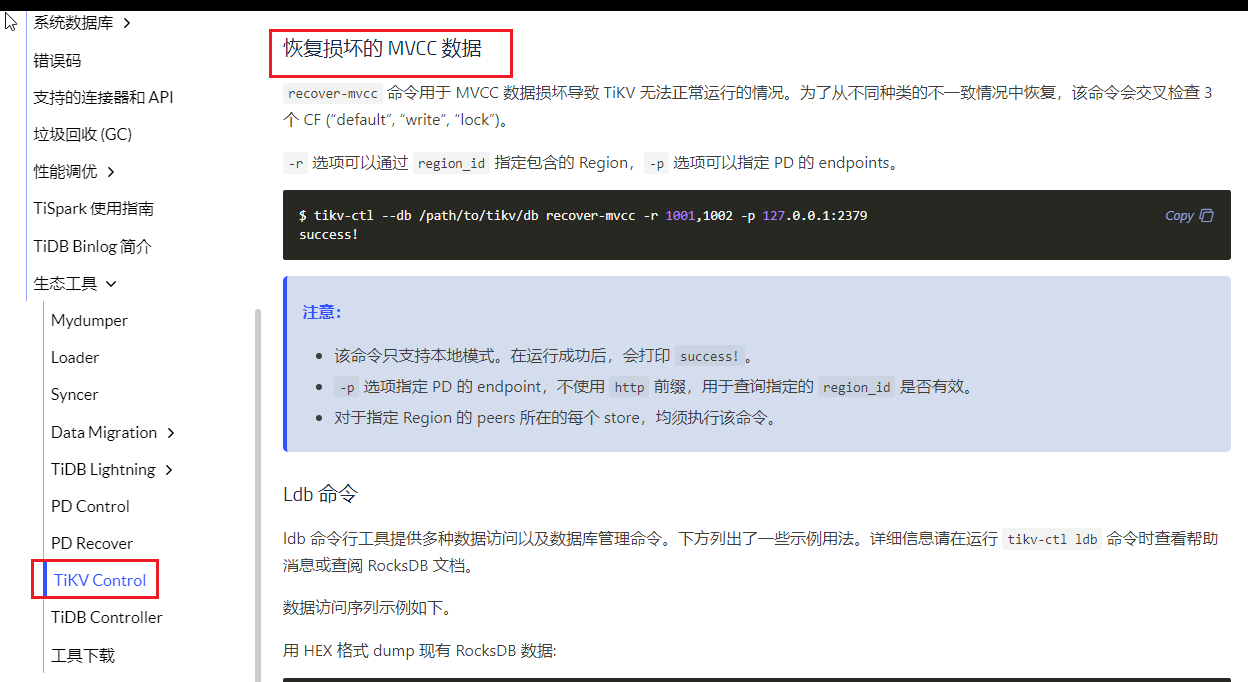
实际上执行后,没啥效果,后来发现是因为此region超过一半副本出问题了,recover-mvcc 没法恢复。
Round 2 结束,找到了救命稻草,TiKV Control 和PD Control,但是,事情远没这么简单。
中间出了个差点搞死自己的小插曲
/home/tidb/tidb-ansible/resources/bin/pd-ctl -u "http://172.16.10.1:2379" -d store delete 10 自作聪明的以为,TiKV 已经没救了,执行了store delete 操作。
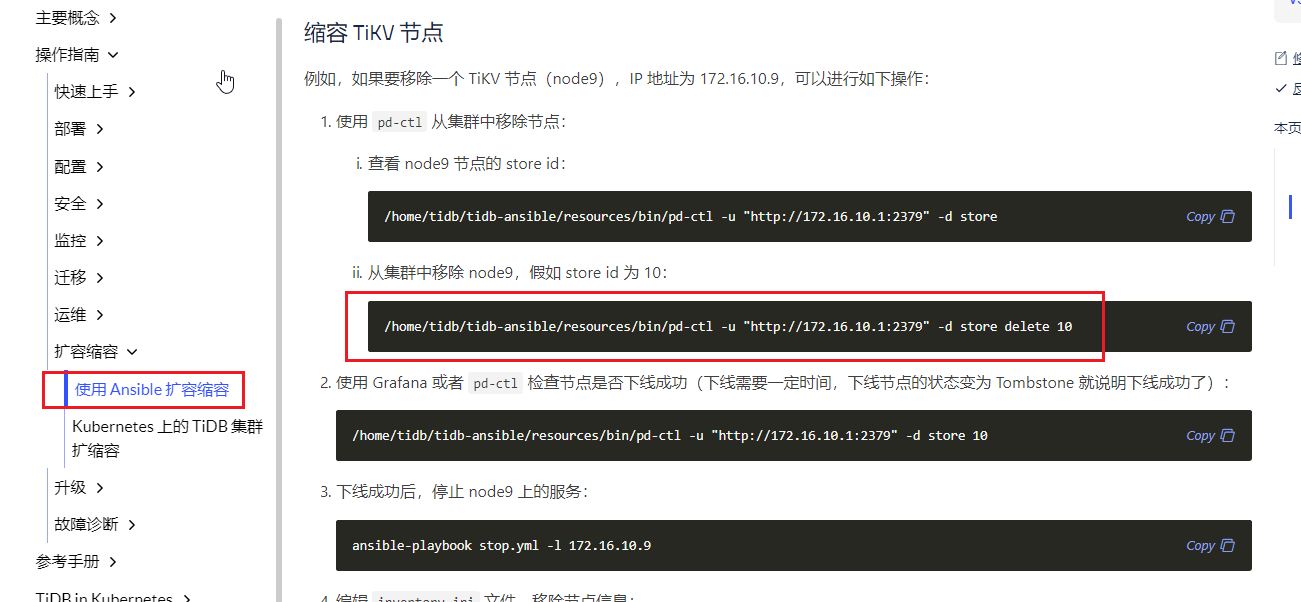
但是实际上还有救,所以又变成了,如何把已经delete掉的store,再度挂上去。
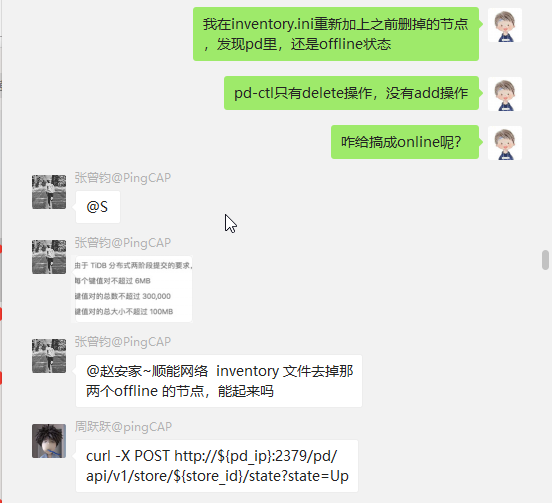
根据 大佬的 curl -X POST http://${pd_ip}:2379/pd/api/v1/store/${store_id}/state?state=Up 成功挂上,当然还是down的状态。
根据
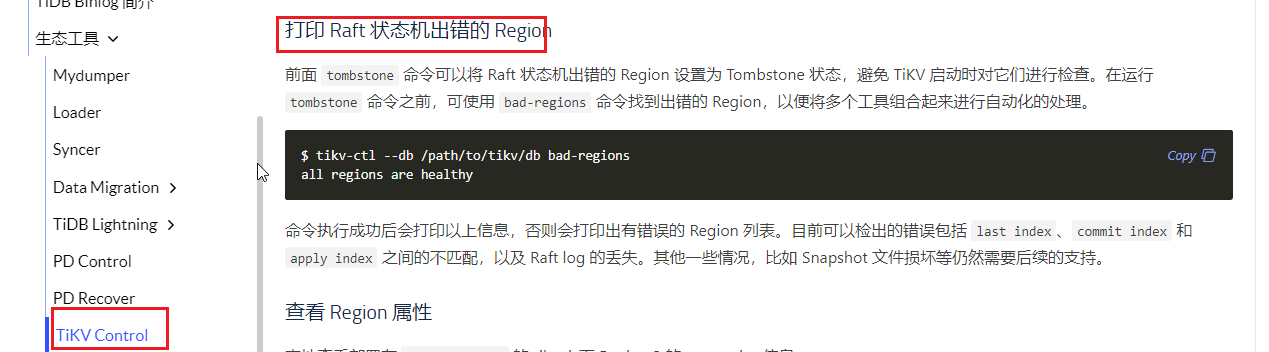
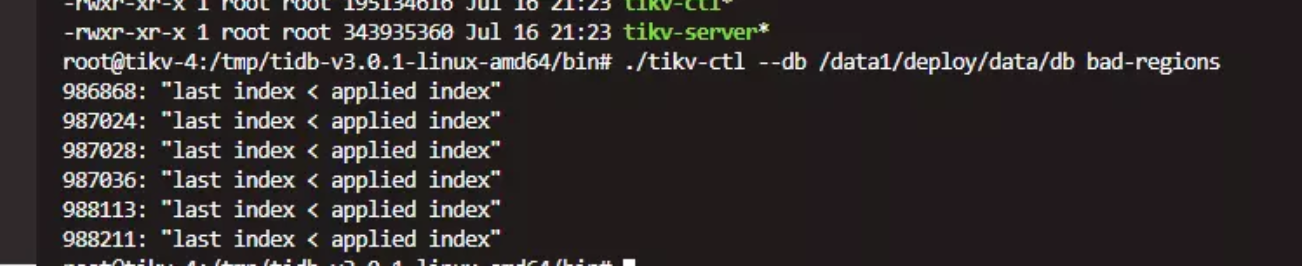
tikv-ctl --db /path/to/tikv/db bad-regions 两台坏的,分别如下


发现坏掉的 region是 31101(实际上因为用的是2.1.4,每次只显示一个,处理完后,才会显示下一个,效率很低,后来在 @戚铮 大佬的指导下,换用tikv-ctl 3.x ,每次可以显示全部的坏的region )
ansible-playbook stop.yml -l tikv_servers 停掉全部tikv节点

此时@张曾钧@PingCAP 提示用 tikv-ctl --db /path/to/tikv/db tombstone -p 127.0.0.1:2379 -r 把坏的 region 设置为tombstone ,但是报错

通过执行 pd-ctl region 31101 发现
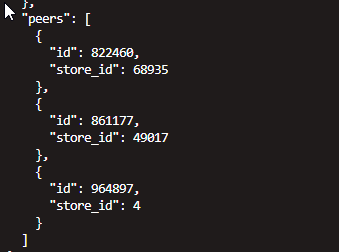
这个region有两个副本是在坏节点上,超过一半损坏(剧透一下,实际上最后发现,出问题的都是损坏超过1半的,1/3的都自己恢复了)
尝试执行 operator add remove-peer 发现删不掉。
此时 戚铮 大佬出场。
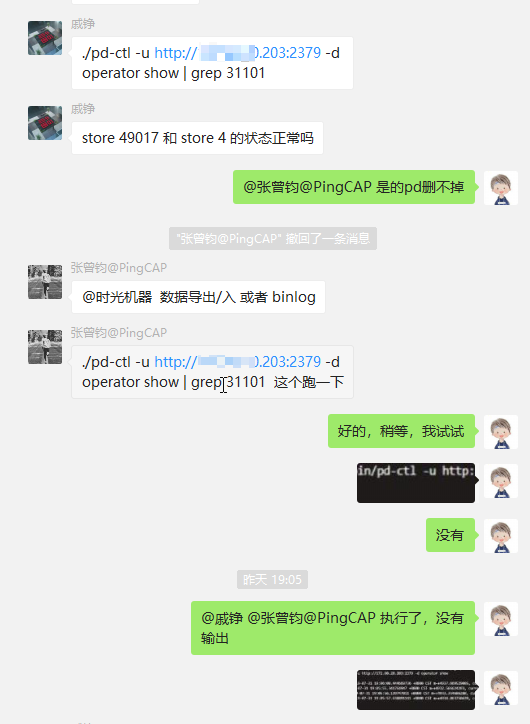
经过一番测试,发现 region31101很坚挺,使用 recover-mvcc 恢复不了,前面说了是因为损失超过一半副本的原因,使用 operator add remove-peer 删不了,估计也是。
不能因为一颗老鼠屎,坏了一锅汤,部分region坏掉了,先尝试强制恢复试试,保证别的正常吧。
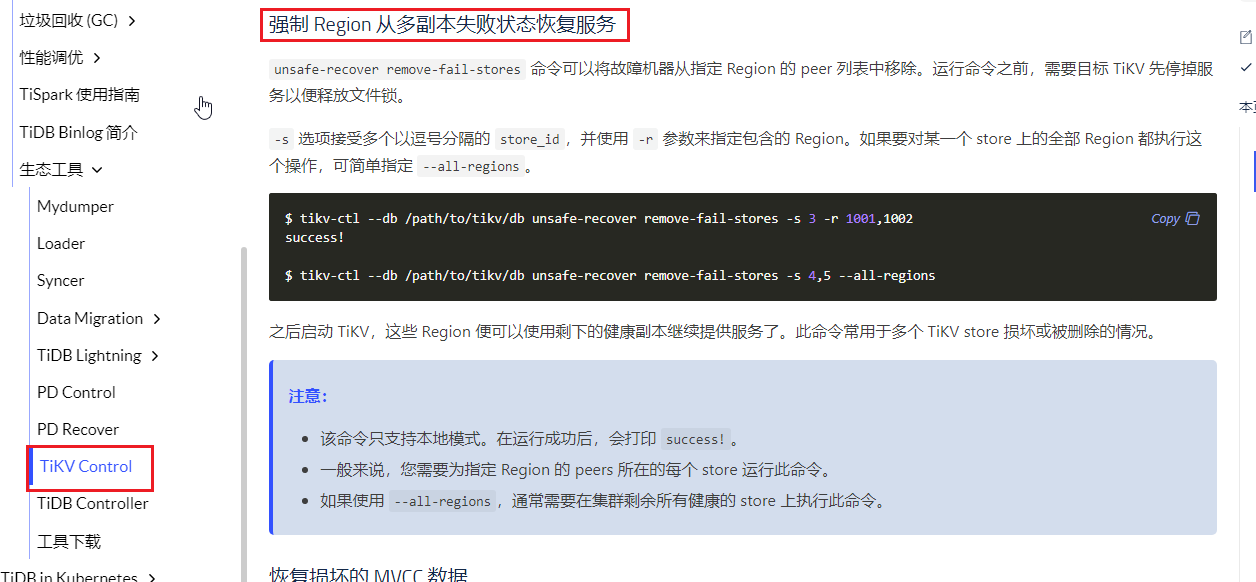
注意此命令是在好的store上执行

此时启动TiKV集群,执行region 31101,坏掉的已经删掉了,但是服务还是起不来。
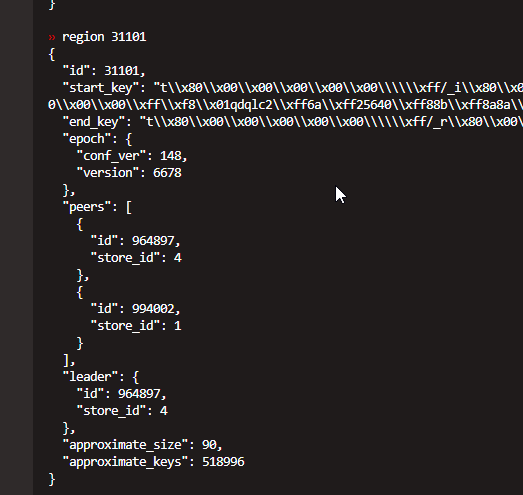
此时执行

此时在 @戚铮 老大的指导下,升级 tikv-ctl ,
结果202这台,一共三个region坏了,处理了俩,感觉遥遥无期,下了tikv-ctl 3.x后发现,就还有一个坏的。胜利在望。

重复上述操作后,此节点终于up了
218这个有6个坏的
unsafe-recover remove-fail-stores 一通后,终于起来服务了。
Round 4 服务已可以启动,总结一下
先stop TiKV
如果坏的region少于一半,可以尝试 recover-mvcc
如果超过一半,就玄乎了,是在不行就 unsafe-recover remove-fail-stores,然后再 tikv-ctl --db /path/to/tikv/db tombstone -p 127.0.0.1:2379 -r 31101,xx,xx,xx
再start TiKV
你以为万事大吉了?命运就是爱捉弄人。

回到原点。
最后还是损失了部分,但是量不大。
对TiDB不够熟悉,很多流于表面
对TiDB的文档和工具使用不熟练
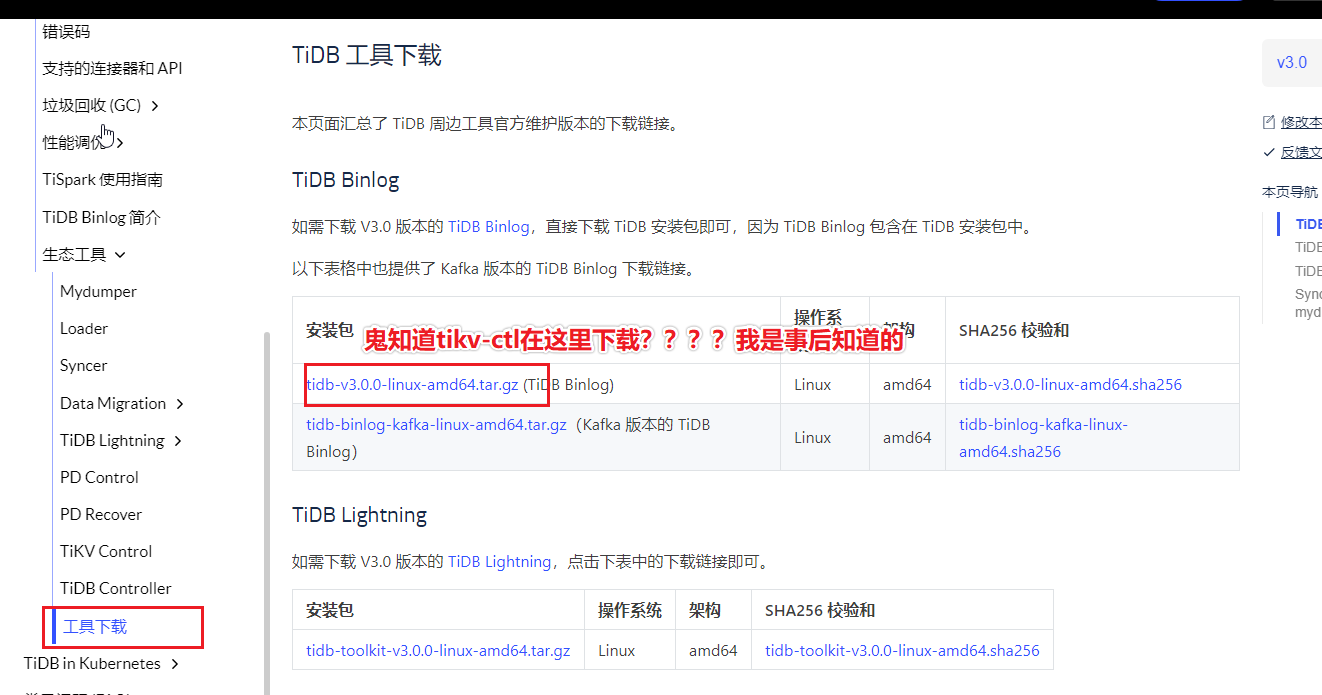
TiDB的文档不太清晰,比如在故障处理里,没有内链像是pd-ctl,tikv-ctl,甚至都没有提,在pd-ctl和tikv-ctl等工具没有提如何下载,在工具下载里,没有提包含啥工具。很佛系
多亏了群内各位大佬的热心指导
如果是TiKV有问题,先stop TiKV
如果对于损坏数小于半数的,可以尝试 recover-mvcc
对于超过半数的,可以尝试 unsafe-recover remove-fail-stores ,再 将store设置 tombstone
再start TiKV
可以结合 tidb损坏tikv节点怎么恢复集群 来做。
多试验,尤其是做极限测试,并且尝试处理,会积累很多经验。
虽然没有瑞恩没有全须全尾的拯救回来,但是缺胳膊少腿总好过没命啊。
其实如果不考虑OLTP的场景,还可以尝试使用clickhouse。这是之前整理的clickhouse的一些文章。