Raft日志
1、Raft与Multi Raft
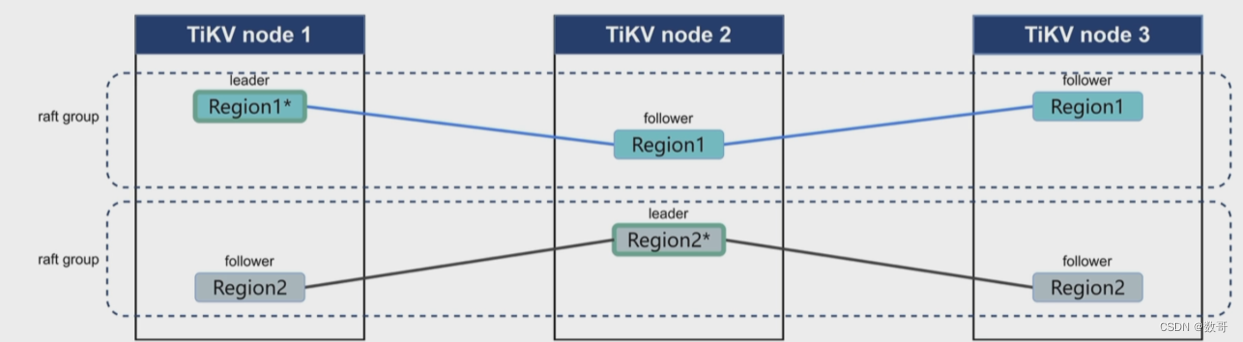
一个region的大小是96Mb ,最大144Mb 。它里面记录的是日志条目,是个左闭右开区间。
[1,999) [1000,1999)
一个TiKV当中如果超过5万个Region,则管理成本就很高了。因为需要向PD汇报相关信息。
2、Raft 日志复制
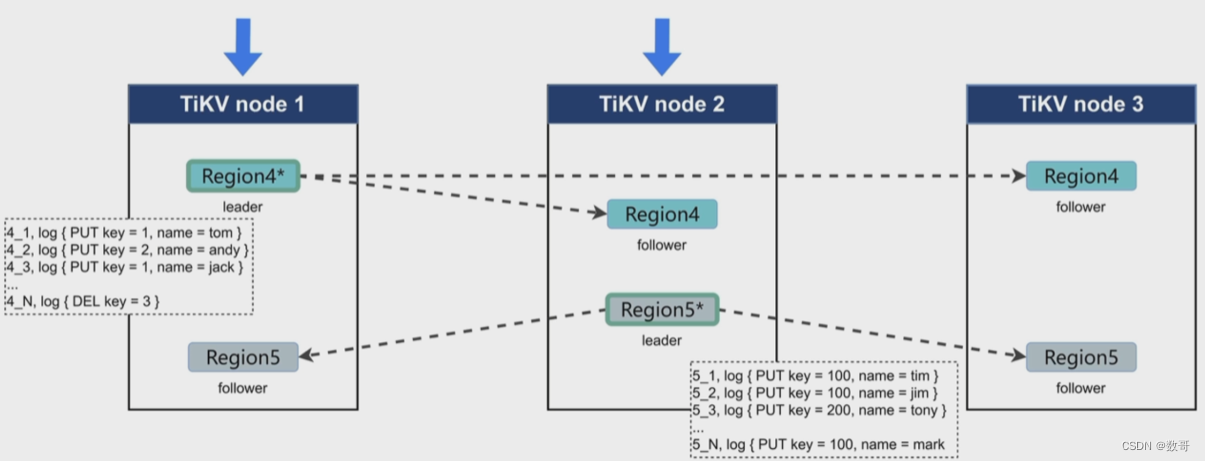
写入数据只发送给leader,然后leader分发给follower
2.1、复制流程总览
- Propose
- Append
- Replicate
- Append
- Commited
- Apply
2.2、Propose
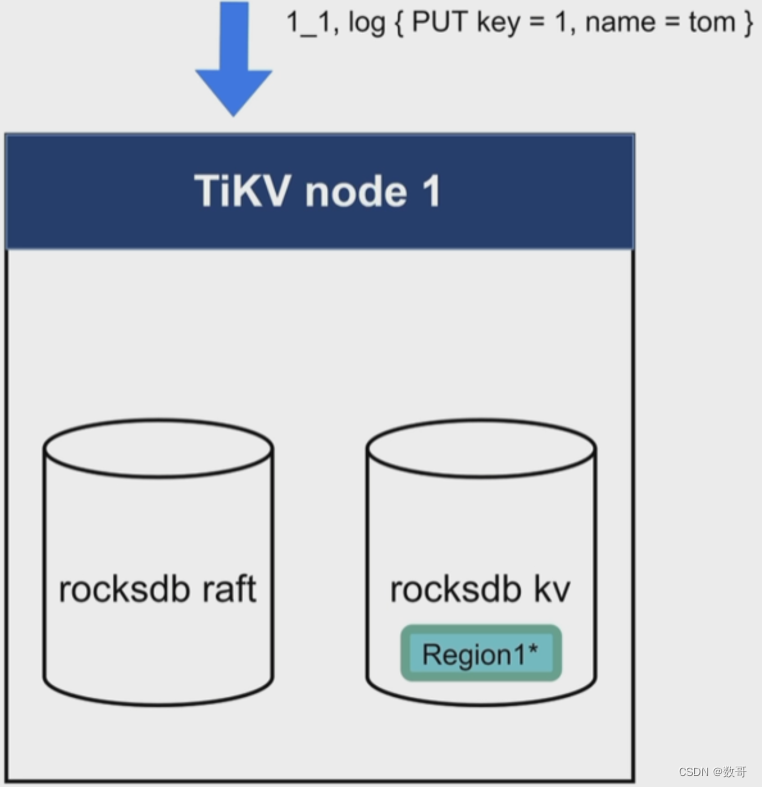
数据的变更(增删改),都是以追加的方式记录到内存中。
2.3、Append
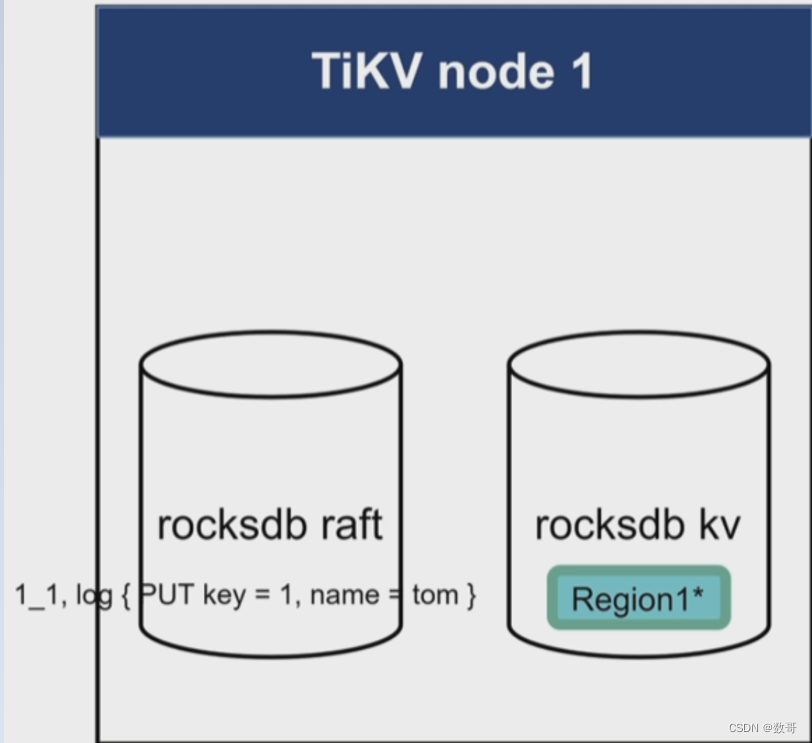
内存中的记录条目持久化到Rocksdb raft
2.3、Replicate(Append)
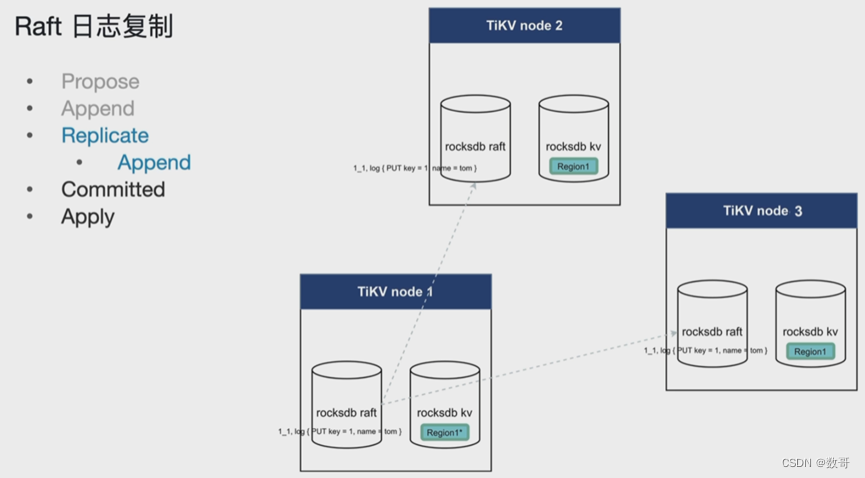
将leader中条目信息拷贝到follower上。并且追加到follower上的rocksdb raft。
2.4 Committed
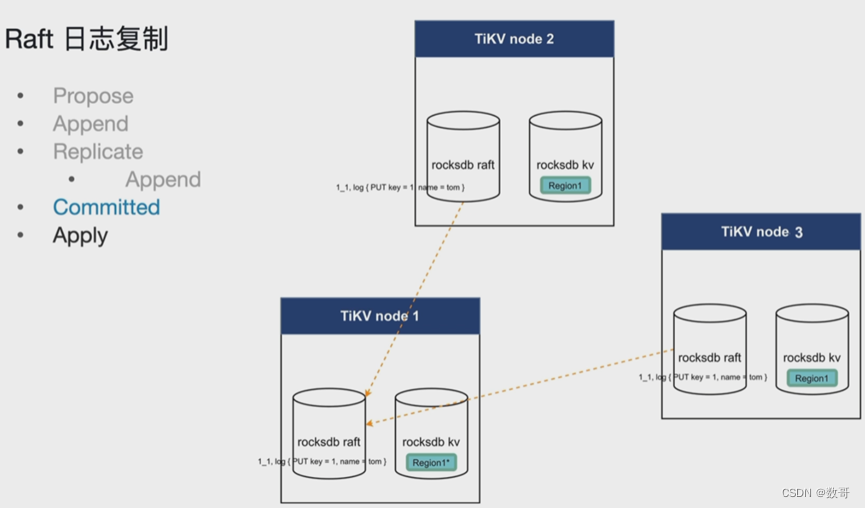
这个commited 是指ACK. 这个说的raft 日志的commit,跟sql语句commit没关。
用户的committed指的是事务层
2.4 Apply
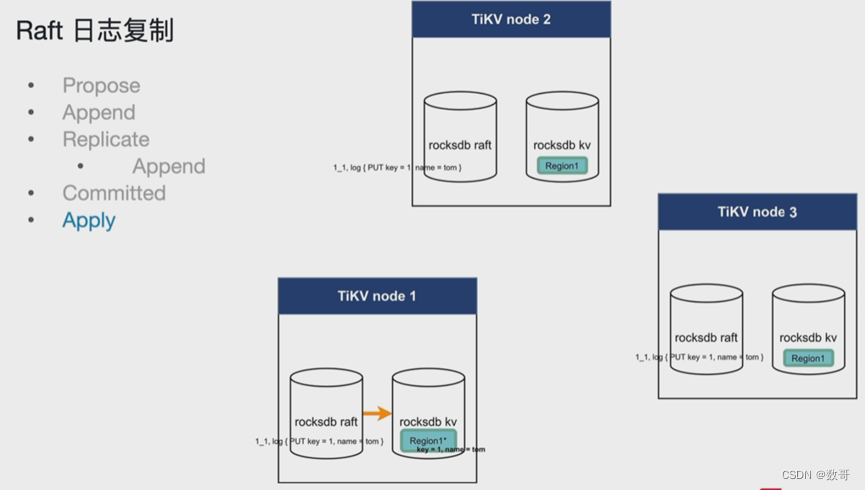
将raft的记录信息应用持久化到Rocksdb kv中。 用户的commited在这个阶段才算成功
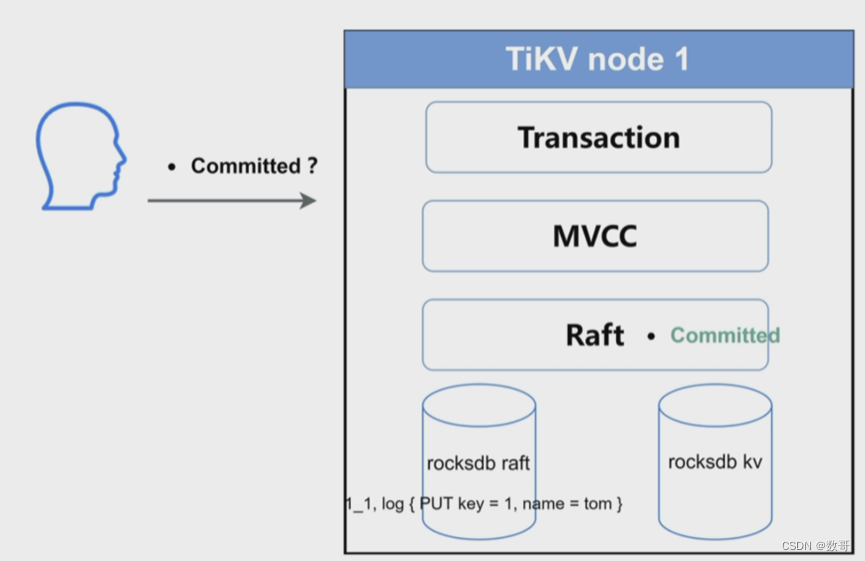
不仅raft 日志 事务应用的commit也成功了。
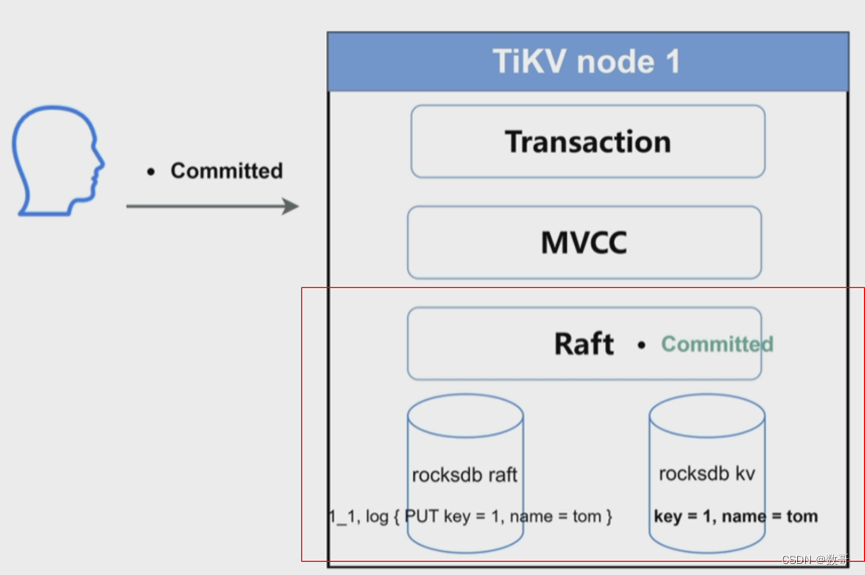
这里的数据写入,指的是已经通过了Transaction 和 MVCC层,之后的处理
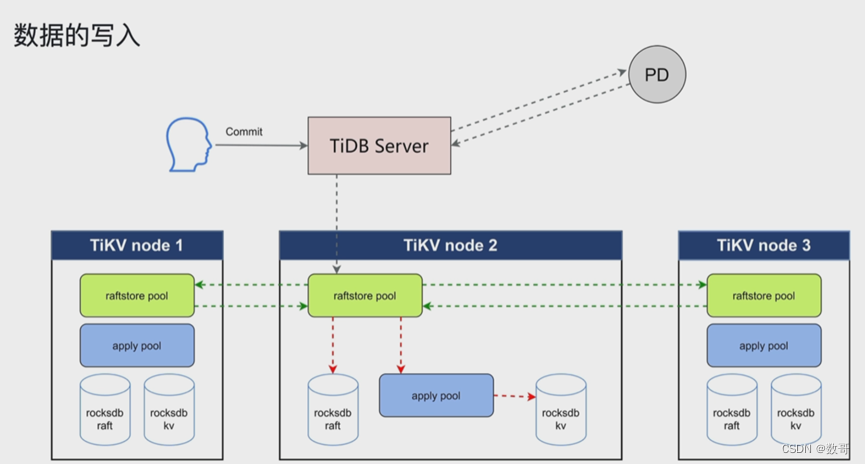
用户的commit 完成成功标识是: 已经commited状态的raft log 通过apply pool 应用到 kv当中。
3、Raft Leader 选举
3.1、原理
term 时期,将一个时间分成一段一段,这个一段一段(不是平均固定的长度)的时间就叫term。
可以把term理解成,恋爱期间的稳定期。
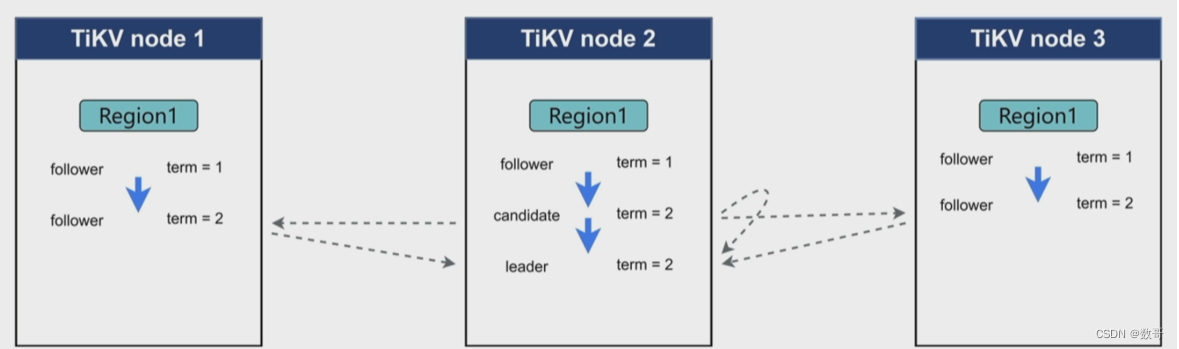
在集群刚开始创建的时候,当前并没有leader , 都是flower ,另外每个region当中都有一个计时器(election timeout 假设是10秒),这三个flower 当前都处于term 1 。term 1中,这三个flower都在等待集群当中leader给我心跳信息,如果一直等不到,超过10秒,则认为集群当中没有leader。 那么这个时候谁会率先达到这个计时器的等待值,假设这个时候node 2 率先达到了10秒,则会打破这个关系,则进入下一段关系 这个时候达到 term 2阶段。在term 2阶段,它就从flower 变成candiate,candiate的作用就是发送选票给其他节点,让其他节点投票给他。告知其他节点(包括自己)现在没有leader ,我要当leader。 同时告诉其他节点,我们现在要去到term 2的阶段。
那其节点凭什么选择node 2 ?
节点收到比自己term 大的消息时候,它就会同意那个节点的请求。
于是在term 2这个时期,node2 就选举成了 leader
实际只要超过一半即可。
3.2、节点故障
如果是节点故障,或者网络隔离的时候,如何处理?
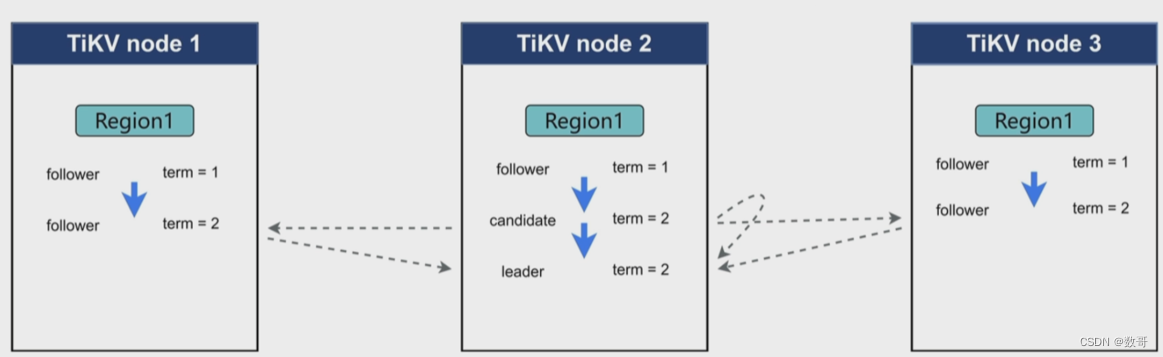
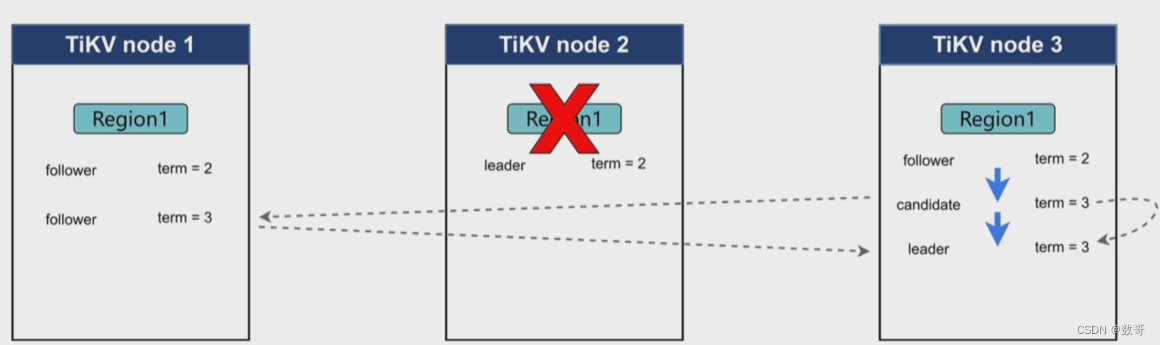
heartbeat interval time : 心跳间隔时间,leader 通过心跳间隔时间发送给flower,如果flower超过心跳时间还没有收到leader信息,则到下一个阶段。
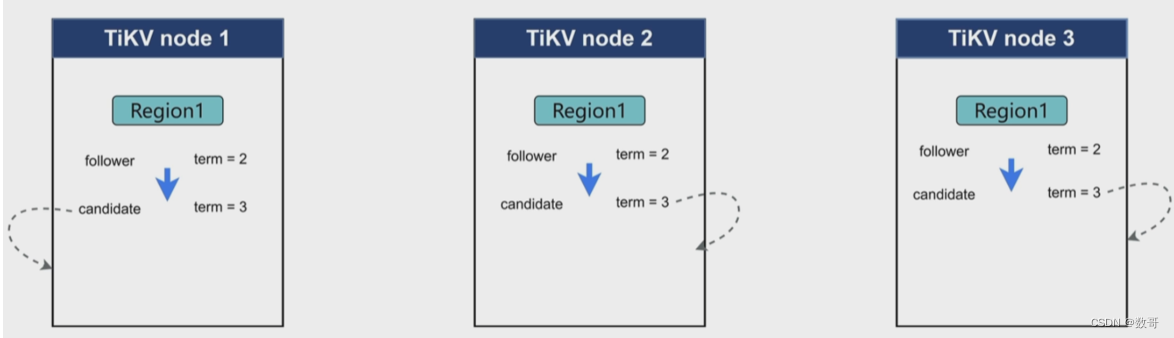
如果同一时间同时达到了 下一阶段,然后都投票给自己,这个时候就没有选出来,因为都一票。系统会重新发出投票,直到选出。 所以有可能出现延迟卡顿的情况,为了解决这个,可能将 电子计时器 的值设置的是范围,以前设置300ms,现在设置100-300ms。这样每个节点的region上的计时器 值是不一样的。 这样避免同时进入下一阶段。


时间间隔: raft-heartbeat-ticks(数量)*raft-base-tick-interval(单位间隔长度)
接下来 TiKV 的实现⾯临⼀件更难的事情:如何保证单机失效的情况下,数据不丢失,不出错?
简单来说,需要想办法把数据复制到多台机器上,这样⼀台机器⽆法服务了,其他的机器上的副本还能提供服务;复杂来说,还需要这个数据复制⽅案是可靠和⾼效的,并且能处理副本失效的情况。TiKV 选择了 Raft 算法。Raft 是⼀个⼀致性协议,Raft 提供⼏个重要的功能:
Leader(主副本)选举
-
身份
三种身份:Leader candidate follower
有个时间轴,在某个时间,它们有对应的身份认证。 这某个时间就是用term 表示。 假设时间间隔是100ms. -
选举流程
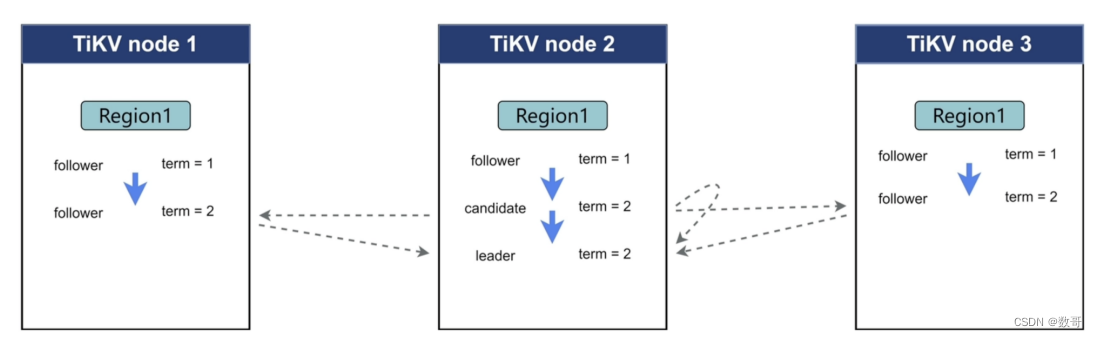
初始化时候(term=1),假设node3 是leader。 node1/node2 是flower。 node3 不断向node1/node2发送心跳,这个时候flower就知道主节点还存在。 flower有个预设的属性值,例如设置100ms ,100ms都没收到leader的心跳,则这个节点进入到candidate 身份认证,也就是这个node2 进入term 2 时期,这个它就会尝试当leader .
然后对于node 1 可能它的100ms(这个时间对于每个node也是随机的,并不是固定)还没有到,它还是处于flower状态 。也就是还处于tiem 1 时期。
在term 2时期,node 2 处于candiatite状态,它会向其他node 发送自己的选票,告诉其他节点我要争取leader 。 这个node 1.收到node 2的选票(tiem 2),则节点1给节点2 投票(因为tiem 2 比tiem 1大,所以投票给它),同样node2 也会给自己投票 。 根据raft协议,只要收到大部分票数,则可以成为leader。 -
成员变更
如添加副本、删除副本、转移 Leader 等操作
⽇志复制
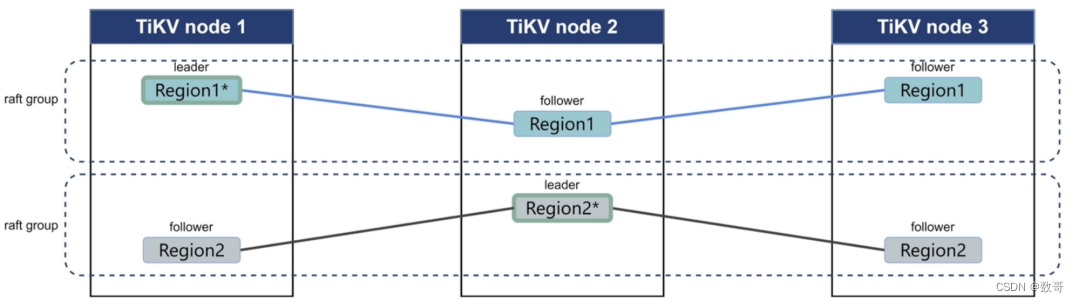
region 存的数据是kv,这个k是按照二进制的大小 有序存放,region大小是96M,如果超过了96,达到了144M 则这个region会进行拆分
TiKV 利⽤ Raft 来做数据复制,每个数据变更都会落地为⼀条 Raft ⽇志,通过 Raft的⽇志复制功能,将数据安全可靠地同步到复制组的每⼀个节点中。不过在实际写⼊中,根据 Raft 的协议,只需要同步复制到多数节点(返回对应ACK),即可安全地认为数据写⼊成功。
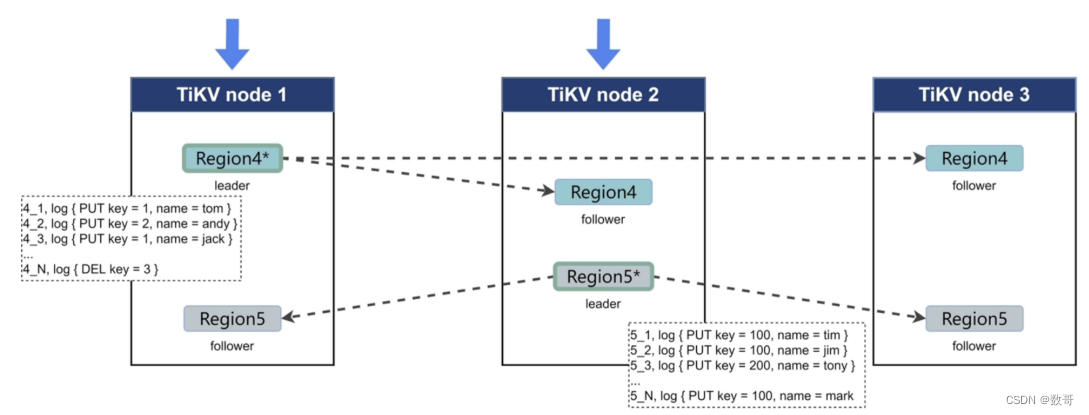
- 同步步骤
- Propose
接收到用户请求,leader此时就是Propose状态,收到日志写入请求。 - Append
将对应的日志写入到rocksdb raft中(针对leader) - Replicate
然后把日志同步给flower- Append
在flower 中,将flower 日志落盘,成功后,返回ack给到leader。
- Append
- Committed
leader 收到超过半数以上的ack,就认为(日志)的同步是成功的,此时提交 - Apply
通知各个副本进行数据的变更。这时候数据的变更才写入到RockDB KV
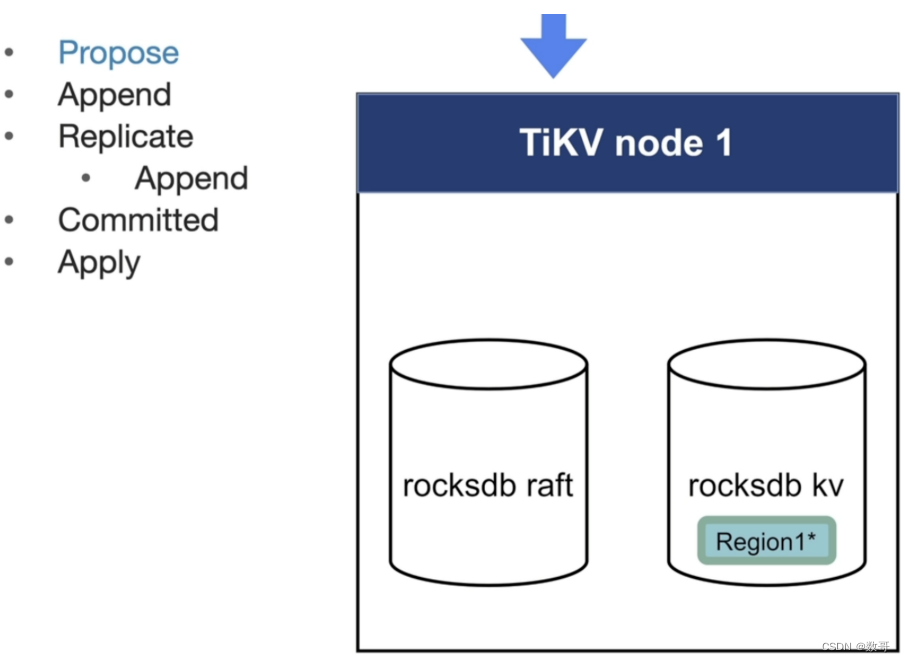
TiKV 磁盘有两个部分,一个是 raft,一个是 kv。 相当于一个是日志,一个是kv。副本间的同步其实是通过raft(日志)实现。
- Propose
总结⼀下,通过单机的 RocksDB,TiKV 可以将数据快速地存储在磁盘上;通过Raft,将数据复制到多台机器上,以防单机失效。数据的写⼊是通过 Raft 这⼀层的接⼝写⼊,⽽不是直接写 RocksDB。通过实现 Raft,TiKV 变成了⼀个分布式的 Key-Value 存储,少数⼏台机器宕机也能通过原⽣的 Raft 协议⾃动把副本补全,可以做到对业务⽆感知。