TiDB Server
1、TiDB总览
1.1、TiDB Server架构
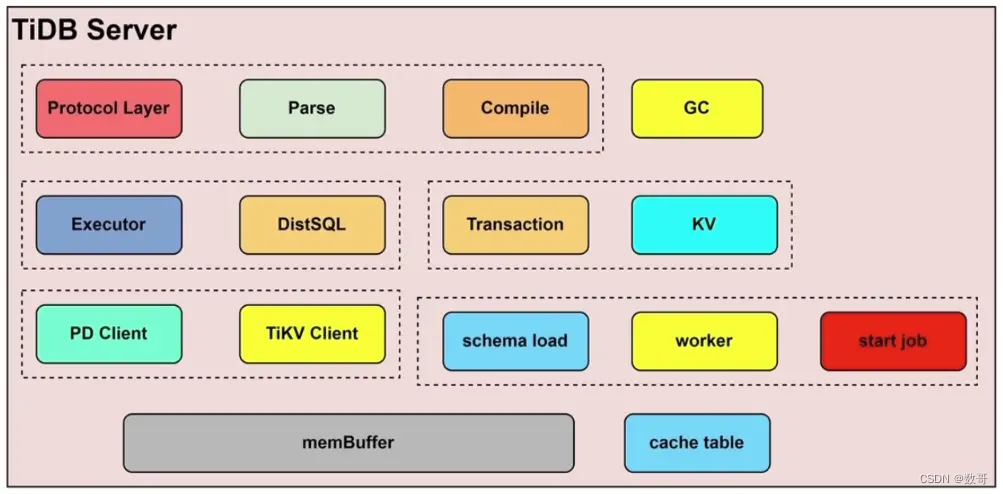
TiDB Server 是无序的,不存储数据。
- (Protocol Layer/Parse/Compile): 负责SQL语句解析和编译(优化)。
- (DistSQL/KV/Executor): 执行生成的计划。 简单的SQL(例如直接通过主键查到)使用KV,DistSQL复杂SQL执行计划的生成。
- (Transaction/KV):这个和负责事务处理相关的进行。
- (PD Client/TiKV Client):这个负责与PD和TiKV 交互的进程。 例如获得时间戳TSO,就是通过PD Client跟PD获取。
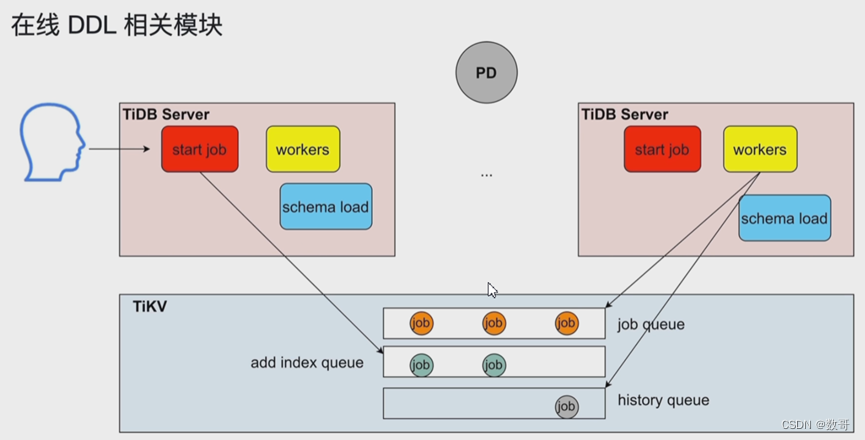
- (schema load/worker/start job): 这三个进程主要负责online ddl
- memBuffer: 缓存当中的数据,类似sga
- cache table: 缓存表的内存区域。
- GC: 垃圾回收,将MVCC过期版本数据进行回收
1.2、TiDB Server 主要功能:
- 处理客户端的链接
- SQL 语句的解析和编译
- 关系型数据与 KV 的转化
- SQL 语句的执行
- Online DDL 的执行(DDL 操作不会阻塞读写,但对整个 TiDB 来说,同一时刻只能有一个 TiDB Server 进行 DDL 操作)
- 垃圾回收
- 热点小表缓存
- 多个 TiDB Server 轮换选举 Owner 节点,Owner 中的 worker 负责执行 DDL
- DDL job 会存储在 TiKV 中进行持久化
- TiDB 是用 Go 开发的
- TiDB Server GC 默认 10 分钟触发一次,删除当前时间上一个 safe point 之前的历史版本数据
- 热点小表缓存,限制表数据需在 64m 以下,可通过 ALTER TABLE users CACHE; 将 users 表放入 TiDB Server 的 cache table 中。
- 热点小表缓存如何保证读写一致的问题:tidb_table_cache_lease=5 参数控制缓存租约。5s 之内用户可以从缓存中读取数据;租约到期前,任何用户不能修改此表,租约过期后,写数据直接写入 TiKV,读也是从 TiKV 读,完成写操作之后,缓存重新续约,缓存内容也会刷新。所以当租约到期时,读性能会下降。不支持对缓存表直接做 DDL 操作,需要先关闭。
- TiDB 中的表分为两种:聚簇表、非聚簇表。聚簇表需要有主键,非聚簇表可以有主键,也可以没有。KV 转换时,聚簇表使用主键作为 key,非聚簇表不管是否定义了主键,都会生成一个 key。
- Protocol Layer 通过 PD Client 异步向 PD 请求 TSO,同时继续进行 SQL 解析和编译,在实际执行前,获取异步请求 TSO 的结果
2、SQL语句处理
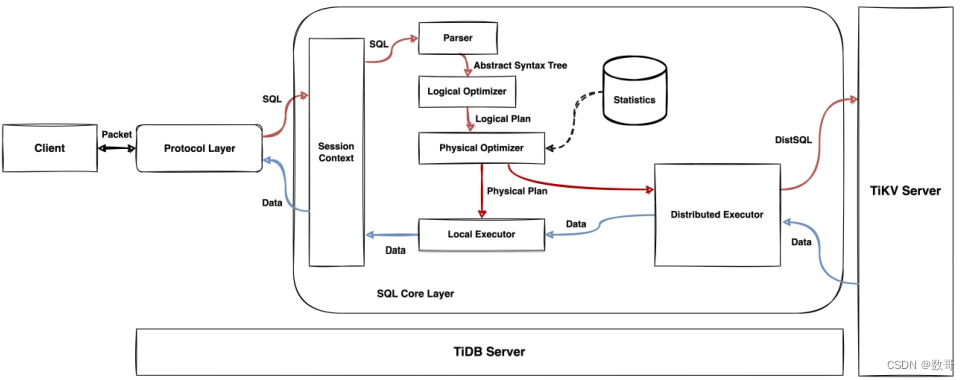
**功能:**负责客户端的连接。 连上之后把SQL语句发送过来,所以第二件事就是解析这些语句。 然后生成一个分布式的执行计划。它是无序的,不保何数据。一个挂掉了,通过一些负载均衡技术,连其它的就可以。
语句的解析和编译
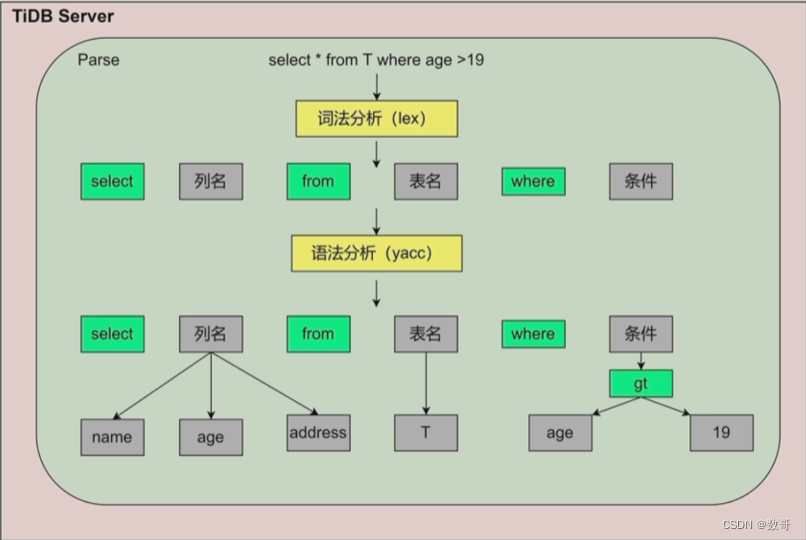
把语句拆分成一个个token,生成一个AST语法树
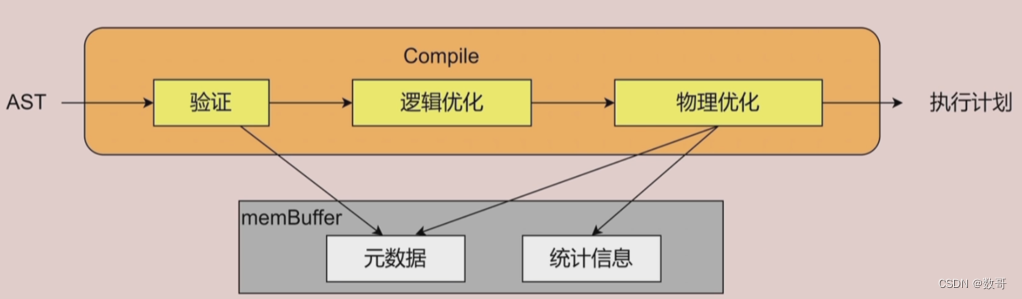
按照已经解析好了执行计划,把这个执行计划给到executor ,然后它按照plan生成的树状执行计划,执行都时候分两种,
-
第一种复杂的SQL例如过滤、范围,关联,嵌套等 防止跟TiKV耦合度太高,中间抽象出一层DistSQL接口。经过DistSQL 都会变成一个个简单的单表计算任务。
-
第二种KV ,简单的SQL,POINT CACHE(点查的模块),例如根据主键或者唯一索引,查看一行或0行记录这种。
SQL层
SQL 层,对外暴露 MySQL 协议的连接 endpoint,负责接受客户端的连接,执⾏SQL 解析和优化,最终⽣成分布式执⾏计划。TiDB 层本身是⽆状态的,实践中可以启动多个 TiDB 实例,通过负载均衡组件(如 LVS、HAProxy 或 F5)对外提供统⼀的接⼊地址,客户端的连接可以均匀地分摊在多个 TiDB 实例上以达到负载均衡的效果。TiDB Server 本身并不存储数据,只是解析 SQL,将实际的数据读取请求转发给底层的存储节点 TiKV(或 TiFlash)。
协议层
protocol layer :协议层,能够让tidb在网络层中提供服务,例如mysql 协议的服务,通过之后,然后客户端连上tidb,把SQL语法发过来
上下文
session context: 会话上下文。例如存放用户登录的数据。登录成功后,SQL语句就发送给解析层
解析层
parser: 解析层,当然这个SQL肯定还是要 前往到具体到某台TiKV server上,集群当中的某一个leader上。所以它要去到哪个leader上面呢,它会去问pd(大脑),要对应的 data location,找到某个tikv server的地址; 另外还有个功能就是将SQL语句变成 树形结构,这个树形结构当中会保存 这条SQL语句要访问的对象以及对这个对象的操作。
逻辑优化器
logical optimizer : 逻辑优化器,
统计信息:通过一系列规则,例如总行数等辅助信息。这些辅助信息有可能对这个SQL语句的执行 起到帮助的作用
物理优化器
physical optimier: 物理优化器,拿到这些统计信息再结合逻辑优化器生成的执行计划。 来生成一个更好的物理执行计划。 这个执行计划会交由两个执行器来处理,
本地执行器
local executor: 如果我有一些命令,需要在客户端 所连的那一台TiDB Server上操作,那这个时候就会 本地执行器来做
分布式执行器
Distributed Executor: 这个SQL,是需要去到TiKV上操作命令的执行,则这些SQL 会交给分布式执行器来处理。 为什么是分布式的,因为TiKV server实际是一个集群,上面执行的SQL是一个并行SQL,它会在多台TiKV server上同时执行这样的SQL
3、如何将表的数据转成kv形式
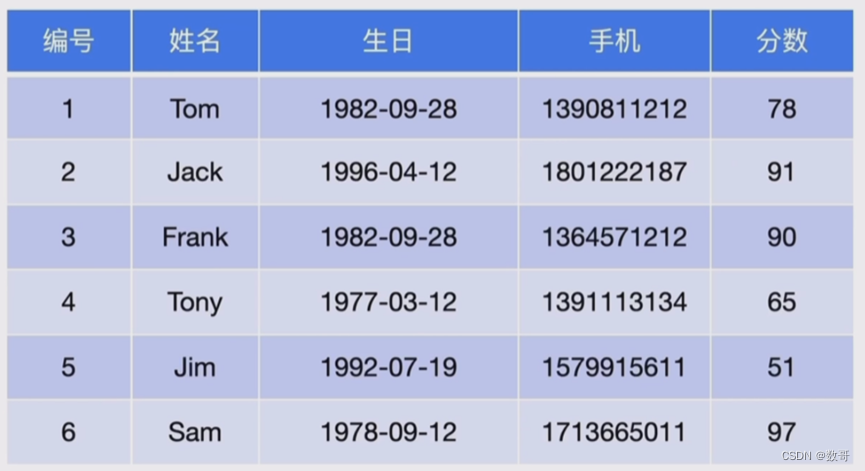
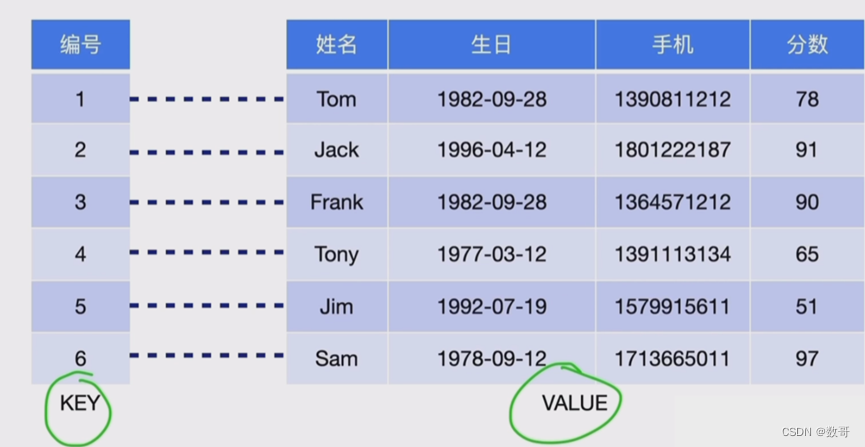
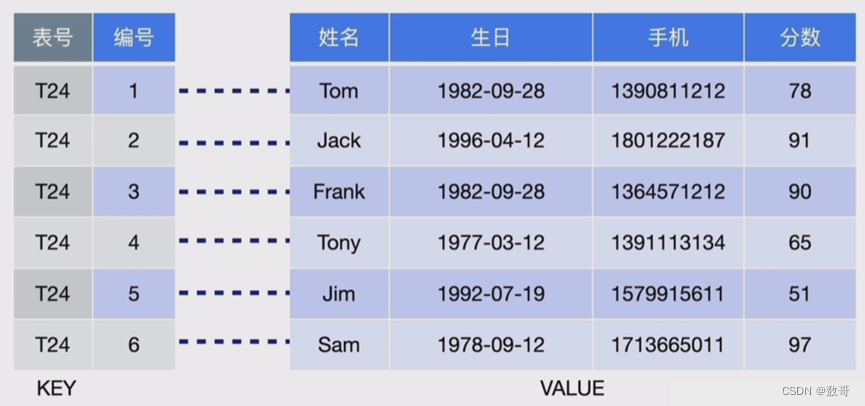


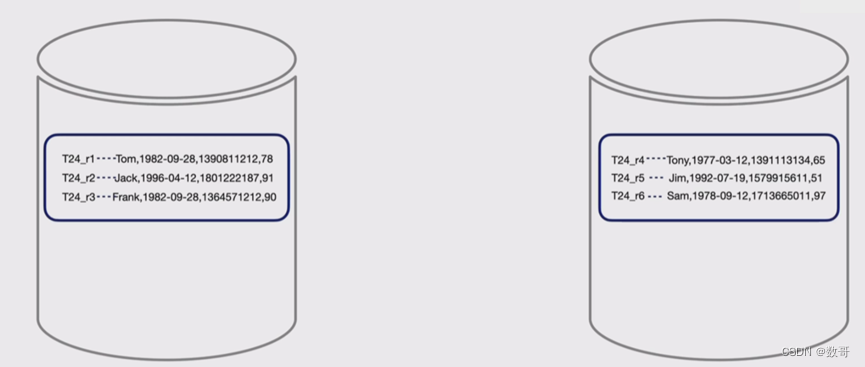
4、在线DDL相关模块
5、GC机制与相关模块
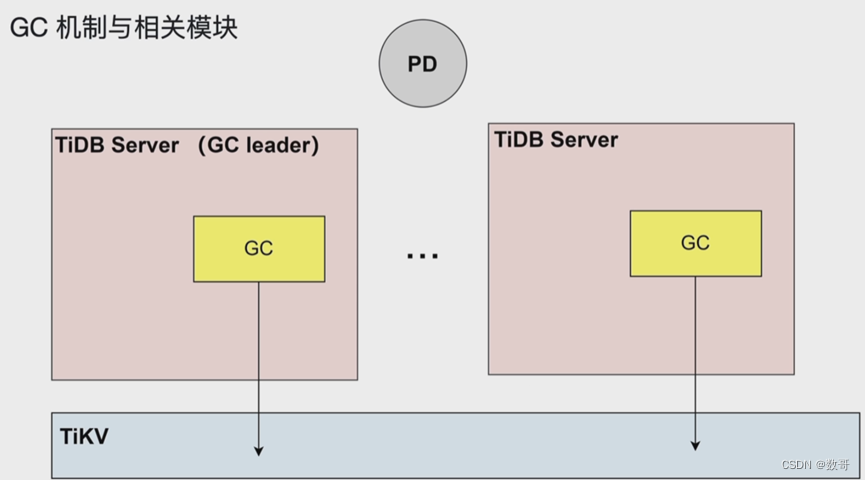
用于回收mvcc 旧版本,定期清理。 这个动作就叫gc
例如可以设置一个gc lift time = 4hout 则safe point 为4个小时,则四个小时内的数据即使增删改,也可以找到这四小当中的任意数据
6、TiDB Server 缓存
- TiDB Server缓存组成
- SQL结果
- 线程缓存
- 元数据,统计信息
- TiDB Server缓存管理
- tidb_mem_quota_query
- oom-action

语句执行过程中,需要的数据会先放到缓存中,这个很类似pga
tidb_meme_quota_query: 限制每条SQL使用的内存,占用缓存的大小
oom-action: 当超过tidb_meme_quota_query这个值后,是如何执行这条SQL(例如中断或者忽略)
7、热点小表缓存
- 表的数据量不大
- 只读表或者修改不频繁的表
- 表的访问和频繁
小表缓存原理
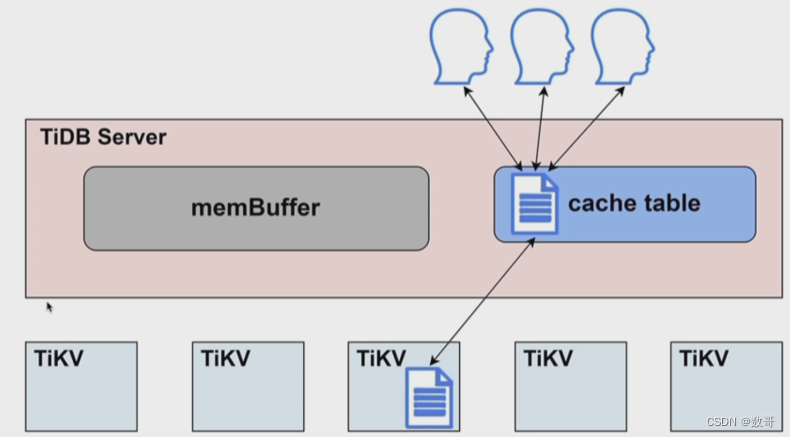
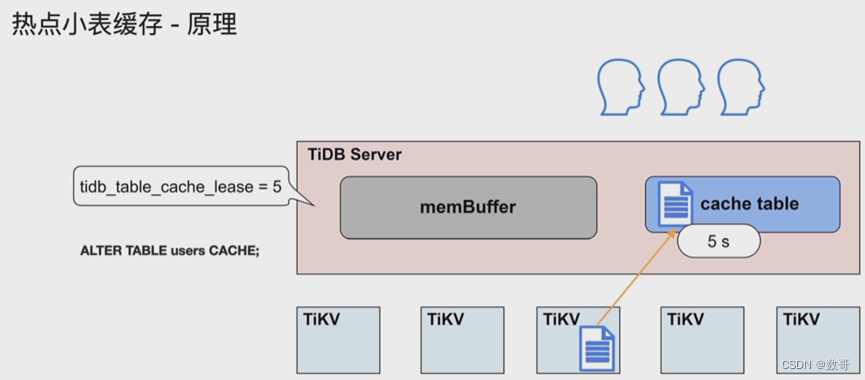
这张表的大小要小于64M才能放到cache
tidb_table_cache_lease: 租约,类似租房的有效期。
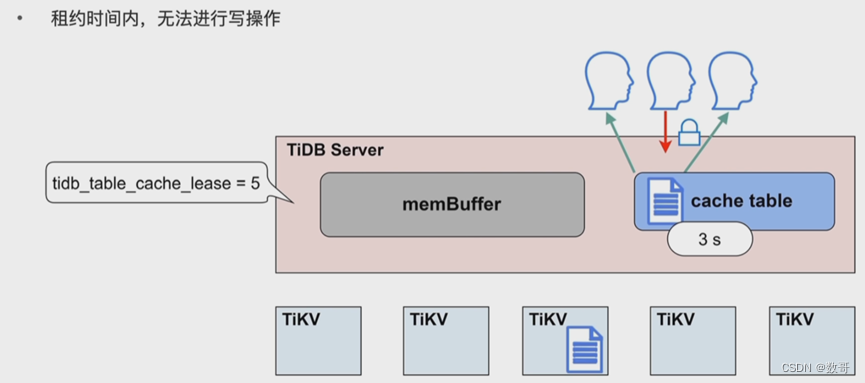
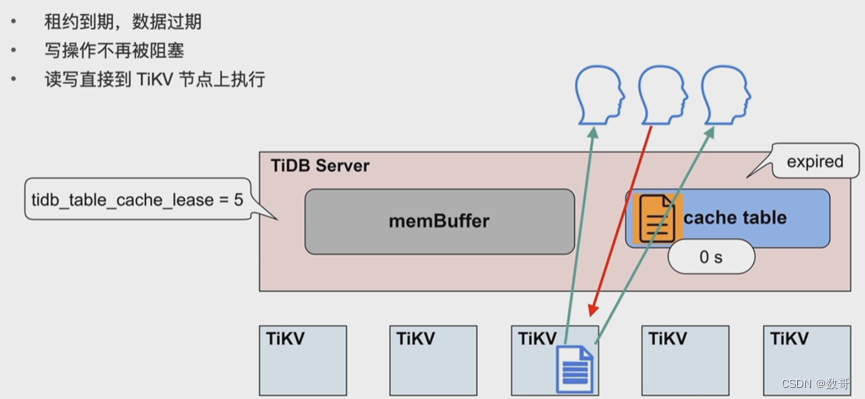
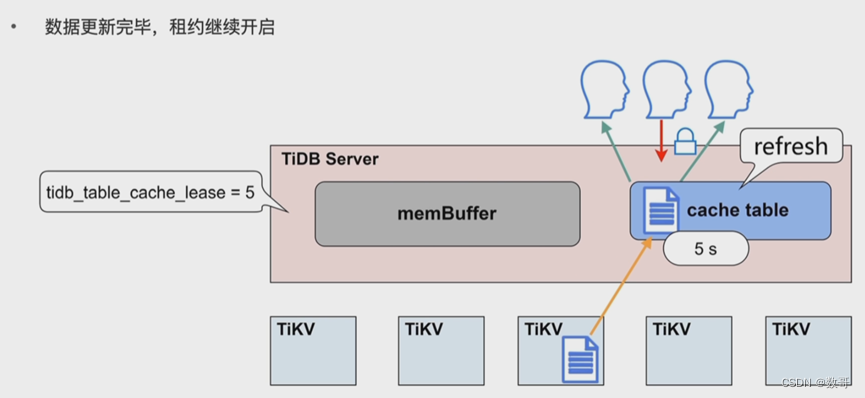
热点小表缓存-应用
- TiDB对于每张缓存表的大小限制为64Mb
- 适用于查询频繁、数据量不大、极少修改的场景
- 在租约(tidb_table_cache_lease)时间内,写操作会被阻塞
- 当租约到期(tidb_table_cache_lease)时,读性能会下降
- 不支持对缓存表直接做DDL,需要先关闭
- 对于表加载较慢或者极少修改的表,可以适当延长tidb_table_cache_lease 保持读性能稳定