监控指标诚然是发现问题于微末之时的极佳手段,但指标往往有其表达的极限。在很多情况下,单独看一个黄金指标并不能表征系统的健康程度,反而有可能被其迷惑,进而忽略相关问题。(本文所提及的Linux Kernel源码版本为4.18.10)
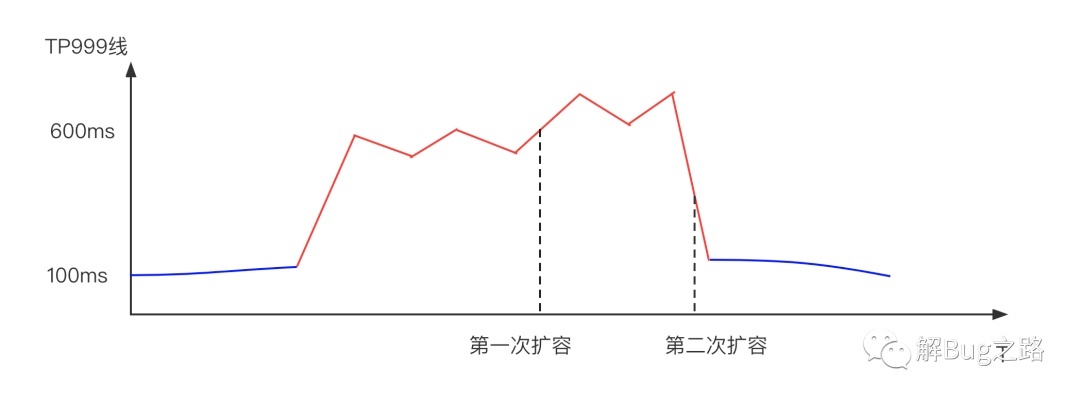
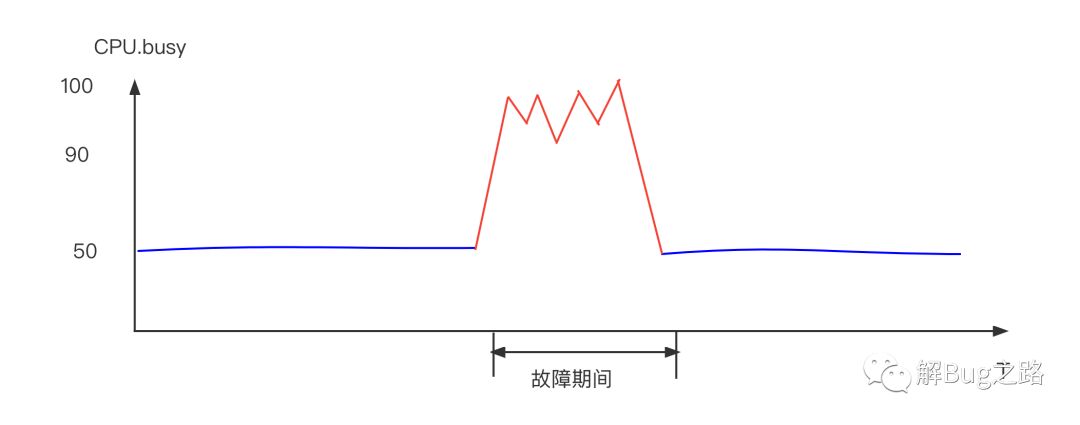
某天中午,某应用的999线突然升高。由于是个QPS高达几十万的查询服务,1分钟的升高就会影响数千个请求。初步判断应用容量不够,直接进行相关扩容,扩容后反而加剧了问题!不得已又做了一次紧急扩容,999线才恢复。这两波操作过去,20多分钟已经过去了。
为了防止问题再次发生,我们必须要彻查相关原因。于是笔者也就参与了调查。
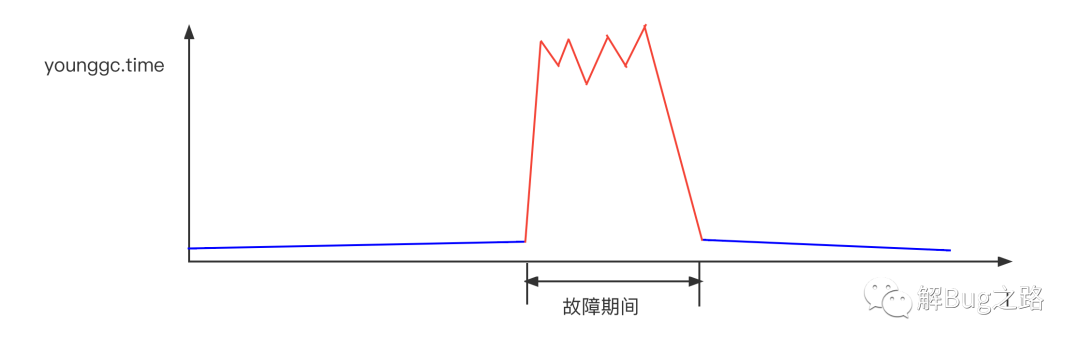
首先是去看常用的指标,例如CPU idle, GC Time。发现有一些机器的CPU达到了60%,而在这些机器中,young gc有一个大幅度的增长。
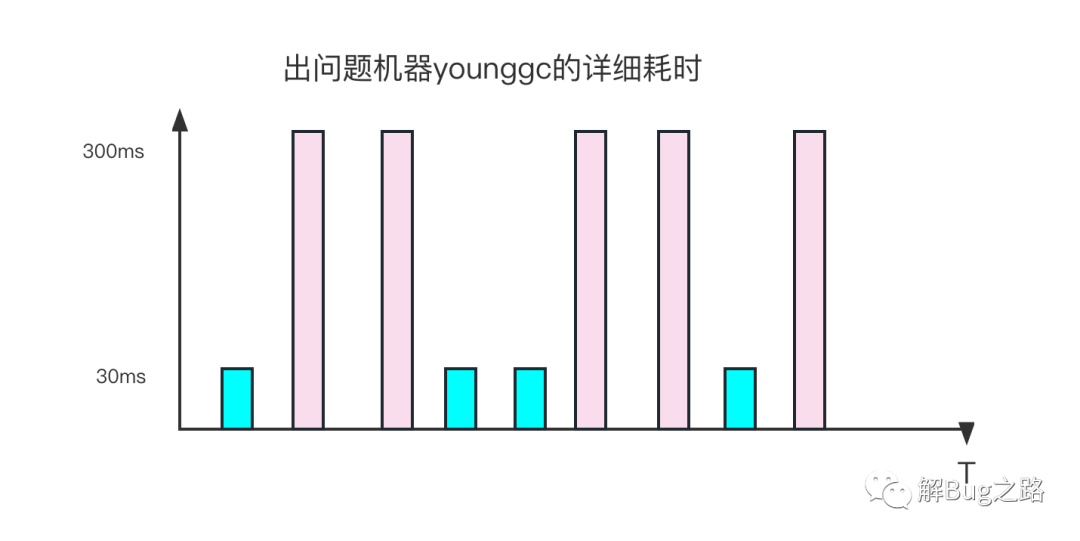
看上去GC问题。那么,笔者就开始思考为什么young gc升高。翻看gc日志。看到故障期间,不停的young gc。但这些young gc的表现很诡异。有时候young gc很快,只有数十毫秒,有时确达到了数百毫秒。而且这个耗时的跳跃没什么规律,不是从某个时间点之后就一直是数百毫秒,而是数十和数百一直参杂着。
观察young GC的详细输出,在数百毫秒的young GC时间里,大部分时间都在[Object Copy]上。令人奇怪的是。其Copy的Object大小确实差不多的。而这是个非常单纯的查询服务,故障期间,它的流量分布以及对应的Object分布不应该有非常大的变化。那么究竟是什么原因让同样大小以及数量的Object Copy会有十倍的差距呢?
再仔细观察,不仅仅是Object Copy,在其它的GC阶段也会出现时间暴涨的情况,只不过大部分集中在Object Copy而已。仅仅靠这些信息是无法看出来相关问题的。
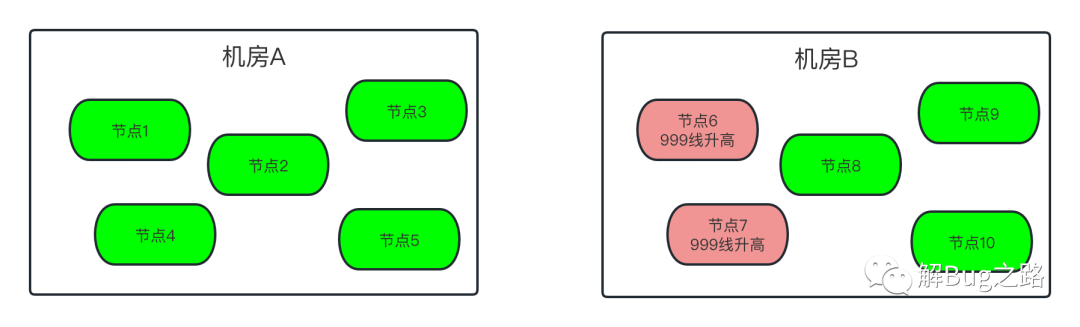
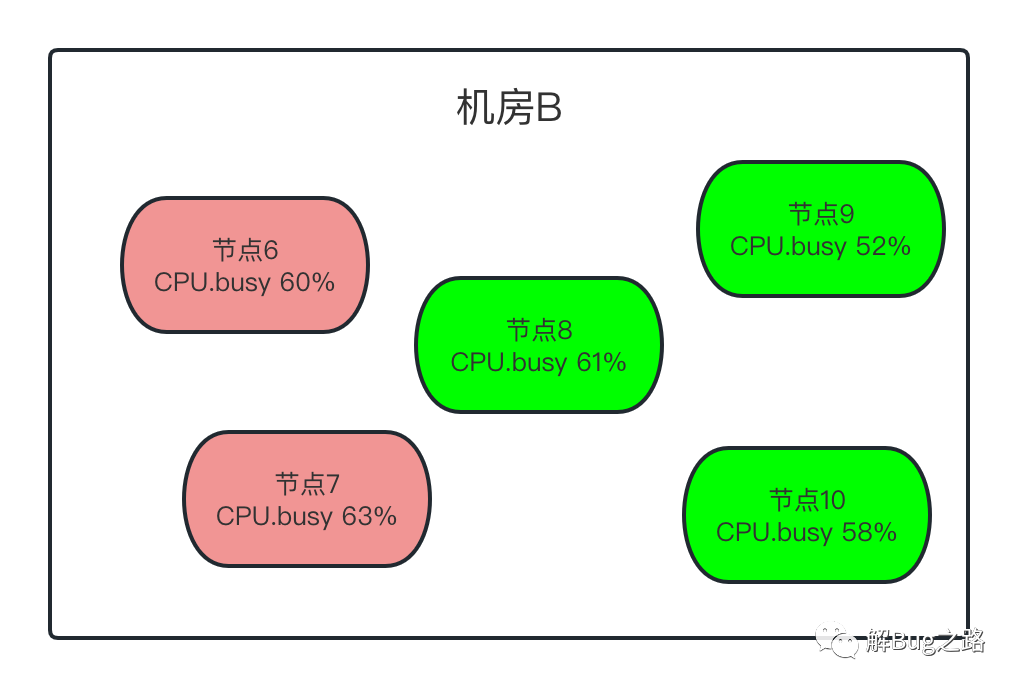
继续观察监控,发现问题出现在一部分机器上。而这部分机器都在一个机房(B机房)里面。另一个机房(A机房)的机器没有受任何影响。当然,出问题的机器都出现了Young GC飙高的现象。难道两个机房的流量分布不一样?经过一番统计,发现接口的调用分布只是略微有些不同。但细细思考一下,如果是机房流量分布不一样,由于同机房是负载均衡的。要出问题,也是同机房都出问题。但问题只集中B机房的一部分机器中。
那么既然只有一部分机器出问题。那么笔者开始搜索起这些机器的共同特征。young gc在这部分机器耗时都大幅增长。但由于笔者尚不能通过gc日志找出原因。那么就寻找了其它特征。
首先,是CPU.busy指标。笔者发现,出问题的机器CPU都在60%左右。但是,正常的节点CPU也有60%的,也有50%的,特征不是很明显。
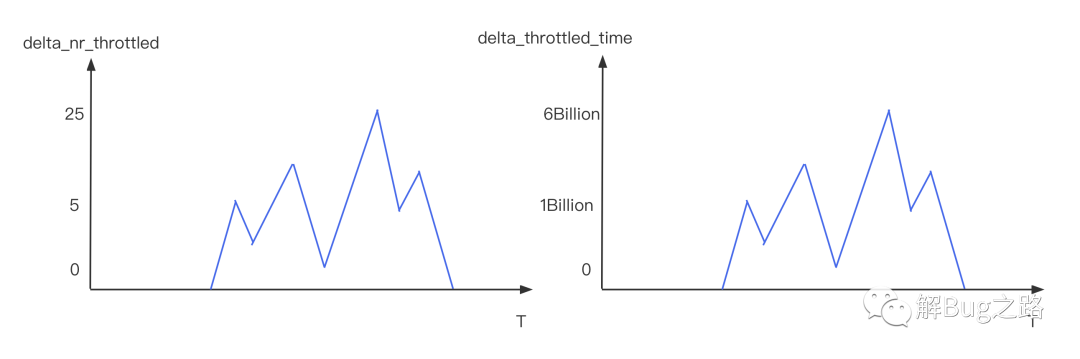
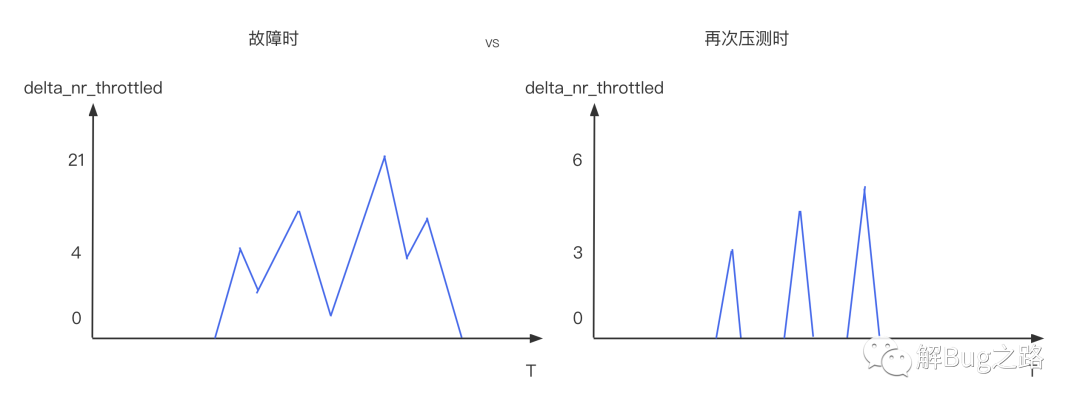
在笔者观察某台故障机器监控指标的时候发现,发现delta_nr_throttled和delta_throttled_time这个指标大幅度升高。
我们看下这两个指标的含义
nr_throttled: Linux Doc: Number of times the group has been throttled/limited. 中文解释: CGROUP被限制的数量delta_nr_throttled: 是通过取间隔1分钟的两个点,计算出每分钟CGROUP被限制的数量throttled_time: linux Doc: The total time duration (in nanoseconds) for which entities of the group have been throttled. 中文解释: 某个CGroup被限制的时间delta_throttled_time: 通过取间隔1分钟的两个点,计算出每分钟CGROUP被限制的总时间复制由于线上应用这边采用的是docker容器,所以会有这两个指标。而这两个指标表明了,这个CGroup由于CPU消耗太高而被宿主机的Kernel限制运行。而令人奇怪的是,这些机器的CPU最多只有60%左右,按理来说只有达到100%才能被限制(throttled/limit)。
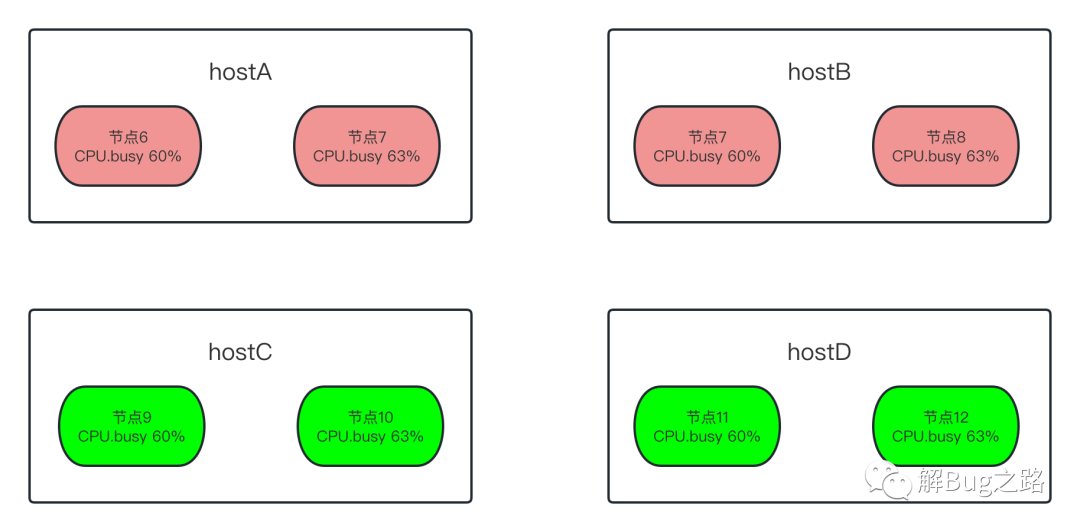
既然是宿主机限制了相关docker容器,那么很自然的联想到宿主机出了问题。统计了一下出故障容器在宿主机上的分布。发现出问题的所有容器都是集中出现在两台宿主机上!
查看了下这两台宿主机的CPU Busy,发现平均已经90%多了。
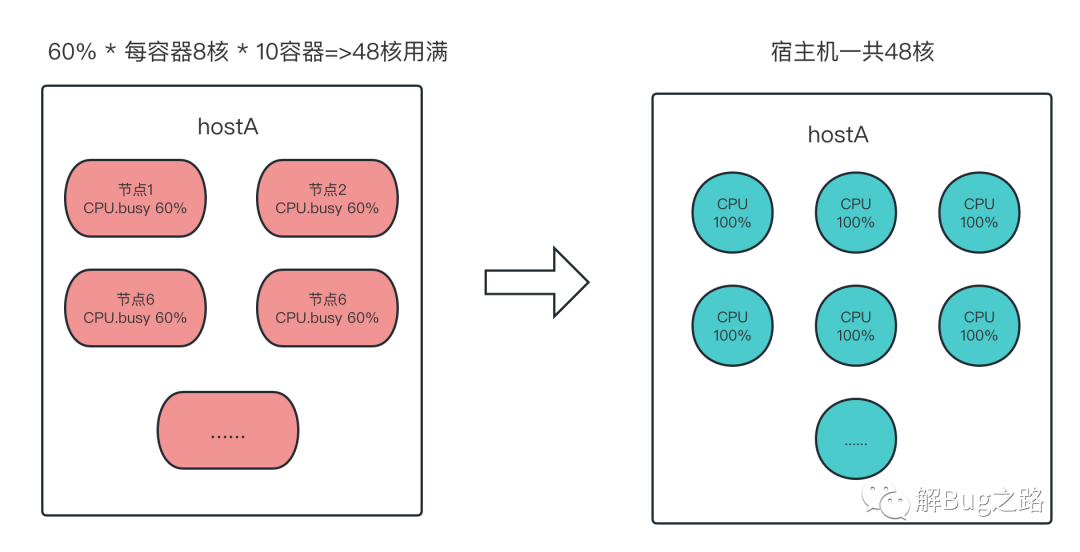
详细观察了下这两个宿主机,发现它们超卖非常严重。而且当前这个出问题的应用非常集中的部署在这两个宿主机上。一台48核的宿主机,仅仅出问题的这个应用就分配了10个,而且分配的资源是每个容器8核(实际上是时间片)。那么按照,每个容器使用了60%计算,正好用满了这个宿主机的核
60% * 10 * 8 = 48 正好和宿主机的48核相对应。复制
因为这次是通过API自动扩容,而由于打散度计算的原因,还是扩容到了这两台已经不堪重负的CPU上。同时应用启动加载时候的CPU消耗也加剧了宿主机CPU的消耗。
因为第二次直接通过API手动扩容,一次性在10多台宿主机上机器上扩了一倍的机器。这样分配在这两台不堪重负的宿主机上的应用流量降低到一半左右。进而使得999线恢复正常。
很明显的,容器的CPU Busy在很大程度上误导了我们的决策。在之前的容量压测中,压到期望的TPS时候CPU Busy只有50%多,而且基本是按照TPS线性增长的,就使得我们觉得这个应用在当前的资源下容量是绰绰有余。毕竟CPU Busy显示的还是非常健康的。
但没想到,在压测CPU 50%多的时候,其实已经到了整个应用容量的极限。线上的流量和压测流量的构造有稍微一点的区别,让CPU涨了个5%左右,过了那个宿主机CPU的临界点,进而就导致了应用出现了非常高的999线。
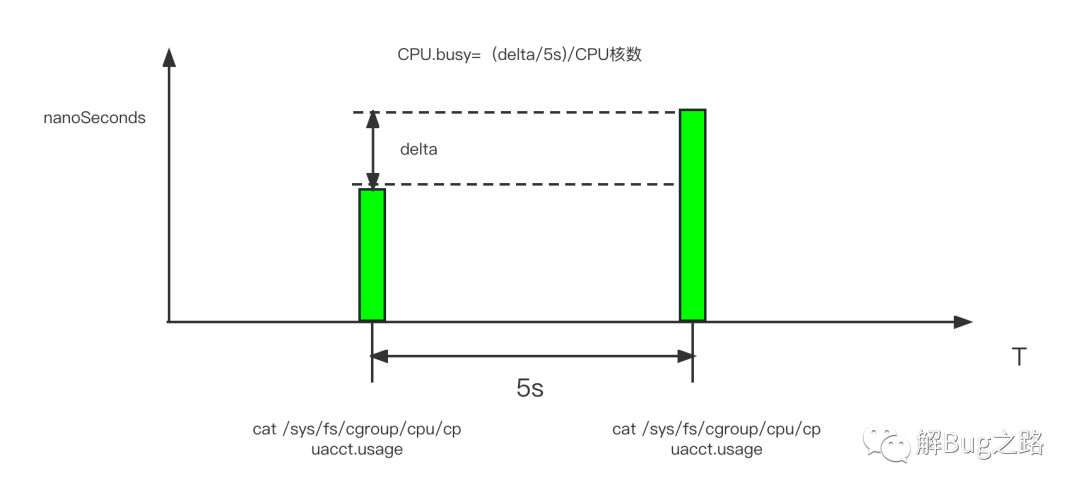
为了探究这个问题,笔者就不得不看下容器的CPU busy是如何计算出来的。毕竟Linux的CGroup并没有提供CPU Busy这个指标。翻阅了一下监控的计算公式。
每隔5秒取一下cpuacct.usage的数据cat /sys/fs/cgroup/cpu/cpuacct.usageCPU.busy = (cpuacct.usage(T秒) - cpuacct.usage(T-5秒))/((5秒)*CPU核数)CPU.idle = 1- CPU.busy复制
那么我们可以看一下cpuacct.usage是如何计算的。Kernel的代码实现为:
cpuusage_read |->__cpuusage_read |->cpuacct_cpuusage_readstatic u64 __cpuusage_read(struct cgroup_subsys_state *css, enum cpuacct_stat_index index){ /* 获取当前对应cgroup中的cpuacct结构体*/ struct cpuacct *ca = css_ca(css); ...... /* 遍历所有可能的CPU */ for_each_possible_cpu(i) totalcpuusage += cpuacct_cpuusage_read(ca, i, index); return totalcpuusage;}static u64 cpuacct_cpuusage_read(struct cpuacct *ca, int cpu, enum cpuacct_stat_index index) { // 从当前cgroup中获取对应相应的cpuusage结构体 struct cpuacct_usage *cpuusage = per_cpu_ptr(ca->cpuusage, cpu); ...... /* i=0计算的是user space的usage,i=1计算的是kernel space的usage */ for (i = 0; i < CPUACCT_STAT_NSTATS; i++) data += cpuusage->usages[i];}复制由代码可见,其计算是将所有CPU中的关于当前CGroup的cpuusage->usages中的user和system time相加,进而获取到最终此。那么我们可以进一步看下CGroup中的cpuusage是如何计算的。这边笔者以我们常用的CFS(完全公平调度的代码实现为例):
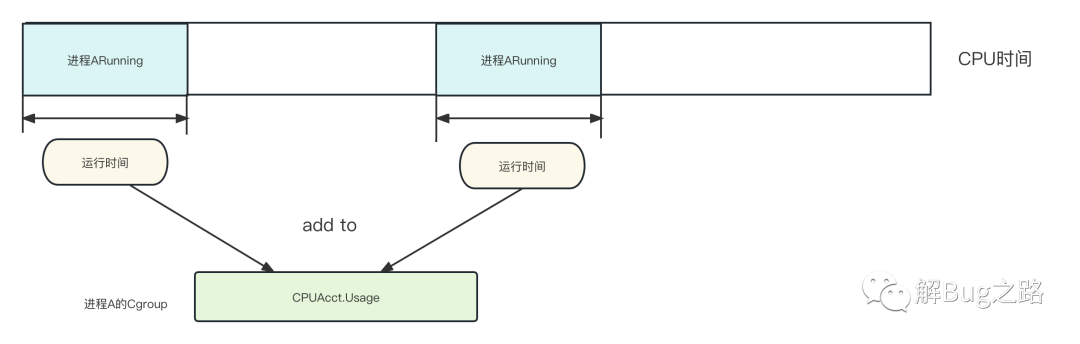
/* 相关的一条cpuusage代码路径如下 *.pick_next_task_fair |->put_prev_entity |->update_curr |->cgroup_account_cputime /* 其中还包含对当前cgroup的parentGroup的修正*/ |->cpuacct_chargevoid cpuacct_charge(struct task_struct *tsk, u64 cputime){ struct cpuacct *ca; int index = CPUACCT_STAT_SYSTEM; struct pt_regs *regs = task_pt_regs(tsk); /* 判断是system time还是user time */ if (regs && user_mode(regs)) index = CPUACCT_STAT_USER; rcu_read_lock(); /* 将相关的CPU运行时间入账 */ for (ca = task_ca(tsk); ca; ca = parent_ca(ca)) this_cpu_ptr(ca->cpuusage)->usages[index] += cputime; rcu_read_unlock();}复制由上面代码可知,kernel会在进程间切换的时候,将当前进程的运行时间记入到相关。那么就是这个cputime的计算了。
/* 一个cfs_rq可以是一个task进程,也可以是一个cgroup,代表的是完全公平调度runqueue中的一个元素 */static void update_curr(struct cfs_rq *cfs_rq){ /* 这个now=rq->clock_task,clock_task返回的rq->clock减去处理IRQs窃取的时间,其计算不在本文描述范围内 , 不考虑IRQ的话,可以认为等于此rq的总运行时间*/ u64 now = rq_clock_task(rq_of(cfs_rq)); /* 这个delta_exec表明了在这一次的运行中,此cfs_rq(进程orCgroup)实际运行了多长时间*/ delta_exec = now - curr->exec_start; curr->exec_start = now; ...... /* 将这一次进程在当前CFS调度下运行的时间更新如相关cgroup的usage */ cgroup_account_cputime(curtask, delta_exec); .....}复制好了,翻了一大堆代码,我们的cpuusage实际上就是这个cgroup在这一次CFS的kernel调度时间片中实际运行的时间。而我们的应用主要是一个Java进程,那么其基本就是这个Java进程运行了多长时间。值得注意的是,每个CPU的调度都会进行这样的计算。如下图所示:
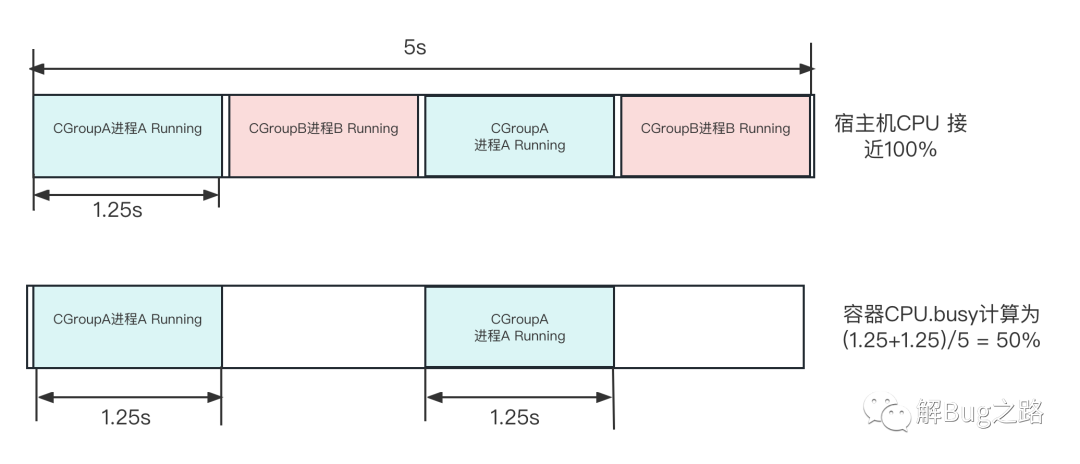
那么我们来看一下在超卖情况下的表现。如下图所示:
(图中1.25s只是为了绘图方便,实际调度时间切片非常小)
如果超卖了,而且进程都比较繁忙,那么每个CGroup肯定不能完全的占用宿主机的CPU。指定到某个CPU上就势必会有多个CGroup交替进行。而之前的容器CPU.Busy计算公式
CPU.busy = (cpuacct.usage(T秒) - cpuacct.usage(T-5秒))/((5秒)*CPU核数)复制反应的实际上是这个容器在这个CPU(核)上运行了多长时间。而完全不能反应CPU的繁忙程度。
如果不超卖,每个CGroup被均匀的分到各自的CPU上互不影响(当然如果cgroup绑核了那隔离性更好),那么这个计算公式才能够比较准确的反映CPU的情况。
在Kernel中这两个参数表示由于分配给Cgroup的cfs_quota_us时间片额度用完。进而导致被内核限制,限制的次数为nr_throttled,限制的总时间为throttled_time。
cat /sys/fs/cgroup/cpuacct/cpu.cfs_period_us 100000(100ms)cat /sys/fs/cgroup/cpuacct/cpu.cpu.cfs_quota_us 800000(800ms) 因为有8个核,所以分配了800mscat /sys/fs/cgroup/cpuset/cpuset.cpus 基本打散到所有的CPU上复制但这边和上面的推论有一个矛盾的点,如果由于CPU超卖而引起的问题的话。那么每个CGroup并不能分到800ms这样总的时间片。因为按照上面的推算,每个CGroup最多分到60% * 800=480ms的时间片。而这个时间片是不应该触发nr_throttled和throttled_time的!
就在笔者对着Kernel源码百思不得其解之际,笔者发现Linux Kernel在5.4版本有个优化
https://lwn.net/Articles/792268/sched/fair: Fix low cpu usage with high throttling by removing expiration of cpu-local slices复制也就是说在5.4版本之前,在一些场景下low cpu usage依旧能导致cgroup被throttled。而这个场景即是:
that highly-threaded, non-cpu-bound applicationsrunning under cpu.cfs_quota_us constraints can hit a high percentage ofperiods throttled高度线程化,非CPU密集的应用程序在CPU.cfs_quota_us约束下运行时,可能会有很高的周期被限制,同时不会消耗分配的配额。复制出故障的应用使用了大量的线程去处理请求,同时也有大量的IO操作(操作分布式缓存),符合此Bug的描述。
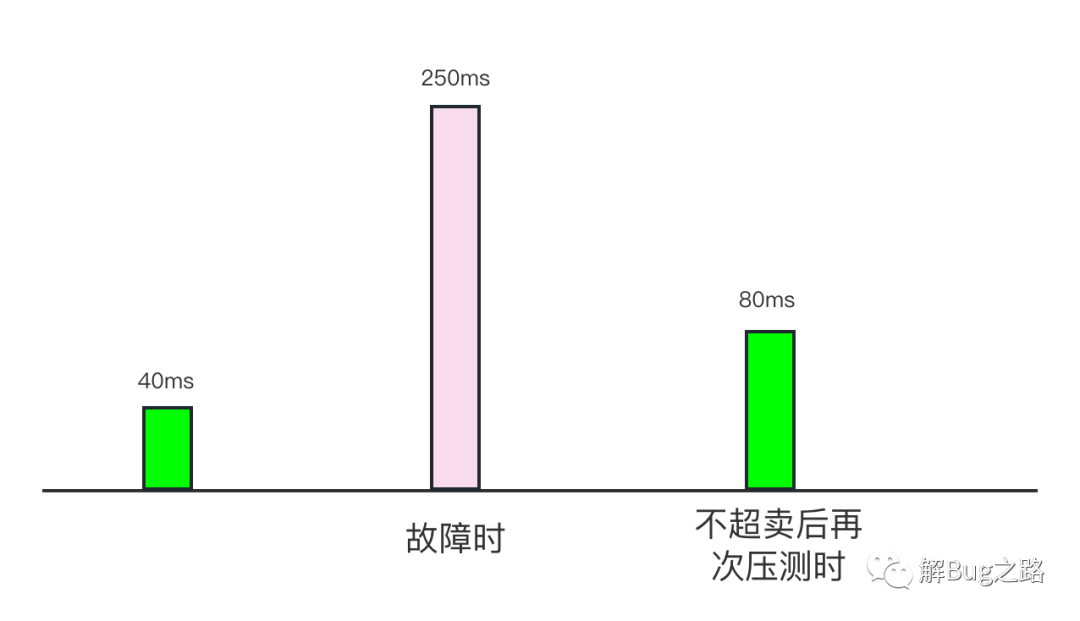
这个疑问当然靠对比来解决,我们在故障之后,做了一次压测(CPU.Busy > 60%),这次应用是不超卖的。这次delta_nr_throttled和delta_throttled_time依旧存在,不过比故障时的数量少了一个数量级。
同时999线从故障时候的暴涨6倍变成了只增长1倍。
很明显的,宿主机超卖是主因!而且宿主机超卖后的宿主机CPU负载过高还加重了这个Bug的触发。
线上的Cgroup(容器)的核数分配实际上是按照(核数=cfs_quota_us/cfs_period_us)这个模型去分配的,同时并不会在cpuset进行绑核。也就是说一个48核的容器,应用的各个线程可以跑在任何一个核上,只不过只分配了8核的时间片额度。这就利用了Cgroup的带宽控制机制CFS_BANDWITH。
很明显的改进措施可以是下面几种:
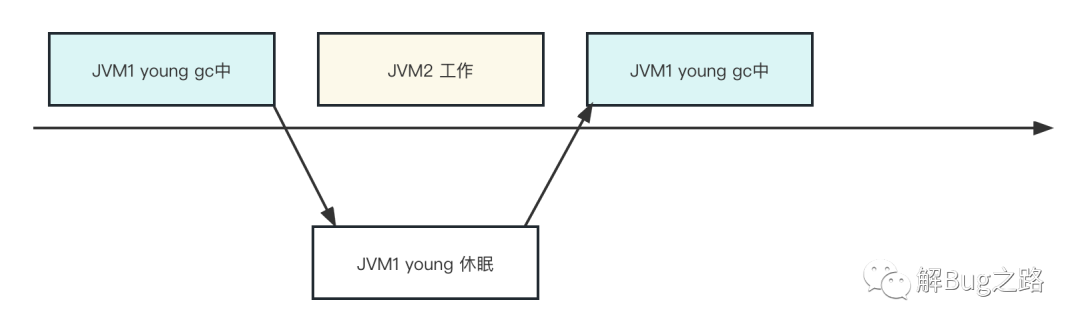
针对超卖: 1) 宿主机不超卖,但不是一个好的选择,因为资源利用率上不去,存在大量CPU利用率很低的应用 2) 根据应用的CPU利用率情况进行高低错配放到宿主机上,在利用资源利用率的同时又不至于互相影响针对内核的Bug 1) 可以打Patch或者升级到5.4复制回过头来看看young gc为什么会慢就很明显了。因为在young gc时候,被shedule出去了,而且没有其它的空闲CPU让jvm可以schedule回来,白白浪费了很长时间。
因为object copy在这个应用的young gc中是最耗费CPU以及时间的操作,所以自然在object copy阶段出现变慢的现象。
当然,进程schedule可以处在各种时间点,所以并不仅仅是Young GC变慢了,在请求处理阶段也可能变慢。
指标虽然能够比较准确且客观的反映两个时间点的变化。但指标的定义和对指标的解读确实比较主观的,没有理解清楚指标所能表达的极限以及使用场景。往往会让我们排查问题进入误区!