单链表是一种链式存取的数据结构,用一组地址任意的存储单元存放线性表中的数据元素。链表中的数据是以结点来表示的,每个结点的构成:元素(数据元素的映象) +指针(指示后继元素存储位置,元素就是存储数据的存储单元,指针就是连接每个结点的地址数据。)
以上是标准定义不太好让人对单链表有直观的感受,下面我们通过对单链表的构成以及存储数据的方式说明,来更加深刻的理解一下什么是单链表。
链表存储数据的方式:
链表是以节点的方式来存储数据的
每个数据节点包含data域,next域:指向下一个数据节点
链表的各个节点在实际存储结构上不一定是连续的
列表分带头节点的链表和不带头节点的链表,根据实际需求来确定使用哪种链表(本文以单链表进行举例说明)
链表的实际结构图示:
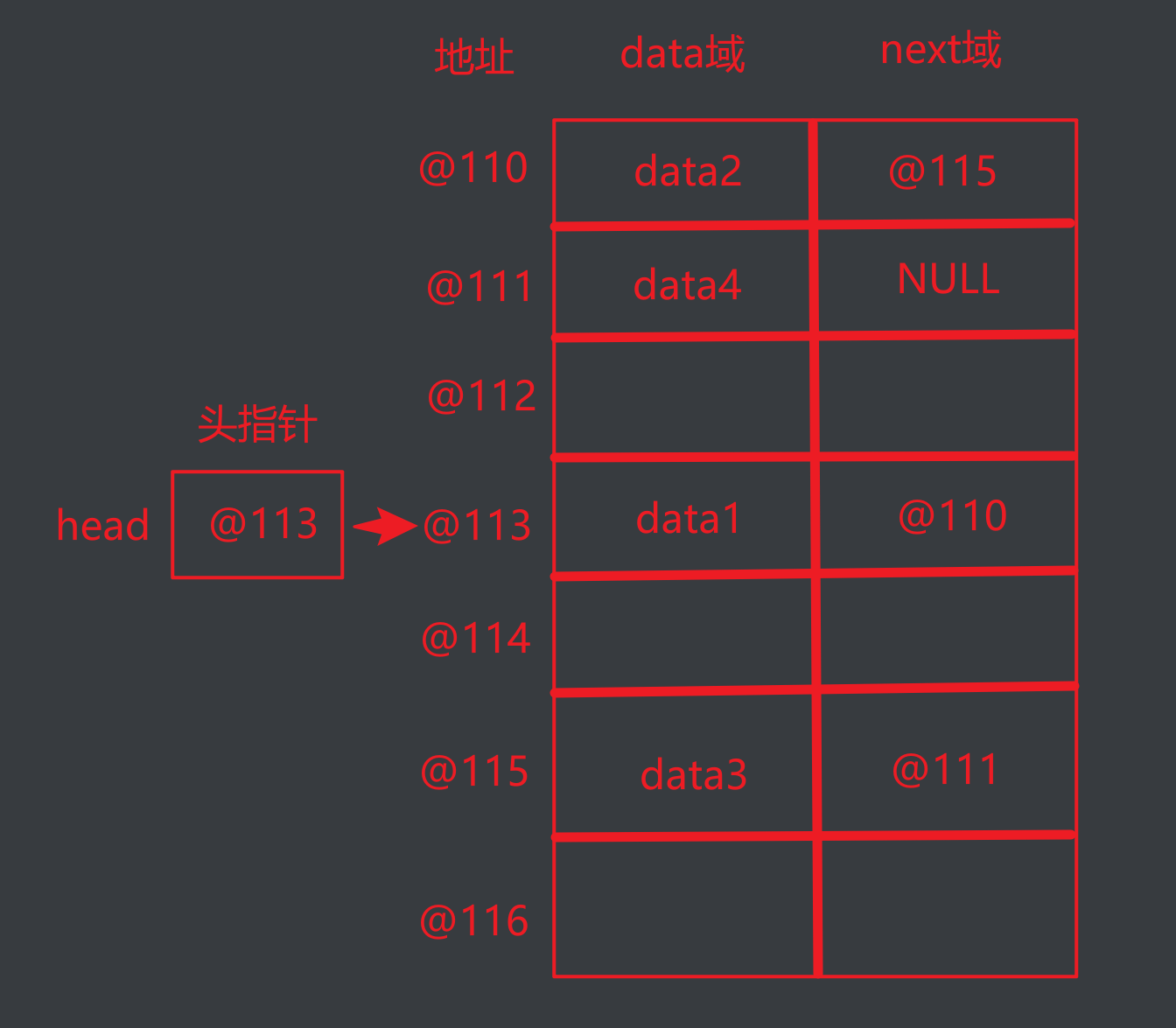 链表的逻辑结构图示:
链表的逻辑结构图示:
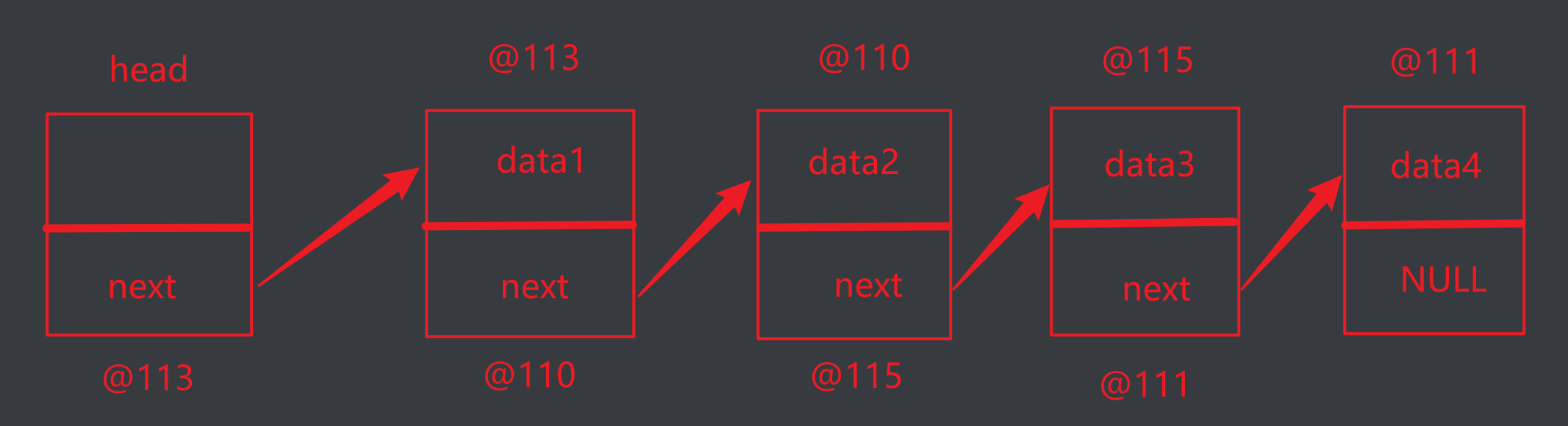
// 定义数据节点类
class DataNode {
private String data; // data域,要存储的数据
private DataNode next; // next域,用于指向下一个数据节点地址
// 数据节点构造器
public DataNode(String data) {
this.data = data;
}
@Override
public String toString() {
return "DataNode{" +
"data='" + data + '\'' +
'}';
}
public String getData() {
return data;
}
public void setData(String data) {
this.data = data;
}
public DataNode getNext() {
return next;
}
public void setNext(DataNode next) {
this.next = next;
}
}
复制/**
* ClassName: SingleLinkedList
* Package: com.zhao.test
* Description: 定义单向链表类
*
* @Author XH-zhao
* @Create 2023/3/26 11:09
* @Version 1.0
*/
public class SingleLinkedList {
// 先初始化一个头节点,头节点不用于存储数据,只用于指向单链表的首元素
private DataNode head = new DataNode("");
/**
* 向单链表中增加数据节点
*
* @param dataNode 待增加的数据节点
*/
public void addDataNode(DataNode dataNode) {
// 由于head节点不能更改,只用于指向单链表的首元素,所以我们需要一个辅助变量接收head的引用
DataNode temp = head;
// 找到链表的最后,即结束
while (temp.getNext() != null) {
// 如果没有找到,就把下一个数据节点的引用赋值给temp,使temp指向下一个数据节点
temp = temp.getNext();
}
// 将找到的最后一个一个数据节点的next域指向新加入的节点地址
temp.setNext(dataNode);
}
/**
* 显示链表的信息
*/
public void showList() {
// 判断链表是否为空
if (head.getNext() == null){
System.out.println("链表为空");
return;
}
// 由于head节点不能更改,只用于指向单链表的首元素,所以我们需要一个辅助变量接收head的引用
DataNode temp = head.getNext();
// 遍历链表并打印链表中的数据节点
while (temp != null) {
System.out.println(temp);
temp = temp.getNext();
}
}
}
复制/**
* ClassName: SingleLinkedList
* Package: com.zhao.test
* Description: 定义单向链表类
*
* @Author XH-zhao
* @Create 2023/3/26 11:09
* @Version 1.0
*/
public class SingleLinkedList {
// 先初始化一个头节点,头节点不用于存储数据,只用于指向单链表的首元素
private DataNode head = new DataNode("");
/**
* 向单链表中增加数据节点
*
* @param dataNode 待增加的数据节点
*/
public void addDataNode(DataNode dataNode) {
// 由于head节点不能更改,只用于指向单链表的首元素,所以我们需要一个辅助变量接收head的引用
DataNode temp = head;
// 找到链表的最后,即结束
while (temp.getNext() != null) {
// 如果没有找到,就把下一个数据节点的引用赋值给temp,使temp指向下一个数据节点
temp = temp.getNext();
}
// 将找到的最后一个一个数据节点的next域指向新加入的节点地址
temp.setNext(dataNode);
}
/**
* 显示链表的信息
*/
public void showList() {
// 判断链表是否为空
if (head.getNext() == null){
System.out.println("链表为空");
return;
}
// 由于head节点不能更改,只用于指向单链表的首元素,所以我们需要一个辅助变量接收head的引用
DataNode temp = head.getNext();
// 遍历链表并打印链表中的数据节点
while (temp != null) {
System.out.println(temp);
temp = temp.getNext();
}
}
}
// 定义数据节点类
class DataNode {
private String data; // data域,要存储的数据
private DataNode next; // next域,用于指向下一个数据节点地址
// 数据节点构造器
public DataNode(String data) {
this.data = data;
}
@Override
public String toString() {
return "DataNode{" +
"data='" + data + '\'' +
'}';
}
public String getData() {
return data;
}
public void setData(String data) {
this.data = data;
}
public DataNode getNext() {
return next;
}
public void setNext(DataNode next) {
this.next = next;
}
}
// 单链表测试类
class SingleLinkedListTest{
public static void main(String[] args) {
// 创建四个数据节点
DataNode dataNode1 = new DataNode("data1");
DataNode dataNode2 = new DataNode("data2");
DataNode dataNode3 = new DataNode("data3");
DataNode dataNode4 = new DataNode("data4");
// 创建单链表对象
SingleLinkedList linkedList1 = new SingleLinkedList();
// 将数据节点依次加入链表中
linkedList1.addDataNode(dataNode1);
linkedList1.addDataNode(dataNode2);
linkedList1.addDataNode(dataNode3);
linkedList1.addDataNode(dataNode4);
// 展示链表内所有数据节点
linkedList1.showList();
}
}
复制DataNode{data='data1'}
DataNode{data='data2'}
DataNode{data='data3'}
DataNode{data='data4'}
进程已结束,退出代码0
复制从上述结果中,我们就实现了带头节点的单链表的数据存储设计。
在上述的实验测试中我们已经完成了单链表存储数据的基本思想。可以让数据节点根据添加顺序依次添加到单链表当中。到这里我们仅仅实现了如何使用单链表的方式存储数据元素。那么如果我们想让数据节点在存储时,实现一些我们想要的特殊功能(例如在添加数据节点的同时,按照数据节点中的某一个属性进行排序加入),我们又该如何实现呢?
这里我们更改一下我们的测试程序,我们将数据节点以4-1-2-3顺序加入链表中,希望呈现出来还是以1-2-3-4排序好的效果。
public static void main(String[] args) {
// 创建四个数据节点
DataNode dataNode1 = new DataNode("data1");
DataNode dataNode2 = new DataNode("data2");
DataNode dataNode3 = new DataNode("data3");
DataNode dataNode4 = new DataNode("data4");
// 创建单链表对象
SingleLinkedList linkedList1 = new SingleLinkedList();
// 将数据节点以4-1-2-3顺序加入链表中
linkedList1.addDataNode(dataNode4);
linkedList1.addDataNode(dataNode1);
linkedList1.addDataNode(dataNode2);
linkedList1.addDataNode(dataNode3);
// 展示链表内所有数据节点
linkedList1.showList();
}
复制DataNode{data='data4'}
DataNode{data='data1'}
DataNode{data='data2'}
DataNode{data='data3'}
进程已结束,退出代码0
复制很显然,我们的代码只能按照节点加入顺序来加入节点。后续我们将在《JAVA实现节点加入到单链表时按需求排序》一文中实现上述我们想要的效果!
如果上述实验中我们按照如下方式去测试代码
public static void main(String[] args) {
// 创建四个数据节点
DataNode dataNode1 = new DataNode("data1");
DataNode dataNode2 = new DataNode("data2");
DataNode dataNode3 = new DataNode("data3");
DataNode dataNode4 = new DataNode("data4");
// 创建单链表对象
SingleLinkedList linkedList1 = new SingleLinkedList();
// 将数据节点依次加入链表中
linkedList1.addDataNode(dataNode1);
linkedList1.addDataNode(dataNode2);
linkedList1.addDataNode(dataNode3);
linkedList1.addDataNode(dataNode4);
// 展示链表内所有数据节点
linkedList1.showList();
// 创建链表2
SingleLinkedList linkedList2 = new SingleLinkedList();
// 将数据节点打乱顺序加入到链表2中
linkedList2.addDataNode(dataNode1);
linkedList2.addDataNode(dataNode4);
linkedList2.addDataNode(dataNode3);
linkedList2.addDataNode(dataNode2);
// 展示链表2内所有数据节点
linkedList2.showList();
}
复制运行结果:
DataNode{data='data1'}
DataNode{data='data2'}
DataNode{data='data3'}
DataNode{data='data4'}
// 程序堵塞在这里,无法向下进行!
复制请思考造成上述问题的原因所在?