在上文《带头节点的单链表的思路及代码实现(JAVA)》中我们想要去实现让数据节点不考虑加入顺序实现数据节点排序效果。
那么我们要如何实现这一需求呢?
假设我们要根据数据节点的ID进行排序,那么我们可以通过使用待增加的节点id逐一遍历链表节点,直到找到要插入位置的前一个节点,将要插入位置的后一个节点的引用赋值给待插入节点的next域,然后再将待插入节点的引用赋值给待插入节点前一个位置的next域,这样就实现了链表数据节点的顺序加入。
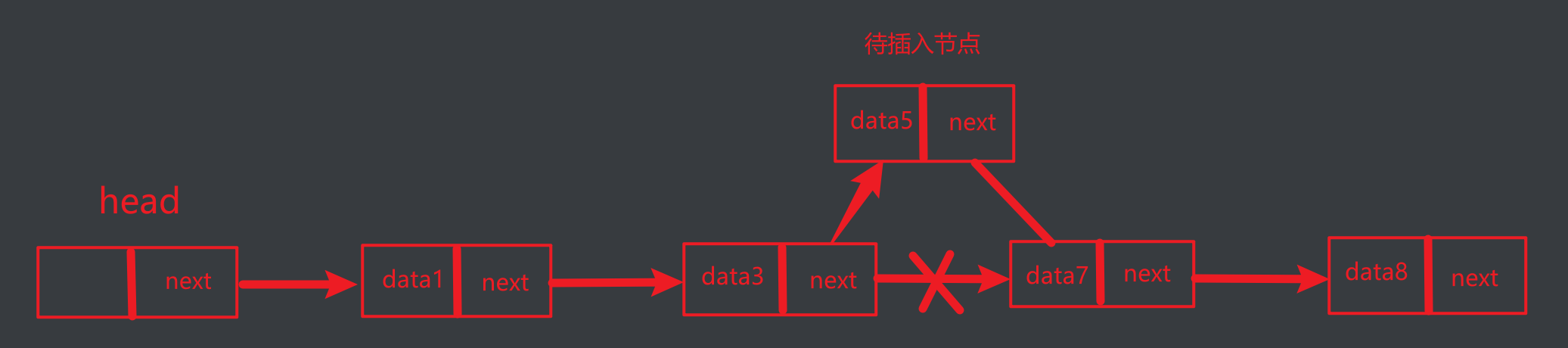
这里为了展示排序效果,数据节点类较上次增添了id属性,用于实现根据id排序。
// 带ID的数据节点类
class IdDataNode{
private int id; // 用来作为排序依据,即实现以id进行排序的单链表
private String data; // data域,要存储的数据
private IdDataNode next; // next域,用于指向下一个数据节点地址
// 数据节点构造器
public IdDataNode(int id, String data) {
this.id = id;
this.data = data;
}
@Override
public String toString() {
return "IdDataNode{" +
"id=" + id +
", data='" + data + '\'' +
'}';
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getData() {
return data;
}
public void setData(String data) {
this.data = data;
}
public IdDataNode getNext() {
return next;
}
public void setNext(IdDataNode next) {
this.next = next;
}
}
复制方法实现思路均已在代码注释中说明。
/**
* ClassName: SingleLinkedListAddOrder
* Package: com.zhao.test
* Description:
*
* @Author XH-zhao
* @Create 2023/3/27 13:31
* @Version 1.0
*/
public class SingleLinkedListAddOrder {
// 创建单链表头节点
private IdDataNode head = new IdDataNode(0,"");
// 将数据节点按照数据id添加进链表
public void addByIdOrder(IdDataNode idDataNode){
// 使用辅助变量temp代替head进行移动
IdDataNode temp = head;
while(true){
// 说明temp走到了最后,必须要添加元素了(添加到最后)
if(temp.getNext() == null){
break;
}
// temp节点的后一个节点的id比要添加节点的id大代表可以添加元素了
if(temp.getNext().getId() > idDataNode.getId()){
break;
}else if(temp.getNext().getId() == idDataNode.getId()){
System.out.println("您添加的元素已经存在了!!");
// 直接结束方法
return;
}
// 将temp元素后移(继续遍历)
temp = temp.getNext();
}
// 当遍历结束时,temp已经指向了要插入的位置的前一个节点(开始插入)
idDataNode.setNext(temp.getNext());
temp.setNext(idDataNode);
}
// 遍历整个链表
public void showLinkedListAll() {
// 当链表为空时不进行遍历,直接结束
if(head.getNext() == null) {
System.out.println("链表为空");
return;
}
// 遍历链表时同样需要辅助变量,因为head节点不能移动,否则就找不到该链表了
IdDataNode temp = head;
while(true) {
// 当链表为空时,不进行遍历,直接结束循环
if(temp.getNext() == null) {
break;
}
// 直接输出链表节点存的数据
System.out.println(temp.getNext());
//将temp指针往后移动
temp = temp.getNext();
}
}
}
复制/**
* ClassName: SingleLinkedListAddOrder
* Package: com.zhao.test
* Description:
*
* @Author XH-zhao
* @Create 2023/3/27 13:31
* @Version 1.0
*/
public class SingleLinkedListAddOrder {
// 创建单链表头节点
private IdDataNode head = new IdDataNode(0,"");
// 将数据节点按照数据id添加进链表
public void addByIdOrder(IdDataNode idDataNode){
// 使用辅助变量temp代替head进行移动
IdDataNode temp = head;
while(true){
// 说明temp走到了最后,必须要添加元素了(添加到最后)
if(temp.getNext() == null){
break;
}
// temp节点的后一个节点的id比要添加节点的id大代表可以添加元素了
if(temp.getNext().getId() > idDataNode.getId()){
break;
}else if(temp.getNext().getId() == idDataNode.getId()){
System.out.println("您添加的元素已经存在了!!");
// 直接结束方法
return;
}
// 将temp元素后移(继续遍历)
temp = temp.getNext();
}
// 当遍历结束时,temp已经指向了要插入的位置的前一个节点(开始插入)
idDataNode.setNext(temp.getNext());
temp.setNext(idDataNode);
}
// 遍历整个链表
public void showLinkedListAll() {
// 当链表为空时不进行遍历,直接结束
if(head.getNext() == null) {
System.out.println("链表为空");
return;
}
// 遍历链表时同样需要辅助变量,因为head节点不能移动,否则就找不到该链表了
IdDataNode temp = head;
while(true) {
// 当链表为空时,不进行遍历,直接结束循环
if(temp.getNext() == null) {
break;
}
// 直接输出链表节点存的数据
System.out.println(temp.getNext());
//将temp指针往后移动
temp = temp.getNext();
}
}
}
// 带ID的数据节点类
class IdDataNode{
private int id; // 用来作为排序依据,即实现以id进行排序的单链表
private String data; // data域,要存储的数据
private IdDataNode next; // next域,用于指向下一个数据节点地址
// 数据节点构造器
public IdDataNode(int id, String data) {
this.id = id;
this.data = data;
}
@Override
public String toString() {
return "IdDataNode{" +
"id=" + id +
", data='" + data + '\'' +
'}';
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getData() {
return data;
}
public void setData(String data) {
this.data = data;
}
public IdDataNode getNext() {
return next;
}
public void setNext(IdDataNode next) {
this.next = next;
}
}
// 测试类
class SingleLinkedListAddOrderTest{
public static void main(String[] args) {
// 创建四个数据节点,id分别是1-2-3-4
IdDataNode dataNode1 = new IdDataNode(1, "data1");
IdDataNode dataNode2 = new IdDataNode(2, "data2");
IdDataNode dataNode3 = new IdDataNode(3, "data3");
IdDataNode dataNode4 = new IdDataNode(4, "data4");
// 创建带头节点的单链表
SingleLinkedListAddOrder singleLinkedListAddOrder = new SingleLinkedListAddOrder();
// 将四个数据节点以id为4-1-3-2的顺序加入到链表
singleLinkedListAddOrder.addByIdOrder(dataNode4);
singleLinkedListAddOrder.addByIdOrder(dataNode1);
singleLinkedListAddOrder.addByIdOrder(dataNode3);
singleLinkedListAddOrder.addByIdOrder(dataNode2);
// 显示链表中元素,查看是否实现排序效果
singleLinkedListAddOrder.showLinkedListAll();
System.out.println("*******************************");
// 增加一个重复数据节点,查看输出结果
singleLinkedListAddOrder.addByIdOrder(dataNode2);
}
}
复制IdDataNode{id=1, data='data1'}
IdDataNode{id=2, data='data2'}
IdDataNode{id=3, data='data3'}
IdDataNode{id=4, data='data4'}
*******************************
您添加的元素已经存在了!!
进程已结束,退出代码0
复制从上述结果中,我们就实现了带头节点的单链表通过id排序的数据存储设计。