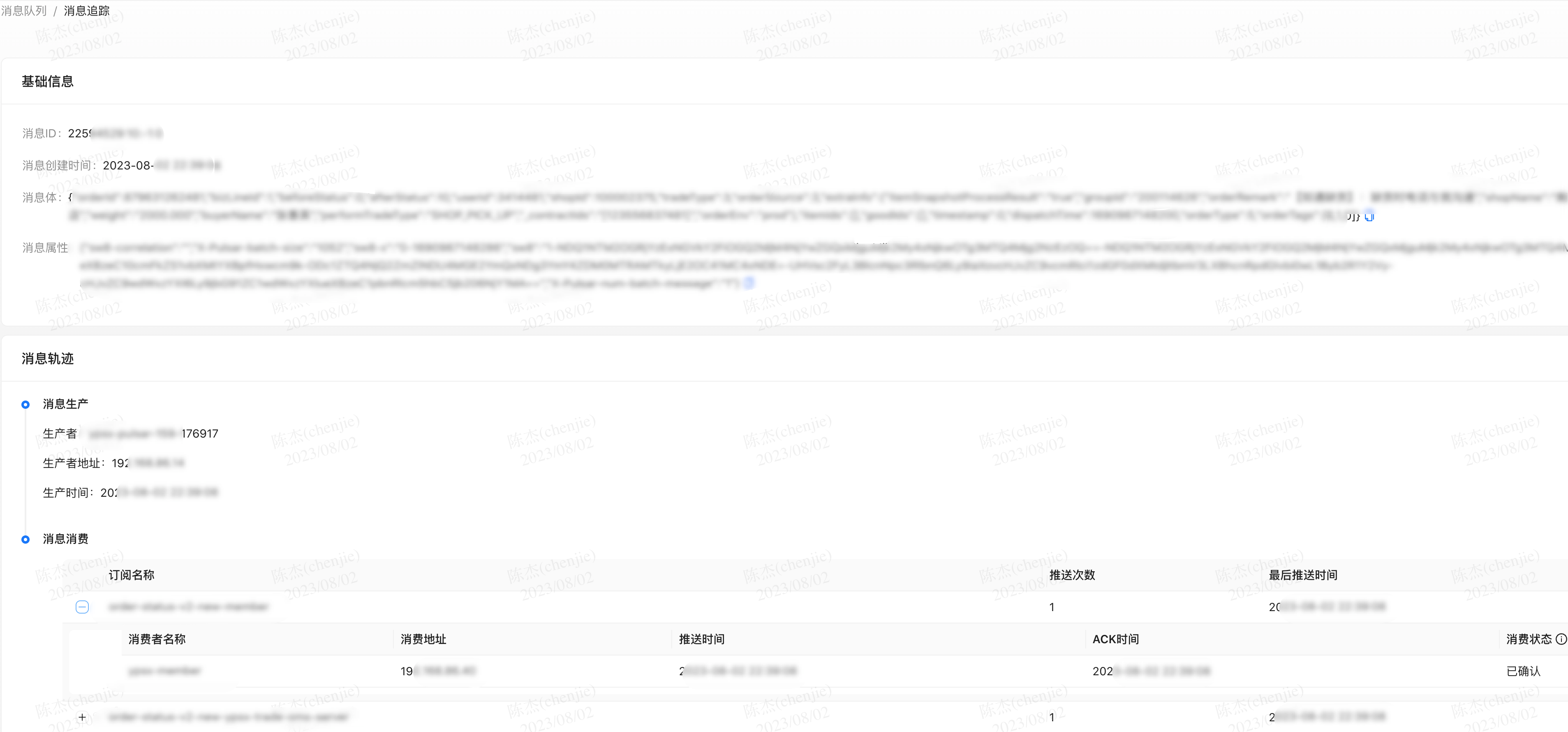
为了让业务团队可以更好的跟踪自己消息的生产和消费状态,需要一个类似于表格视图的消息列表,用户可以直观的看到发送的消息;同时点击详情后也能查到消息的整个轨迹。
消息列表
点击详情后查看轨迹
由于 Pulsar 并没有关系型数据库中表的概念,所有的数据都是存储在 Bookkeeper 中,为了模拟使用 SQL 查询的效果 Pulsar 提供了 Presto (现在已经更名为 Trino)的插件。
Trino 是一个分布式的 SQL 查询引擎,它也提供了插件能力,如果我们想通过 SQL 从自定义数据源查询数据时,基于它的 SPI 编写一个插件是很方便的。
这样便可以类似于查询数据库一样查询 Pulsar 数据:

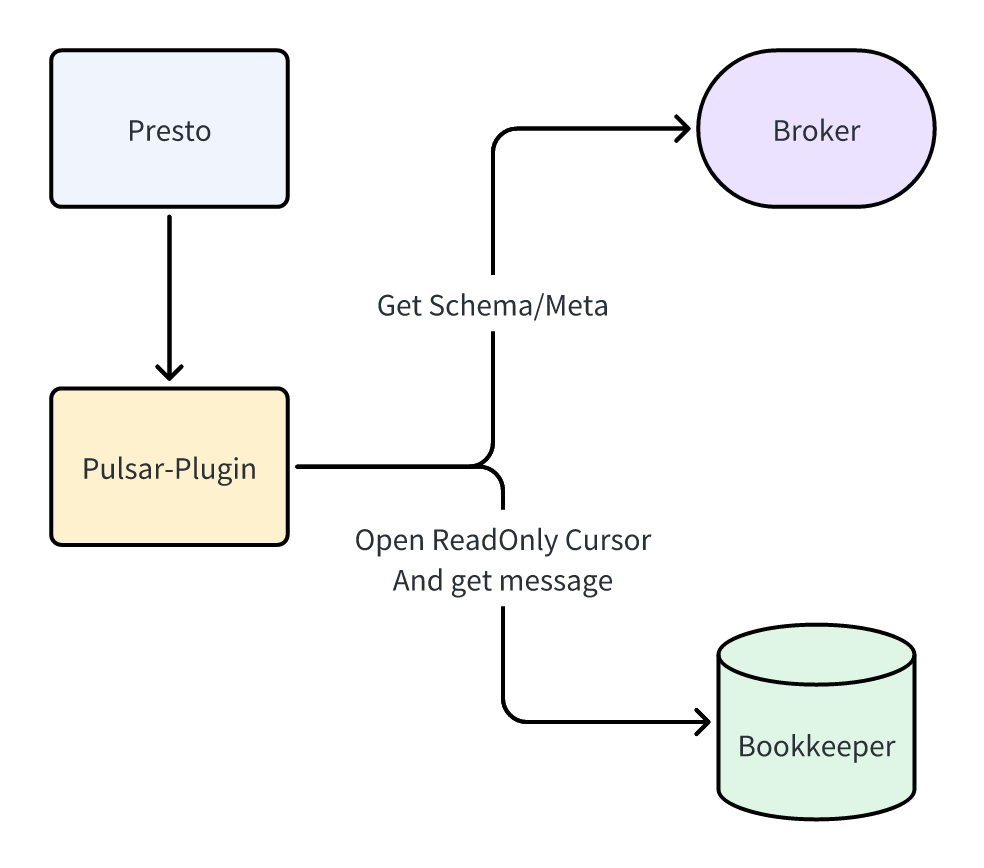
Pulsar 插件的运行流程如上图所示:
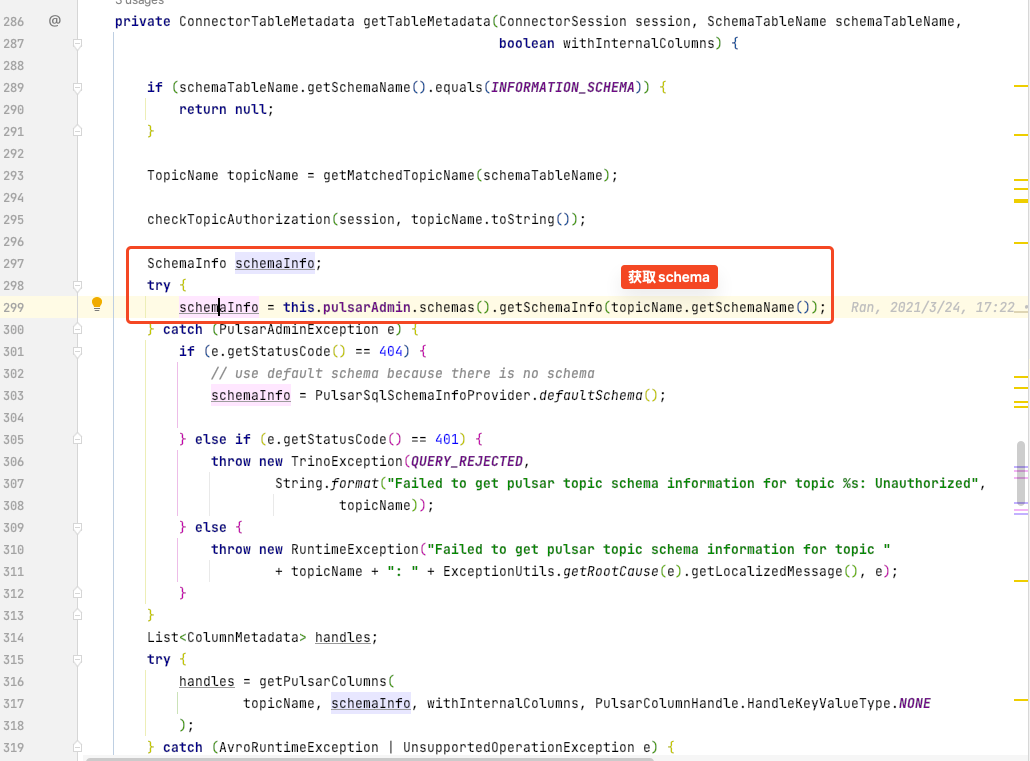
Pulsar-Admin 接口获取一些元数据,比如 Scheme,topic 分区信息等。相关代码:

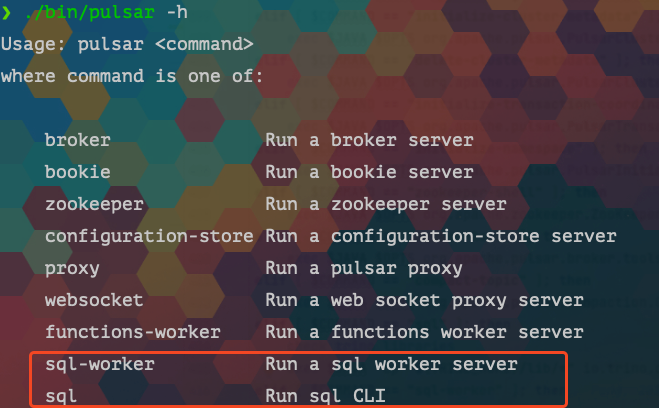
使用起来也很简单,官方提供了两个命令:
自己在本地运行的时候自然是没问题,可是一旦想在生产运行,同时如果你的 Pulsar 集群是运行再 k8s 环境中时就会碰到一些问题。
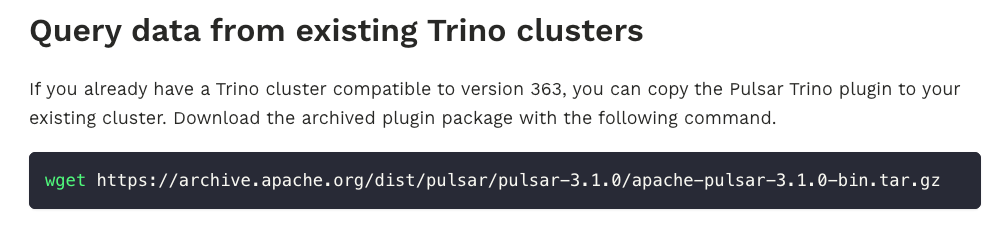
首先第一个问题是如果生产环境已经有了一个 Trino 集群想要复用的时候就会碰到问题,常规流程是将 Pulsar 的插件复制到 Trino 的 Plugin 目录,然后重启 Trino 后就能使用该插件。
当然社区也是支持这么做的:
但是当我将 Pulsar-plugin 复制到 Trino 中运行的时候却失败了,整体的流程可以参考这个 issue:
https://github.com/apache/pulsar/discussions/20941
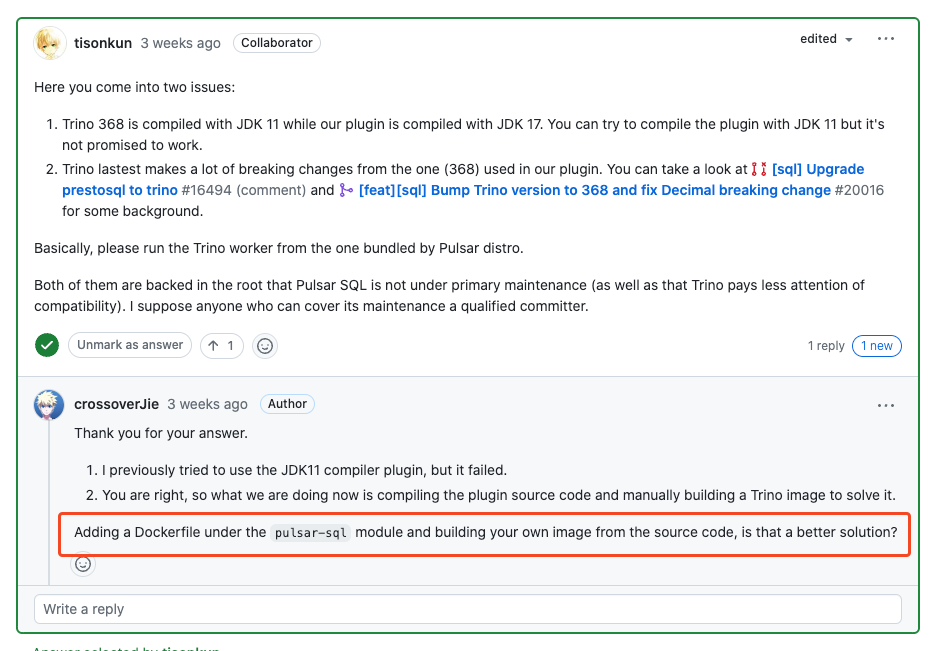
简单来说 Trino 的官方镜像和 pulsar-plugin 并不能兼容,这个问题直接影响到我们是否可以在生产环境使用它。
但是手动编译出来的 Trino 服务和插件是兼容的,可以直接运行。
因此我只能在本地编译出 Trino 服务端和 pulsar-plugin 然后打包成一个镜像来运行了,当然这样的坏处就是无法利用到我们现有的 Trino 集群,又得重新部署一个了。
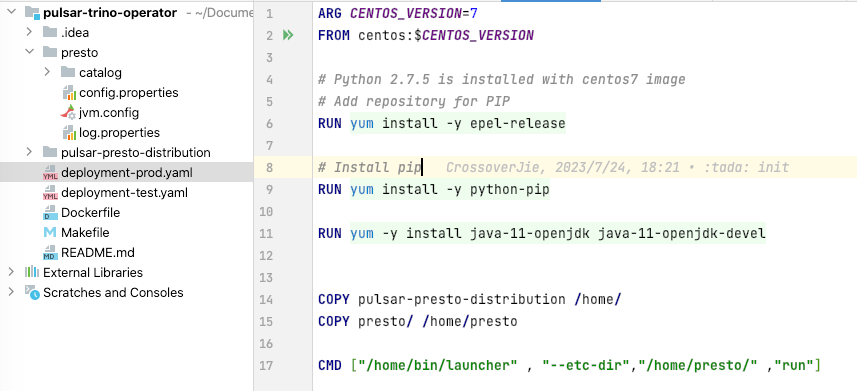
流程也比较麻烦:
Pulsar-SQL 模块make docker 打出 docker 镜像并上传到私服kubectl 将 trino 部署到 k8s 环境中整个流程做下来加上和社区的沟通,更加确定这个功能应该是很少有人在生产环境使用的,毕竟第一个坑就很麻烦,更别提后续的问题了😂。
第二个问题也是个深坑,当我把 Trino 部署好查询数据的时候直接抛了一个调用 pulsar-admin 接口连接超时的异常。
结果排查了半天发现原来是 pulsar-plugin 里没有提供 JWT 的验证方式,而我们的 Pulsar 集群恰好是打开了 JWT 验证的。
为此我只能先在本地修复了这个问题,同时也提交了 PR,预计会在下一个大版本合并吧:
https://github.com/apache/pulsar/pull/20860
第二个问题是当查询一个新创建的 topic 时,客户端会直接 block,相关的复现流程在这里:
https://github.com/apache/pulsar/issues/20910
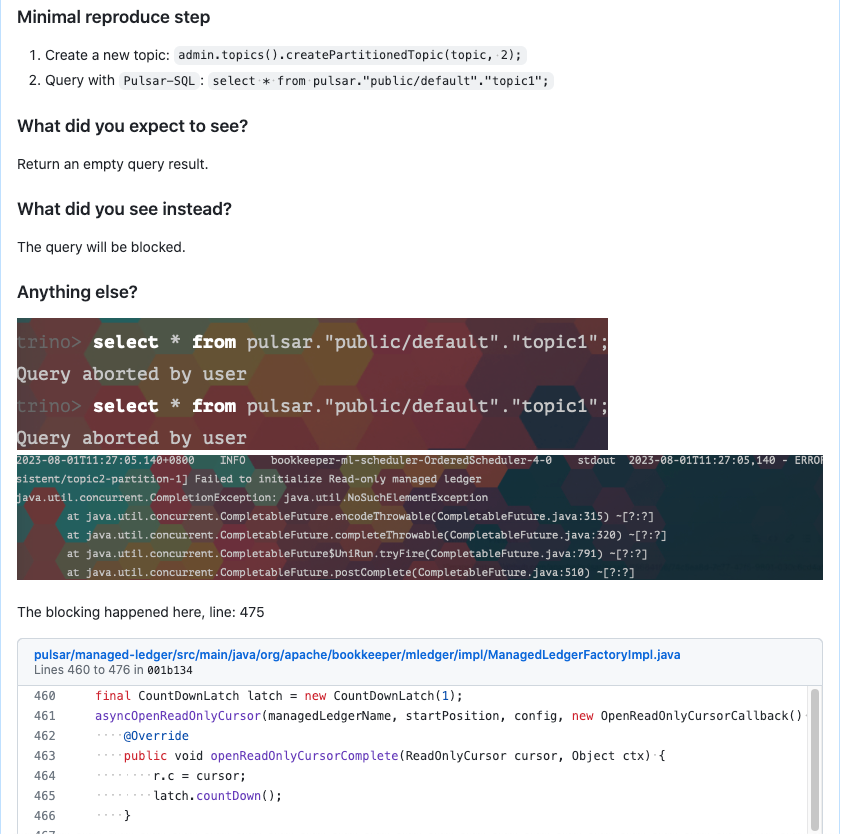
这个问题还好,不是很致命,是我在本地测试的时候无意间发现的。
本地我已经修复了,后面也提交了一个 PR,目前还在讨论中:
https://github.com/apache/pulsar/pull/20911
这个问题也不是很严重,数据量少的时候会发现,就是在指定了消息发送时间的查询条件时,最后一条消息会被过滤掉,相关 issue 在这里:
https://github.com/apache/pulsar/issues/20919
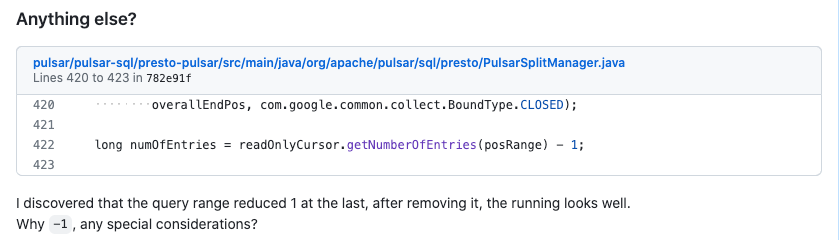
这个我只是定位到了原因,但不太清楚 为什么要这么做(-1),影响也不是很大,就放在这里搁置了。
最后发现的一个问题是我们线上某些 topic 查询数据的时候会抛出 Not a record: "string"的异常,但只是部分 topic,也排查了很久,整个源码中没有任何一个地方有这个异常。
https://github.com/apache/pulsar/issues/20945
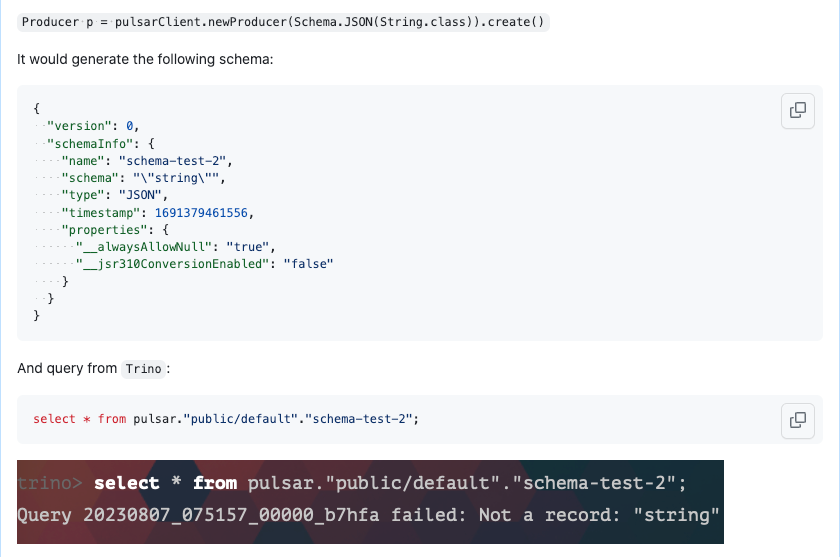
根本原因是生产者生成的 schema 有问题,类型已经是 JSON 了,但是 schema 却是 string,这样导致 pulsar-plugin 在反序列化 schema 的时候抛出了异常,由于是 pb 反序列化抛出的异常,所以源码中都搜索不到。
没有问题的 topic 使用了正确的 schema
后续我也在本地修复了这个问题,当抛出异常后就将 schema 降级为基本类型进行解析。
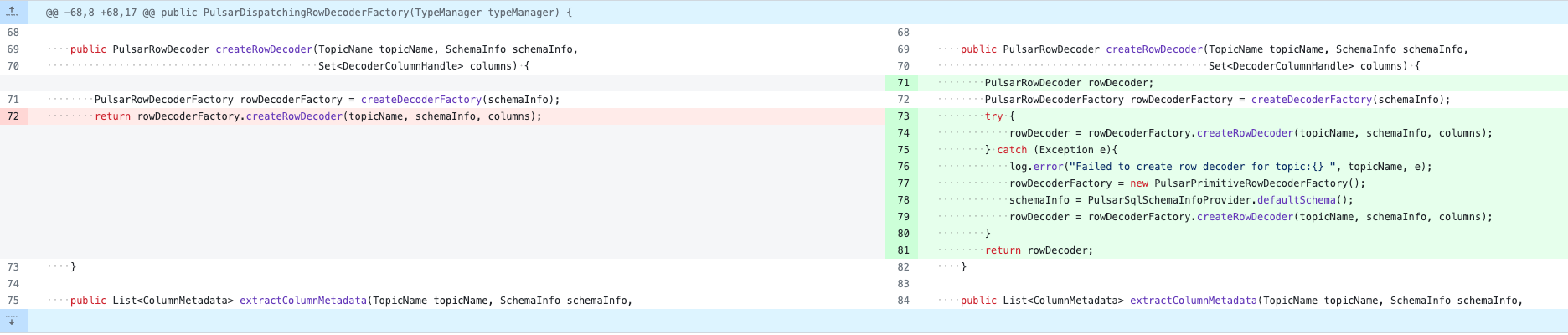
不过本质问题还是客户端使用有误,如果对 schema 理解不准确的话还是建议使用 byte[] 吧,这样至少兼容性不会有问题。
相关 PR:
https://github.com/apache/pulsar/pull/20955
Pulsar-SQL 是一个非常有用的功能,只是我们使用过程中确实发现了一些问题,大部分都已经修复了;
希望对后续使用该功能的朋友有所帮助。