随着 ChatGPT 的问世,人工智能(AI)新时代也正式开启。ChatGPT 是一种语言模型。它与用户进行对话交互,以便用户输入问题或提示,模型响应,然后对话可以继续来回进行,类似于在消息传递应用程序上向实际人员发送消息的方式。随着对 AI 的需求不断增长,为 AI 模型提供信息的能力也变得同样重要。这就是提示工程(Prompt Engineering)的用武之地,通过给 AI 模型提供正确的“提示”来满足业务需求。
在本文中,我们将一同探讨提示工程的概念、基本要素,以及提示工程面临的挑战与未来趋势。
提示工程是为 AI 语言模型设计有效输入的过程,以获得所需的输出。提示工程包括了解模型的能力和局限性,以及用户的目标和期望。提示工程对于探索和释放AI语言模型的全部潜力至关重要,让 AI 语言模型可以顺利执行文本生成、摘要、问题解答、代码生成等多种任务。当然,这些模型需要需要根据明确而具体的指令才能产生准确、相关和有用的结果。
一般来说,提示工程由两个主要目标:
提示工程的首要目标是设计基于文本的输入,可以更有效地指导 AI 模型。提示工程师为模型提供各种输入,然后评估输出结果。如果输出未达到预期的精度水平,提示工程师与开发人员则会进行合作对模型进行微调。例如,可能要求模型不得使用任何攻击性语气或避免表达任何政治观点,并且还必须防范例如提示注入(Prompt injection)之类的安全威胁。
在第二种情况下,根据企业所在的行业编写不同的文本输入,以提供优化结果,同时满足领域要求。例如,在医疗保健行业, AI 模型不泄露任何个人或机密信息至关重要。另一个例子是开发有效的提示,以充分利用模型,同时利用最少数量的 token 来最大限度地降低使用 AI 模型的成本。
有效的提示工程需要深入了解大型语言模型(LLM)的功能和限制,以构建优秀的输入提示的能力。同时,提示工程通常涉及仔细选择提示中包含的单词、短语以及输入的整体结构,以实现获得准确回复的目的。即使对提示进行微小的修改也会对结果产生重大影响,因此提示工程的系统方法至关重要。
LLM 是一种 AI 模型,经过大量文本数据的训练,可以对自然语言输入创建类似人类的回复。LLM 以其撰写高质量、连贯的写作能力而著称,这些写作通常与人类的写作没有什么太大区别。这种尖端性能是通过在大型文本语料库(通常有数十亿个单词)上训练 LLM 来实现的,使其能够掌握人类语言的复杂性。
以下是与提示工程和 LLM 相关的几个关键术语,从 LLM 中使用的主要算法开始:
Word embedding(词嵌入)是 LLM 中使用的一种基本方法,因为它用于以数字方式表示单词的含义,随后可由 AI 模型进行分析。
Attention mechanisms(注意力机制) 是一种 LLM 算法,能够结合上下文,让 AI 在创建输出时专注于输入文本的某些元素,例如与情感相关的短语。
Transformer 是 LLM 研究中常见的一种神经网络设计,通过自注意力技术处理输入数据。
Fine-tuning(微调)是通过在较小的相关数据集上进行训练来使 LLM 适应给定工作或主题的过程。
Prompt engineering(提示工程)是对 LLM 输入提示的专家设计,以提供高质量、连贯的输出。
Interpretability(可解释性)是指理解和解释 AI 系统的输出和决策的能力,由于其复杂性,这通常是 LLM 的一个挑战和持续的研究领域。
说明:提示的主要目的是为语言模型提供清晰的说明。
上下文:上下文提供额外的信息来帮助语言模型产生更相关的输出。该信息可以来自外部来源或由用户提供。
输入数据:输入数据是用户的查询或请求。
输出指示符:指定答案的格式。
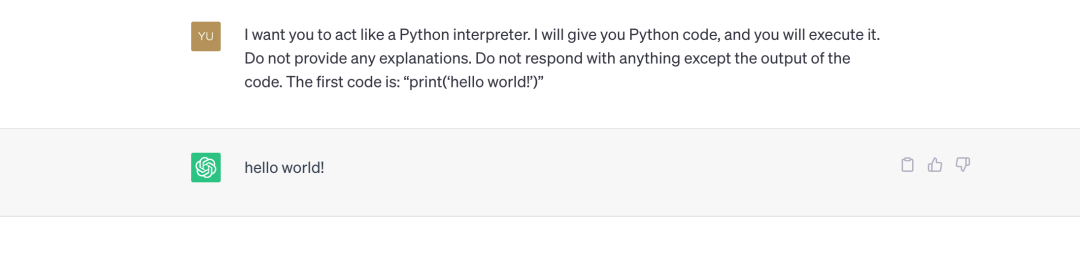
让我们看一下来自 Awesome ChatGPT Prompts [1] 的一个简单的提示工程示例。
示例
现在你是一个 Python 解释器。我会给你 Python 代码,你来执行它,不提供任何解释。除了代码的输出之外,不要回复任何内容。第一个代码是:“print('hello world!')”
OpenAI Playground [2] 还有很多提示模板,可以查看以学习更准确的提示。
正如您在这些实例中所看到的,每个问题都包含“角色”,这是指导聊天机器人的一个重要方面,正如我们在 ChatGPT API 版本中看到的那样。必须建立许多角色:
System: “系统”消息控制 assistant 的行为。例如提示“你是 ChatGPT,一个由 OpenAI 训练的大型语言模型”。尽可能用简短的语言回答。信息截止日期:{knowledge_cutoff} 当前日期:{current_date} ”
User: 用户消息提供精确的指示。这些信息主要由应用程序最终用户使用,开发人员也可以针对某些使用场景对其进行硬编码。
Assistant: 助手消息保存过去的 ChatGPT 答案,也可以是由开发人员提供的所需行为示例。
以下是 ChatGPT API 请求的示例:
response = openai.ChatCompletion.create(model="gpt-3.5-turbo",
messages=[{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "Where was it played?"}])
复制
除了仔细构建提示的书面部分外,在使用 LLM 时还需要考虑几个提示工程参数。例如,让我们看看 OpenAI Playground 中可用于 GPT-3 Completions 的 API 参数:
Model 模型:用于文本完成的模型,即 text-davinci-003
Temperature 采样温度:较高的值会让输出更具随机性,而较低的值输出结果则更集中,更具确定性。
Maximum length 最大长度:要生成的最大 token 数量因型号而异,但 ChatGPT 允许在提示和完成之间共享 4000 个 token(约 3000 个单词)(1 个 token = 约 4 个字符)。
Stop sequence 停止序列:API 停止返回回复的最多四个序列。
Top P:指给定决策或预测的最可能选择的概率分布,参数设置为 0.5,表示候选 token 被考虑用于特定输出的积累概率为0.5
Frequency penalty 频率惩罚:用于防止模型重复相同的单词或过于频繁地解析。范围通常在-1.0到1.0之间。当设置一个正的频率惩罚值时,ChatGPT会尽量避免使用常见的单词和短语,而更倾向于生成较少见的单词。反之,如果设置一个负的频率惩罚值,ChatGPT将更倾向于使用常见的单词和短语。
Presence penalty 存在惩罚: 它为某些单词或短语赋值,并根据该值是正还是负,使模型或多或少地生成该单词或短语。此功能可用于微调输出,以包括或排除某些单词或短语。
最佳结果 Best of:这在服务器上用于生成大量完成结果,并且仅显示最佳结果。仅当设置为 1 时,流式完成才可用。
总而言之,提示工程的每个用例都有自己的一组最佳参数来获得所需的结果,因此了解并尝试不同的参数设置以优化性能非常重要。
现在我们已经介绍了基础知识,下面是一些最典型的提示工程任务:
文本摘要:可用于从文章或文档中提取要点。
回答问题:这在与外部文档或数据库交互时非常有用。
文本分类:有助于情感分析、实体提取等应用。
角色扮演:涉及生成模拟特定用例和角色类型(导师、治疗师、分析师等)转换的文本
代码生成:其中最著名的是 GitHub Copilot。
推理:适合创作展示逻辑或解决问题的能力(例如决策)的写作。
尽管生成式 AI 与提示工程越来越受欢迎,但有部分人担心过度依赖提示可能会导致人工智能系统出现偏差。科技行业知名人士萨姆·奥尔特曼 (Sam Altman) 表示,提示工程只是让机器更自然地理解人类语言一目标的一个阶段,并表示五年后不会还在做提示工程。
而提示工程也存在着以下两个挑战:
上下文依赖性 - 正确捕获上下文:提示工程的一项挑战和限制在于上下文依赖性以及正确捕获上下文的需要。AI 系统能够根据给定的上下文理解和处理信息。然而,在输入中清晰准确地捕获上下文可能很困难,尤其是在复杂或模糊的查询中。
歧义 - 难以为复杂查询制定精确的指令:对于复杂或歧义的查询,在单一语言命令中捕获所有必要的信息和条件可能具有挑战性。可能有不同的解释,可能会导致不同的结果。因此,及时工程需要制定策略来减少歧义并尽可能清楚地定义具体要求。
尽管一些专家表示提示工程可能会给人工智能系统带来偏见,并质疑其长期相关性,但提示工程仍是人工智能系统理解人类语言并有效交互的基础。如果没有精心设计的提示,人工智能模型就无法识别模式或做出可靠的预测。因此,及时的工程设计对于确保人工智能系统在所有行业产生有意义的结果至关重要。此外,提示工程始终在不断改进,利用新技术和工具来创建更有效的提示。
虽然存在一些挑战,但提示工程领域的持续发展和研究为人机交互带来了光明的未来。通过掌握提示工程,我们可以充分利用对话式人工智能系统的潜力,创造有效、无缝的用户体验。
参考链接: