怎么会讲这个话题,这个说来真的长了。但是,长话短说,也是可以的。
我前面的文章提到,线上的服务用了c3p0数据库连接池,会偶发连接泄露问题,而分析到最后,又怀疑是db侧主动关闭连接,或者是服务所在机器和db之间有防火墙,防火墙主动关闭了连接。导致我们这边socket看着还健康,实际在对端已经失效了,然后我们在这个socket发消息过去,对方一直不回复,我方没设置超时时间,导致长时间阻塞在read方法上(等待对方响应)。
然后,为了模拟这种场景,我是想了一些办法,我搜到的传统一点的办法是,我们是oracle,支持sleep命令,执行后,数据库就像死了一样,这样应该可以模拟出read timeout。但是吧,开发环境就那一个数据库,很多人用,我去sleep它,不太好,我自己搭吧,有点懒,而且,感觉这个方法不够通用,换个别的数据库超时,或者是什么服务超时,岂不是又要另寻他法?
个人偏爱通用的东西,比如这种超时模拟的场景,不只是可以模拟db,也可以模拟其他远端服务。
一开始,我想的办法是nginx四层代理(使用stream模块),比如客户端连接nginx,然后又nginx转发流量到后面的db啥的,然后当后端db返回响应时,我在nginx上sleep个n秒再返回,就能达成客户端超时的场景,但是,经过我后面多方研究,找到了一个在nginx或者openresty上支持sleep的模块(https://github.com/openresty/stream-echo-nginx-module),但是,这个模块明确写了,不能和proxy模块一起用:
- The commands of this module cannot be mixed with other response-generating modules like the standard ngx_stream_proxy module in the same
server {}block, for obvious reasons.
另外,它也说了,它虽然sleep,但是不会阻塞nginx的eventloop线程。
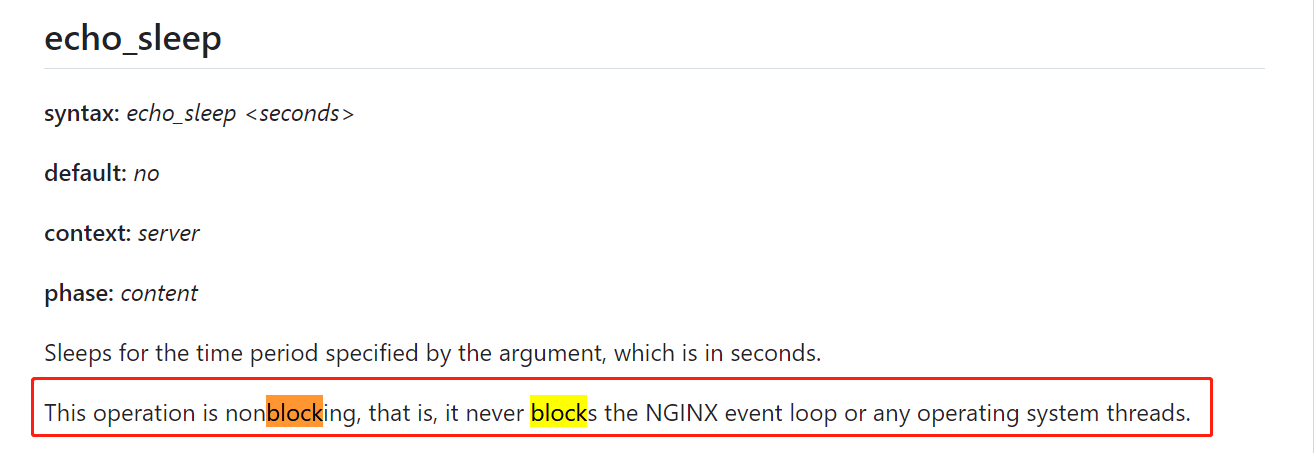
再后来,也试过stream-lua-nginx-module模块,打算用lua代码来sleep,发现依然不行,应该怎么说呢,我的理解是,nginx本身就是一个非阻塞的模型,所以,想要靠sleep这些去阻塞它,反而做不到。
所以,后面我放弃了这条路。
再后来,我是偶然间来了灵感,认为可以靠机器上的防火墙,将db返回的数据包给丢掉,这样,就可以模拟出读超时的场景了,事实上,这条路是正确的,但是,主要是网上资料比较少,所以也踩了好多坑才折腾出来。
最近就打算好好介绍下这个防火墙,但是,我发现想要比较系统地介绍它,还是比较困难,我自己又现学了好一阵,每次想写的时候,发现还是有太多不了解的,于是搁笔。
今天是打算先介绍下iptables的nat功能,结果实验的时候,死活有问题,然后想着怎么打日志,结果打日志又出问题,折腾了好久(搜索引擎上关于这个的资料较少),这里就记录下来。
在centos 6时代,我记得机器上默认的防火墙就是iptables;centos 7,基本换成了firewalld。我这次最先折腾的是firewalld,后来一直没成功,后来换到iptables结果就好了,因此最近都是在折腾iptables,这里就先介绍iptables,后续再去研究firewalld。
一般来说,先停止firewalld,避免互相影响。
systemctl status firewalld systemctl stop firewalld复制
安装iptables并启动:
yum install -y iptables-services // 启动 systemctl start iptables // 查看状态 systemctl status iptables 如果提示绿色的“active (exited)”,则iptables已经启动成功。 // 停止 systemctl stop iptables复制
安装完成后,或者启动后,执行如下命令,会发现有一些默认规则。
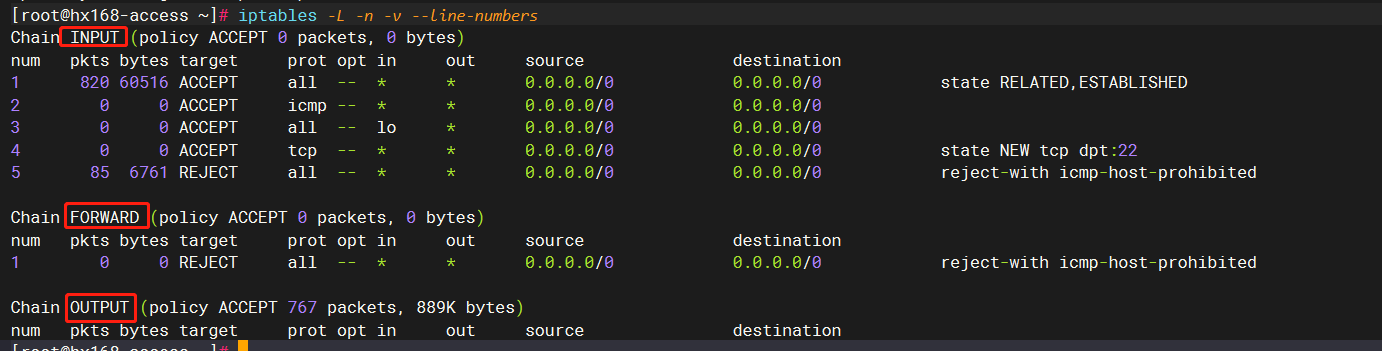
所谓规则,在防火墙中,就是:针对某个满足条件1、条件2、条件n的包,需要采取什么动作,而我们可能有很多这样的规则,形成一个或多个list。
而上面看到的默认规则,存放在文件 /etc/sysconfig/iptables:
vim /etc/sysconfig/iptables *filter :INPUT ACCEPT [0:0] :FORWARD ACCEPT [0:0] :OUTPUT ACCEPT [0:0] // 1 state如果为ESTABLISHED,可以粗略理解为tcp中三次握手后的数据包,对这种包,放行。当然,防火墙不止处理tcp,所以这个概念还是略有差异 -A INPUT -m state --state RELATED,ESTABLISHED -j ACCEPT // 2 对于ping包,放行 -A INPUT -p icmp -j ACCEPT // 3 本机的loopback网卡的包,放行 -A INPUT -i lo -j ACCEPT // 4 对于本机的ssh连接请求包,放行 -A INPUT -p tcp -m state --state NEW -m tcp --dport 22 -j ACCEPT // 5 其他的包,都拒绝 -A INPUT -j REJECT --reject-with icmp-host-prohibited -A FORWARD -j REJECT --reject-with icmp-host-prohibited COMMIT复制
下面的一些iptables的东西,我们还没介绍,所以可能导致看不太懂,可以简单看下,我们本篇就是介绍,如何保证debug的日志能看到。
一般来说,对于开发同学来说,场景也就是比较简单,如禁止/允许访问某端口,或者只禁止允许某些ip等,比如,假设我们希望放行8080端口,要怎么设置呢?
我们得设想一下,客户端访问8080端口的话,传过来的packet一般长啥样,是不是tcp协议这一层的目标端口是8080呢,对吧?那我们只要设置一个规则,将这种包筛选出来,放行即可。
我先随便启动一个8080的监听:
python -m SimpleHTTPServer 8080复制
然后我们新建一个rule,准备放行8080端口:
iptables -i filter -I INPUT 1 -p tcp -m tcp --dport=8080 -j ACCEPT复制
然后本机执行telnet,结果发现连不上。。。
为啥呢,因为我命令写错了,假设我不知道我命令写错了,感觉没匹配上我的这个规则呢,那我怎么知道,iptables到底最终匹配到哪个rule了呢,会不会还没到这个rule就出问题了呢?
不要着急,我们加上下面这个命令:
iptables -t raw -I PREROUTING -p tcp -m tcp --dport 8080 -j TRACE复制
这个命令,分段来看:
-t raw : 指定要操作的table,其实就是传说中的三表五链中的三表之一,table这里可以先不管 -I PREROUTING: -I表示插入规则,后面指定要插入的链(链就是规则的集合) 上面两个选项,暂时不理解可以先不管,其实就是指定了一个时机,这个时机,发生在防火墙处理网络报文的最前面。 此时,我们指定一个rule: -p tcp -m tcp --dport 8080 -j TRACE 即,对于目标端口为8080的报文,-j TRACE ,表示进行跟踪,这样的话,防火墙会在日志打印出最终匹配上了哪些rule复制
增加了上述命令后,我们重试一次telnet,然后打开/var/log/messages日志:

能看到对于某一条客户端报文(这里其实就是客户端发过来的第一次tcp握手,注意看,第二行的ID都是35701,所以都是针对同一条报文的日志),一共打印了三行:
raw:PREROUTING:policy:2 nat:PREROUTING:policy:1 filter:INPUT:rule:6复制
这里其实就是表示,一个顺序经过了三个规则。
首先是raw:PREROUTING,即raw表的PREROUTING链的默认规则(policy:2),看下图,raw表只有我们那个trace规则,除此之外,啥都没有,所以匹配了PREROUTING链的默认策略:

按照网上的说法,下图红框处就表示默认策略:

他么的,为啥说是网上的说法呢,因为,我本来想实验一下,把这块改成DROP再看看效果:
// 不要执行!!!这个命令就是设置默认策略为drop iptables -P PREROUTING DROP -t raw复制
结果,他么的,马上shell就断了,然后这是工作服务器,我都以为必须找运维才能解决了,后来好歹想起来有个平台,可以重启服务器,重启后,iptables我是没设置开机启动的,这条rule也是没有持久化的,所以我才能连上shell,在这里继续做实验。
扯远了,执行完第一条链的默认策略ACCEPT后,进入表nat的PREROUTING链:
[root@hx168-access ~]# iptables -nvL -t nat Chain PREROUTING (policy ACCEPT 0 packets, 0 bytes) pkts bytes target prot opt in out source destination Chain INPUT (policy ACCEPT 0 packets, 0 bytes) pkts bytes target prot opt in out source destination Chain OUTPUT (policy ACCEPT 0 packets, 0 bytes) pkts bytes target prot opt in out source destination Chain POSTROUTING (policy ACCEPT 0 packets, 0 bytes) pkts bytes target prot opt in out source destination复制
这个也是空的,没有rule,所以最终是执行了PREROUTING:policy:1默认策略:ACCEPT,然后进入到下面的:
filter:INPUT:rule:6。
这就是filter表的INPUT规则链的第六条规则:
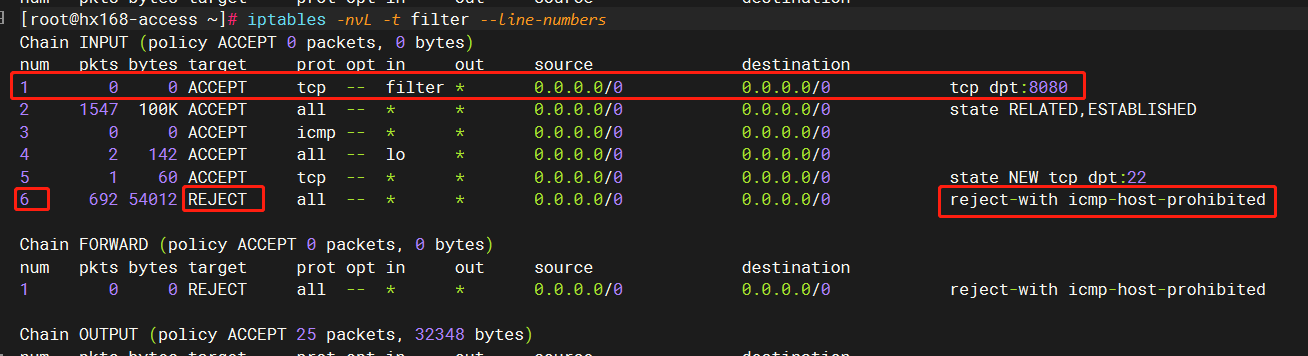
第六条规则,就是简单粗暴地拒绝,为啥会执行到第六条呢,这个是按1-6顺序执行下来的,说明前面的5条,都没匹配上条件,那肯定就是条件估计写得有问题。
经过我认真检查,发现自己手写还是容易出错,正确的应该是下面这样:
// 正确版本 iptables -I INPUT -p tcp --dport 8080 -j ACCEPT // 错误版本 iptables -i filter -I INPUT 1 -p tcp -m tcp --dport=8080 -j ACCEPT复制
错误的地方就是 -i filter,我本来是准备显式指定下要操作的表(其实正确的版本里就没指定,默认就是filter),结果语法写错了,应该是-t filter,重新执行下,就好了:
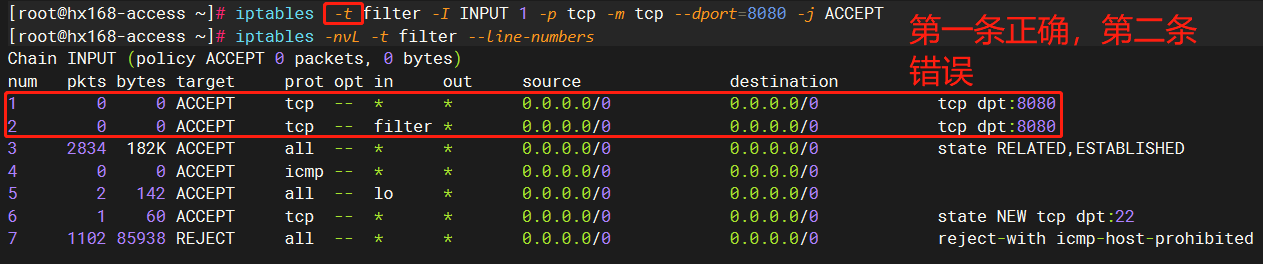
可以看到,虽然错误的规则还存在,但是我们把正确的规则放到了num=1,它会先执行,它匹配上了,后面就不会执行了。
我们重新看trace日志,这次就是匹配上rule1了:

今天其实花了很多时间在trace规则上,我在网上查到有这种规则,但是,加了后,死活在log日志里看不到内容,查了半天,到处改改改也没搞出来。
这个/var/log/messages文件,一般是什么服务在往里面写呢?是rsyslogd,它是一个后台进程,
简单一句话的介绍是,它是一个支持将消息记录到日志的系统工具,消息可以通过网络或者本机unix socket的方式发送给它。
Rsyslogd is a system utility providing support for message logging. Support of both internet and unix domain sockets enables this utility to support both local and remote logging.
一般来说,都是通过本机unix socket方式。
根据man rsyslogd的说法,这个进程主要涉及如下几个重要文件:
主配置文件: /etc/rsyslog.conf Configuration file for rsyslogd. See rsyslog.conf(5) for exact information. unix socket的位置,本进程就从这里获取要写日志的消息 /dev/log The Unix domain socket to from where local syslog messages are read. 进程pid: /var/run/syslogd.pid The file containing the process id of rsyslogd.复制
进程id这个是可以看到,是匹配的:4773:
[root@hx168-access ~]# cat /var/run/syslogd.pid 4773 [root@hx168-access ~]# ps -ef|grep rsys root 4773 1 0 18:44 ? 00:00:00 /usr/sbin/rsyslogd -n复制
这个进程,主要会写如下文件(默认配置情况下):

比如我们上面的防火墙跟踪日志就在/var/log/messages。
今天我遇到的问题就是,看到网上说,要改配置,将内核日志给输出才行:
vim /etc/rsyslog.conf 增加如下一行: kern.* /var/log/iptables.log(这里文件名可以自取)复制
结果弄了后还是没效果。
后面我换了台机器,结果发现可以输出,而且也没像上面这样配置,我后面就在想,到底是哪里的问题。
# xxx为rsyslogd的pid
strace -p xxx -q -f -s 200
复制strace命令可以attach到一个进程上,监控其系统调用。
我当时两台机器,一台可以,一台不行,于是分别在两台机器上开启该命令,然后执行ping,发现正常的机器上,是可以看到有如下这些系统调用的,而异常的机器就没有:
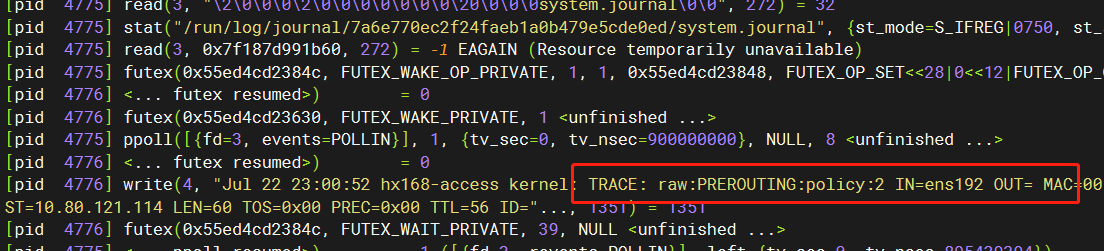
所以,我开始怀疑是不是防火墙本身的问题,并没把日志写到rsyslogd。
在man iptables-extensions文档,讲解了TRACE这个target操作的信息。
TRACE
This target marks packets so that the kernel will log every rule which match the packets as those traverse the tables, chains, rules.A logging backend, such as nf_log_ipv4(6) or nfnetlink_log, must be loaded for this to be visible. The packets are logged with the string prefix: "TRACE:
tablename:chainname:type:rulenum " where type can be "rule" for plain rule, "return" for implicit rule at the end of a user defined chain and "policy" for
the policy of the built in chains.
It can only be used in the raw table.
这里面提到:
A logging backend, such as nf_log_ipv4(6) or nfnetlink_log, must be loaded for this to be visible.
必须先在机器上加载nf_log_ipv4或者nfnetlink_log这两个模块之一,其他细节就没有了。
我在网上当时也查了不少文章,就是看看大家是怎么配置这个TRACE规则的,然后跟着做了些操作,比如,加载模块的命令是modprobe,我搜索shell history,发现执行了如下这么多次:
678 modprobe ipt_LOG 688 modprobe ipt_LOG ip6t_LOG nfnetlink_log 741 modprobe nfnetlink_log 748 modprobe nf_log_ipv4复制
模块相关的命令有这几个:
加载或删除模块 modprobe - Add and remove modules from the Linux Kernel 显示已加载的模块 lsmod - Show the status of modules in the Linux Kernel lsmod is a trivial program which nicely formats the contents of the /proc/modules, showing what kernel modules are currently loaded. 查看模块信息 modinfo - Show information about a Linux Kernel module复制
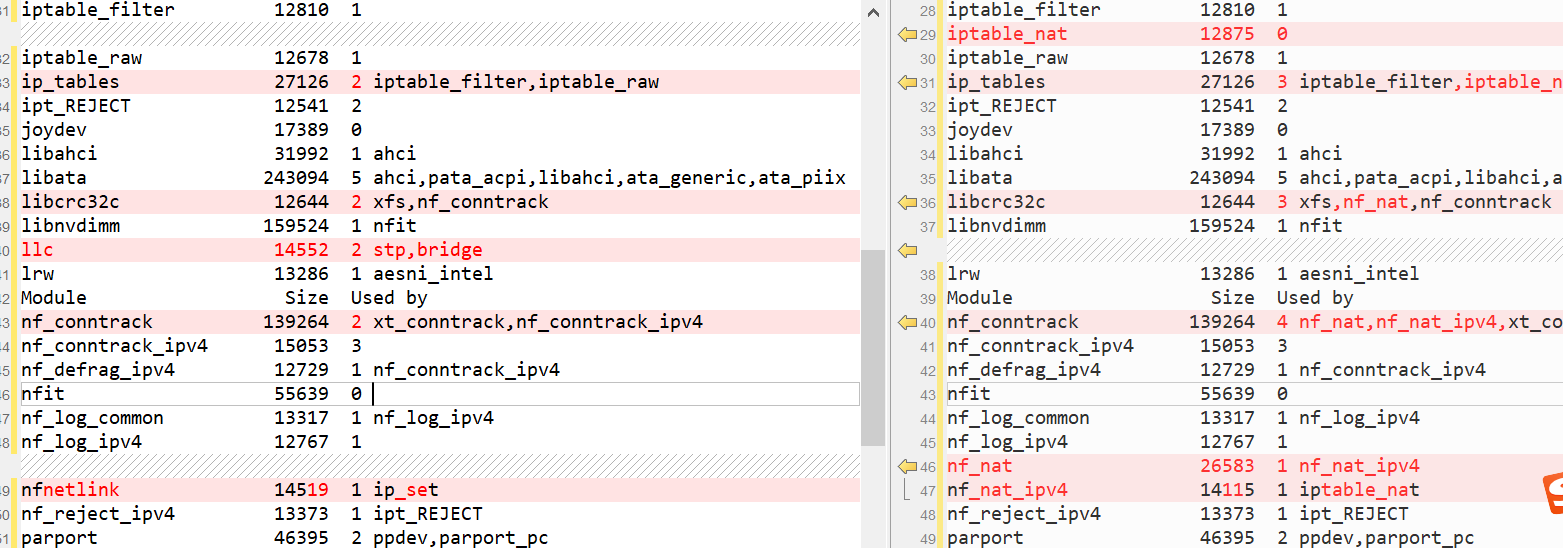
我分别在两台机器执行了lsmod | sort,然后比较差异,确实有些差异:
然后在网上看到一些文章,说和内核参数有关(sysctl -a),于是也比较了一下,发现其中一个参数可能有影响:
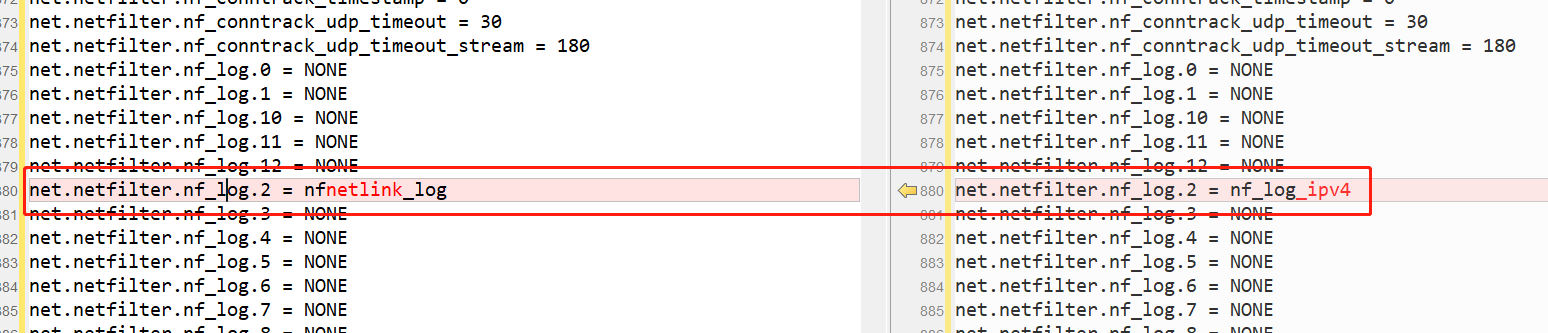
这个参数我在网上查了好久,甚至没查到枚举值有哪些,总的来说,信息非常少。
后来大概知道,如下这个参数值,会把log不是发往rsyslogd,而是发往一个叫ulogd的后台程序。
net.netfilter.nf_log.2 = nfnetlink_log复制
这个ulogd大概介绍下,https://www.netfilter.org/projects/ulogd/:
ulogd is a userspace logging daemon for netfilter/iptables related logging.
它是一个用户态的日志后台,供netfilter/iptables相关的日志使用。不管怎么说,反正不会发往rsyslog这边就对了。
这个为啥会变成这样呢,大概是因为我执行了modprobe nfnetlink_log吧。正确的模块其实应该是nf_log_ipv4.
所以我这边修改了下值:
echo nf_log_ipv4 > /proc/sys/net/netfilter/nf_log/2 然后再查看: sysctl -a 发现就已经变成nf_log_ipv4了复制
这里额外补充下,在如下目录下,有12个文件:
[root@hx168-access ~]# ll /proc/sys/net/netfilter/nf_log -rw-r--r-- 1 root root 0 Jul 22 23:25 2 ... -rw-r--r-- 1 root root 0 Jul 22 23:25 12复制
其中,2就是表示IP协议族,表示遇到IP协议族时,日志打印使用的模块,其他的协议族都不用特别关心。
首先是一个feature,貌似是这块net.netfilter.nf_log.2可以取的值太多了,要合并掉几个:
https://patchwork.kernel.org/project/netdevbpf/patch/20210406122133.1644-2-pablo@netfilter.org/
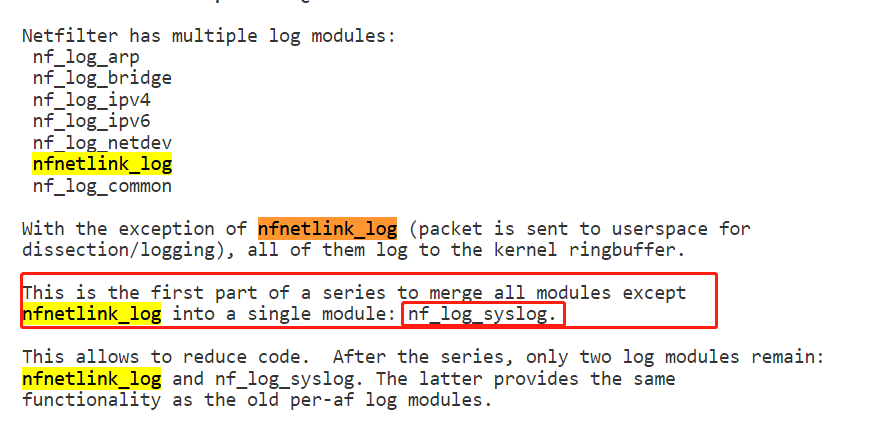
就是以后就两个模块,一个nfnetlink_log,一个nf_log_syslog(这个一看就是写到rsyslog的)。
再下来,是一个bug提交,和我的问题一模一样,最后解决办法也一样,是吐槽trace的文档写得太草了:
https://bugzilla.netfilter.org/show_bug.cgi?id=1076
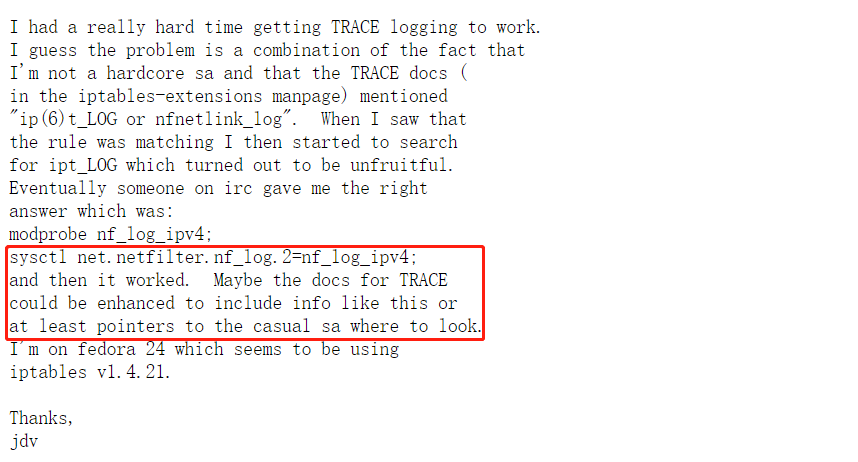
问题是几年前提的,看起来还是没人改,bug也没关闭。
就这样吧,下篇再继续讲这个iptables的其他方面。