布隆过滤器(Bloom Filter)是1970年由布隆提出的
它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中
优点:
缺点:
用的使用场景:
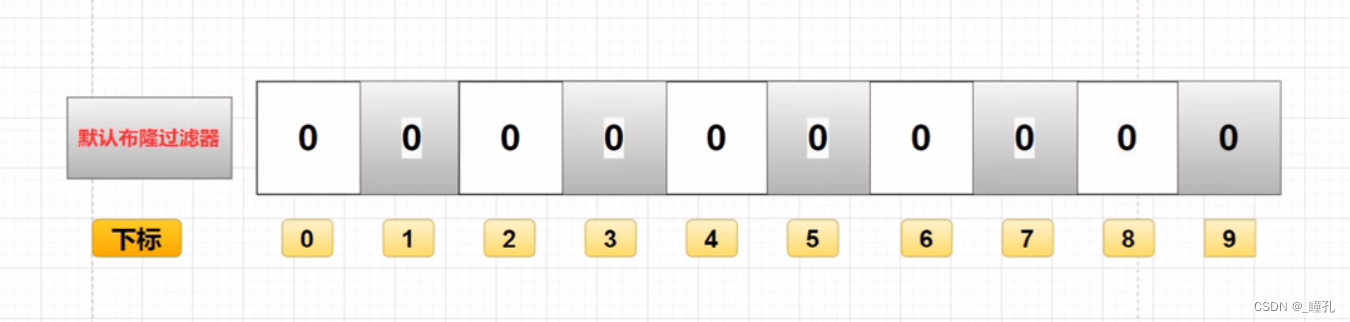
布隆过滤器是一个bit向量或者说是一个bit数组(下面的数字为索引):
为什么布隆过滤器要使用多个Hash函数?
假设我们的布隆过滤器有三个哈希函数,分别名为hash1、hash2、hash3,主要流程如下:
1、初始化
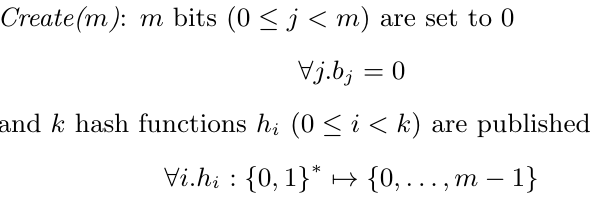
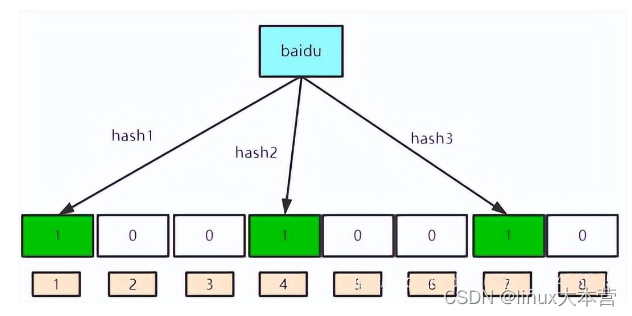
针对于“baidu”这个元素,我们调用三个哈希函数,将其映射到bit向量的三个位置(分别为1、4、7),并且将对应的位置置为1
2、插入
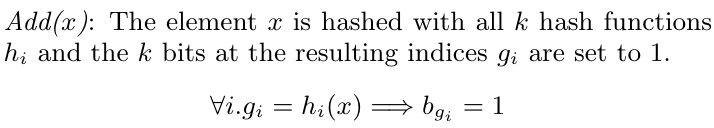
现在针对于“tencent”这个元素,我们也调用三个哈希函数,将其映射到bit向量的三个位置(分别为3、4、8),并且将对应的位置置为1
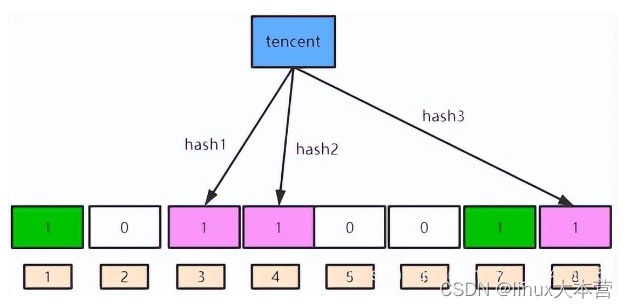
此时,整个bit向量的1、3、4、7、8这几个位置被置为1了。其中4这个索引被覆盖了,因为“baidu”和“tencent”都将其置为1,覆盖的索引与误判率有关。
3、查找

例如上面我们去查询“baidu”的时候,由于“baidu”之前被我们插入过,为什么还不能百分百确定它一定存在呢?
因此,当随着增加的值越来越多时,bit向量被置为1的数量也就会越来越多,因此误判率会越来越大。例如,当查询“taobao”时,万一所有的哈希函数返回的对应bit都为1,那么布隆过滤器可能也认为“taobao”这个元素存在。
那如何控制误判率?
\(k\):哈希函数个数;\(w\):带插入元素个数;\(m\):BF数组的长度。
\(n\):布隆过滤器最大处理的元素的个数;\(P\):希望的误差率;\(m\):布隆过滤器的bit位数目;\(k\):哈希函数的个数
1、python简单实现
这里的哈希函数是简单定义的
import math
import random
import time
def hash_function(a, b, c, item, tablelen):
return (a * item ** 2 + b * item + c) % tablelen #哈希函数
def construction_of_SBF(tablelen = 1000, set = []):
k = int(math.log(2, math.e) * (tablelen / len(set))) #哈希函数的个数
print("k=",k)
hash = []
random.seed(time.time())
for i in range(k): #随机生成哈希函数的三个参数
a = random.randint(1, 1000)
b = random.randint(1, 1000)
c = random.randint(1, 1000)
hash.append((a, b, c))
bitArray = [0] * tablelen #BF数组
for element in set: #映射集合元素到位数组
for i in range(k):
hx = hash_function(hash[i][0], hash[i][1], hash[i][2], element, tablelen)
bitArray[hx] = 1
print("BF=",bitArray)
filter = [bitArray, hash]
return filter
# 测试
def test_bloom_filters(bloom_filter = None):
if bloom_filter == None:
return False
testSet = [1, 3, 7, 11, 9, 5, 4, 67, 81]
for item in testSet:
flag = True
for i in range(len(filter[1])):
hx = hash_function(filter[1][i][0], filter[1][i][1], filter[1][i][2], item, len(filter[0]))
if bloom_filter[0][hx] != 1:
flag = False
break
if flag is True:
print("%d is in filter\n" % item)
else:
print("%d is not in filter\n" % item)
return True
if __name__ == "__main__":
filter = construction_of_SBF(set = list(range(10)))
test_bloom_filters(filter)
复制2、C++实现
这里哈希函数使用的是MurmurHash2算法,输出64位哈希值
#include "bloomfilter.h"
#define MAX_ITEMS 6000000 // 设置最大元素个数,BF容量
#define ADD_ITEMS 1000 // 添加测试元素
#define P_ERROR 0.0001// 设置误差
//
int main(int argc, char** argv)
{
printf(" test bloomfilter\n");
// 1. 定义BaseBloomFilter
static BaseBloomFilter stBloomFilter = {0};
// 2. 初始化stBloomFilter,调用时传入hash种子,存储容量,以及允许的误判率
InitBloomFilter(&stBloomFilter, 0, MAX_ITEMS, P_ERROR);
// 3. 向BloomFilter中新增数值
char url[128] = {0};
for(int i = 0; i < ADD_ITEMS; i++){
sprintf(url, "https://blog.csdn.net/qq_41453285/%d.html", i);
if(0 == BloomFilter_Add(&stBloomFilter, (const void*)url, strlen(url))){
printf("add %s success\n", url);
}else{
printf("add %s failed\n", url);
}
memset(url, 0, sizeof(url));
}
// 4. check url exist or not
char* str = "https://blog.csdn.net/qq_41453285/0.html";
if (0 == BloomFilter_Check(&stBloomFilter, (const void*)str, strlen(str)) ){
printf("https://blog.csdn.net/qq_41453285/0.html exist\n");
}
char* str2 = "https://blog.csdn.net/qq_41453285/10001.html";
if (0 != BloomFilter_Check(&stBloomFilter, (const void*)str2, strlen(str2)) ){
printf("https://blog.csdn.net/qq_41453285/10001.html not exist\n");
}
// 5. free bloomfilter
FreeBloomFilter(&stBloomFilter);
return 0;
}
复制1、https://blog.csdn.net/qq_40989769/article/details/126781815