学习&转载文章:使用Python的一维卷积
在开发机器学习算法时,最重要的事情之一(如果不是最重要的话)是提取最相关的特征,这是在项目的特征工程部分中完成的。
在CNNs中,此过程由网络自动完成。特别是在早期层中,网络试图提取图像的最重要的特征,例如边缘和形状。
另一方面,在最后一层中,它将能够组合各种特征以提取更复杂的特征,例如眼睛或嘴巴,这在例如我们想要创建人类图像的分类器时可能很有用。
让我们想象一只狗的形象。我们想在这张图片中找到一只耳朵,以确保有一只狗。我们可以创建一个滤波器或核,以查看它是否可以在图像中的各个点找到耳朵。
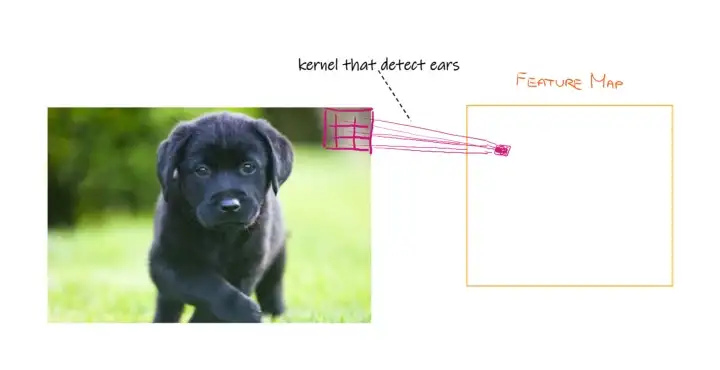
在图像中,我们有一组紫色的权重(内核),当乘以输入图像的像素值时,它会告诉我们是否存在耳朵或下巴。我们是如何创建这些权重参数的?嗯…随机!网络的训练将慢慢学习正确的权重参数。
生成的输出(橙色)称为特征图。
通常在卷积之后,所以在获得特征图之后,我们有汇集层来汇总更多信息,然后我们将进行另一个卷积等等,但我们在本文中不讨论其他层。
我们直观地理解了卷积如何从图像中提取特征。但卷积也经常与文本等其他类型的数据一起使用,这是因为卷积只是一个公式,我们需要了解它是如何工作的。
一维卷积是在两个向量之间定义的,而不是像图像中的情况那样在矩阵之间定义的。
所以我们将有一个向量\(x\)作为我们的输入,一个核\(w\)作为第二个向量。
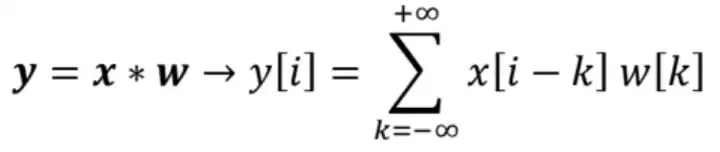
符号\(*\)表示卷积(不是乘法)。\(Y[i]\)是合成向量\(Y\)的元素\(i\)。
首先,如果你注意到求和的极端值从\(-inf\)到\(+inf\),但这在机器学习中没有太大意义。我们通常给某个大小加前缀。假设输入向量的大小必须为12。但是如果向量小于前缀大小会发生什么?嗯,我们可以在向量的开头和结尾添加零,以使其大小正确,这种技术称为填充。
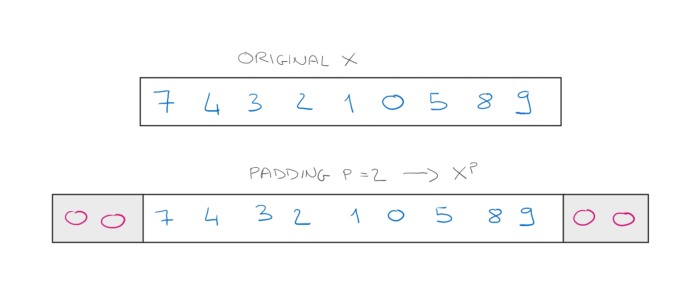
然后我们假设原始输入\(x\)和滤波器\(w\)分别具有大小\(n\)和\(m\),其中\(n≤ m\)、 然后,带有填充的输入将具有大小\(n+2p\),原始公式如下。
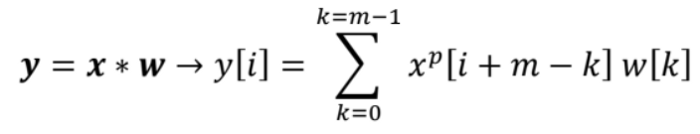
从上面的公式中,我们可以注意到一件事:我们所做的是滚动\(x^p\)向量和\(w\)向量的单元格。然而,向量\(x^p\)从右向左滚动,\(w\)从左向右滚动。但是,我们可以简单地反转向量\(w\),并执行\(x^p\)和\(w^{rotated}\)之间的向量积。
\(x^p\):表示\(x\)填充后的
\(w^{rotated}\):表示\(x\)旋转后的
让我们直观地看看会发生什么。首先,我们旋转滤波器(旋转\(w\))。
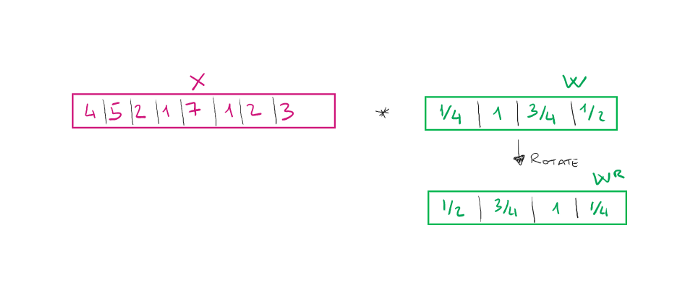
初始公式告诉我们要做的是使两个向量之间的向量积,只考虑初始向量的一部分。这部分被称为局部感受野。然后,我们将向量\(w^R\)每次滑动两个位置,在这种情况下,我们将说我们使用的是步幅=2。后者也是我们需要优化的网络的超参数。
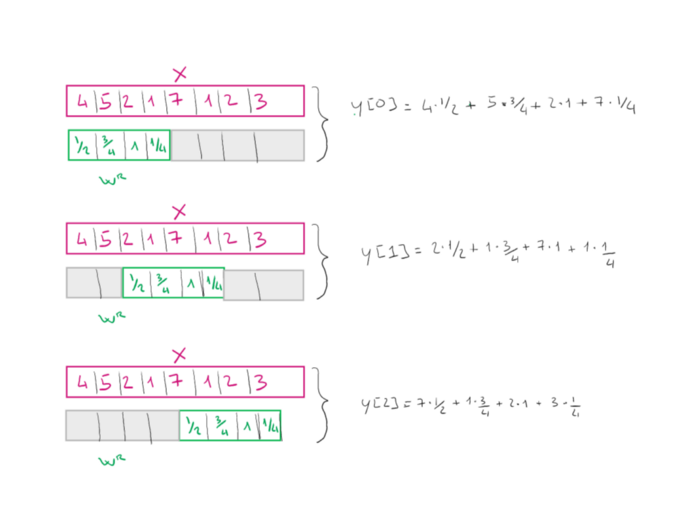
你应该注意,根据我们使用的填充模式,我们或多或少地强调了一些输入单元格。在前面的例子中,当我们计算输出\(y[0]\)时,单元格\(x[0]\)只考虑了一次。相反,在\(y[1]\)和\(y[2]\)的计算中都考虑了\(x[2]\)单元,因此它更重要。我们还可以通过使用填充来处理向量边界处的单元格的这种重要性。
有3种不同类型的填充:
如何确定卷积输出大小?
许多人经常对CNN各个层的输入和输出大小感到困惑,并与不匹配的错误作斗争!实际上,计算卷积层的输出大小非常简单。
假设我们有一个输入\(x\),一个核\(w\),并且想要计算卷积\(y=x*w\)。
要考虑的参数是\(x\)的大小\(n\)、\(w\)的大小\(m\)、填充\(p\)和步幅\(s\)。输出的大小\(o\)将由以下公式给出:
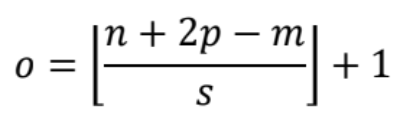
符号$⌊⌋ \(指示向下取整操作。例如\)⌊2.4⌋ = 2$.
让我们看看如何应用公式和示例:
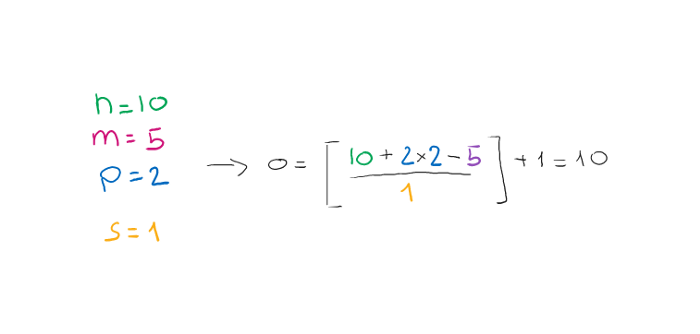
在第一个示例中,我们看到输出大小与输入大小相同,因此我们推断使用了相同的模式填充。
我们看到另一个例子,我们改变了核大小和步长。
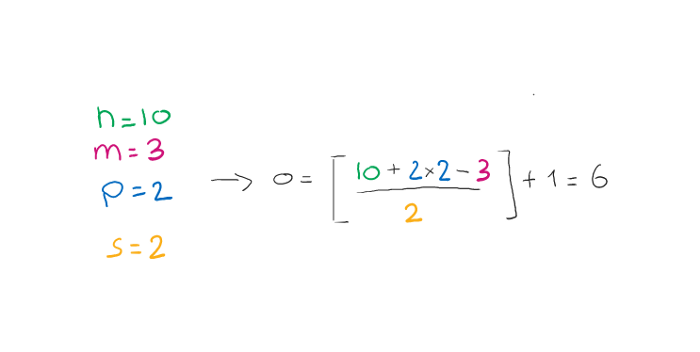
如果到目前为止你仍然有点困惑,没问题。让我们开始着手编写代码,事情会变得更清楚。
import numpy as np
def conv1D(x,w, p=0 , s=1):
'''
x : input vector
w : filter
p : padding size
s : stride
'''
assert len(w) <= len(x), "x should be bigger than w"
assert p >= 0, "padding cannot be negative"
w_r = np.array(w[::-1]) #rotation of w
x_padded = np.array(x)
if p > 0 :
zeros = np.zeros(shape = p)
x_padded = np.concatenate([zeros, x_padded, zeros]) #add zeros around original vector
out = []
#iterate through the original array s cells per step
for i in range(0, int((len(x_padded) - len(w_r))) + 1 , s):
out.append(np.sum(x_padded[i:i + w_r.shape[0]] * w_r)) #formula we have seen before
return np.array(out)
让我们尝试在一些真实数据上运行此函数并查看结果。让我们将结果与自动计算卷积结果的NumPy内置函数进行比较。
x = [3,6,8,2,1,4,7,9]
w = [4 ,0, 6, 3, 2]
conv1D(x,w,2,1)
'''
>>> array([50., 53., 76., 64., 56., 67., 56., 83.])
'''
np.convolve(x , w, mode = 'same')
'''
>>> array([50., 53., 76., 64., 56., 67., 56., 83.])
'''
正如你所看到的,我们开发的函数和NumPy的卷积方法的结果是相同的。卷积是卷积神经网络以及现代计算机视觉的基本元素。我们经常在不了解其组成的构建块的情况下立即开始实现复杂的算法。