本文将介绍大模型研发中数据工程,包括数据以及自动化相关的内容,并介绍在当前的情况下,知识图谱的定位以及如何融入到大模型的整个研发当中。
分享将会围绕下面四个方面展开:
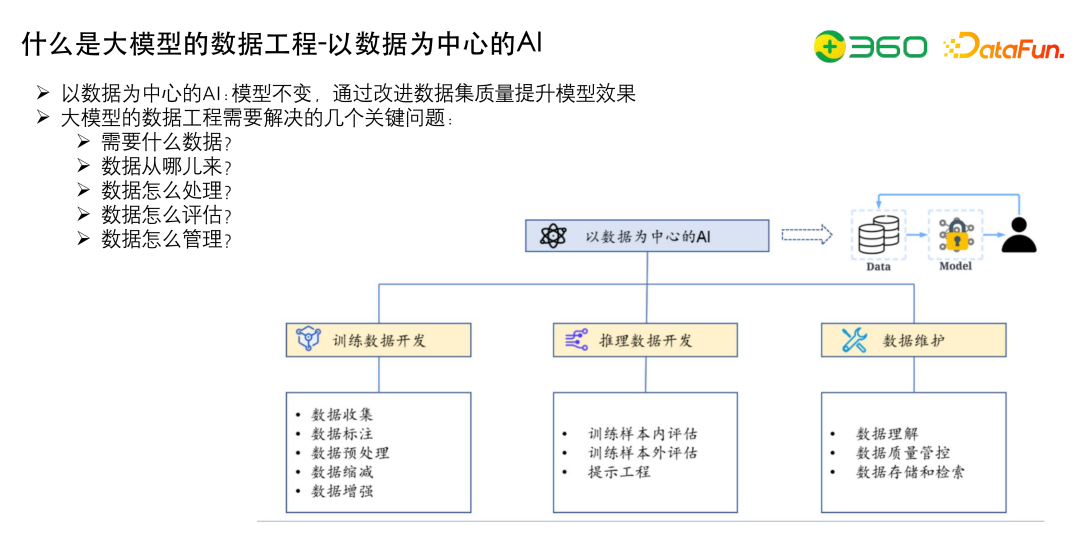
什么是大模型的数据工程?现在大家去做GPT模型或者BERT等模型,都会有两个方向。
以数据为中心的 AI 核心在于训练数据开发,推理数据开发以及数据维护。
训练数据开发包括很多的pipeline,包括如何收集数据,如何定数据源,如何做高质量的数据标注,如何做数据的预处理或者数据的缩减或增强。比如做领域微调数据,如果行业数据只有几万条,需要增强到几十万条或者几百万条,才能真正地把领域或行业的数据加进去。
推理数据开发,就是怎么评估之前的训练样本,更好的评估测试集外的数据。
数据维护,做数据相关的事情需要实现成一个闭环,包括对数据的理解。使用训练数据进行训练时如果发现数据有问题,需要可以定位到问题来源于哪个数据集,做定点的追踪和优化。
大模型的数据工程主要解决的几个关键问题如下:
解决上面的问题,就可以比较好的搭一个相对完整的pipeline了。

回顾一下现有大模型的基本情况,这里基于四张图进行阐述。
左上图反映了到2023年3月为止,语言模型的模型大小,饼越大,其对应的参数就越大。可以看到,国外的MT-NLG、PaLM还有OPT的参数规模是比较大的;国内的GLM-130B的参数是比较大的,已经到了千亿级水平。
右上图比较形象地揭示了现在不同段位的大模型的玩法:
现在做大模型大家基本是分散在这3个层级内。
左下图描述了截止2022年12月DeepMind的模型,DeepMind在不断地更新一些模型,先后提出了Gopher-280B、Chinchilla-70B、Flamingo-80B 等不同代号的模型,可以看到,现在做大模型的时候都喜欢用动物来命名,所以现在动物园的名称可能后面也会卷的不行。
右下图描述了代码生成模型的规模。目前比较大有CodeGen,有16B参数;然后有清华的CodeGeeX,有13B参数。现在也有一个趋势,就是把文本和代码就混合去训练,训练后的 COT (增强混合模型)能力有一定提升。

上图列出了大模型的应用场景,大家不断在探索大模型的边界,分了几个层级:
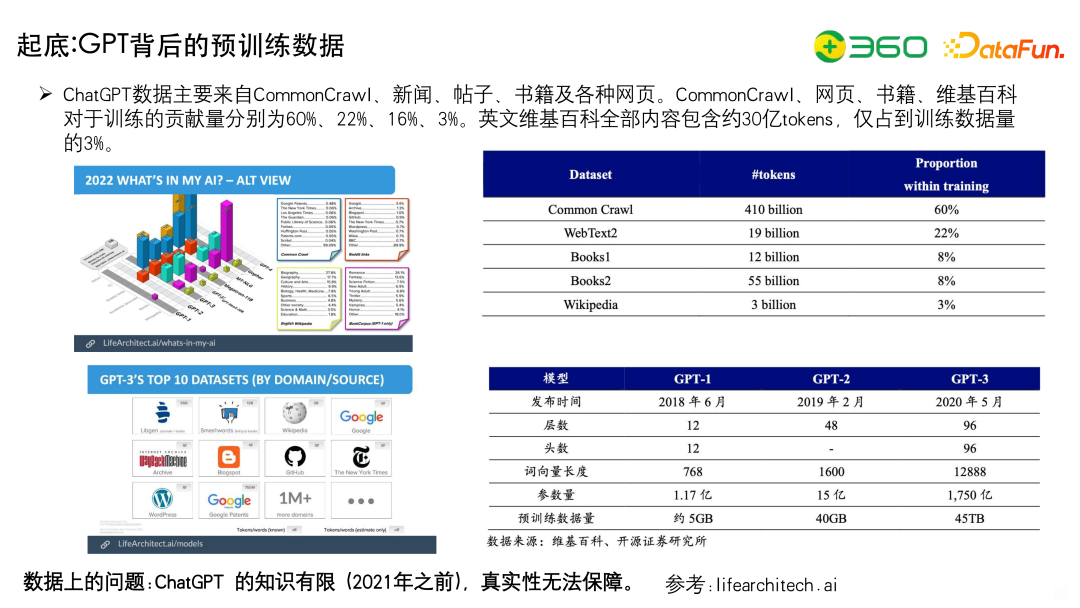
这些模型背后都用了什么数据呢?
我们先来看ChatGPT的变化:
右上图看一下GPT-3具体数据上的分布,60%的数据是Common Crawl,也就是低质量的网页;占比22%的WebText2是抓取的高质量网页;Books1、Books2是比较高质量的书籍,分别占比8%;维基百科Wikipedia占比3%。
可以发现:
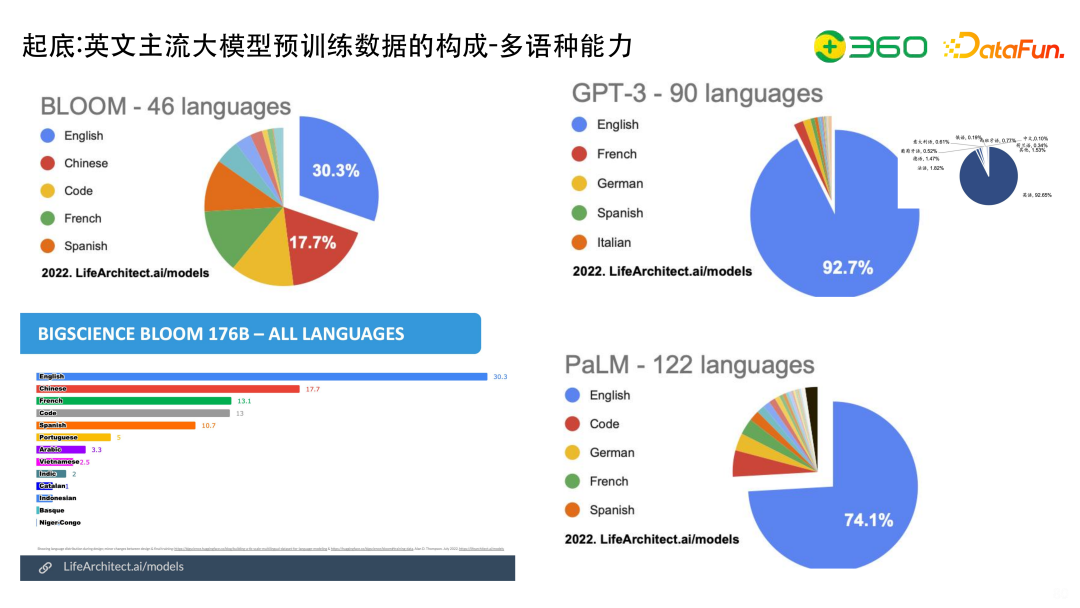
从多语种能力上看一下英文主流大模型。比如说BLOOM,有46种语言,最多的还是English,所以现在大家去做领域微调进行技术选型的时候, BLOOM是一个比较好的底座,和LLaMA相比,BLOOM的多语言能力比较强。GPT-3有90种语言,当然绝大部分约92.7%还是English,中文的话大约是0.1%。PaLM有122种语言, 74.1%是English,其中还加了一些code。
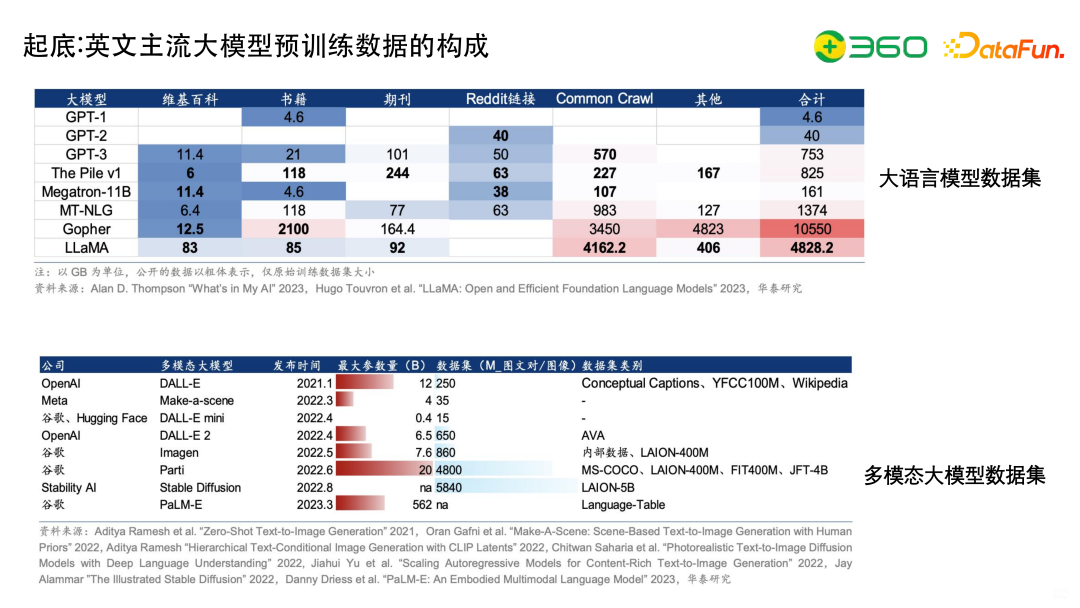
分析一下主流大模型训练数据的构成。我们先拉出来一个维度,基本上包括维基百科、书籍、期刊、Reddit链接(WebText)、Common Crawl等。
可以看到很多大模型Common Crawl都是占了比较大的比重。
除了文本大模型,还有多模态大模型。
OpenAI有DALL-E会有Conceptual Captions等数据集,谷歌的多模态模型也是一样,但是跟文本大模型相比,数据集相对比较少,而且多模态的参数量跟纯文本相比还是相差一定量级的。
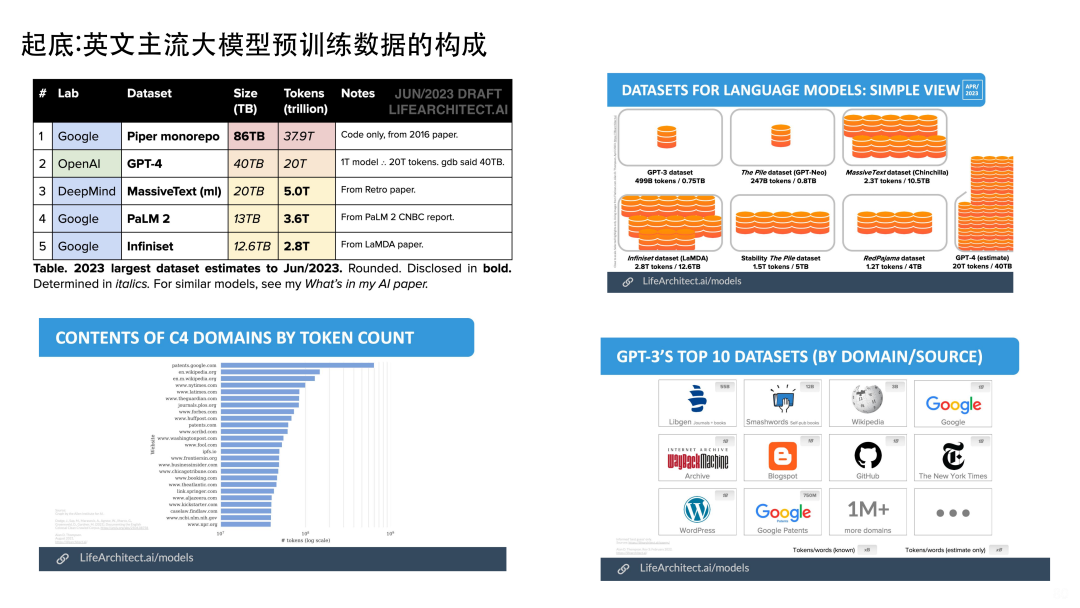
GPT-3有一个很重要的数据集叫Common Crawl,从Common Crawl中通过清洗的方式可以获取英语语料比如C4,C4中很多数据都是专利数据(patents.google.com)。我们再看一下GPT-3 TOP10 的一些Datasets,包括Wikipedia、Google、Libgen等。

上图列出了几个预训练数据内部构成:
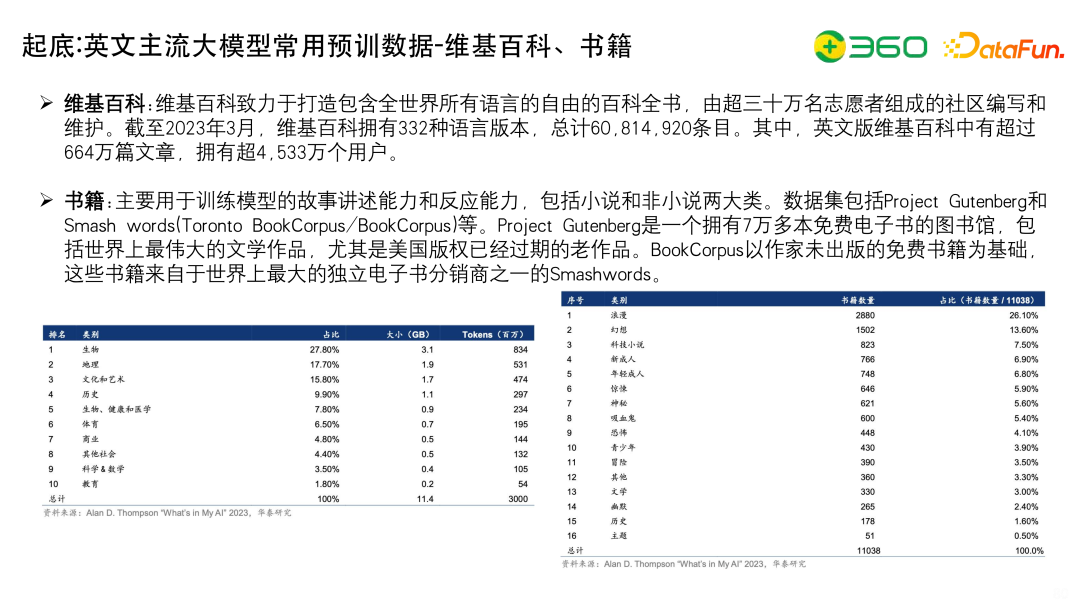
上面列出了英文常用的预训练数据-维基百科、书籍。

上面列出了英文常用的预训练数据-论文期刊。ArXiv有2000多万的文章,都可以下载到。
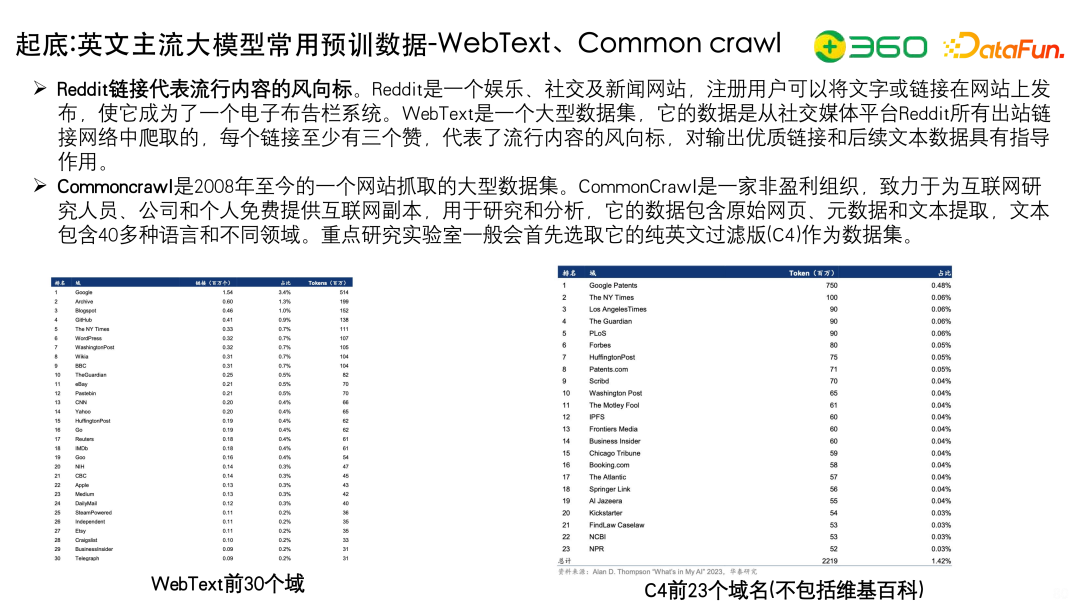
上面列出了英文常用的预训练数据-WebText、Conmmon Crawl。也是大家可以下载到的。
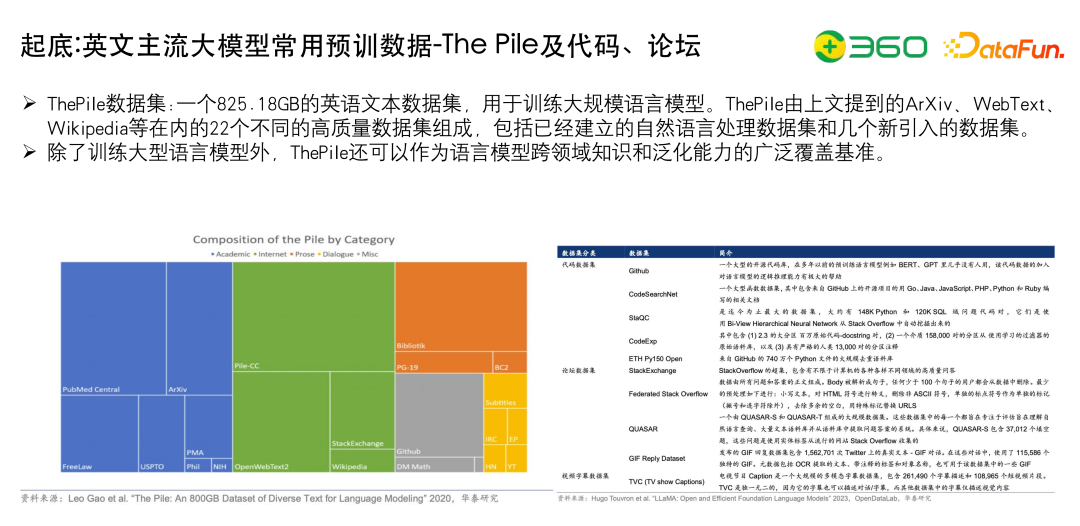
上面列出了英文常用的预训练数据The Pile及代码、论坛。左下是Pile数据集的内部分布。代码数据集公开的比较多,能下载到的有上T级别的。
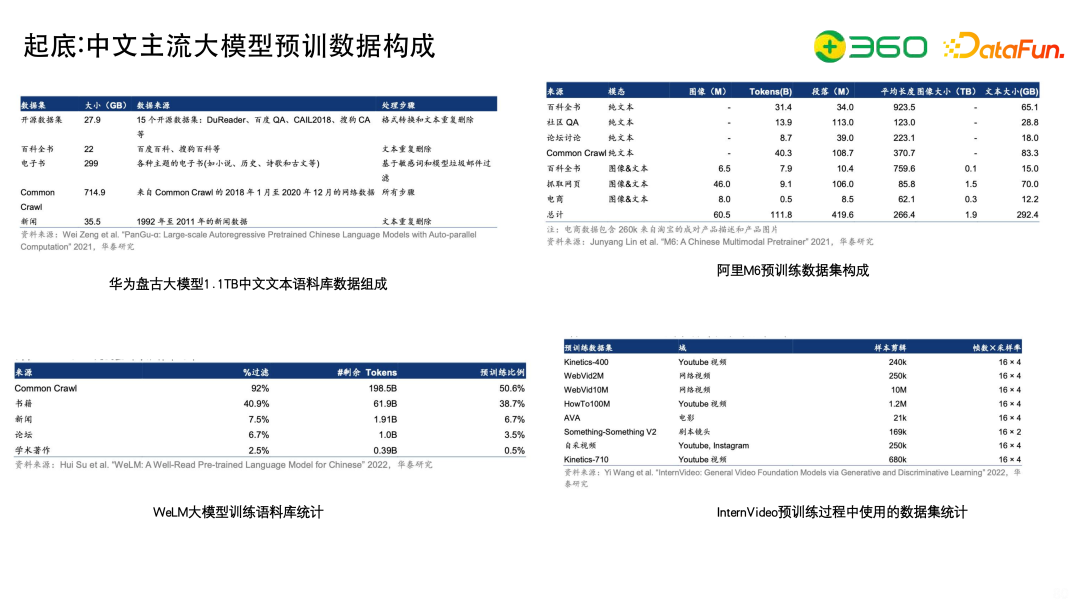
下面介绍一下中文主流大模型预训数据构成,目前中文的开源数据集和英文相比差距还是比较大的。
阿里的M6大模型用到百科全书、社区QA、论坛讨论、Common Crawl等,还有一些和业务结合的电商数据。
WeLM的数据构成更像GPT,包括Common Crawl、书籍、新闻、论坛、学术著作等。
InternVideo是多模态模型,会用到网络视频,YouTube视频、电影等。
大家可以看到,在多样性上和英文相比会存在比较大的缺陷。
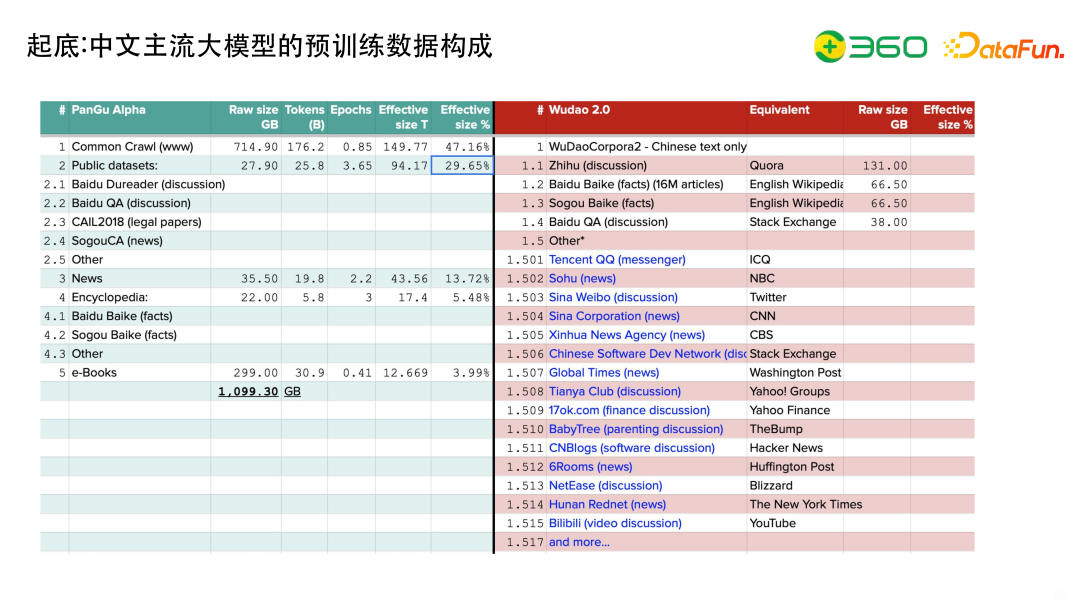
详细看一下预训练数据的构成:
左边是PanGu Alpha 【盘古】,有47.16%是Common Crawl,有29.65%的Public Datasets(刚才提到的各种公开的测试集),对于这种高质量的评测数据,训练时Epochs数可以更多,而CommonCrawl的Epochs 数更少,进行降采样。
右边是Wudao2.0【悟道】,Wudao也是大家可以拿到的开放数据。悟道里有知乎、百度百科等,当然也其他网站,包括腾讯、搜狐的数据。从Raw Size维度看,知乎数据只有131 GB。
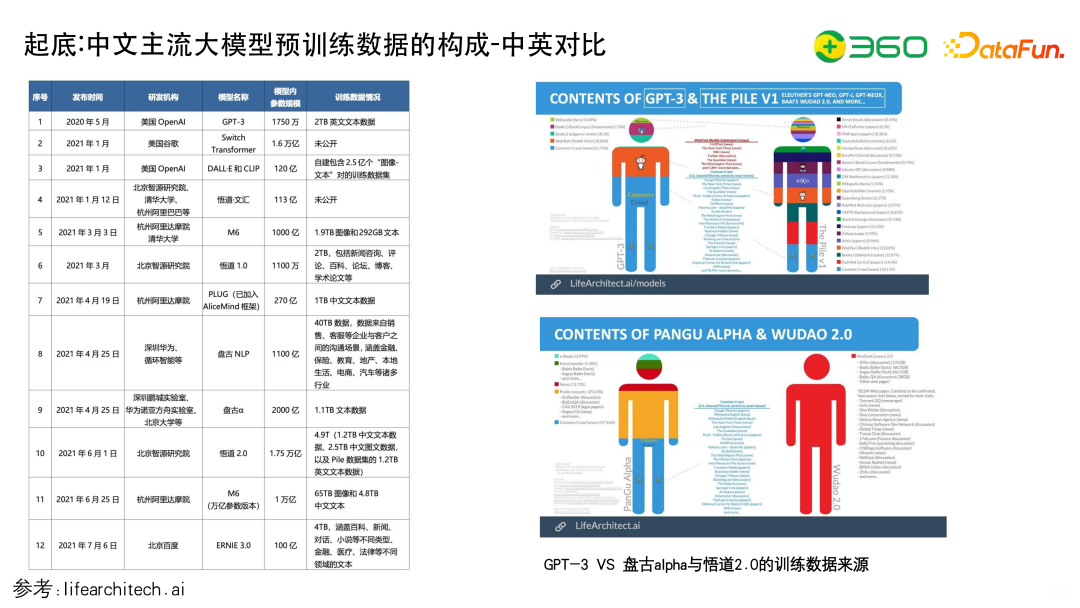
上图主要列出了大模型预训练数据构成中的中英对比,右图可以从颜色看到一个区分度,英文不同的来源的区分是特别细的,而中文来源的区分是比较粗的,存在比较明显的差别。

如果要复现GPT-4、GPT-3等模型,通常会从语料上找中英文数据集之间是否存在映射关系。
可以看到,中文的知乎对应英语的Quora;百度百科对应English Wikipedia,但有个很大的问题是中文的百科对比英文的维基百科,训练数据的质量是没有那么好的,英文的Wikipedia里面包括各种参考文献,特别丰富的而且权威性比较高,它都会注释来源于哪,而且包含多个版本,所以在百科这个方面存在一定差距;搜狐News对应NBC;腾讯QQ对应 ICQ;另外还有一些比较垂域的,比如17ok.com(finance discussion)对应Yahoo Finance 等。

讨论了中英对应并找到差距之后,继续讨论一下如果要做好的模型,应该准备怎样的预训练数据?从源头上去讲,语言模型质量要求如下:
这些也可以看作是评价模型的标准。
达到质量要求后,可以得出大模型需要高质量、大规模、多样性的数据。
(1)高质量
(2)大规模
预训练的数据量越多,大模型的拟合能力就越强,效果就会越来越好。如果数据规模太小的话,模型学的东西不会多,记得也不够深。
(3)多样性
数据丰富性能够提高大模型的泛化能力,模型预训练数据足够多,其生产内容也能更多样。在准备预训练数据的时候尽可能准备更多的数据,数据多了,模型的泛化能力就会更强;而且数据足够丰富,在训练时就不会偏向某一类,导致过拟合问题的出现。所以需要对预训练数据做严格的去重,有各种花式的玩法。
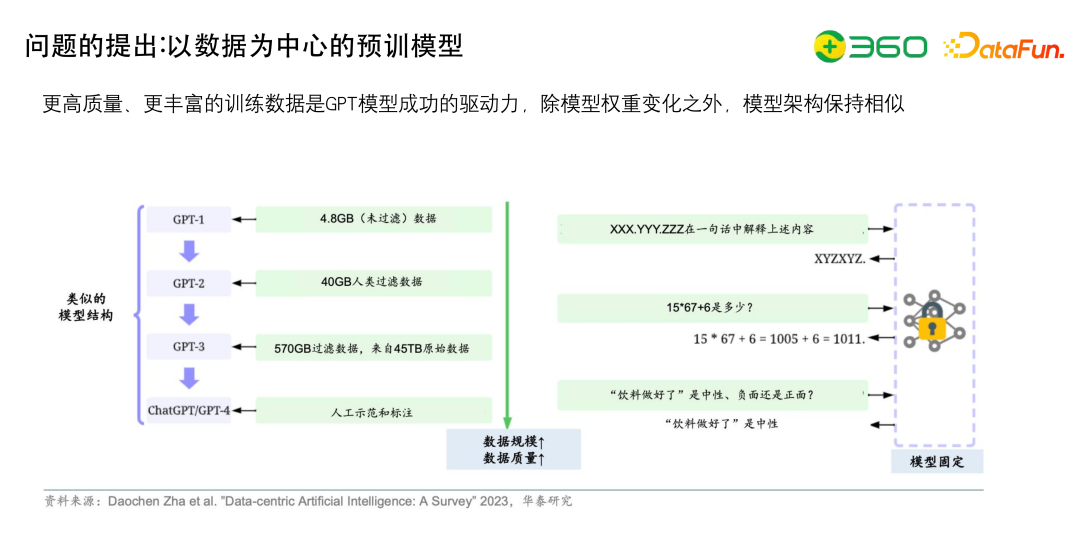
找到数据之后,需要最多的处理就是去重,比如GPT-1有4.8GB未过滤数据,GPT-2有40GB人类过滤数据,GPT-3有570GB过滤数据(来自45TB原始数),过滤数据很重要的。
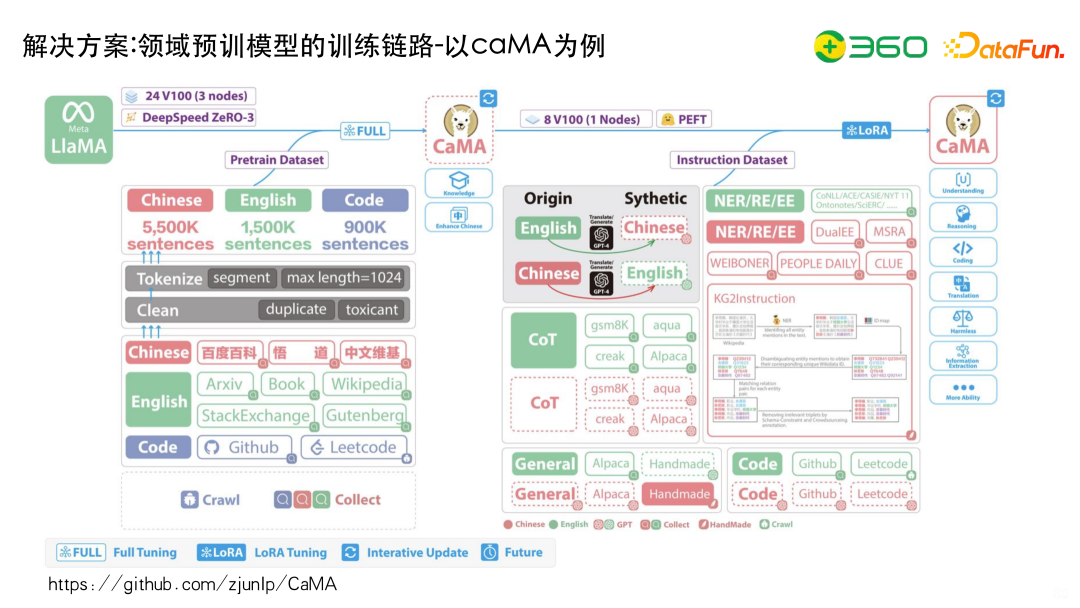
这里以浙江大学CaMA模型为例,为大家展示如何从数据端去完成一个领域模型。
浙江大学在LLaMA的基础上做了两个工作:
为了增强LLaMA的中文能力,做了很多数据上的处理,比如怎么去拿数据。Code主要收集 GitHub 和Leetcode的数据;英文主要收集ArXiv,Book,Wikipedia等英文的数据;中文主要收集百度百科、悟道、中文维基等等。
我们要保证它的多样性,从语种上有中英文;从类型上有代码、文本;在领域上有百科、维基等。
拿到数据之后做两个事情:
微调阶段如何构造高质量的微调数据?比方General,用52K的数据做各种翻译等等;还有去做一些 COT的东西,比如说gsm8K、aqua、Alpaca等COT的数据。拿到这些数据之后,我们可以去用ChatGPT做泛化。因为CaMa是做KG相关的,所以它会用很多的任务数据或者说命名实体识别的数据、关系抽取的数据以及事件抽取的数据,与泛化后的数据一并放进去进行tuning,得到一个比较好的效果。
通过上面的描述可知,无论是在pretrain阶段【预训练】还是在SFT阶段【微调】,数据都是很重要的,而且数据需要尽可能的多样、尽可能地清洗,对模型的提升是有意义的。
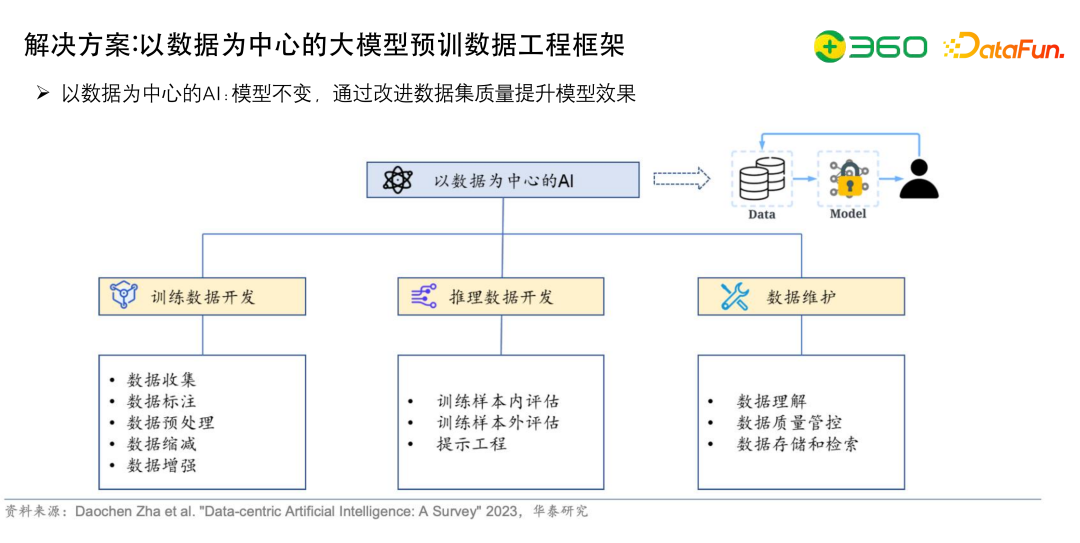
上图展示了以数据为中心的的工程框架,包括之前提到的训练数据开发、推理数据开发、数据维护等。
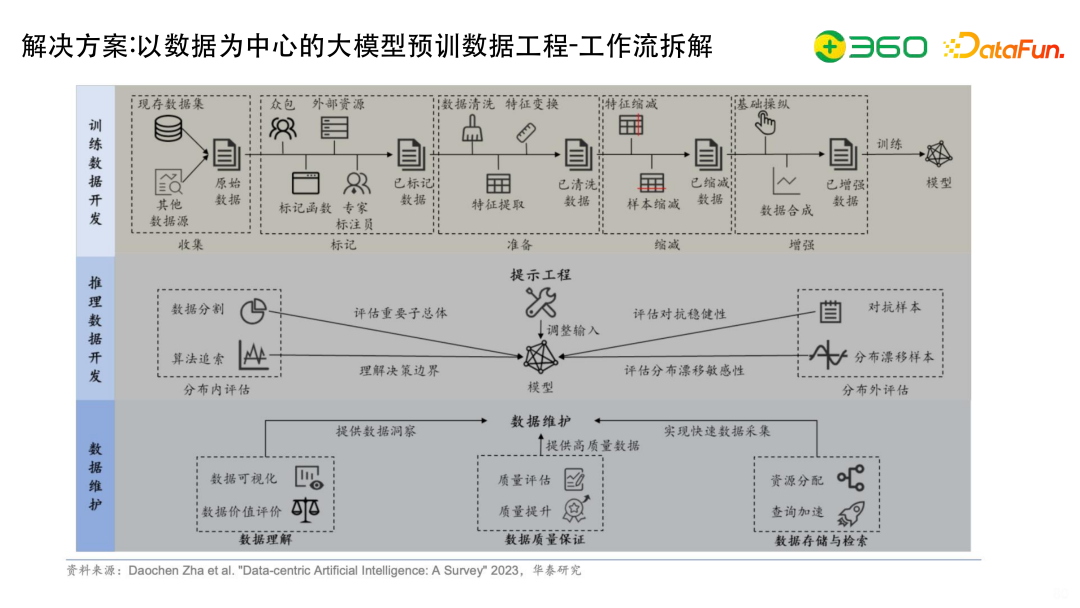
以数据为中心的大模型预训练数据工程的工作流可以拆解为很多环节:
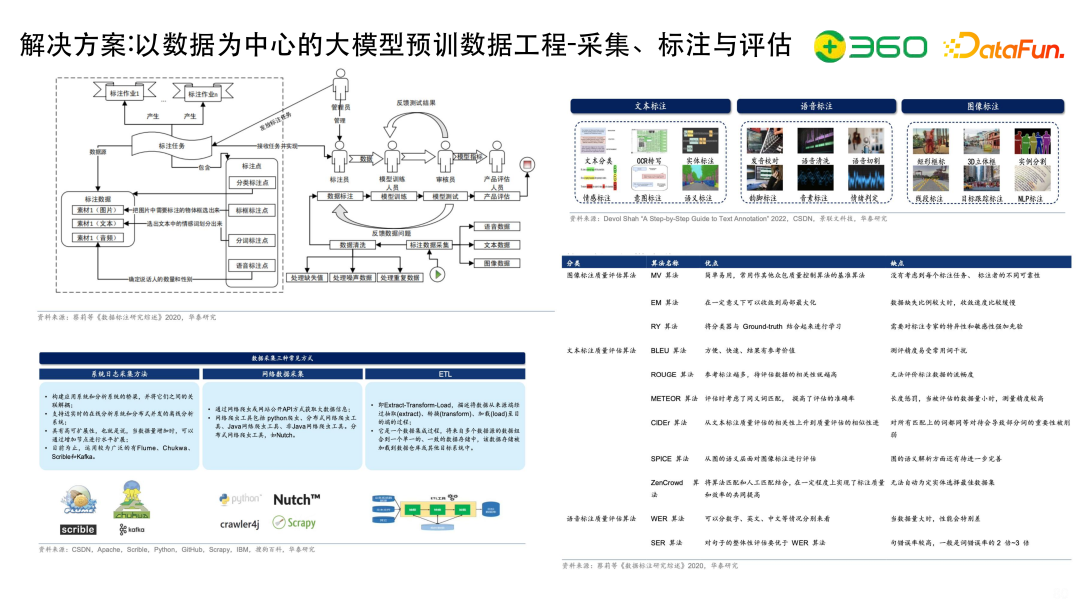
需要针对不同数据制定好的标注标准,包括文本标注、语音标注、图像标注等。
如何衡量标注数据集的质量是很重要的。现在有很多的算法,比如图像标注质量评估的MV 算法、文本质量评估的BLEU算法等,根据不同的语音文本以及视频,有不同的衡量算法,帮助大家衡量数据标注的质量。
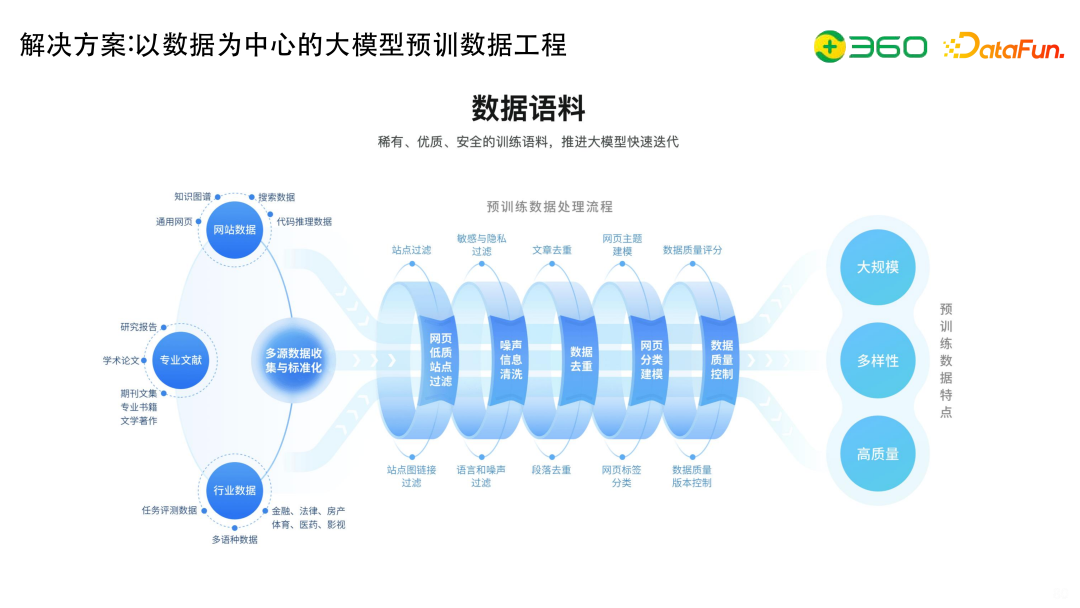
上图展示了具体实现的时候处理数据的大致流程:
我们的数据主要包括网站数据、专业文献以及各个行业数据。
为了实现数据的大规模、多样性和高质量,大致的流程包括如下几步:
一、站点过滤,站点过滤的方法也有很多,就包括基于图的过滤方法、基于单点的过滤方法、基于规则的过滤方法等;
二、敏感与隐私过滤,语言或者噪声过滤等;
三、文章去重,做不同粒度的去重;
四、网页主题建模,要提升多样性,主题就一定要好,所以会做大量的主题挖掘的工作,这里搜索有天然的优势;
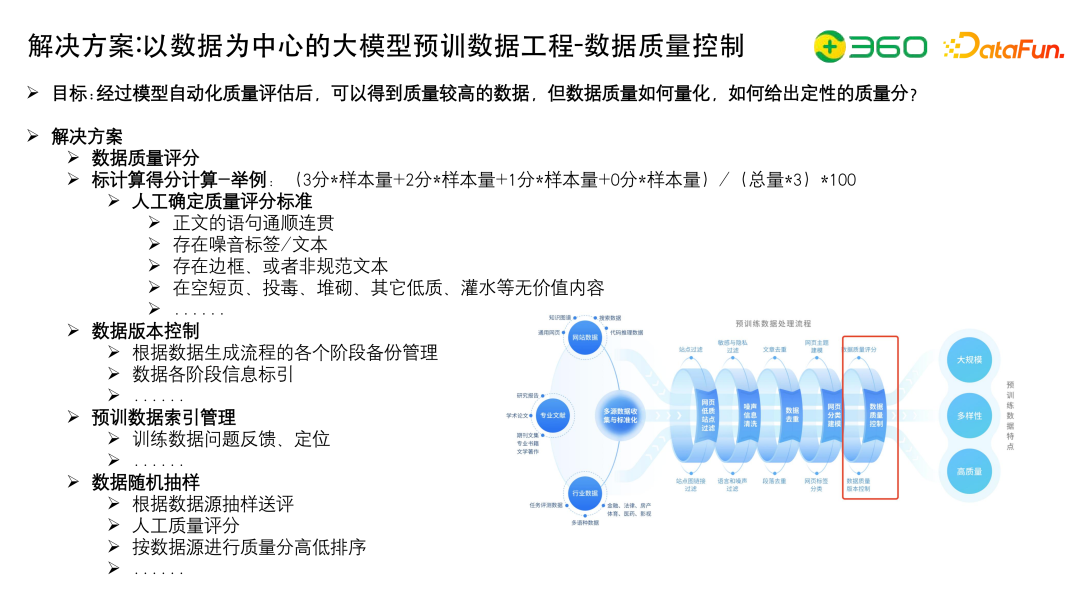
五、数据质量评分,包括数据质量版本控制等。
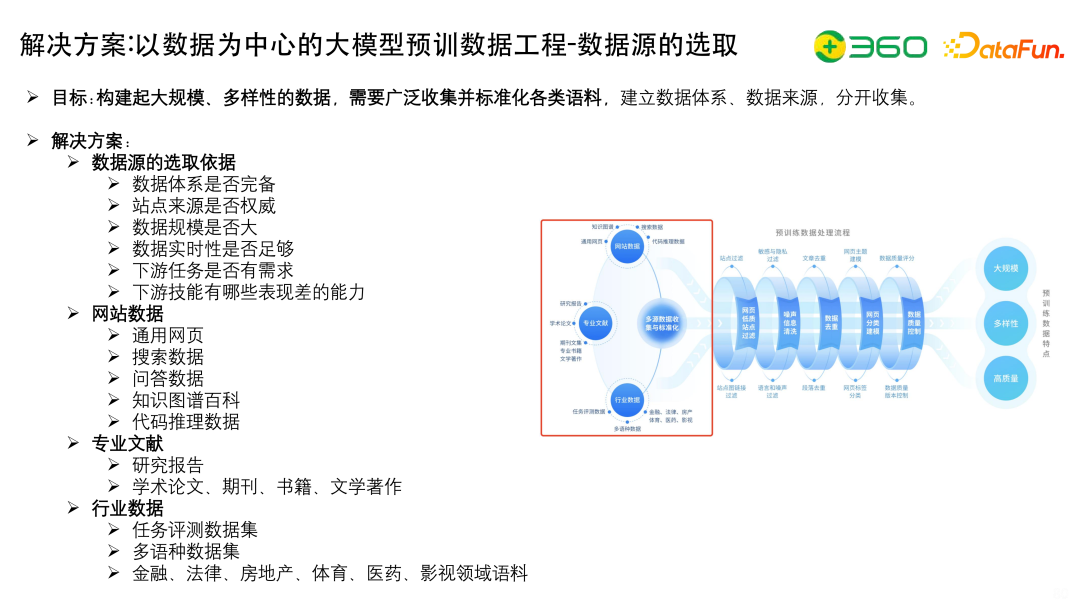
数据源的选取依据有很多,包括:
网站数据,包括通用的网页数据、搜索数据、问答数据、知识图谱百科、代码推理数据等。
专业文献,包括研究报告,学术论文、期刊、书籍、文学著作等。
行业数据,包括任务评测数据集,多语种数据集,金融、法律、房地产、体育、医药、影视领域语料等。
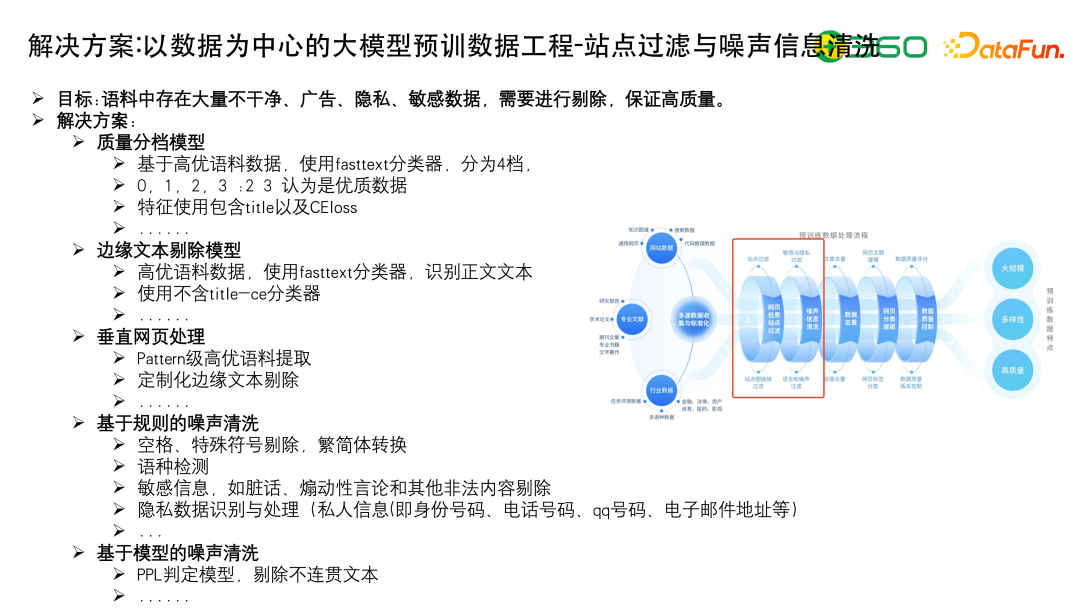
站点过滤和噪声信息清洗有很多方法。
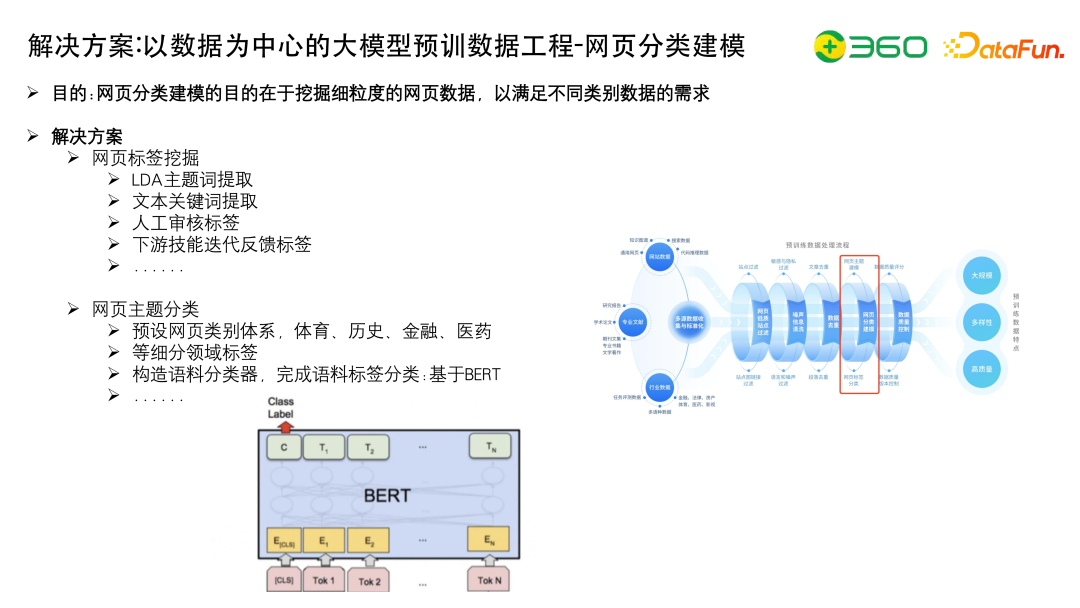
网页分类建模的目的是挖掘细粒度的网页数据,以满足不同类别数据的需求。
给网页标注比较好的tag的方法有很多,要么做分类,要么做聚类。如使用LDA主题词提取、文本关键词提取、人工审核标签、下游技能迭代反馈标签等。
网页主题分类,预设网页类别体系,包括体育、历史、金融、医药等几十类别的体系,细分领域标签,然后构造语料分类器,基于BERT完成语料标签分类。

以DoReMi的工作为例,讨论一下预训练数据采样。
先初始化数据分布,训练一个小参数模型,比如使用The Pile的原始分布,训练一个小模型;训练小模型之后我们再使用群体分布稳健优化(GroupDRO)对领域进行训练,更新领域权重;最后使用迭代好的领域权重对数据集重新采样,训练一个更大的、全尺寸的模型。

微调数据生成方式:
(1)基于人工标准,使用较多
(2)基于大模型进行数据蒸馏
上面右图是人大的工作,对于收集到的开源指令集,先去重,然后做主题上的分布,最后进行清洗和多样性控制。
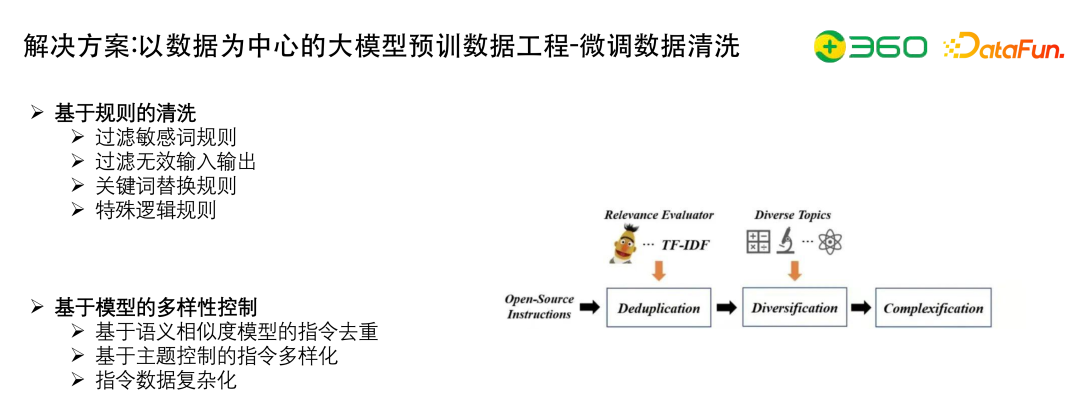
基于规则的清晰,可以应用如下的规则:
基于模型的多样性控制,包括:
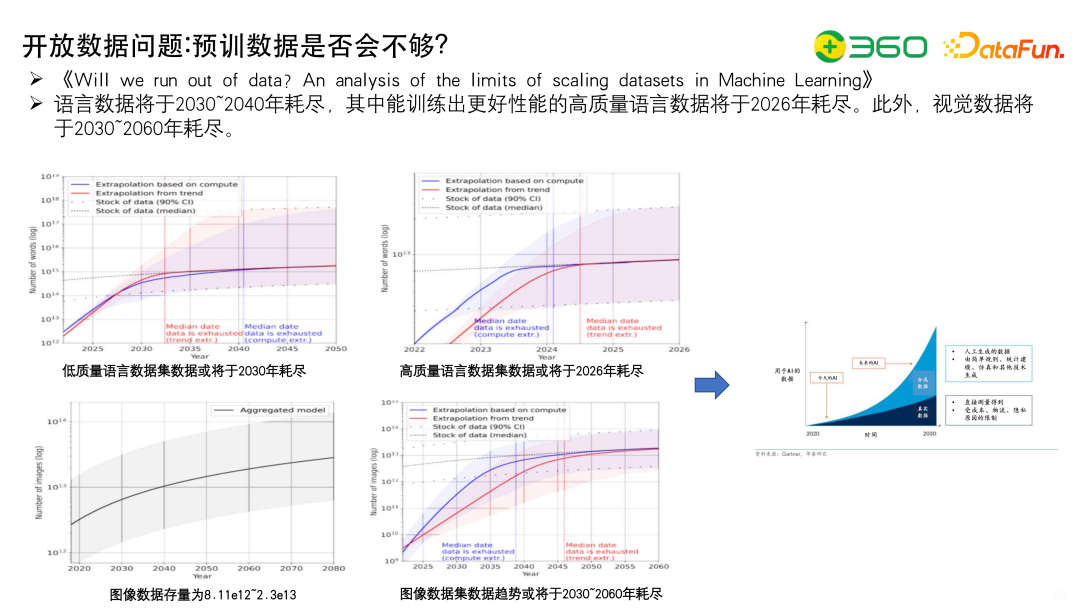
关于现在预训数据到底够不够的问题,报告《Will we run out of data? An analysis of the limits of scaling datasets in Machine Learning》中提出了一个有趣的观点:语言数据将于2030~2040年耗尽,其中能训练出更好性能的高质量语言数据将于2026年耗尽。此外,视觉数据将于2030~2060年耗尽。大家可以仔细研究一下这个报告。【还以为是视觉中国呢】
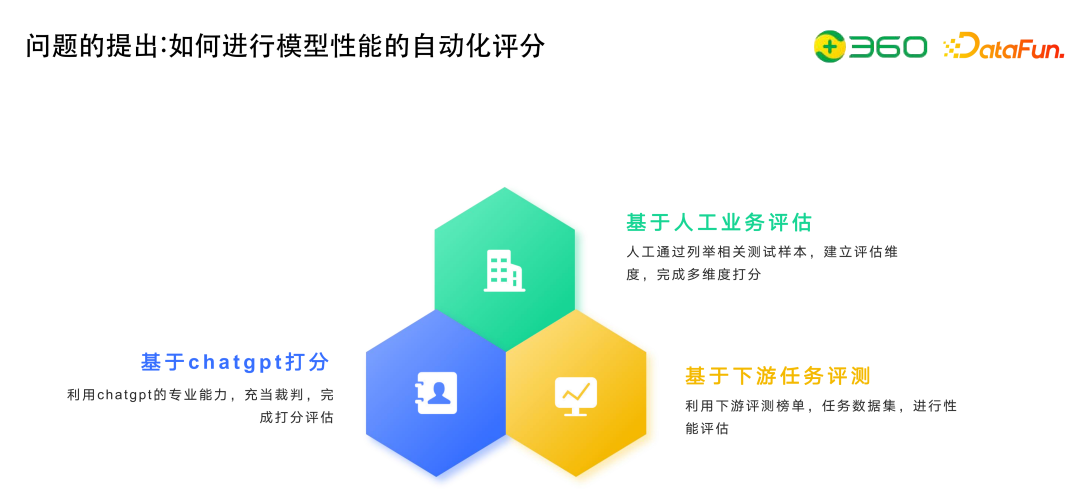
模型性能的自动化评估基本上有三种方式。

现在就会有很多人用ChatGPT打分。我们给出一个问题,再给出一个答案,然后告诉ChatGPT,这里有这样一个问题和答案,打分区间是一到零分,请问该答案可以打多少分并给出打分依据。Vicuna 采取了这种评估方案。
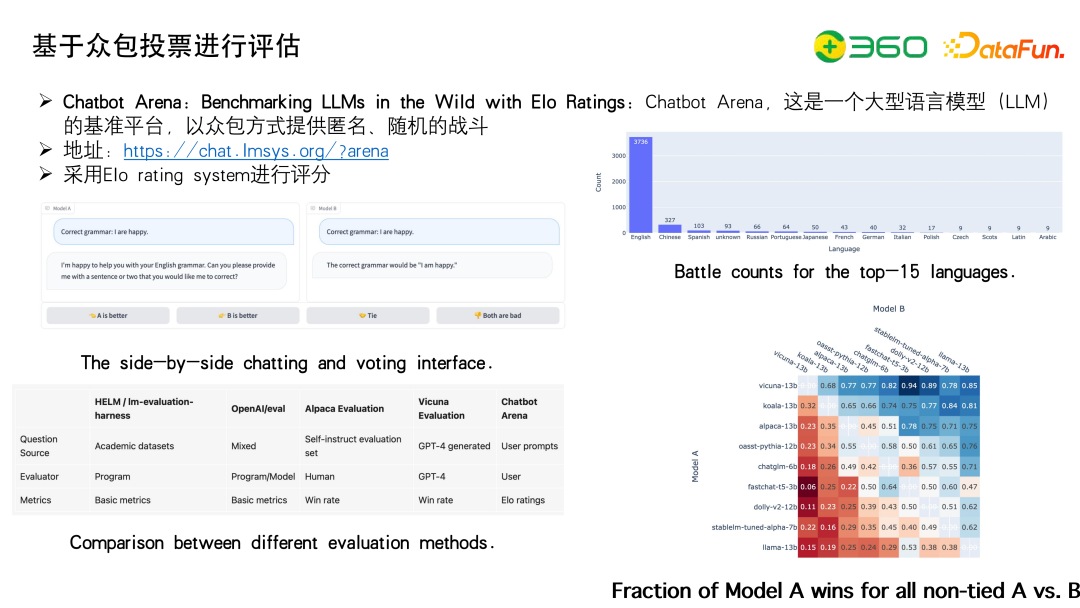
另外一种方式就是众包。用众包的原因是用GPT自动评估的方式主观性是很强的,而且数据集也不够多,所以需要大家一起来打分,产出一个琅琊榜。Arena这个琅琊榜,首先给一个问题,然后各个模型给出答案,通过大家投票,采用Elo rating system进行评分。
中文其实也有,中文在英文的基础上产出了一个版本叫琅琊榜。

目前基于下游评测任务进行评估出现了一个风向,就是使用专业的考试题,包括Google BIG-bench、MMLU、C-EVAL、M3KE等评测数据,或者去卷专业考试。
这样的方式是合理的,如果要做一个垂域的模型,如何去验证模型在垂域上的能力呢?比如说法律有律师从业资格考试,或者说专利有对应的资格考试,这也使得模型和业务有了很好的融合。
下面与大家讨论一下大模型与知识图谱的结合。
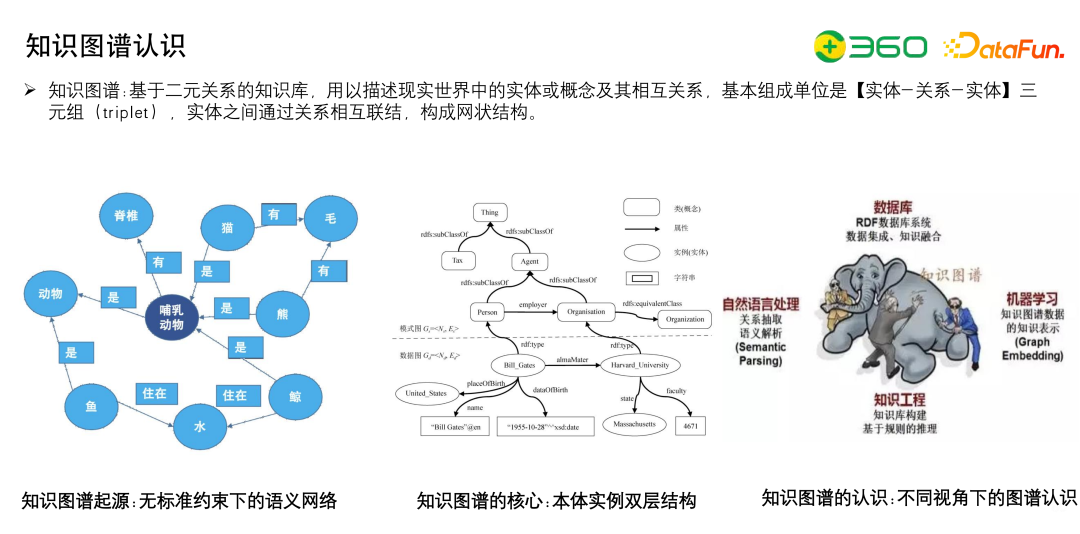
首先看一下知识图谱,现在有种论断,大模型之后知识图谱的重要性严重下降了,知识图谱的定位也变得不太清晰。
以我的个人理解来说知识图谱最大的优势在上面左边的两张图中。
第一个图是知识图谱的图结构,知识图谱通过知识以图的形式做表示,因此可以完成Graph Embedding、路径搜索等算法,大模型在这方面有一定缺陷。
第二个图是知识图谱在一些组织上的优势,比如知识图谱通过Schema规范结构化数据的表达, 知识图谱提出来是为了解决业务的在垂域中知识的组织和管理问题,虽然大模型可以端到端地生产知识,但这些知识是没有体系的。可以把体系化的知识图谱和大模型结合,大模型生产数据,知识图谱组织数据,更好的完成目标。另外,知识图谱拥有垂域的一些数据,这些数据可以用于去检验大模型事实上的错误。

知识图谱与大语言模型的共同点:
知识图谱与大语言模型的不同点:
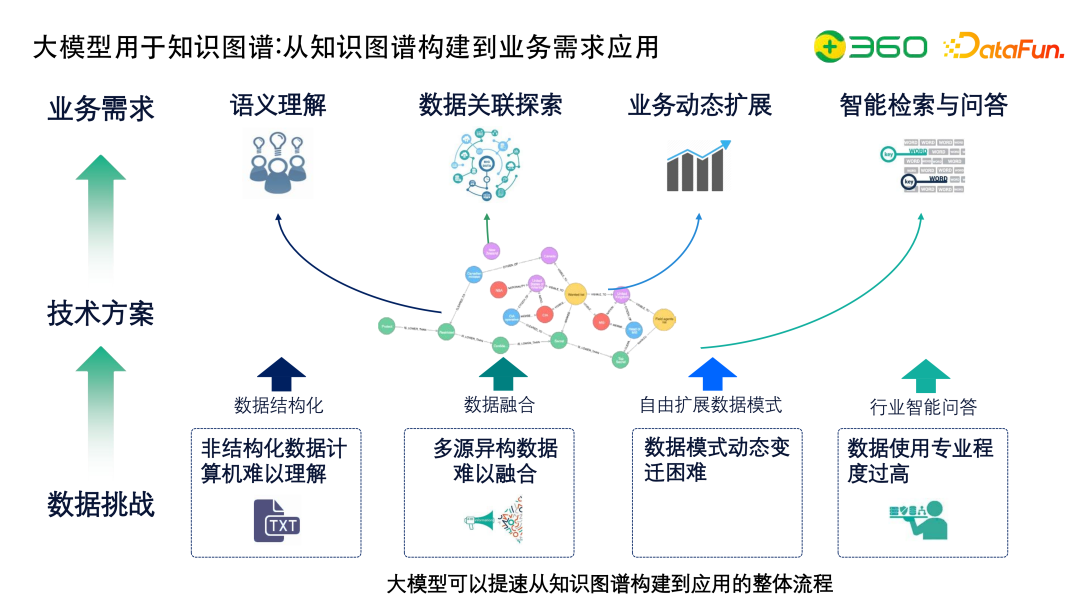
大模型用于知识图谱可以重构上图的整个状态,比如进行数据结构化、数据融合、扩展数据模式或者行业智能问答等工作,大模型可以加速而不是替代知识图谱构建的环节,包括应用大模型做问答、抽取等。
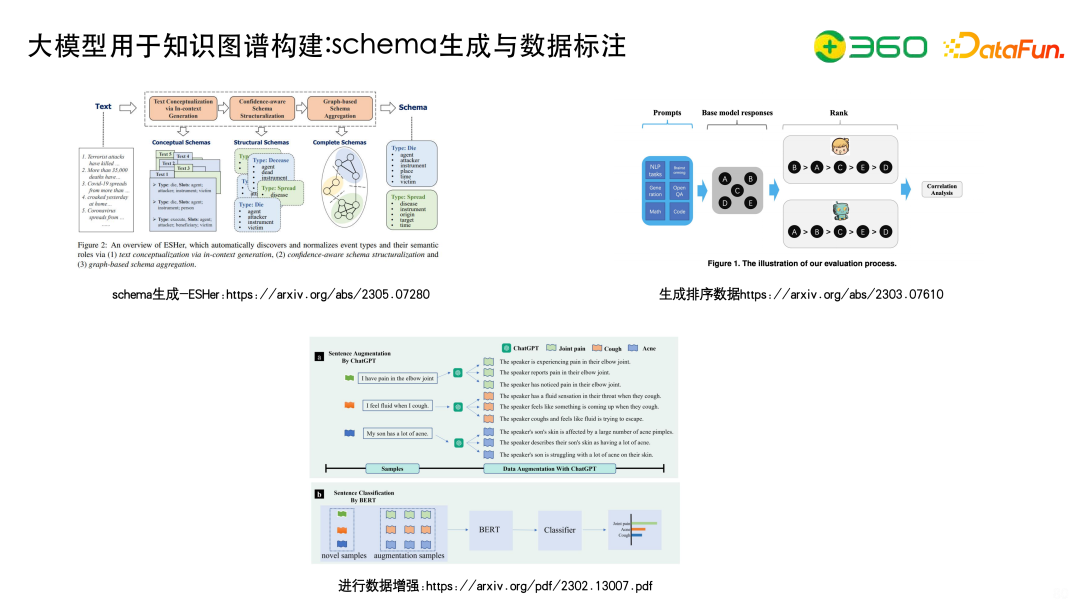
大模型可以用于知识图谱构建中的schema生成与数据标注部分。
大模型完成Schema的生成。ESHer是中科院软件所的工作,使用大模型Prompt生成事件的Schema,再从Schema实现打分函数,通过聚类社区发现得到相应的事件以及对应的槽。
大模型可以生成排序数据,进行数据增强。大模型之前我们通常用 EDA做数据增强,现在其实完全可以用 ChatGPT 改写的方式生成大量的标注数据,降低知识图谱标注端的成本。
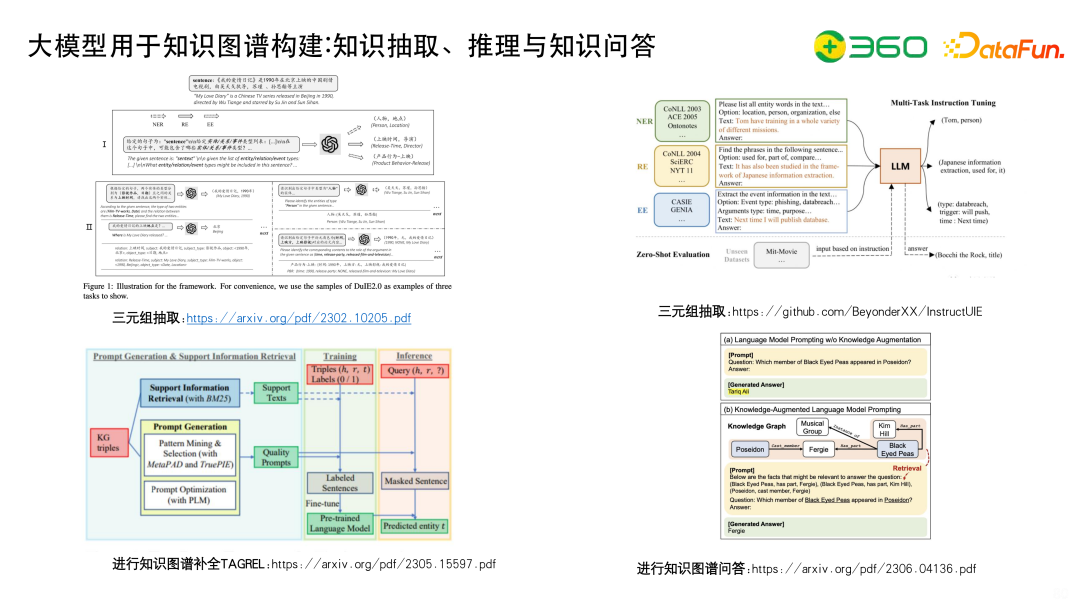
大模型在知识图谱构建的知识抽取、推理与知识问答方向也可以发挥作用。
如左上图的三元组抽取,先做NER抽取,再做关系抽取。
右上图的工作是InstructUIE,在之前 UIE 的基础上,统一这个方式,约定输入和输出的格式,让LLM进行三元组抽取。
左下图是用大模型去做知识图谱的补全,通常知识图谱补全需要定义 score function,比如360之前用知识图谱挑战OGB的时候就创新了一个新的score function,现在可以用大模型直接做排序任务。
右下图使用大模型做知识图谱问答,有些问题大模型不一定能回答,但是如果加上一些实体链接,到图谱里把子图给召回出来,拼接成上下文,构成提示语让大模型去做推断,能够起到减轻大模型幻觉的作用。

探讨一下知识图谱能够用于大模型研发的三个阶段。
(1)训练前阶段
(2)训练中阶段
(3)训练后阶段

在预训练阶段,可以用模板化去生成事实性的描述文本。
在微调阶段,可以根据模板来生成问题,用self-instrcut的思路(重点在于多样性)。比如左下的中心词,我们可以用模板的方式生成右下方的QA对。比如Lawyer LLaMA这样的法律领域的行业模型,大家会通过这样的方式结合知识图谱生成大量的SFT数据。

这里讨论下融合知识的预训练模型,包括用特征融合、嵌入融合、数据结构统一、知识监督或者基于检索等都是可以实现的。
核心点有两个:
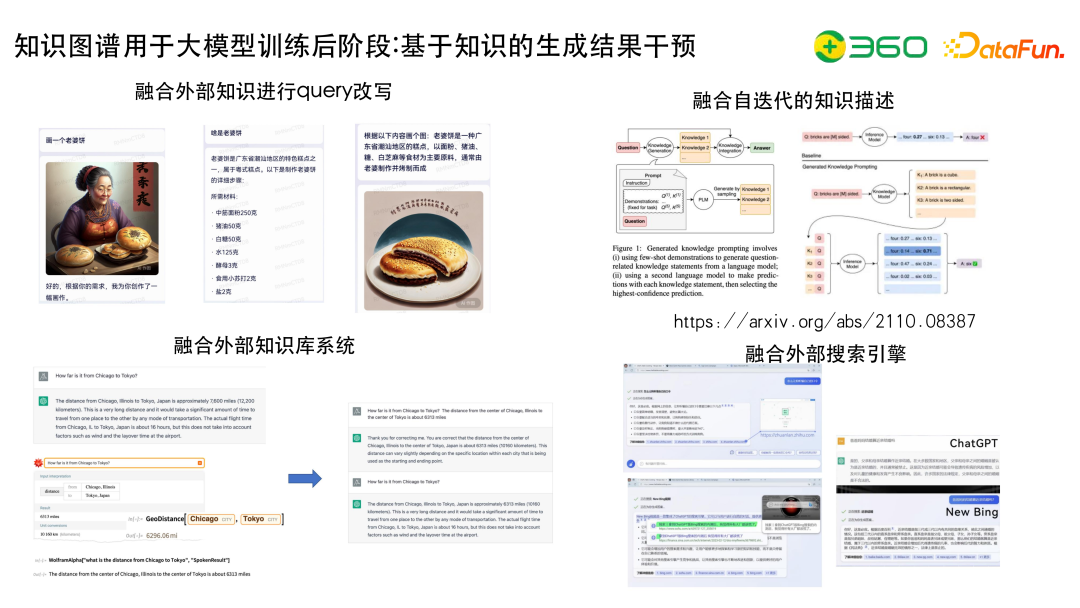
左上图有一个比较好的例子,画一个老婆饼,某AI会画出一个老婆婆和饼,如果AI可以拿到老婆饼的比较好的描述,得到的效果会得到改善。
右上图描述了融合自迭代的知识描述,为了做问答,在Question的基础上结合知识图谱生成比较好的description,然后再放进去,可以比较好地解决一些问题。
左下图描述了融合外部知识库系统,ChatGPT在数学计算方面,比如被提问芝加哥到东京到底有多远的时候,回答的可能并不精准,这时可以外挂一些工具,比如WolframAlpha能够解决这些问题,两者结合起来,可以更好的解决问题。
右下图描述了融合外部搜索引擎,目前大模型普遍时效性不够好,为了解决时效性问题,需要借助比较有实时性的工具,比如搜索引擎。搜索引擎可以调用索引的相关性,获取top的结果,封装到prompt中。另外,融合搜索引擎可以解决大模型结果不可信的问题,比如NewBing会通过"了解详细信息"的来源来为大模型输出的结果进行增信,也便于用户可以快速的进行验证。不过,有的时候会发现NewBing和ChatGPT引用的链接很多都是空的、假的,所以后面还需要考虑如何提高生成链接的准确性。
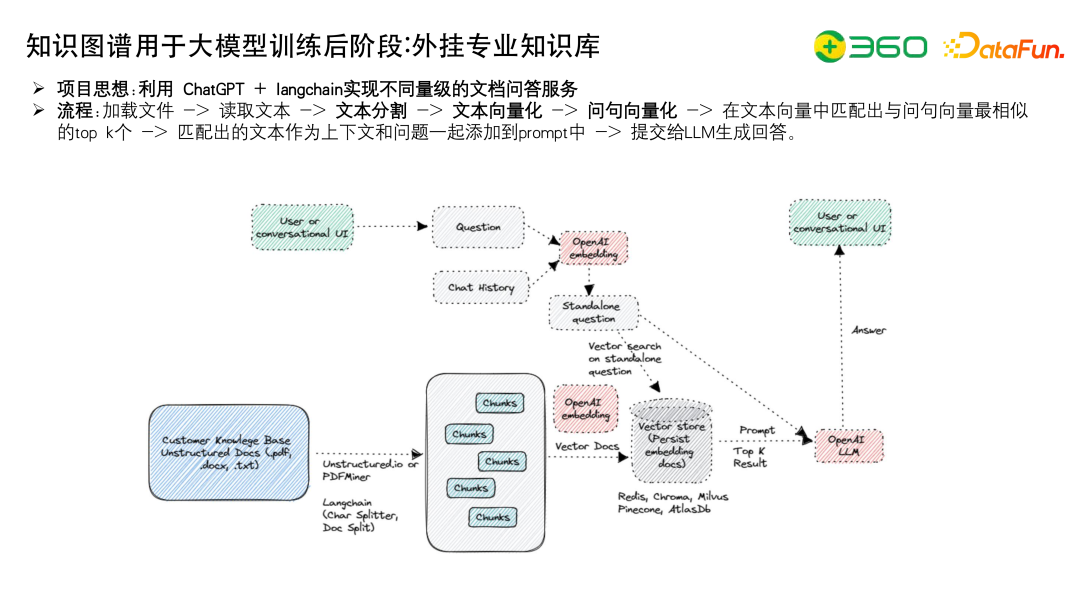
最后介绍一下目前知识图谱用在大模型训练后阶段的外挂专业知识库,目前在行业中是用的最多的,其主要流程是:
目前的难点,一个是在于如何拿到好的文本向量化模型,比如最近比较火的M3E、SimCSE、Text2vec等;另一个是读取文本,如何比如说表格数据如何组织,例如用Latex的表示方式,各种富文本包括图片的展示等等。
最后总结一下大模型的未来发展方向。

大模型的未来发展发现主要有如下几点: