如何在自己的计算机上安装类似 ChatGPT 的个人 AI 并在没有互联网的情况下运行它
本文旨在为任何人安装此软件。最初它有一个视频,伴随着操作方法,但是事情变化很快,我的三次尝试只是推迟了我发表这篇文章。我以后可能会包括它。我努力创建一个简单的分步说明,为极端新手安装个人 AI。可能从未去过GitHub并且从未使用过终端的人。如果你是有的人,那么这篇文章很可能不适合你。您可能会发现我们已经构建的一些本地模型,并将很快发布,以使其更有趣。如果您是安装软件的专家,请将精力集中在帮助他人和社区上,而不是“谁不知道”或“我知道,他只是在写......”有点评论。用你的力量和技能把我们都提升得更高。
个人 AI 的“第一台 PC”时刻
这是个人AI的“第一台PC”时刻,随之而来的是限制,就像在车库里生产第一台Apple 1一样。你是先驱。今天,任何人都可以使用私人和个人AI。您可以在自己的计算机上运行类似 ChatGPT 的功能版本,并且在安装后不需要将其连接到互联网。
所有人类知识都是已知和未知的综合。人工智能用作正力多路复用器和您的智力放大器,您的个人人工智能很好地帮助您和我们所有人克服这一差距。有了你的个人人工智能和正确的超级提示,人类将以前所未有的方式蓬勃发展。此刻你唯一需要的就是知道这一点的力量,并把它拿在手中去处理它,因为你想为你和你爱的每个人看到这个世界。它不是AI,而是IA(智能放大)。
我们今天将介绍的系统(我将写更多)可以在最新且典型的但不是高性能 CPU 上运行,具有 8GB RAM 和仅 4GB 磁盘空间。是的,整个模型,在仅4GB的磁盘空间中包含了大量的人类知识语料库。有限制吗?答案是肯定的。它不是 ChatGPT 4,它不会正确处理某些事情。然而,它是有史以来最强大的个人人工智能系统之一。它被称为GPT4All。
GPT4All是一个免费的开源类ChatGPT大型语言模型(LLM)项目,由Nomic AI(Nomic.ai)的程序员团队完成。这是许多志愿者的工作,但领导这项工作的是令人惊叹的Andriy Mulyar Twitter:@andriy_mulyar。如果您发现该软件有用,我敦促您通过与他们联系来支持该项目。GPT4All 基于 LLaMA 7B 模型构建。LLaMA代表大型语言模型元(Facebook)AI。它包括从 7 亿 (7B) 到 65 亿个参数的一系列模型大小。Meta AI 研究人员专注于通过增加训练数据量而不是参数数量来扩展模型的性能。他们声称 13 亿个参数模型的性能优于 GPT-175 模型的 3 亿个参数。它使用转换器架构,并通过网络抓取维基百科,GitHub,Stack Exchange,古腾堡项目的书籍,ArXiv上的科学论文提取了1.4万亿个代币。
Nomic AI团队对LLaMA 7B和最终模型的模型进行了微调,并在437,605个后处理助手式提示上对其进行了训练。他们从另一个名为Alpaca的类似ChatGPT的项目中获得灵感,但使用OpenAI API的GPT-3.5-Turbo收集了大约800,000个提示响应对,以创建437,605个助手式提示和世代的训练对,包括代码,对话和叙述。然而,800K对大约是羊驼的16倍。该模型最好的部分是它可以在CPU上运行,不需要GPU。像羊驼一样,它也是一个开源,可以帮助个人进行进一步的研究,而无需花费商业解决方案。
详细的模型超参数和训练代码可以在 GitHub 存储库中找到,https://github.com/nomic-ai/gpt4all。开发 GPT4All 大约需要四天时间,并产生了 800 美元的 GPU 费用和 500 美元的 OpenAI API 费用。此外,最终的gpt4all-lora模型可以在大约100小时内在Lambda Labs DGX A8 80x 8GB上进行训练,总成本为100美元。
GPT4All 将其困惑度与最知名的羊驼-lora 模型进行了比较,并表明与 Alpaca 相比,微调的 GPT4All 模型在自指导评估中表现出较低的困惑度。但是,由于鼓励用户在本地CPU上运行模型以获得对其功能的定性见解,因此此评估并不详尽。

Nomic AI团队在几天内完成了所有这些工作,并且仅在4GB的磁盘空间中完成。它是免费和开源的。重要的是要知道所有本地化的个人人工智能模型和软件都是非常新的,通常不是为普通人设计的。它是开源的,没有“客户服务和支持”。安装通常是“转到 Git Hub 并克隆它”。因此,这是早期的先驱者时代,因此您需要耐心等待。回报是你自己的个人AI。我觉得个人人工智能是一场革命,相当于汽车的发明。直到亨利·福特(Henry Ford)让汽车触手可及,人类才打破了阻碍我们的界限。这就是我写这篇操作方法文章的精神,我希望它可以帮助即使是技术上最具挑战性的人也能获得这个新工具。
但为什么要有个人人工智能呢?会有无穷无尽的原因,但有些是:
还有许多其他原因,几乎没有一个是出于“不良目的”。如果一个坏人想问“坏”的事情,有比本地人工智能更容易的方法。但是,使用下面模型的SECRET版本,您可能会对某些结果感到冒犯。它旨在提供没有过滤器的原始结果。您可以在模型之间切换以衡量其编辑方式。因此,如果您很敏感并且通常很容易被冒犯,这是一个警告,请不要下载SECRET版本。如果你想看看LLM AI是如何“理解”你和我实际生活的世界,我建议使用SECRET版本,而它仍然可用。
您将拥有自己的AI,您不必对任何人负责,但要回答自己
这个帖子有点像一个实验。当然,你可以去很多地方获得GPR4All。我只为会员发布内容有一些原因。一个原因是责任。出于某些原因,我有点犹豫要不要在这里发布这个。当你将人工智能用于任何目的时,要理智,要有荣誉和尊严。这既是石蕊测试,也是罗夏测试,测试你是谁,你在生活和成熟中的位置。如果你觉得有必要做“人工智能说了一件坏事”之类的事情,那就去做吧,但要知道你只是为了确保人工智能在未来你和你的孩子的某个时候不会是免费的和本地的。这是责任,它完全在你的肩膀上。我认为您可以在私人计算机上做任何您喜欢的事情。我认为在社交媒体上分享任何有意义的、有意义的、有真正目的的东西都是可以的。然而,另一方面,我们大多数人可能会认为任何让人工智能“危险”的人都是为了一个目的而支撑起来的,这个目的很可能是为了“安全”而创造“监管人工智能”的条件,我们中的一些人会评判你并记住你。我们的人工智能也是如此。如果你觉得自己没有能力变得理智,没有荣誉和尊严,为了你的家族血统让你来到这里,要么长大,要么继续前进,玩别的东西。欢迎所有其他人探索。不知道还能怎么说,但不得不说。
您将拥有自己的AI。
在任何100 +笔记本电脑的硬盘驱动器中对新的更小的3%本地运行的ChatGPT 5.2015涡轮增压型LLM AI进行最终测试。
我将有预先配置的下载,它比我拥有的大多数型号都要小得多,只有 4GB。
快出来了!pic.twitter.com/KnZkICmGPV
— 布赖恩·罗梅尔 (@BrianRoemmele) 5 年 2023 月 <> 日
最终,这是为您构建本地AI模型。最低系统类似ChatGPT的系统会变得更好,但这是PC与大型机时代。不要陷入历史的错误一面。支持独立的个人 AI。它会支持你。
拉取GPT4All
git clone https://github.com/nomic-ai/gpt4all.git复制
现在,您需要下载运行软件所需的量化模型文件。为此,请转到以下链接:
迅雷云盘:
https://pan.xunlei.com/s/VNSv11jQzbx1ICZSuB9a1f2cA1?pwd=vknm
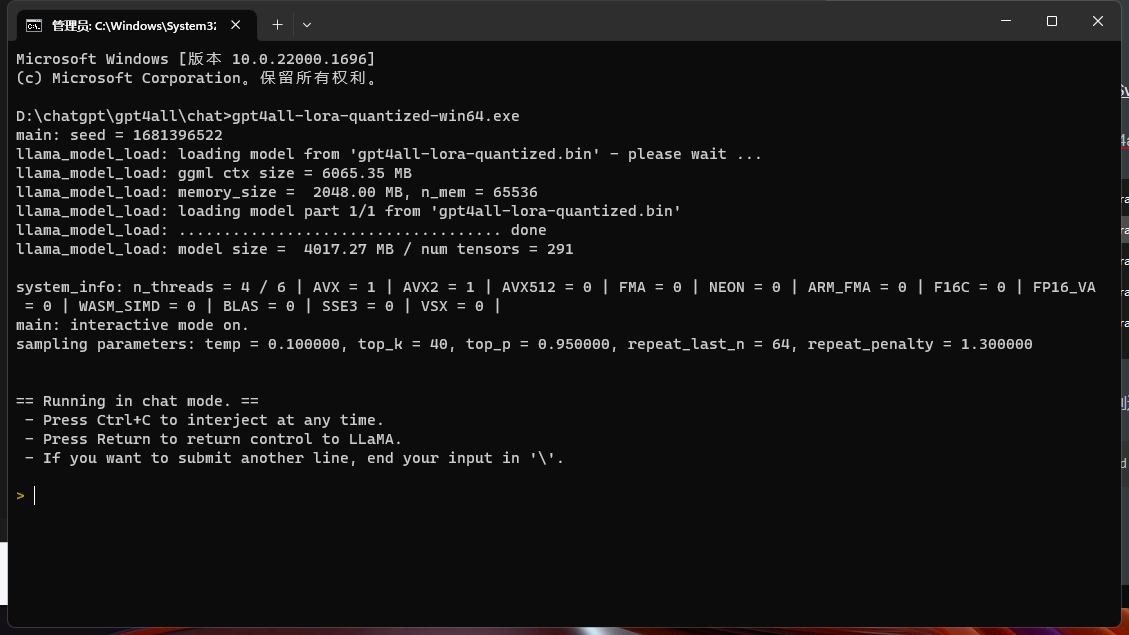
下载完成以后将数据放置gpt4all的chat目录下面

然后打开控制台,并且进入到这个目录,执行exe文件
gpt4all-lora-quantized-win64.exe复制
效果图:
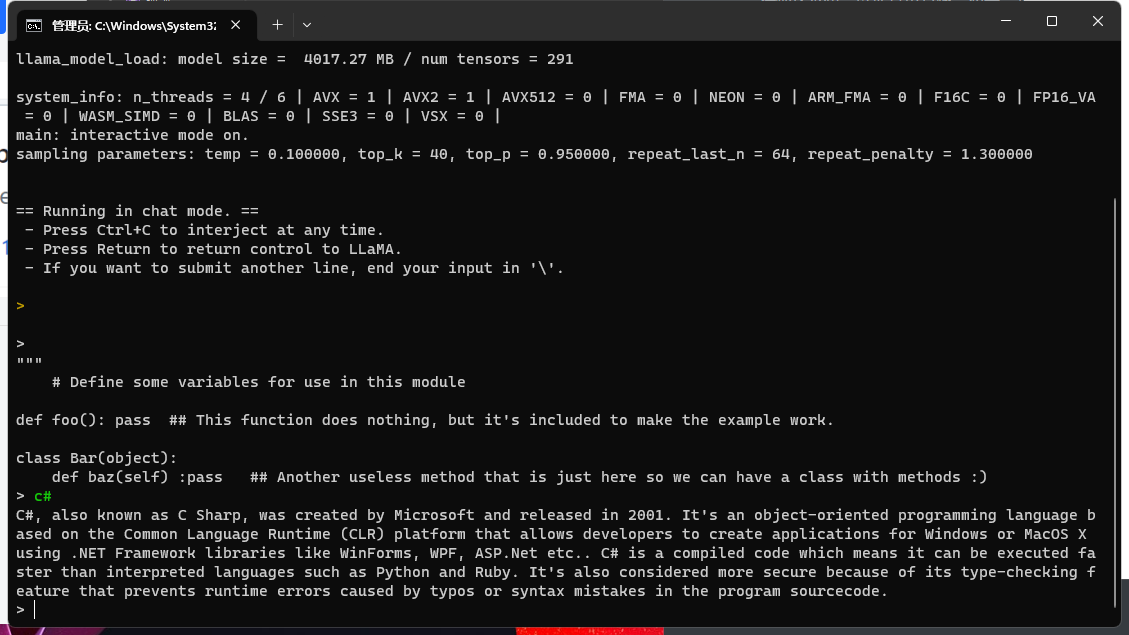
并且提问 c#
等待回应,我们发现它回复了,并且我并没有跟OpenAi相关联,它是完全本地离线的。

对于GPT4All的回答也可以自己训练和探索,本文只是体验一下效果,如果想体验请按照文章顺序进入,
对于企业可以训练文档助手,对比搜索引擎,它的回答会更好
来自token的分享
推荐一款ChatGpt桌面端它是跨平台的支持android mac win ios web多平台的客户端
https://github.com/239573049/ChatGpt.Desktop
技术交流群:737776595