在现代物流的实际作业流程中,会有大量关系到运营相关信息的数据产生,如商家,车队,站点,分拣中心,客户等等相关的信息数据,这些数据直接支撑齐了物流的整个业务流转,具有十分重要的地位,那么对于这一类数据我们需要提供基本的增删改查存的能力,目前京东物流的基础数据是由中台配运组来整体负责。
在基础数据的常规能力当中,数据的存取是最基础也是最重要的能力,为了整体提高数据的读取能力,缓存技术在基础数据的场景中得到了广泛的使用,下面会重点展示一下配运组近期针对数据缓存做的瘦身实践。
这次优化我们挑选了商家基础资料和C后台2个系统进行了缓存数据的优化试点,从结果看取得了非常显著的成果,节省了大量的硬件资源成本,下面的数据是优化前后的缓存使用情况对比:
商家基础资料Redis数据量由45G降为8G;
C后台Redis数据量由132G降为7G;
从结果看这个优化的力度太大了,相信大家对如何实现的更加好奇了,那接下来就让我们一步步来看是如何做到的吧!
首先目前的商家基础资料使用@Caceh注解组件作为缓存方式,它会将从db中查出的值放入本地缓存及jimdb中,由于该组件早期的版本没有jimdb的默认过期时间且使用注解时也未显式声明,造成早期大量的key没有过期时间,从而形成了大量的僵尸key。
所以如果我们可以找到这些僵尸key并进行优化,那么就可以将缓存进行一个整体的瘦身,那首先要怎么找出这些key呢?
可能很多同学会想到简单粗暴的keys命令,遍历出所有的key依次判断是否有过期时间,但Redis是单线程执行,keys命令会以阻塞的方式执行,遍历方式实现的复杂度是O(n),库中的key越多,阻塞的时间会越长,通常我们的数据量都会在几十G以上,显然这种方式是无法接受的。
redis在2.8版本提供了scan命令,相较于keys命令的优势:
当然也有缺点:
目前看来这是个不错的选择,让我们来看下命令的基本语法:
SCAN cursor [MATCH pattern] [COUNT count]
首先感觉上就是根据游标进行增量式迭代,让我们实际操作下:
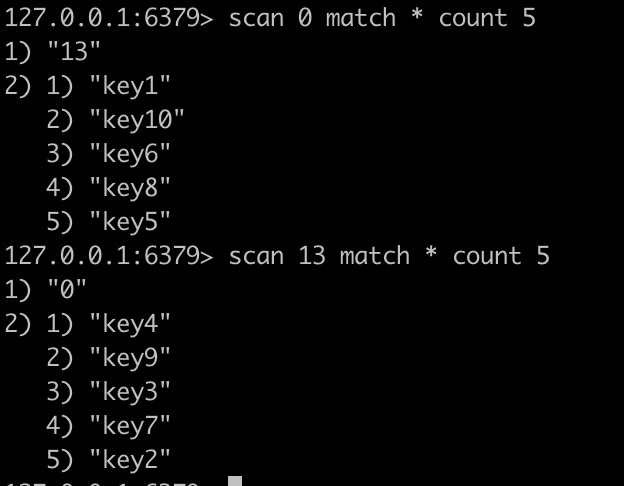
看来我们只需要设置好匹配的key的前缀,循环遍历删除key即可。
可以通过Controller或者调用jsf接口来触发,使用云redis-API,demo如下:
好的,大功告成.在管理端执行randomkey命令查看.发现依然存在大量的无用key,貌似还有不少漏网之鱼,这里又是怎么回事呢?
下面又到了喜闻乐见的踩坑环节。
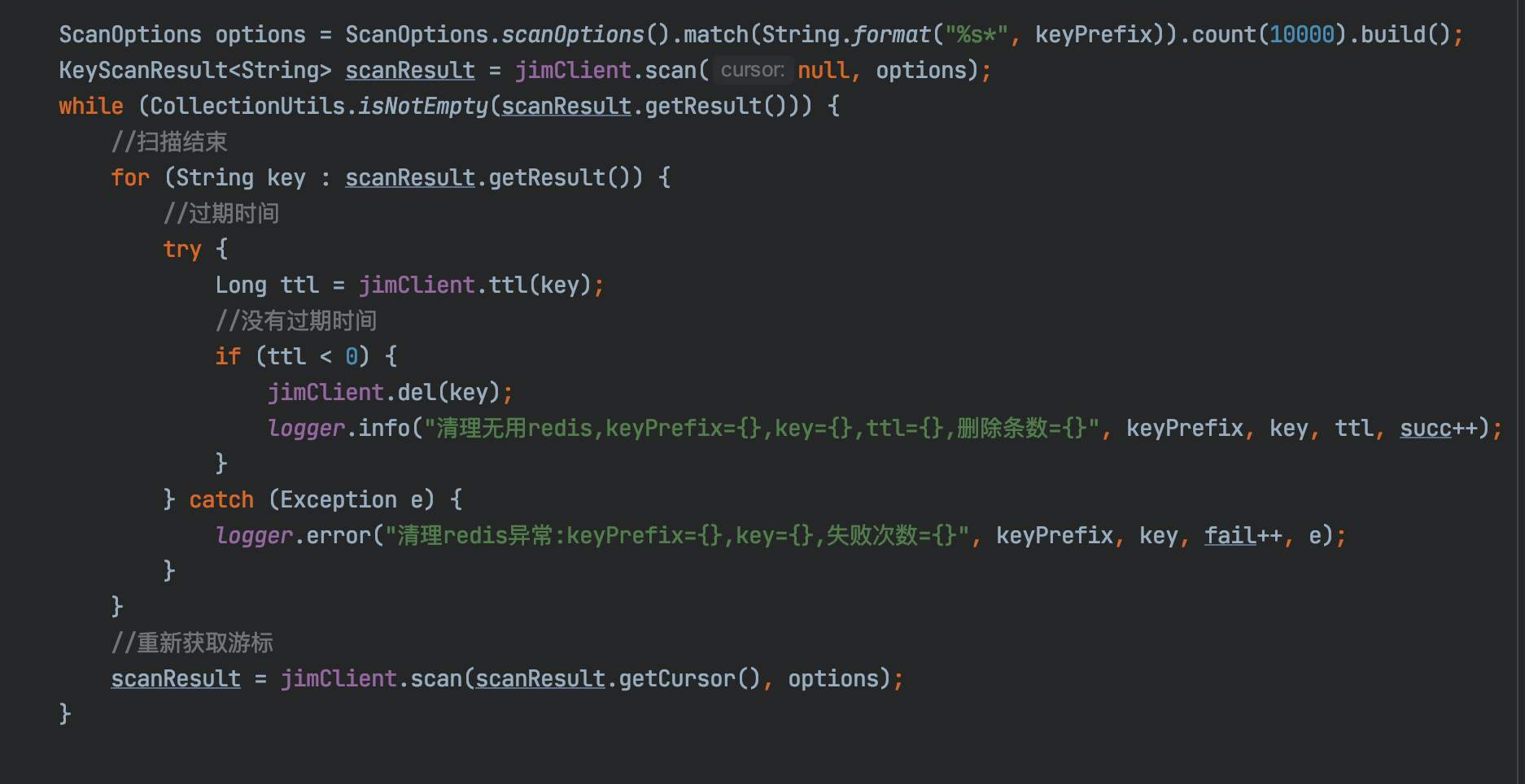
通过增加日发现,返回的结果集为空,但游标并未结束!
其实不难发现scan命令跟我们在数据库中按条件分页查询是有别的,mysql是根据条件查询出数据,scan命令是按字典槽数依次遍历,从结果中再匹配出符合条件的数据返回给客户端,那么很有可能在多次的迭代扫描时没有符合条件的数据。
我们修改代码使用scanResult.isFinished()方法判断是否已经迭代完成。
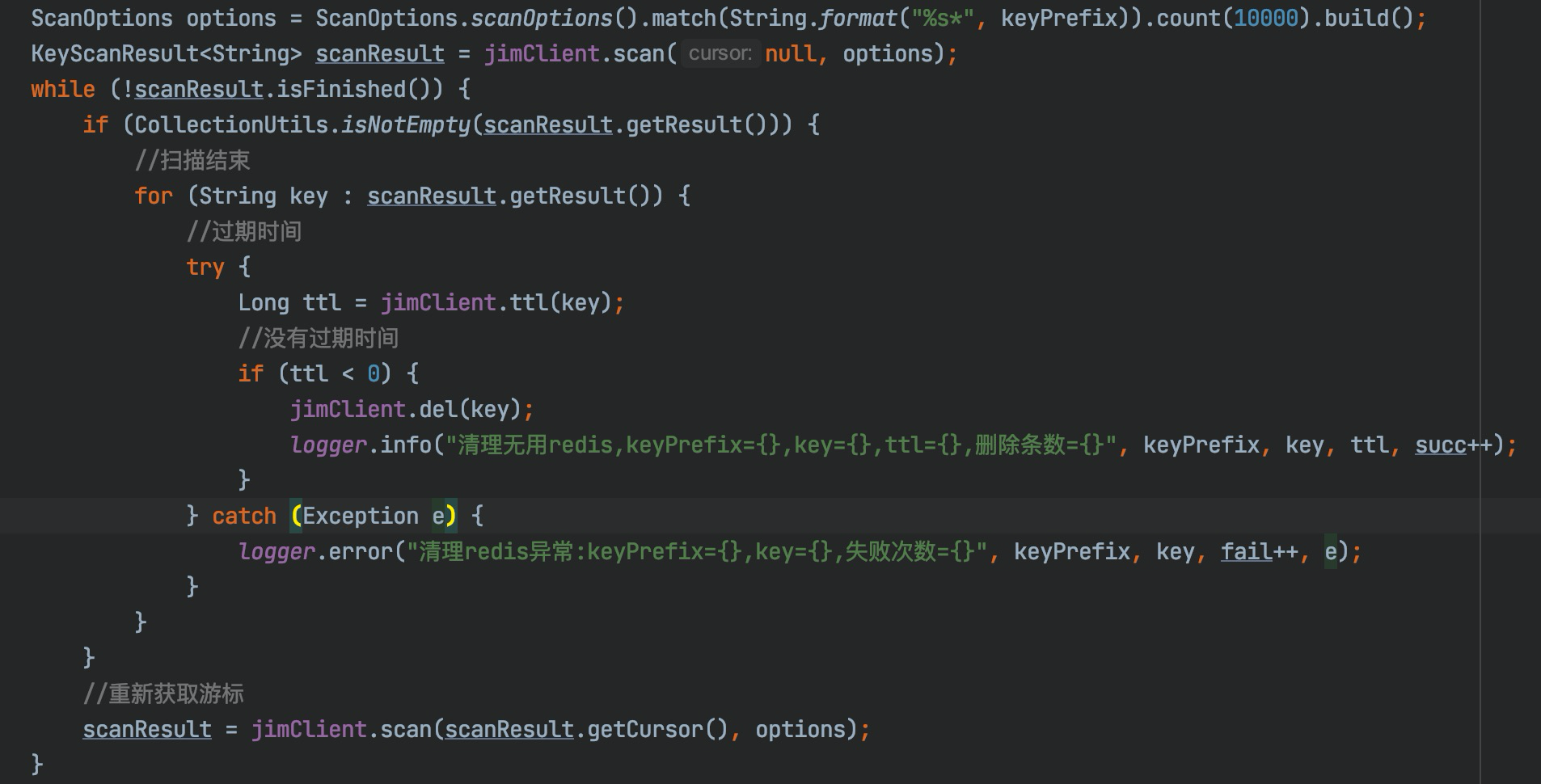
至此程序运行正常,之后通过传入不同的匹配字符,达到清楚缓存的目的。
这里我们探讨重复数据的问题:为什么遍历出的数据可能会重复?
首先我们看下scan命令的遍历顺序:
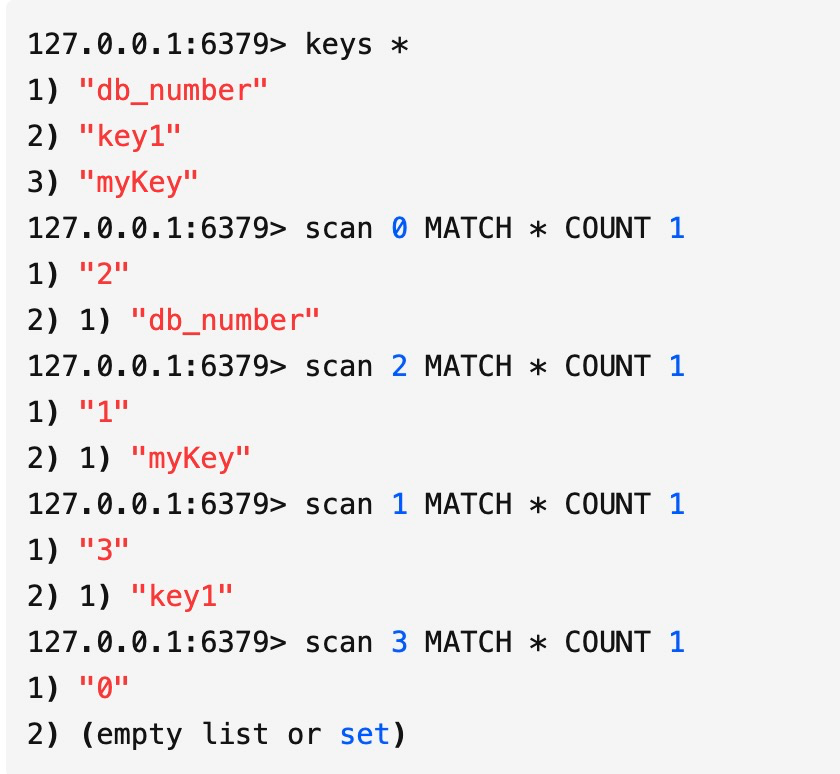
Redis中有3个key,我们用scan命令查看发现遍历顺为0->2->1->3,是不是感到奇怪,为什么不是按0->1->2->3的顺序?
我们都知道HashMap中由于存在hash冲突,当负载因子超过某个阈值时,出于对链表性能的考虑会进行Resize操作.Redis也一样,底层的字典表会有动态变换,这种扫描顺序也是为了应对这些复杂的场景。
3.1.1 字典表的几种状态及使用顺序扫描会出现的问题
字典表没有扩容
字段tablesize保持不变,顺序扫描没有问题
字典表已扩容完成
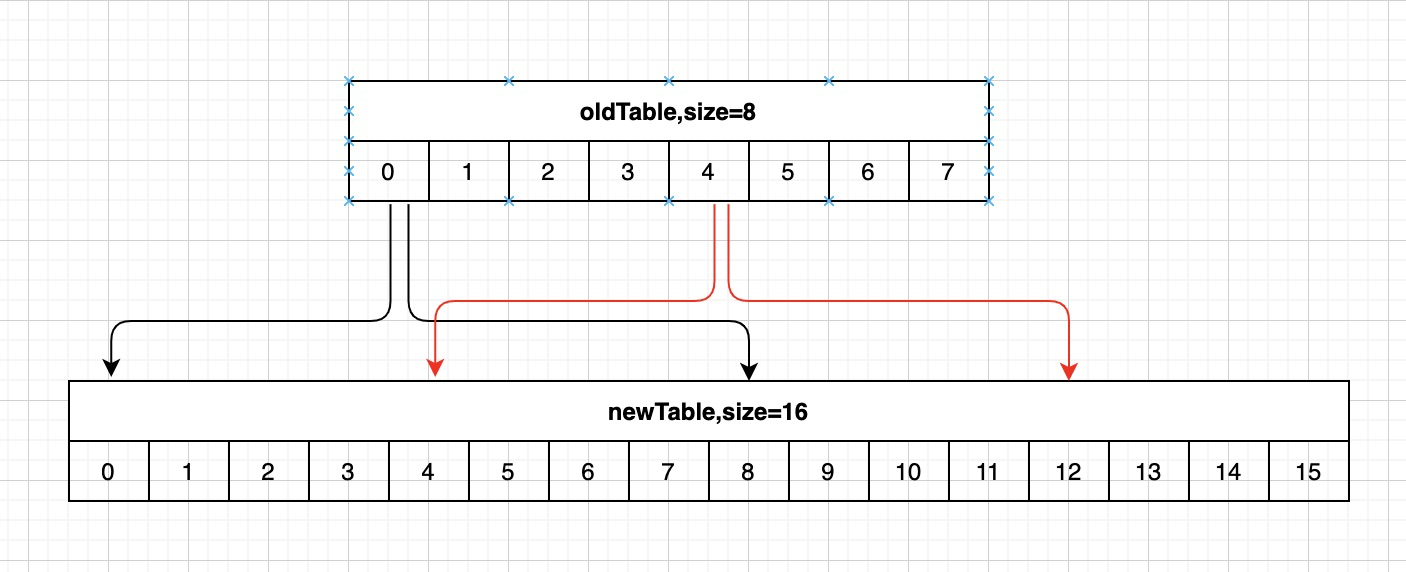
假设字典tablesize从8变为16,之前已经访问过3号桶,现在03号桶的数据已经rehash到811号桶,若果按顺序继续访问4~15号桶,那么这些元素就重复遍历了。
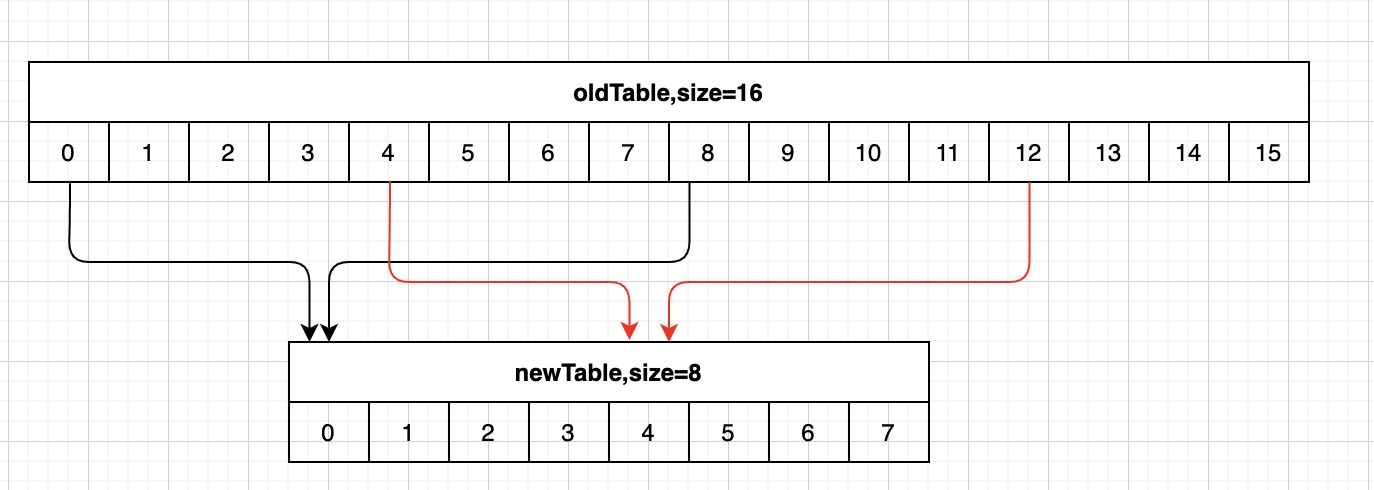
假设字典tablesize从16缩小到8,同样已经访问过3号桶,这时8~11号桶的元素被rehash到0号桶,若按顺序访问,则遍历会停止在7号桶,则这些数据就遗漏掉了。
3.1.2 反向二进制迭代器算法思想
我们将Redis扫描的游标与顺序扫描的游标转换成二进制作对比:
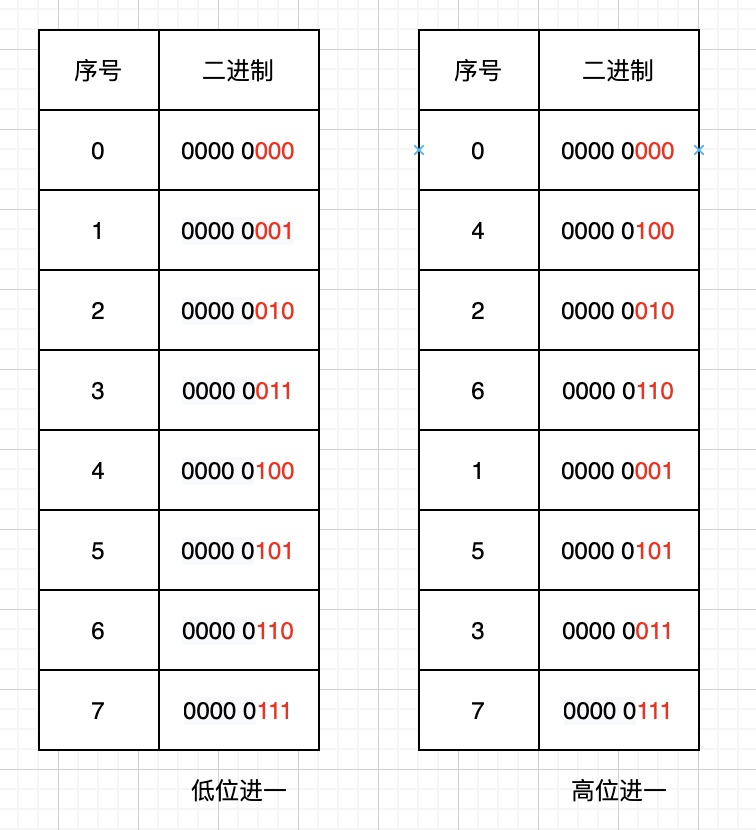
高位顺序访问是按照字典sizemask(掩码),在有效位上高位加1。
举个例子,我们看下Scan的扫描方式:
1.字典tablesize为8,游标从0开始扫描;
2.返回客户端的游标为6后,字典tablesize扩容到之前的2倍,并且完成Rehash;
3.客户端发送命令scan 6;
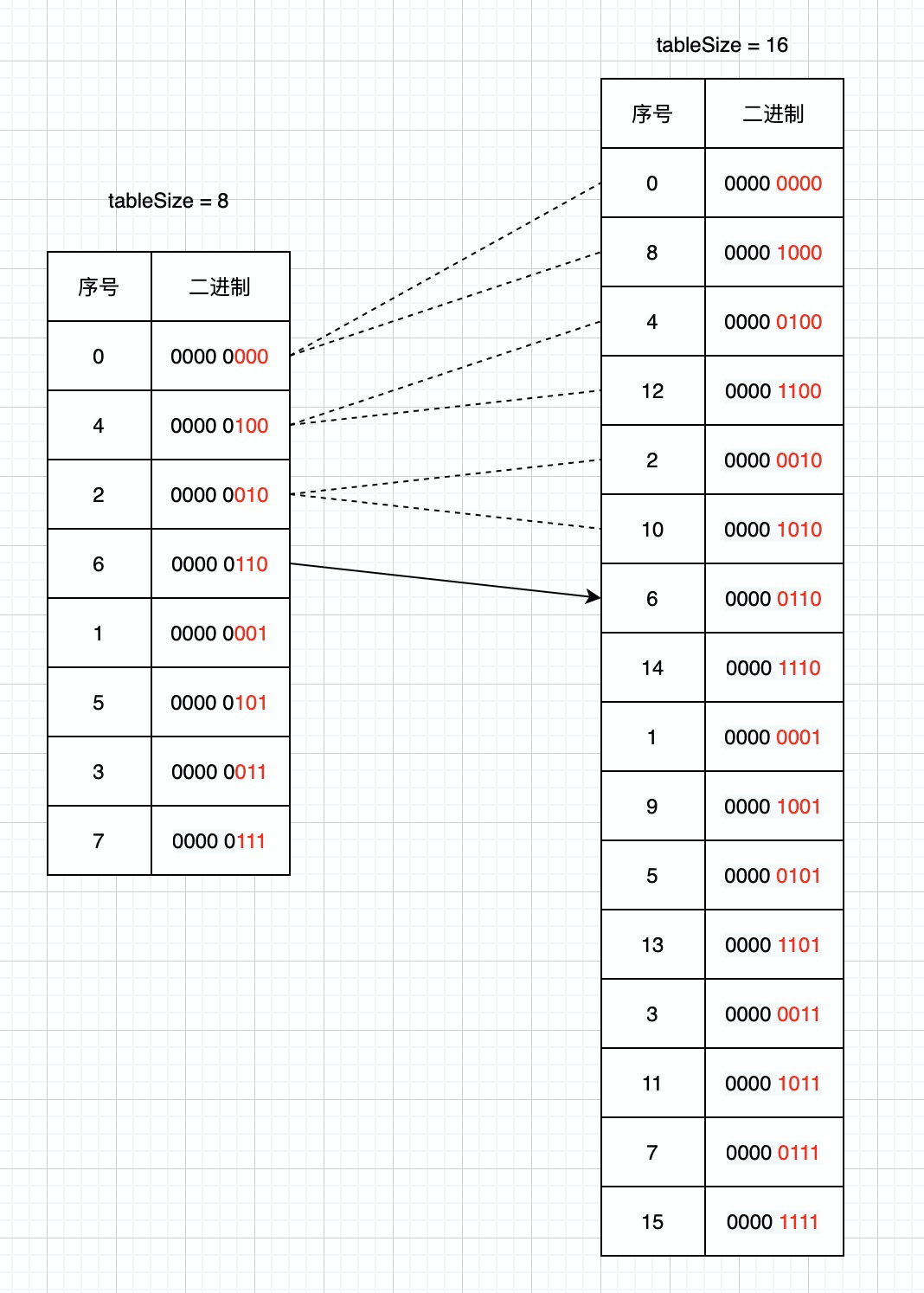
这时scan命令会将6号桶中链表全部取出返回客户端,并且将当前游标的二进制高位加一计算出下次迭代的起始游标.通过上图我们可以发现扩容后8,12,10号槽位的数据是从之前0,4,2号槽位迁移过去的,这些槽位的数据已经遍历过,所以这种遍历顺序就避免了重复扫描。
字典扩容的情况类似,但重复数据的出现正是在这种情况下:
还以上图为例,再看下缩容时Scan的扫描方式:
1.字典tablesize的初始大小为16,游标从0开始扫描;
2.返回客户端的游标为14后,字典tablesize缩容到之前的1/2,并完成Rehash;
3.客户端发送命令scan 14;
这时字典表已完成缩容,之前6和14号桶的数据已经Rehash到新表的6号桶中,那14号桶都没有了,要怎么处理呢?我们继续在源码中找答案:
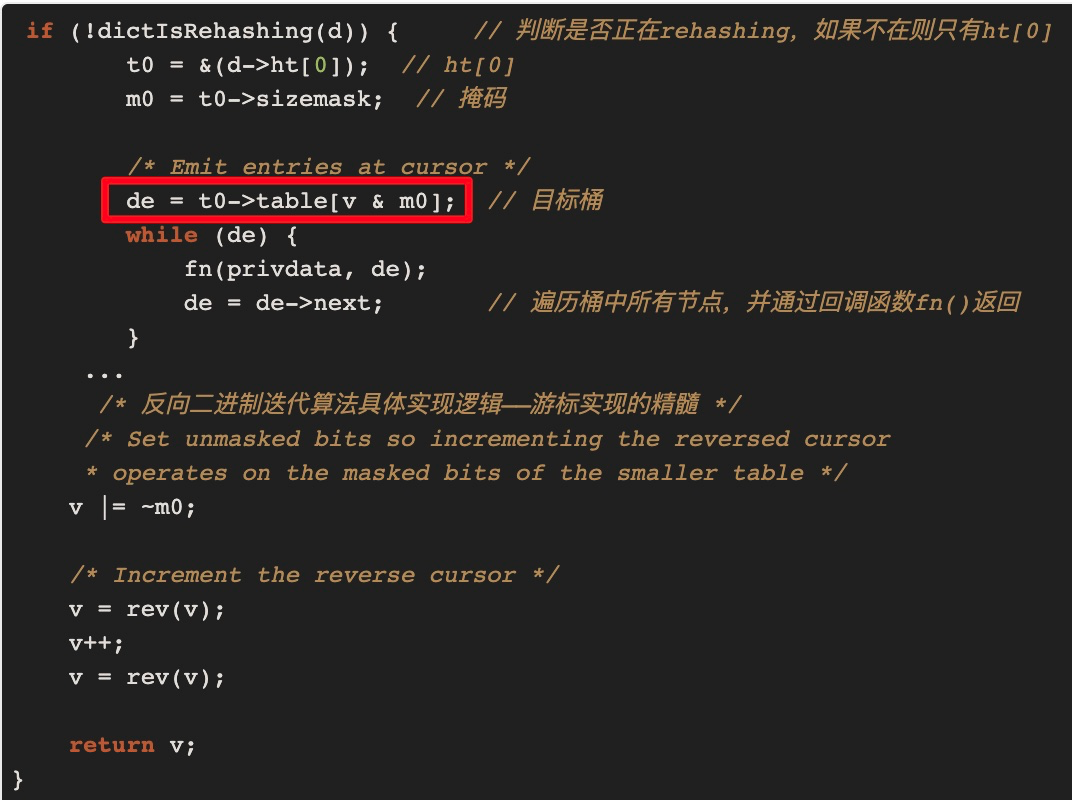
即在找目标桶时总是用当前hashtaba的sizemask(掩码)来计算,v=14即二进制000 1110,当前字典表的掩码从15变成了7即二进制0000 0111,v&m0的值为6,也就是说在新表上还要扫一遍6号桶.但是缩容后旧表6和14号桶的数据都已迁移到了新表的6号桶中,所以这时扫描的结果就出现了重复数据,重复的部分为上次未缩容前已扫描过的6号桶的数据。
结论:
当字典缩容时,高位桶中的数据会合并进低位桶中(6,14)->6,scan命令要保证不遗漏数据,所以要得到缩容前14号桶中的数据,要重新扫描6号桶,所以出现了重复数据.Redis也挺难的,毕竟鱼和熊掌不可兼得。
通过本次Redis瘦身实践,虽然是个很小的工具,但确实带来的显著的效果,节约资源降低成本,并且在排查问题中又学习到了命令底层巧妙的设计思想,收货颇丰,最后欢迎感兴趣的小伙伴一起交流进步。
在基础数据的常规能力当中,数据的存取是最基础也是最重要的能力,为了整体提高数据的读取能力,缓存技术在基础数据的场景中得到了广泛的使用,下面会重点展示一下配运组近期针对数据缓存做的瘦身实践。
本文介绍基于ENVI软件,利用“Image Registration Workflow”工具实现栅格遥感影像自动寻找地面控制点从而实现地理配准的方法~