一.HuggingFace简介
1.HuggingFace是什么
可以理解为对于AI开发者的GitHub,提供了模型、数据集(文本|图像|音频|视频)、类库(比如transformers|peft|accelerate)、教程等。
2.为什么需要HuggingFace
主要是HuggingFace把AI项目的研发流程标准化,即准备数据集、定义模型、训练和测试,如下所示:
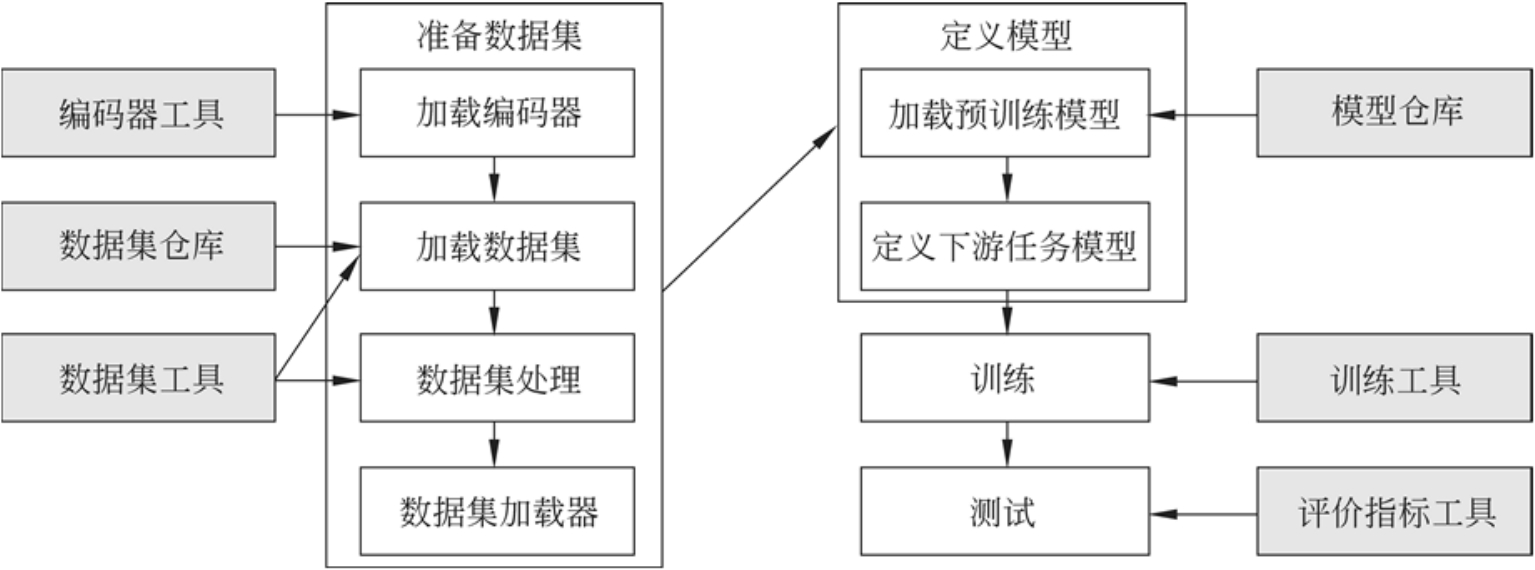
二.HuggingFace社区和GitHub
1.HuggingFace社区
HuggingFace是一个高速发展的社区,包括Meta、Google、Microsoft、Amazon在内的超过5000家组织机构在为HuggingFace开源社区贡献代码、数据集和模型。目前包括模型236,291个,数据集44,810个。刚开始大多数的模型和数据集是NLP方向的,但图像和语音的功能模型正在快速更新中。
 2.HuggingFace GitHub
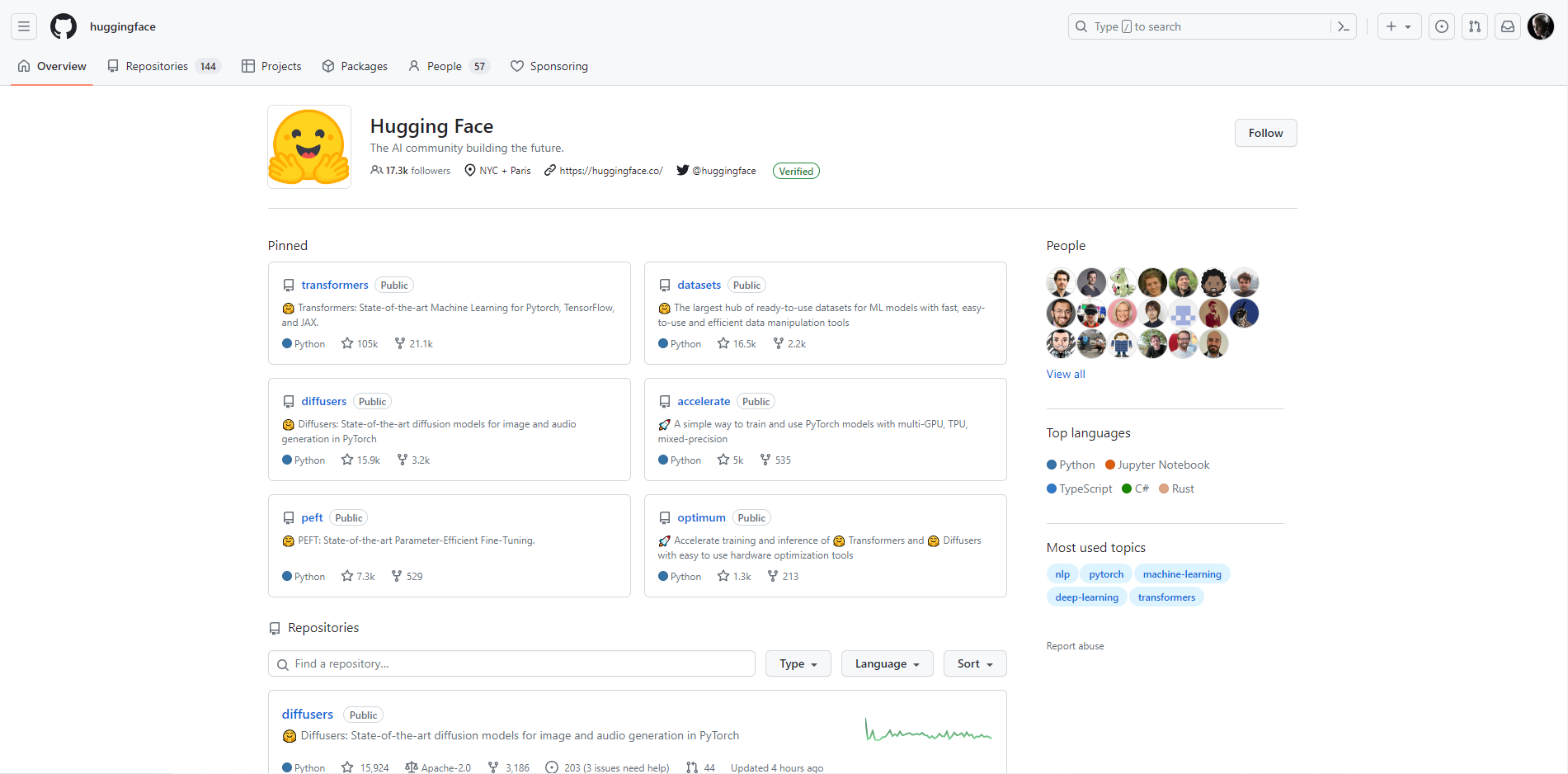
2.HuggingFace GitHub
可以看到包括常用的transformers、datasets、diffusers、accelerate、pef和optimum类库:
参考文献:
[1]利用Hugging Face中的模型进行句子相似性实践:https://mp.weixin.qq.com/s/NBwBC_Z3Xa_pmN1zD_OIxA
[2]Hugging Face博客:https://huggingface.co/blog/zh
[3]Hugging Face GitHub:https://github.com/huggingface/