1.TextCNN原理
CNN的核心点在于可以捕获信息的局部相关性,具体到文本分类任务中可以利用CNN来提取句子中类似N-Gram的关键信息。
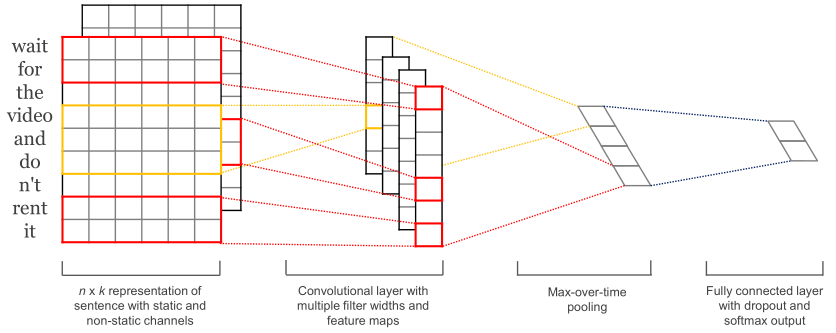 (1)一维卷积:使用不同尺寸的kernel_size来模拟语言模型中的N-Gram,提取句子中的信息。即TextCNN中的卷积用的是一维卷积,通过不同kernel_size的滤波器获取不同宽度的视野。
(1)一维卷积:使用不同尺寸的kernel_size来模拟语言模型中的N-Gram,提取句子中的信息。即TextCNN中的卷积用的是一维卷积,通过不同kernel_size的滤波器获取不同宽度的视野。
(2)词向量:static的方式采用预训练的词向量,训练过程不更新词向量,本质就是迁移学习,主要用于数据量比较小的情况。not-static的方式是在训练过程中更新词向量。推荐的方式是not-static的fine-tunning方式,它是以预训练的词向量进行初始化,训练过程中调整词向量。在工程实践中,通常使用字嵌入的方式也能得到非常不错的效果,这样就避免了中文分词。
(3)最大池化:TextCNN中的池化保留的是Top-1最大信息,但是可能保留Top-K最大信息更有意义。比如,在情感分析场景中,"我觉得这个地方景色还不错,但是人也实在太多了",这句话前半部分表达的情感是正向的,后半部分表达的情感是负向的,显然保留Top-K最大信息能够很好的捕获这类信息。
2.TextRNN原理
TextCNN擅长捕获更短的序列信息,但是TextRNN擅长捕获更长的序列信息。具体到文本分类任务中,BiLSTM从某种意义上可以理解为可以捕获变长且双向的N-Gram信息。
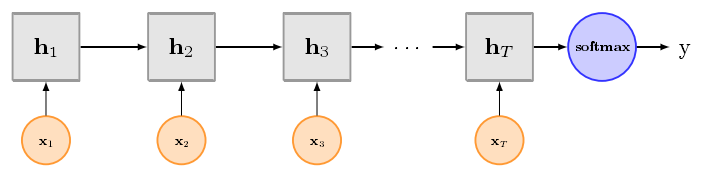 将CNN和RNN用在文本分类中都能取得显著的效果,但是有一个不错的地方就是可解释性不好,特别是去分析错误案例的时候,而注意力机制(Attention)能够很好的给出每个词对结果的贡献程度,已经成为Seq2Seq模型的标配,实际上文本分类也可以理解为一种特殊的Seq2Seq模型。因此,注意力机制的引入,可以在某种程度上提高深度学习文本分类模型的可解释性。
将CNN和RNN用在文本分类中都能取得显著的效果,但是有一个不错的地方就是可解释性不好,特别是去分析错误案例的时候,而注意力机制(Attention)能够很好的给出每个词对结果的贡献程度,已经成为Seq2Seq模型的标配,实际上文本分类也可以理解为一种特殊的Seq2Seq模型。因此,注意力机制的引入,可以在某种程度上提高深度学习文本分类模型的可解释性。
3.TextCNN和TextRNN的TensorFlow实现
(1)TextCNN的TensorFlow实现:https://download.csdn.net/download/shengshengwang/10935497
(2)TextRNN的TensorFlow实现:https://download.csdn.net/download/shengshengwang/10935477
参考文献:
[1]Convolutional Neural Networks for Sentence Classification
[2]Recurrent Convolutional Neural Networks for Text Classification
[3]用深度学习解决大规模文本分类问题-综述和实践:https://zhuanlan.zhihu.com/p/25928551
[4]TextCNN文本分类详解:https://hunto.github.io/nlp/2018/03/29/TextCNN%E6%96%87%E6%9C%AC%E5%88%86%E7%B1%BB%E8%AF%A6%E8%A7%A3.html