本文通过ChnSentiCorp数据集介绍了完型填空任务过程,主要使用预训练语言模型bert-base-chinese直接在测试集上进行测试,也简要介绍了模型训练流程,不过最后没有保存训练好的模型。
一.完形填空
完形填空应该大家都比较熟悉,就是把句子中的词挖掉,根据上下文推测挖掉的词是什么。
二.准备数据集
本文使用ChnSentiCorp数据集,不清楚的可以参考中文情感分类介绍。一些样例如下所示:
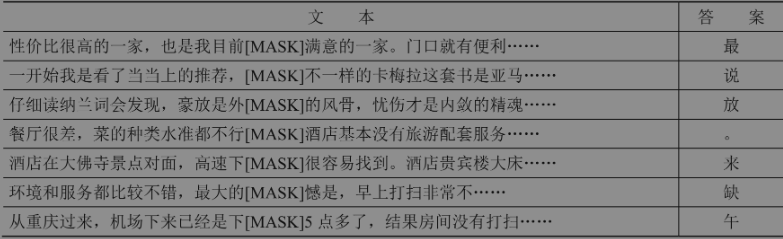 本文做法为将每句话截断为固定的30个词,同时将第15个词替换为[MASK],模型任务为根据上下文预测第15个词。
本文做法为将每句话截断为固定的30个词,同时将第15个词替换为[MASK],模型任务为根据上下文预测第15个词。
1.使用编码工具
def load_encode_tool(pretrained_model_name_or_path): token = BertTokenizer.from_pretrained(Path(f'{pretrained_model_name_or_path}')) return tokenif __name__ == '__main__': # 测试编码工具 pretrained_model_name_or_path = r'L:\20230713_HuggingFaceModel\bert-base-chinese' token = load_encode_tool(pretrained_model_name_or_path) print(token)复制输出结果如下所示:
BertTokenizer(name_or_path='L:\20230713_HuggingFaceModel\bert-base-chinese', vocab_size=21128, model_max_length=1000000000000000019884624838656, is_fast=False, padding_side='right', truncation_side='right', special_tokens={'unk_token': '[UNK]', 'sep_token': '[SEP]', 'pad_token': '[PAD]', 'cls_token': '[CLS]', 'mask_token': '[MASK]'}, clean_up_tokenization_spaces=True)复制测试编码句子如下所示:
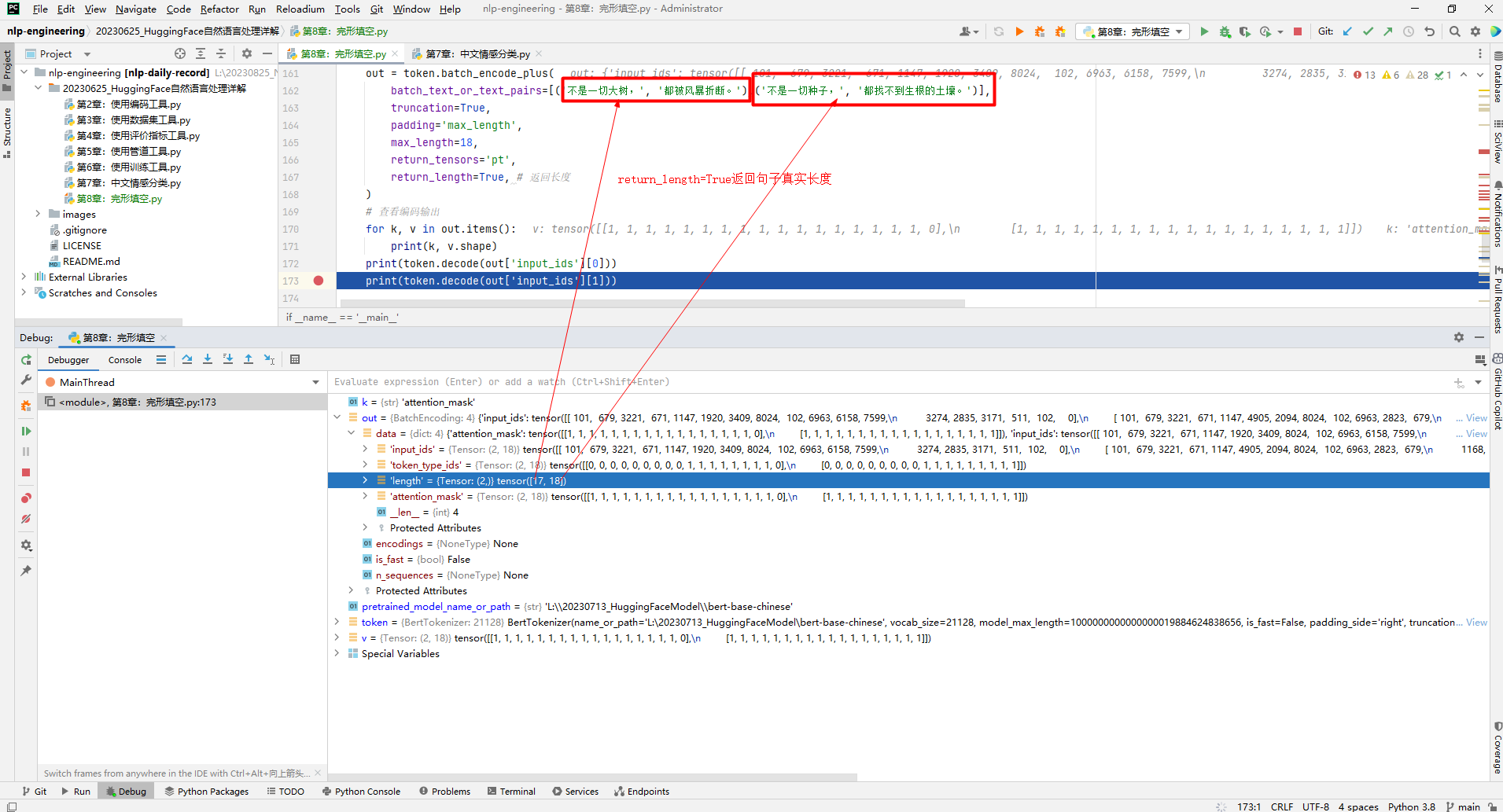
if __name__ == '__main__': # 测试编码工具 pretrained_model_name_or_path = r'L:\20230713_HuggingFaceModel\bert-base-chinese' token = load_encode_tool(pretrained_model_name_or_path) # 测试编码句子 out = token.batch_encode_plus( batch_text_or_text_pairs=[('不是一切大树,', '都被风暴折断。'),('不是一切种子,', '都找不到生根的土壤。')], truncation=True, padding='max_length', max_length=18, return_tensors='pt', return_length=True, # 返回长度 ) # 查看编码输出 for k, v in out.items(): print(k, v.shape) print(token.decode(out['input_ids'][0])) print(token.decode(out['input_ids'][1]))复制结果输出如下所示:
input_ids torch.Size([2, 18])token_type_ids torch.Size([2, 18])length torch.Size([2])attention_mask torch.Size([2, 18])[CLS] 不 是 一 切 大 树 , [SEP] 都 被 风 暴 折 断 。 [SEP] [PAD][CLS] 不 是 一 切 种 子 , [SEP] 都 找 不 到 生 根 的 土 [SEP]复制第1个句子长度为17,补了1个[PAD],第2个句子长度为18。return_length=True表示返回句子真实长度,即不包括[PAD]填充部分长度。如下所示:
 编码结果如下所示:
编码结果如下所示:

2.定义数据集
def load_dataset_from_disk(): pretrained_model_name_or_path = r'L:\20230713_HuggingFaceModel\ChnSentiCorp' dataset = load_from_disk(pretrained_model_name_or_path) # batched=True表示批量处理 # batch_size=1000表示每次处理1000个样本 # num_proc=8表示使用8个线程操作 # remove_columns=['text']表示移除text列 dataset = dataset.map(f1, batched=True, batch_size=1000, num_proc=8, remove_columns=['text', 'label']) return datasetif __name__ == '__main__': # 加载数据集 dataset = load_dataset_from_disk() print(dataset)复制结果输出如下所示:
DatasetDict({ train: Dataset({ features: ['input_ids', 'token_type_ids', 'attention_mask', 'length'], num_rows: 9600 }) validation: Dataset({ features: ['input_ids', 'token_type_ids', 'attention_mask', 'length'], num_rows: 1200 }) test: Dataset({ features: ['input_ids', 'token_type_ids', 'attention_mask', 'length'], num_rows: 1200 })})复制3.定义计算设备
# 定义计算设备device = 'cpu'if torch.cuda.is_available(): device = 'cuda'# print(device)复制4.定义数据整理函数
本质是将每个句子第15个词替换为[MASK],同时将第15个词作为标签,即根据上下文要预测的词。如下所示:
# 数据整理函数def collate_fn(data): # 取出编码结果 input_ids = [i['input_ids'] for i in data] attention_mask = [i['attention_mask'] for i in data] token_type_ids = [i['token_type_ids'] for i in data] # 转换为Tensor格式 input_ids = torch.LongTensor(input_ids) attention_mask = torch.LongTensor(attention_mask) token_type_ids = torch.LongTensor(token_type_ids) # 把第15个词替换为MASK labels = input_ids[:, 15].reshape(-1).clone() input_ids[:, 15] = token.get_vocab()[token.mask_token] # 移动到计算设备 input_ids = input_ids.to(device) attention_mask = attention_mask.to(device) token_type_ids = token_type_ids.to(device) labels = labels.to(device) return input_ids, attention_mask, token_type_ids, labels复制5.定义数据集加载器
# 数据集加载器loader = torch.utils.data.DataLoader(dataset=dataset['train'], batch_size=16, collate_fn=collate_fn, shuffle=True, drop_last=True)print(len(loader)) #600=9600/16复制查看样例数据如下所示:
# 查看数据样例for i, (input_ids, attention_mask, token_type_ids, labels) in enumerate(loader): breakprint(input_ids.shape, attention_mask.shape, token_type_ids.shape, labels)复制输出结果如下所示:
torch.Size([16, 30])torch.Size([16, 30])torch.Size([16, 30])tensor([4638, 8024, 3198, 6206, 6392, 4761, 3449, 2128, 3341, 119, 3315, 2697, 2523, 2769, 6814, 1086], device='cuda:0')复制三.定义模型
1.加载预训练模型
加载模型并移动到device(CPU或GPU)中,如下所示:
pretrained_model_name_or_path = r'L:\20230713_HuggingFaceModel\bert-base-chinese'# 加载预训练模型pretrained = BertModel.from_pretrained(Path(f'{pretrained_model_name_or_path}'))pretrained.to(device) 复制2.定义下游任务模型
下游任务模型将BERT提取第15个词的特征(16×768),输入到全连接神经网络(768×21128),得到16×21128,即把第15个词的特征投影到全体词表空间中,还原为词典中的某个词。
class Model(torch.nn.Module): def __init__(self): super().__init__() self.decoder = torch.nn.Linear(in_features=768, out_features=token.vocab_size, bias=False) # 重新将decode中的bias参数初始化为全o self.bias = torch.nn.Parameter(data=torch.zeros(token.vocab_size)) self.decoder.bias = self.bias # 定义 Dropout层,防止过拟合 self.Dropout = torch.nn.Dropout(p=0.5) def forward(self, input_ids, attention_mask, token_type_ids): # 使用预训练模型抽取数据特征 with torch.no_grad(): out = pretrained(input_ids=input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids) # 把第15个词的特征投影到全字典范围内 out = self.Dropout(out.last_hidden_state[:, 15]) out = self.decoder(out) return out复制四.训练和测试
1.训练
定义了AdamW优化器、loss损失函数(交叉熵损失函数)和线性学习率调节器,如下所示:
def train(): # 定义优化器 optimizer = AdamW(model.parameters(), lr=5e-4, weight_decay=1.0) # 定义1oss函数 criterion = torch.nn.CrossEntropyLoss() # 定义学习率调节器 scheduler = get_scheduler(name='linear', num_warmup_steps=0, num_training_steps=len(loader) * 5, optimizer=optimizer) # 将模型切换到训练模式 model.train() # 共训练5个epoch for epoch in range(5): # 按批次遍历训练集中的数据 for i, (input_ids, attention_mask, token_type_ids, labels) in enumerate(loader): # 模型计算 out = model(input_ids=input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids) # 计算loss并使用梯度下降法优化模型参数 loss = criterion(out, labels) loss.backward() optimizer.step() scheduler.step() optimizer.zero_grad() # 输出各项数据的情况,便于观察 if i % 50 == 0: out = out.argmax(dim=1) accuracy = (out == labels).sum().item() / len(labels) lr = optimizer.state_dict()['param_groups'][0]['lr'] print(epoch, 1, loss.item(), lr, accuracy)复制输出部分结果如下所示:
0 1 10.123428344726562 0.0004998333333333334 0.00 1 8.659417152404785 0.0004915 0.06250 1 7.431852340698242 0.0004831666666666667 0.06250 1 7.261701583862305 0.00047483333333333335 0.06250 1 6.693362236022949 0.0004665 0.1250 1 4.0811614990234375 0.00045816666666666667 0.3750 1 7.034963607788086 0.00044983333333333334 0.1875复制
2.测试
使用测试数据集进行测试,如下所示:
def test(): # 定义测试数据集加载器 loader_test = torch.utils.data.DataLoader(dataset=dataset['test'], batch_size=32, collate_fn=collate_fn, shuffle=True, drop_last=True) # 将下游任务模型切换到运行模式 model.eval() correct = 0 total = 0 # 按批次遍历测试集中的数据 for i, (input_ids, attention_mask, token_type_ids, labels) in enumerate(loader_test): # 计算15个批次即可,不需要全部遍历 if i == 15: break print(i) # 计算 with torch.no_grad(): out = model(input_ids=input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids) # 统计正确率 out = out.argmax(dim=1) correct += (out == labels).sum().item() total += len(labels) print(correct / total)复制参考文献:
[1]HuggingFace自然语言处理详解:基于BERT中文模型的任务实战
[2]https://github.com/ai408/nlp-engineering/blob/main/20230625_HuggingFace自然语言处理详解/第8章:完形填空.py