本文通过ChnSentiCorp数据集介绍了中文句子关系推断任务过程,主要使用预训练语言模型bert-base-chinese直接在测试集上进行测试,也简要介绍了模型训练流程,不过最后没有保存训练好的模型。
一.任务简介和数据集
通过模型来判断2个句子是否连续,使用ChnSentiCorp数据集,不清楚的可以参考中文情感分类介绍。句子关系推断数据集样例如下所示:
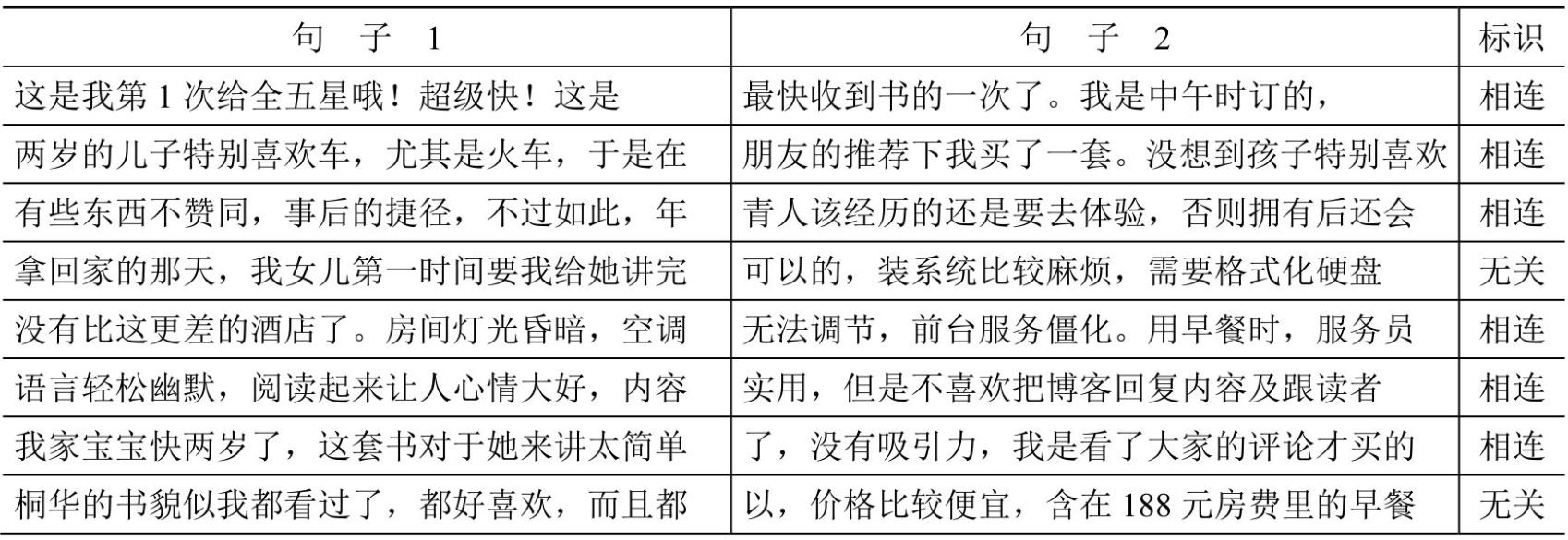
二.准备数据集
1.使用编码工具
编码工具详细介绍可参考使用编码工具。如下所示:
def load_encode_tool(pretrained_model_name_or_path): token = BertTokenizer.from_pretrained(Path(f'{pretrained_model_name_or_path}')) return tokenif __name__ == '__main__': # 测试编码工具 pretrained_model_name_or_path = r'L:\20230713_HuggingFaceModel\bert-base-chinese' token = load_encode_tool(pretrained_model_name_or_path) print(token) # 测试编码句子 out = token.batch_encode_plus( batch_text_or_text_pairs=[('不是一切大树,', '都被风暴折断。'),('不是一切种子,', '都找不到生根的土壤。')], truncation=True, padding='max_length', max_length=18, return_tensors='pt', return_length=True, # 返回长度 ) # 查看编码输出 for k, v in out.items(): print(k, v.shape) print(token.decode(out['input_ids'][0])) print(token.decode(out['input_ids'][1]))复制输出结果如下所示:
BertTokenizer(name_or_path='L:\20230713_HuggingFaceModel\bert-base-chinese', vocab_size=21128, model_max_length=1000000000000000019884624838656, is_fast=False, padding_side='right', truncation_side='right', special_tokens={'unk_token': '[UNK]', 'sep_token': '[SEP]', 'pad_token': '[PAD]', 'cls_token': '[CLS]', 'mask_token': '[MASK]'}, clean_up_tokenization_spaces=True)input_ids torch.Size([2, 18])token_type_ids torch.Size([2, 18])length torch.Size([2])attention_mask torch.Size([2, 18])[CLS] 不 是 一 切 大 树 , [SEP] 都 被 风 暴 折 断 。 [SEP] [PAD][CLS] 不 是 一 切 种 子 , [SEP] 都 找 不 到 生 根 的 土 [SEP]复制编码结果如下所示:

2.定义数据集
首先在__init__()中加载ChnSentiCorp数据集,然后过滤掉小于40个字的句子。在__getitem__()中将一句话分隔为各20个字的两句话,并且有50%概率把后半句替换为无关的句子,这样就构建完成本文所需要数据集。
class Dataset(torch.utils.data.Dataset): def __init__(self, split): pretrained_model_name_or_path = r'L:\20230713_HuggingFaceModel\ChnSentiCorp' dataset = load_from_disk(pretrained_model_name_or_path)[split] # 过滤长度大于40的句子 self.dataset = dataset.filter(lambda data: len(data['text']) > 40) def __len__(self): return len(self.dataset) def __getitem__(self, i): text = self.dataset[i]['text'] # 将一句话切分为前半句和后半句 sentence1 = text[:20] sentence2 = text[20:40] # 随机整数,取值为0和1 label = random.randint(0, 1) # 有一半概率把后半句替换为无关的句子 if label == 1: j = random.randint(0, len(self.dataset) - 1) # 随机取出一句话 sentence2 = self.dataset[j]['text'][20:40] # 取出后半句 return sentence1, sentence2, label # 返回前半句、后半句和标签if __name__ == '__main__': # 加载数据集 dataset = Dataset('train') sentence1, sentence2, label = dataset[7] print(len(dataset), sentence1, sentence2, label)复制输出结果如下所示:
8001地理位置佳,在市中心。酒店服务好、早餐品种丰富。我住的商务数码房电脑宽带速度满意0复制其中,8001表示训练数据集,每条训练数据包括两句话和一个标签,标签表示这两句话是否有关。
3.定义计算设备
# 定义计算设备device = 'cpu'if torch.cuda.is_available(): device = 'cuda'复制4.定义数据整理函数
collate_fn(data)函数中的data表示一个batch的数据,每条记录包括句子对和标签,该函数功能为编码一个batch文本数据。
def collate_fn(data): sents = [i[:2] for i in data] labels = [i[2] for i in data] data = token.batch_encode_plus(batch_text_or_text_pairs=sents, # 输入句子对 truncation=True, # 截断 padding='max_length', # [PAD] max_length=45, # 最大长度 return_tensors='pt', # 返回pytorch张量 return_length=True, # 返回长度 add_special_tokens=True) # 添加特殊符号 # input_ids:编码之后的数字 # attention_mask:补零的位置是0, 其他位置是1 # token_type_ids:第1个句子和特殊符号的位置是0, 第2个句子的位置是1 input_ids = data['input_ids'].to(device) attention_mask = data['attention_mask'].to(device) token_type_ids = data['token_type_ids'].to(device) labels = torch.LongTensor(labels).to(device) return input_ids, attention_mask, token_type_ids, labels复制输入参数data数据样例如下所示:
data = [('酒店还是非常的不错,我预定的是套间,服务', '非常好,随叫随到,结账非常快。',0),('外观很漂亮,性价比感觉还不错,功能简', '单,适合出差携带。蓝牙摄像头都有了。',0),('《穆斯林的葬礼》我已闻名很久,只是一直没', '怎能享受4星的服务,连空调都不能用的。', 1)]复制5.定义数据集加载器
# 数据集加载器loader = torch.utils.data.DataLoader(dataset=dataset, batch_size=8, collate_fn=collate_fn, shuffle=True, drop_last=True)# print(len(loader))复制三.定义模型
1.加载预训练模型
pretrained_model_name_or_path = r'L:\20230713_HuggingFaceModel\bert-base-chinese'pretrained = BertModel.from_pretrained(Path(f'{pretrained_model_name_or_path}'))pretrained.to(device)复制2.定义下游任务模型
下游任务模型为线性神经网络,权重矩阵为768×2,即把一个768维度的向量转换到2维空间(相关或无关)。其中,out.last_hidden_state[:, 0, :]表示只使用了第1个词([CLS])的特征用于相关或无关的判断。如下所示:
class Model(torch.nn.Module): def __init__(self): super().__init__() self.fc = torch.nn.Linear(768, 2) def forward(self, input_ids, attention_mask, token_type_ids): # 使用预训练模型抽取数据特征 with torch.no_grad(): out = pretrained(input_ids=input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids) # 对抽取的特征只取第1个字的结果进行分类即可 out = self.fc(out.last_hidden_state[:, 0, :]) out = out.softmax(dim=1) return out #torch.Size([16, 2])复制四.训练和测试
1.训练
def train(): # 定义优化器 optimizer = AdamW(model.parameters(), lr=5e-5) # 定义1oss函数 criterion = torch.nn.CrossEntropyLoss() # 定义学习率调节器 scheduler = get_scheduler(name='linear', num_warmup_steps=0, num_training_steps=len(loader), optimizer=optimizer) # 将模型切换到训练模式 model.train() # 按批次遍历训练集中的数据 for epoch in range(5): # 按批次遍历训练集中的数据 for i, (input_ids, attention_mask, token_type_ids, labels) in enumerate(loader): # 模型计算 out = model(input_ids=input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids) # 计算loss并使用梯度下降法优化模型参数 loss = criterion(out, labels) loss.backward() # 反向传播 optimizer.step() # 梯度下降法优化模型参数 scheduler.step() # 学习率调节器 optimizer.zero_grad() # 清空梯度 # 输出各项数据的情况,便于观察 if i % 20 == 0: out = out.argmax(dim=1) # 取出最大值的索引 accuracy = (out == labels).sum().item() / len(labels) # 计算准确率 lr = optimizer.state_dict()['param_groups'][0]['lr'] # 获取当前学习率 print(epoch, 1, loss.item(), lr, accuracy)复制2.测试
def test(): # 定义测试数据集加载器 dataset = Dataset('test') loader_test = torch.utils.data.DataLoader(dataset=dataset, batch_size=32, collate_fn=collate_fn, shuffle=True, drop_last=True) # 将下游任务模型切换到运行模式 model.eval() correct = 0 total = 0 # 按批次遍历测试集中的数据 for i, (input_ids, attention_mask, token_type_ids, labels) in enumerate(loader_test): # 计算5个批次即可,不需要全部遍历 if i == 5: break print(i) # 计算 with torch.no_grad(): out = model(input_ids=input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids) # 统计正确率 out = out.argmax(dim=1) correct += (out == labels).sum().item() total += len(labels) print(correct / total)复制参考文献:
[1]HuggingFace自然语言处理详解:基于BERT中文模型的任务实战
[2]代码链接:https://github.com/ai408/nlp-engineering/blob/main/20230625_HuggingFace自然语言处理详解/第9章:中文句子关系推断.py