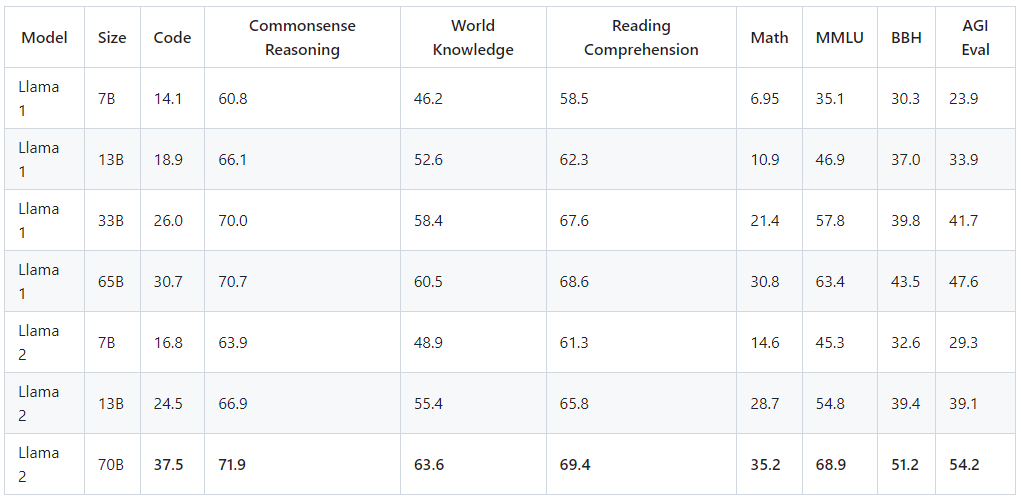
2023年7月18日Meta开源了Llama2,在2万亿个Token上训练,可用于商业和研究,包括从7B到70B模型权重、预训练和微调的代码。相比Llama1,Llama2有较多提升,评估结果如下所示:
基于Llama2模型的开源模型如下所示:
1.WizardCoder Python V1.0
https://huggingface.co/WizardLM/WizardCoder-Python-13B-V1.0https://huggingface.co/WizardLM/WizardCoder-Python-34B-V1.0复制
2.Phind Code Llama v1
https://huggingface.co/Phind/Phind-CodeLlama-34B-v1https://huggingface.co/Phind/Phind-CodeLlama-34B-Python-v1复制
3.WizardLM 70B V1.0
https://huggingface.co/WizardLM/WizardLM-70B-V1.0复制
4.Dophin Llama 2 7B
https://huggingface.co/ehartford/dolphin-llama2-7b复制
5.Airoboros L2 2.0
https://huggingface.co/jondurbin/airoboros-l2-7b-gpt4-2.0https://huggingface.co/jondurbin/airoboros-l2-13b-gpt4-2.0https://huggingface.co/jondurbin/airoboros-33b-gpt4-2.0https://huggingface.co/jondurbin/airoboros-l2-70b-gpt4-2.0复制6.OpenOrca Preview2 13B
https://huggingface.co/Open-Orca/OpenOrcaxOpenChat-Preview2-13B复制
7.Vicuna v1.5 16k
https://huggingface.co/lmsys/vicuna-7b-v1.5-16khttps://huggingface.co/lmsys/vicuna-13b-v1.5-16k复制8.Vicuna v1.5
https://huggingface.co/lmsys/vicuna-7b-v1.5https://huggingface.co/lmsys/vicuna-13b-v1.5复制9.Hermes LLongMA-2 8k
https://huggingface.co/conceptofmind/Hermes-LLongMA-2-7b-8khttps://huggingface.co/conceptofmind/Hermes-LLongMA-2-13b-8k复制10.OpenChat V3.2
https://huggingface.co/openchat/openchat_v3.2复制
11.Llama 2 70B Instruct v2
https://huggingface.co/upstage/Llama-2-70b-instruct-v2复制
12.StableBeluga
https://huggingface.co/stabilityai/StableBeluga-7Bhttps://huggingface.co/stabilityai/StableBeluga-13Bhttps://huggingface.co/stabilityai/StableBeluga2复制13.Holodeck
https://huggingface.co/KoboldAI/LLAMA2-13B-Holodeck-1https://huggingface.co/KoboldAI/LLAMA2-13B-Holodeck-1-GGML复制
14.Llama 2 7B 32K
https://huggingface.co/togethercomputer/LLaMA-2-7B-32K复制
15.Kimiko
https://huggingface.co/nRuaif/Kimiko_7Bhttps://huggingface.co/nRuaif/Kimiko_13B复制
v16.LLongMA 2 16k**
https://huggingface.co/conceptofmind/LLongMA-2-7b-16khttps://huggingface.co/conceptofmind/LLongMA-2-13b-16k复制17.Airoboros L2 GPT4 1.4.1
https://huggingface.co/jondurbin/airoboros-l2-7b-gpt4-1.4.1https://huggingface.co/jondurbin/airoboros-l2-13b-gpt4-1.4.1https://huggingface.co/jondurbin/airoboros-l2-70b-gpt4-1.4.1复制**18.Llama 2 13B Orca 8kv
https://huggingface.co/OpenAssistant/llama2-13b-orca-8k-3319复制
19.WizardLM 13B V1.2
https://huggingface.co/WizardLM/WizardLM-13B-V1.2复制
20.LLongMA 2 8k
https://huggingface.co/conceptofmind/LLongMA-2-7bhttps://huggingface.co/conceptofmind/LLongMA-2-13b复制21.Nous Hermes Llama 2
https://huggingface.co/NousResearch/Nous-Hermes-llama-2-7bhttps://huggingface.co/NousResearch/Nous-Hermes-llama-2-7b-GGMLhttps://huggingface.co/NousResearch/Nous-Hermes-Llama2-13bhttps://huggingface.co/NousResearch/Nous-Hermes-Llama2-13b-GGMLhttps://huggingface.co/NousResearch/Nous-Hermes-Llama2-13b-GPTQ复制
22.Redmond Puffin 13B
https://huggingface.co/NousResearch/Redmond-Puffin-13Bhttps://huggingface.co/NousResearch/Redmond-Puffin-13B-GGML复制
23.Llama 2 7B Uncensored
https://huggingface.co/georgesung/llama2_7b_chat_uncensored复制
24.Luna AI 7B Chat Uncensored
https://huggingface.co/Tap-M/Luna-AI-Llama2-Uncensored复制
25.Guanaco Llama 2
https://huggingface.co/Mikael110/llama-2-7b-guanaco-fp16https://huggingface.co/Mikael110/llama-2-13b-guanaco-fp16https://huggingface.co/Mikael110/llama-2-70b-guanaco-qlora复制
26.Chinese Llama 2 7B
https://github.com/LinkSoul-AI/Chinese-Llama-2-7b复制
27.llama2-Chinese-chat
https://github.com/CrazyBoyM/llama2-Chinese-chat复制
参考文献:
[1]https://github.com/facebookresearch/llama
[2]https://github.com/facebookresearch/llama-recipes/
[3]https://ai.meta.com/resources/models-and-libraries/llama-downloads/
[4]https://github.com/facebookresearch/llama/blob/main/MODEL_CARD.md
[5]https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
[6]https://ai.meta.com/resources/models-and-libraries/llama/
[7]https://github.com/ovh/ai-training-examples/blob/main/notebooks/natural-language-processing/llm/miniconda/llama2-fine-tuning/llama_2_finetuning.ipynb
[8]https://blog.ovhcloud.com/fine-tuning-llama-2-models-using-a-single-gpu-qlora-and-ai-notebooks/
[9]https://www.reddit.com/r/LocalLLaMA/wiki/models/
[10]大模型评测:https://opencompass.org.cn/