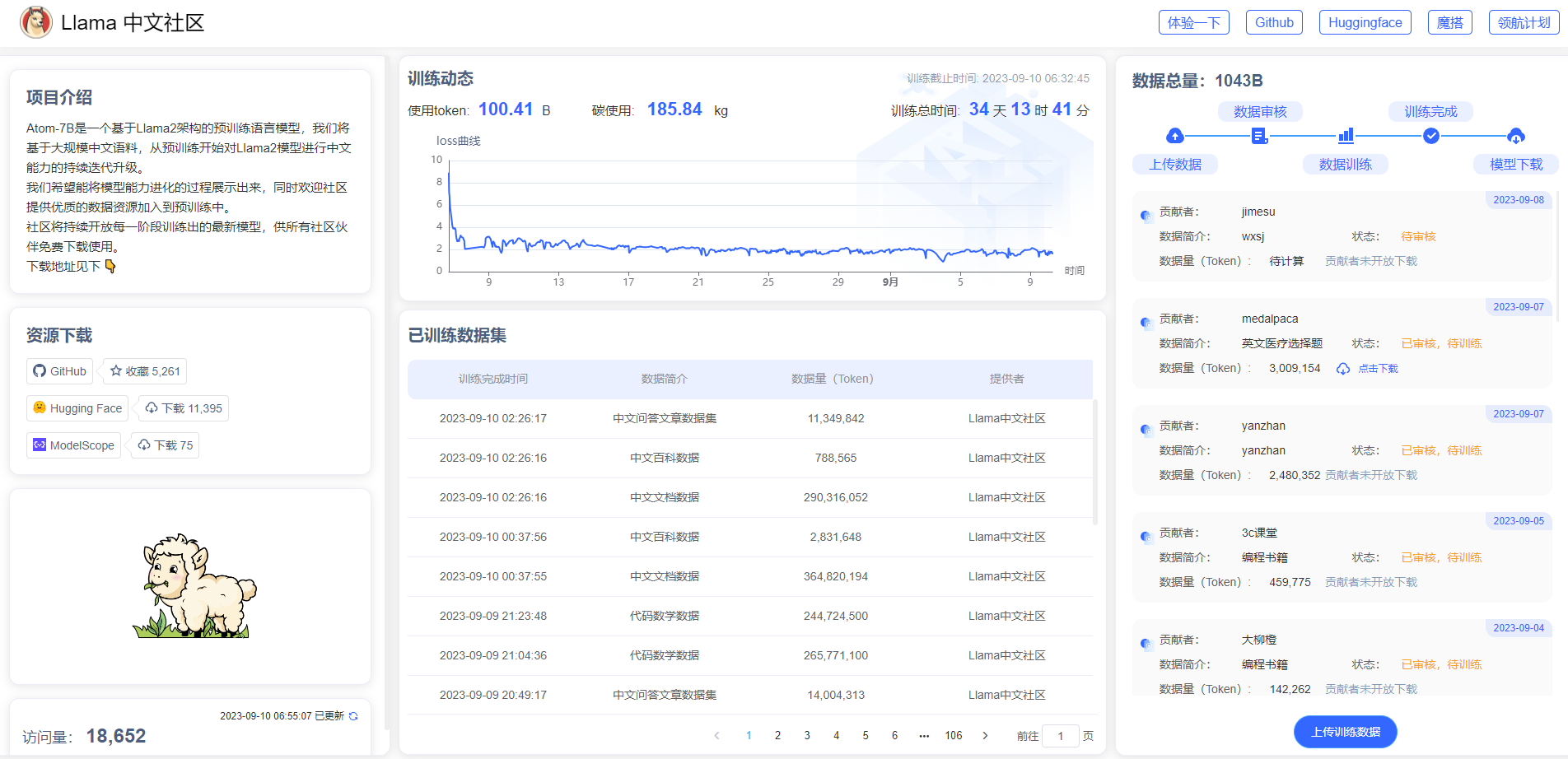
Atom-7B与Llama2间的关系:Atom-7B是基于Llama2进行中文预训练的开源大模型。为什么叫原子呢?因为原子生万物,Llama中文社区希望原子大模型未来可以成为构建AI世界的基础单位。目前社区发布了6个模型,如下所示:
FlagAlpha/Atom-7BFlagAlpha/Llama2-Chinese-7b-ChatFlagAlpha/Llama2-Chinese-7b-Chat-LoRAFlagAlpha/Llama2-Chinese-13b-ChatFlagAlpha/Llama2-Chinese-13b-Chat-LoRAFlagAlpha/Llama2-Chinese-13b-Chat-4bit复制
一.Llama2-Chinese项目介绍
 1.Llama相关论文
1.Llama相关论文
LLaMA: Open and Efficient Foundation Language Models
Llama 2: Open Foundation and Fine-Tuned Chat Models
Code Llama: Open Foundation Models for Code
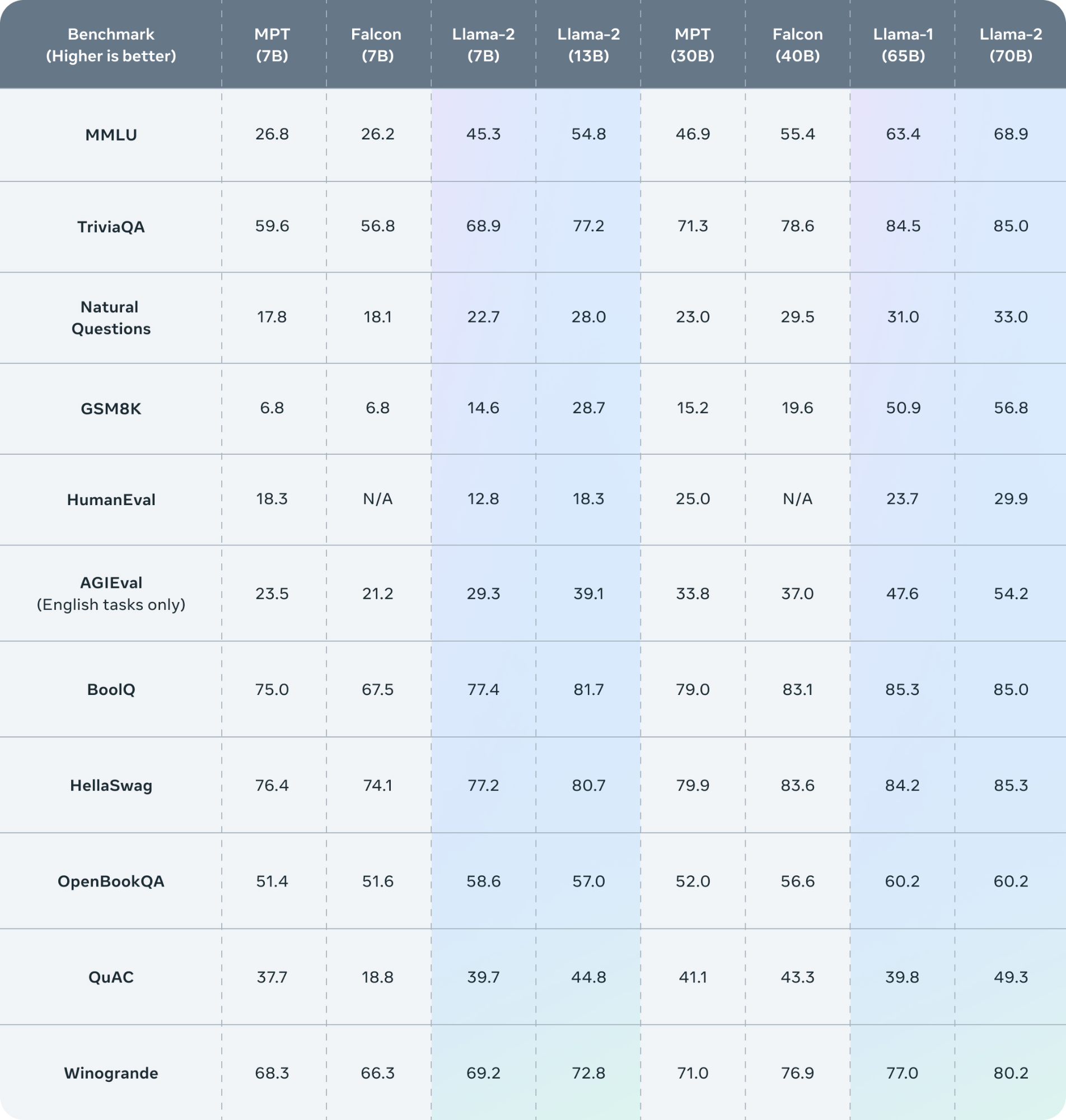
2.Llama2的评测结果
二.Atom-7B加载和推理
模型调用代码示例如下所示:
from transformers import AutoTokenizer, AutoModelForCausalLMfrom pathlib import Pathimport torchpretrained_model_name_or_path = r'L:/20230903_Llama2/Atom-7B'model = AutoModelForCausalLM.from_pretrained(Path(f'{pretrained_model_name_or_path}'), device_map='auto', torch_dtype=torch.float16, load_in_8bit=True) #加载模型model = model.eval() #切换到eval模式tokenizer = AutoTokenizer.from_pretrained(Path(f'{pretrained_model_name_or_path}'), use_fast=False) #加载tokenizertokenizer.pad_token = tokenizer.eos_token #为了防止生成的文本出现[PAD],这里将[PAD]重置为[EOS]input_ids = tokenizer(['<s>Human: 介绍一下中国\n</s><s>Assistant: '], return_tensors="pt", add_special_tokens=False).input_ids.to('cuda') #将输入的文本转换为tokengenerate_input = { "input_ids": input_ids, #输入的token "max_new_tokens": 512, #最大生成的token数量 "do_sample": True, #是否采样 "top_k": 50, #采样的top_k "top_p": 0.95, #采样的top_p "temperature": 0.3, #采样的temperature "repetition_penalty": 1.3, #重复惩罚 "eos_token_id": tokenizer.eos_token_id, #结束token "bos_token_id": tokenizer.bos_token_id, #开始token "pad_token_id": tokenizer.pad_token_id #pad token}generate_ids = model.generate(**generate_input) #生成tokentext = tokenizer.decode(generate_ids[0]) #将token转换为文本print(text) #输出生成的文本复制三.相关知识点
1.Fire库
解析:Fire是一个Google开发的库,用于自动生成Python命令行接口(CLI)。它可以帮助开发人员快速将Python对象和函数暴露为命令行工具。使用Fire可以自动创建命令行参数,参数类型和默认值等。
2.Llama1和Llama2区别
解析:
(1)Llama2采用Llama1的大部分预训练设置和模型架构,它们使用标准的Transformer架构,应用RMSNorm进行预归一化,使用SwiGLU激活函数和旋转位置编码。与Llama1相比,主要的架构差异包括增加的上下文长度和分组查询注意力(GQA)。
(2)Llama2总共公布了7B、13B和70B三种参数大小的模型。相比于LLaMA,Llama2的训练数据达到了2万亿token,上下文长度也由之前的2048升级到4096,可以理解和生成更长的文本。Llama2Chat模型基于100万人类标记数据微调得到,在英文对话上达到了接近ChatGPT的效果。
四.相关问题
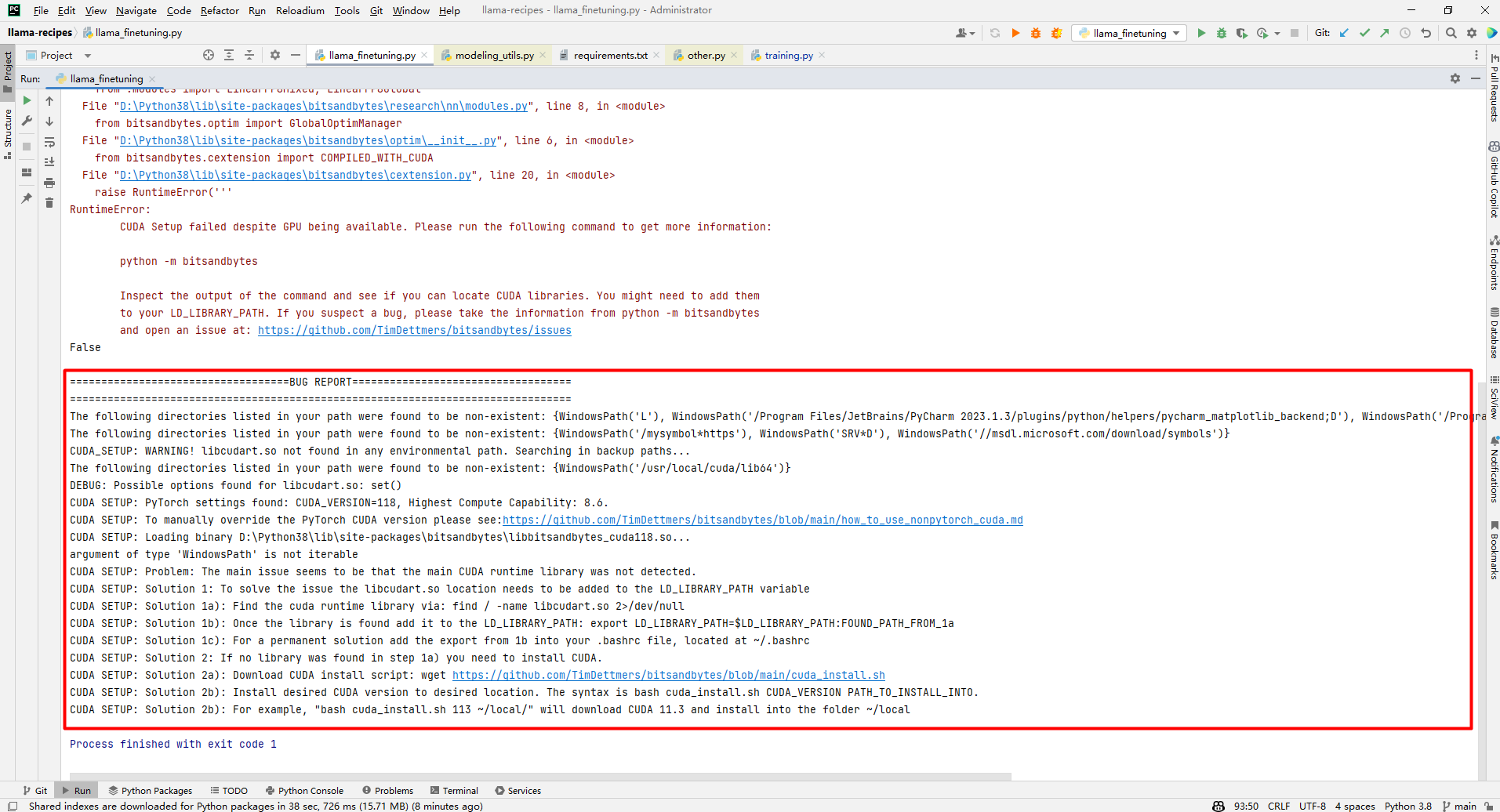
1.CUDA Setup failed despite GPU being available
解析:如下是网上介绍的解决方案,还有的建议源码编译,但是这2种方案都没有走通。
 (1)安装路径
(1)安装路径
cudart64_12.dllcublas64_12.dllcublasLt64_12.dllcusparse64_12.dllnvJitLink_120_0.dll复制
实践经验建议方式[8]为pip3 install https://github.com/jllllll/bitsandbytes-windows-webui/blob/main/bitsandbytes-0.39.0-py3-none-any.whl。有图有证据如下所示:

(2)修改文件 D:\Python38\Lib\site-packages\bitsandbytes\cuda_setup\main.py
if not torch.cuda.is_available(): return 'libsbitsandbytes_cpu.so', None, None, None, None替换为if torch.cuda.is_available(): return 'libbitsandbytes_cuda116.dll', None, None, None, Noneself.lib = ct.cdll.LoadLibrary(binary_path)替换为self.lib = ct.cdll.LoadLibrary(str(binary_path))(3)添加libbitsandbytes_cuda116.dll和libbitsandbytes_cpu.dll
存放路径为D:\Python38\Lib\site-packages\bitsandbytes,下载地址参考[0]。
2.RuntimeError: cuDNN error: CUDNN_STATUS_NOT_INITIALIZED
解析:下载链接为[7],下载之前需要NVIDIA社区账号登录。
 (1)解压cudnn-windows-x86_64-8.9.4.25_cuda12-archive.zip
(1)解压cudnn-windows-x86_64-8.9.4.25_cuda12-archive.zip
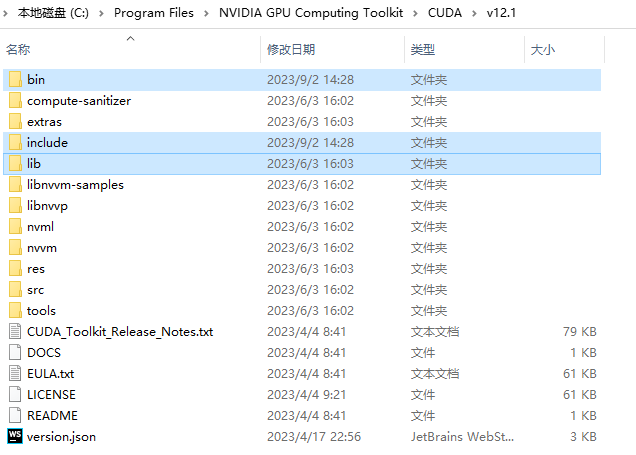
 (2)拷贝到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.1
(2)拷贝到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.1
参考文献:
[0]https://github.com/DeXtmL/bitsandbytes-win-prebuilt/tree/main
[1]https://github.com/facebookresearch/llama
[2]https://github.com/facebookresearch/llama-recipes/
[3]https://huggingface.co/meta-llama/Llama-2-7b-hf/tree/main
[4]https://huggingface.co/spaces/ysharma/Explore_llamav2_with_TGI
[5]https://huggingface.co/meta-llama/Llama-2-70b-chat-hf
[6]https://huggingface.co/blog/llama2
[7]https://developer.nvidia.com/rdp/cudnn-download
[8]https://github.com/jllllll/bitsandbytes-windows-webui
[9]https://github.com/langchain-ai/langchain
[10]https://github.com/AtomEcho/AtomBulb
[11]https://github.com/huggingface/peft
[12]全参数微调时,报没有target_modules变量:https://github.com/FlagAlpha/Llama2-Chinese/issues/169
[13]https://huggingface.co/FlagAlpha
[14]https://llama.family/