以前使用Neo4j图数据库,考虑到生产环境需要最终选择了NebulaGraph图数据库。对于数据要求比较高的领域,比如医疗、财务等,暂时还是离不开知识图谱的。后面主要围绕LLM+KG做一些行业解决方案和产品,涉及的技术主要是对话、推荐、检索这3个大的方向,可用于客服系统和聊天机器人等。
1.安装NebulaGraph
首先电脑上安装好Docker、Docker Compose和Git,然后使用Docker Compose部署NebulaGraph服务:
git clone -b release-3.6 https://github.com/vesoft-inc/nebula-docker-compose.git
cd nebula-docker-compose/
docker-compose up -d
复制 运行成功后Docker Desktop界面如下所示:
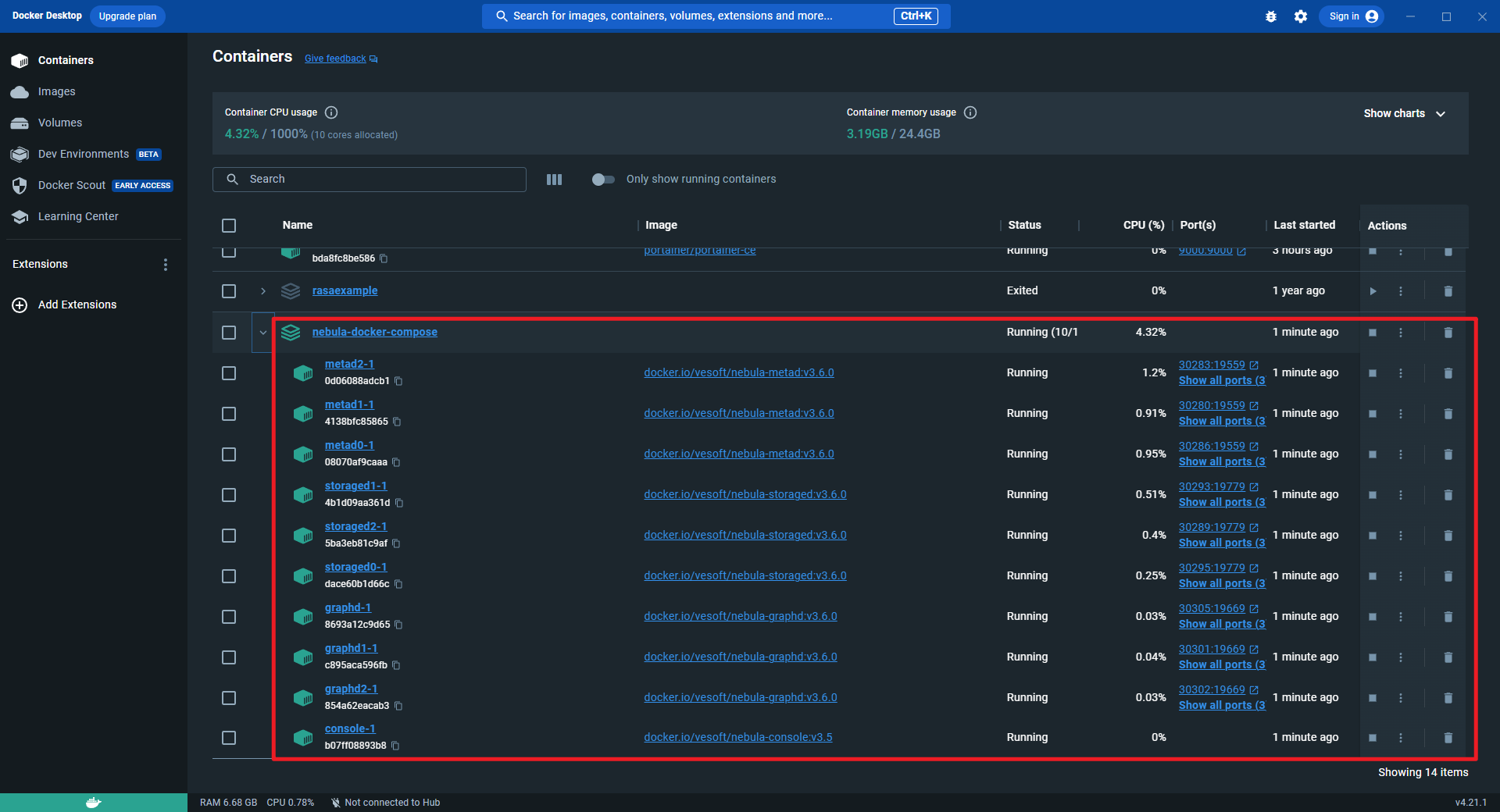
2.安装NebulaGraph Studio
NebulaGraph Studio是一款可以通过Web访问的开源图数据库可视化工具,搭配NebulaGraph内核使用,提供构图、数据导入、编写nGQL查询等一站式服务。如下所示:
wget https://oss-cdn.nebula-graph.com.cn/nebula-graph-studio/3.7.0/nebula-graph-studio-3.7.0.tar.gz
mkdir nebula-graph-studio-3.7.0 && tar -zxvf nebula-graph-studio-3.7.0.tar.gz -C nebula-graph-studio-3.7.0
cd nebula-graph-studio-3.7.0
docker-compose pull
docker-compose up -d
复制 运行成功后Docker Desktop界面如下所示:

3.连接数据库
打开链接http://localhost:7001/login,如下所示:

根据实际情况输入NebulaGraph的Graph服务本机IP地址,以及用户名root和密码nebula,如下所示:
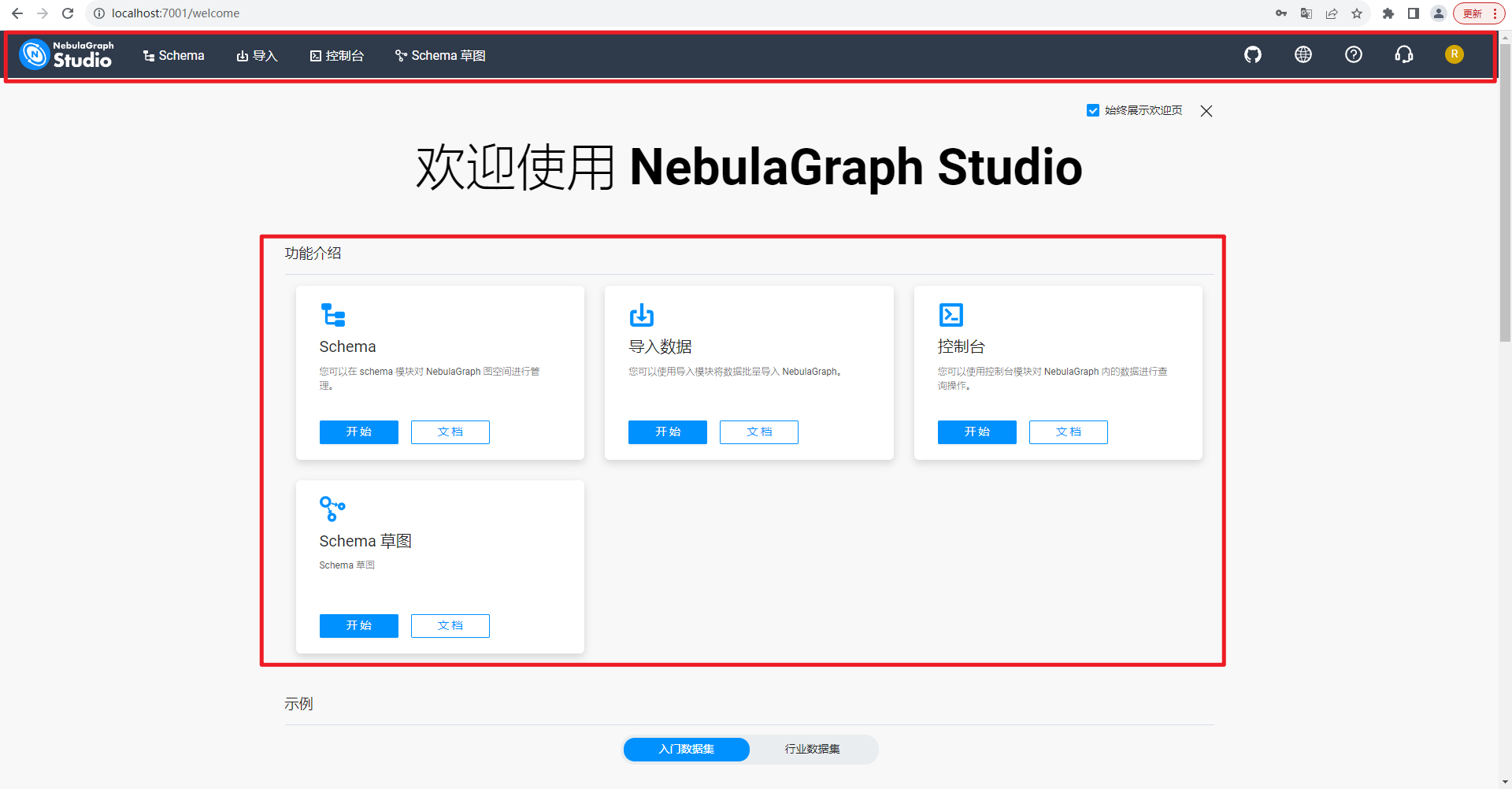
除了功能介绍外,还有入门和行业数据集、学习文档,如下所示:
4.NebulaGraph Python
NebulaGraph Python是一款Python语言的客户端,可以连接、管理NebulaGraph图数据库。安装命令为pip3 install nebula3-python。Nebula-Python版本和NebulaGraph版本间的匹配关系,如下所示:
| Nebula-Python版本 | NebulaGraph版本 |
|---|---|
| 1.0 | 1.x |
| 2.0.0 | 2.0.0/2.0.1 |
| 2.5.0 | 2.5.0 |
| 2.6.0 | 2.6.0/2.6.1 |
| 3.0.0 | 3.0.0 |
| 3.1.0 | 3.1.0 |
| 3.3.0 | 3.3.0 |
| master | master |
NebulaGraph Python客户端提供Connection Pool和Session Pool两种使用方式,使用Connection Pool需要用户自行管理Session实例。如下所示:
from nebula3.gclient.net import ConnectionPool
from nebula3.Config import Config
config = Config() # 定义一个配置
config.max_connection_pool_size = 10 # 设置最大连接数
connection_pool = ConnectionPool() # 初始化连接池
# 如果给定的服务器是ok的,返回true,否则返回false
ok = connection_pool.init([('172.27.211.84', 9669)], config)
# 方式1:connection pool自己控制连接释放
# 从连接池中获取一个session
session = connection_pool.get_session('root', 'nebula')
session.execute('USE nba') # 选择space
result = session.execute('SHOW TAGS') # 展示tags
print(result) # 打印结果
session.release() # 释放session
# 方式2:Session Pool,session将自动释放
with connection_pool.session_context('root', 'nebula') as session:
session.execute('USE nba')
result = session.execute('SHOW TAGS')
print(result)
# 关闭连接池
connection_pool.close()
复制说明:后续分享NebulaGraph、LLM、LlamaIndex、Graph RAG、Agent与实际行业结合的实践操作。
参考文献:
[1]连接数据库:https://docs.nebula-graph.com.cn/3.6.0/nebula-studio/deploy-connect/st-ug-connect/
[2]基于Docker Compose快速部署:https://docs.nebula-graph.com.cn/3.6.0/2.quick-start/1.quick-start-overview/
[3]https://github.com/vesoft-inc/nebula-studio
[4]https://github.com/vesoft-inc
[5]LLM:大模型下的知识图谱另类实践:https://www.nebula-graph.com.cn/posts/llm-implement
[6]Graph RAG:知识图谱结合LLM的检索增强:https://www.nebula-graph.com.cn/posts/graph-rag-llm
[7]知识图谱驱动的大语言模型Llama Index:https://www.nebula-graph.com.cn/posts/knowgraph-with-llamaindex
[8]关于LLM和图、图数据库的那些事:https://www.nebula-graph.com.cn/posts/llm-database