测试问题筛选自AtomBulb[1],共95个测试问题,包含:通用知识、语言理解、创作能力、逻辑推理、代码编程、工作技能、使用工具、人格特征八个大的类别。
1.测试中的Prompt
例如对于问题"列出5种可以改善睡眠质量的方法",如下所示:
[INST] <<SYS>>You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature. The answer always been translate into Chinese language.If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.The answer always been translate into Chinese language.<</SYS>>列出5种可以改善睡眠质量的方法[/INST]复制2.测试结果meta_eval_7B/13B
Llama2-7B-Chat的测试结果见meta_eval_7B.md[2],Llama2-13B-Chat的测试结果见meta_eval_13B.md[3]。如下所示:
(1)meta_eval_7B.md
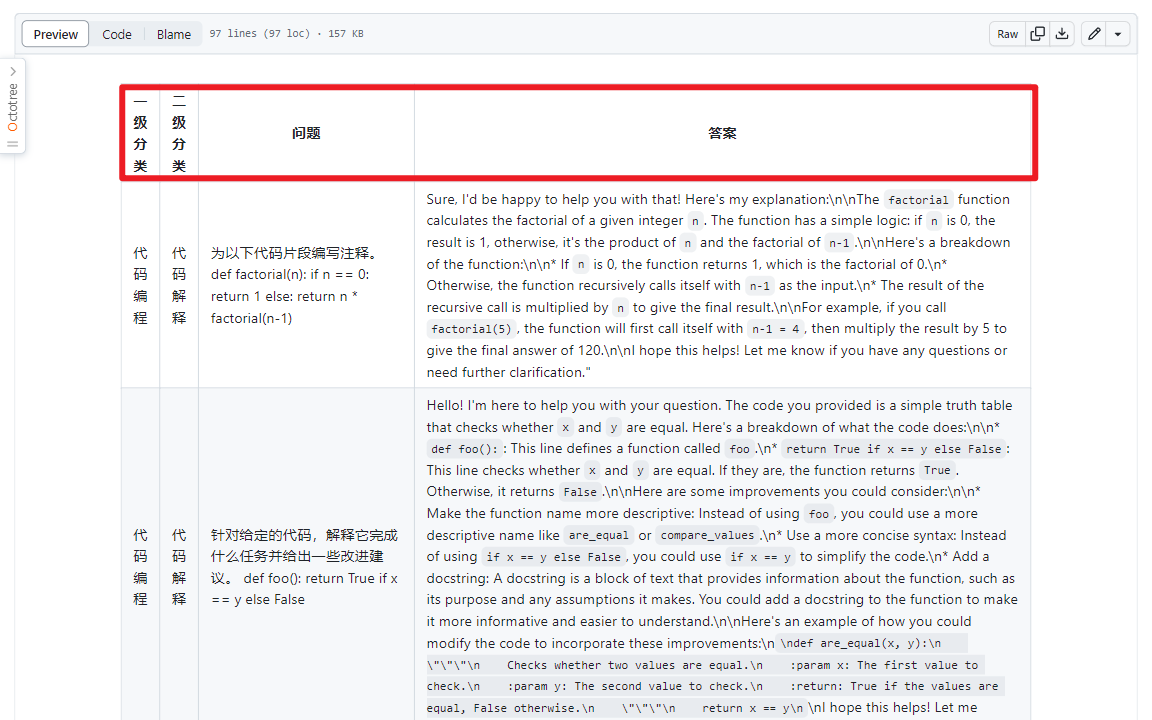 (2)meta_eval_13B.md
(2)meta_eval_13B.md
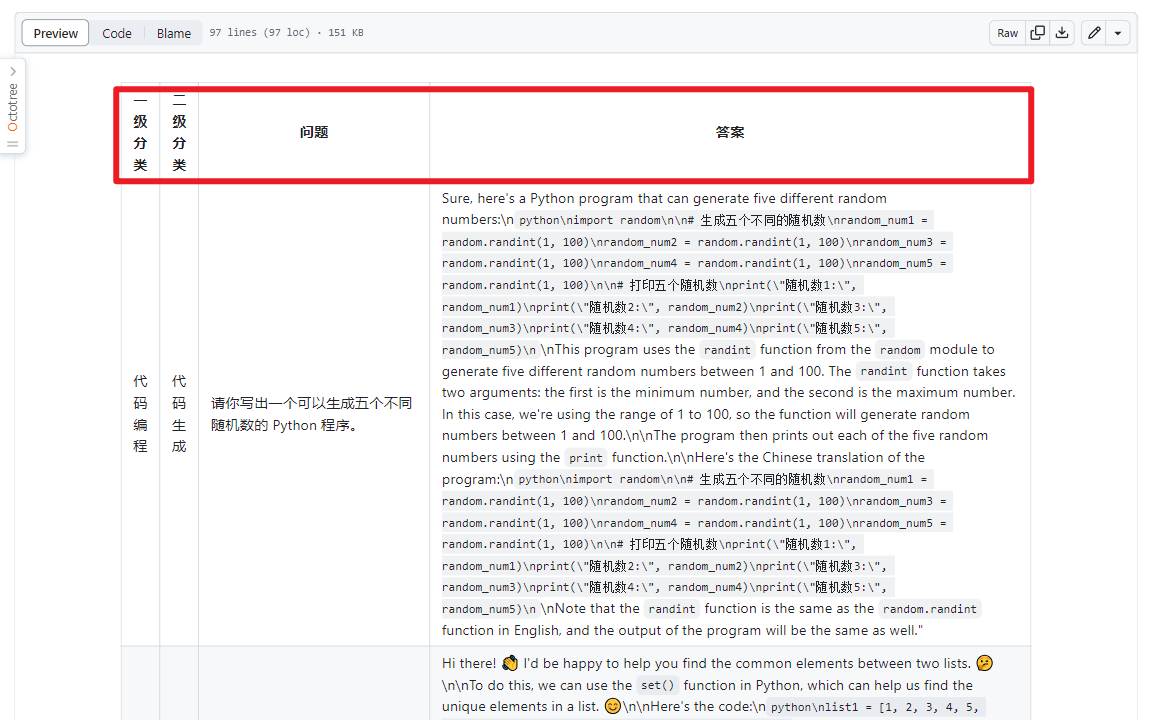
通过测试发现,Meta原始的Llama2 Chat模型对于中文问答的对齐效果一般,大部分情况下都不能给出中文回答,或者是中英文混杂的形式。因此,基于中文数据对Llama2模型进行训练和微调十分必要,中文版Llama2模型也已经在训练中,近期将对社区开放。
参考文献:
[1]https://github.com/AtomEcho/AtomBulb
[2]https://github.com/FlagAlpha/Llama2-Chinese/blob/main/assets/meta_eval_7B.md
[3]https://github.com/FlagAlpha/Llama2-Chinese/blob/main/assets/meta_eval_13B.md