TRL(Transformer Reinforcement Learning)是一个使用强化学习来训练Transformer语言模型和Stable Diffusion模型的Python类库工具集,听上去很抽象,但如果说主要是做SFT(Supervised Fine-tuning)、RM(Reward Modeling)、RLHF(Reinforcement Learning from Human Feedback)和PPO(Proximal Policy Optimization)等的话,肯定就很熟悉了。最重要的是TRL构建于transformers库之上,两者均由Hugging Face公司开发。
一.TRL类库
1.TRL类库介绍
简单理解就是可以通过TRL库做RLHF训练,如下所示:
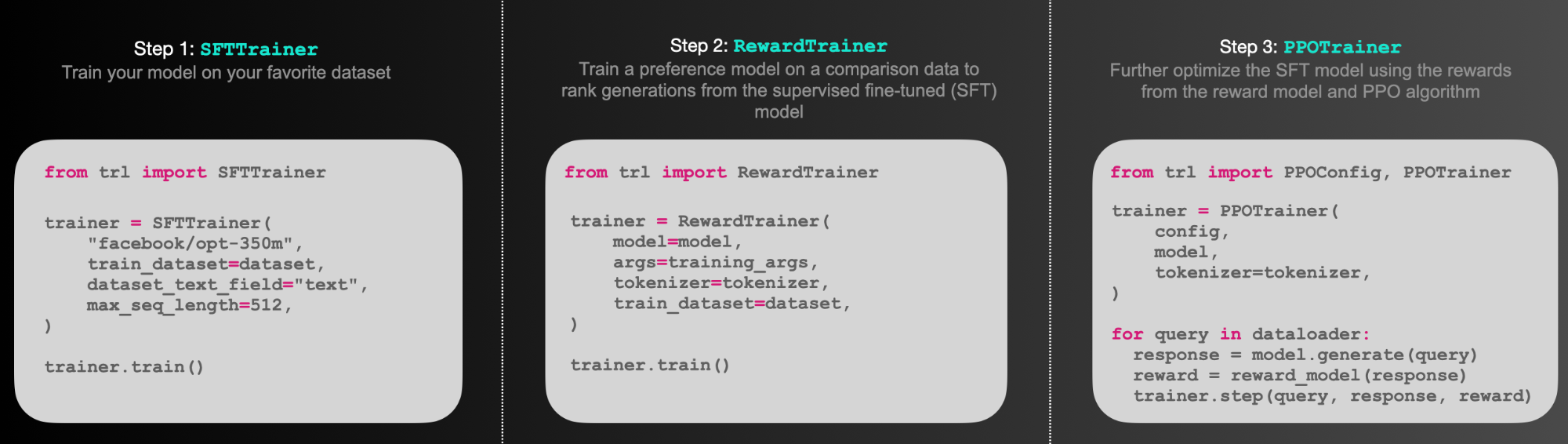 (1)
(1)SFTTrainer:是一个轻量级、友好的transformers Trainer包装器,可轻松在自定义数据集上微调语言模型或适配器。
(2)RewardTrainer:是一个轻量级的transformers Trainer包装器,可轻松为人类偏好(奖励建模)微调语言模型。
(3)PPOTrainer:一个PPO训练器,用于语言模型,只需要(query, response, reward)三元组来优化语言模型。
(4)AutoModelForCausalLMWithValueHead & AutoModelForSeq2SeqLMWithValueHead:一个带有额外标量输出的transformer模型,每个token都可以用作强化学习中的值函数。
(5)Examples:使用BERT情感分类器训练GPT2生成积极的电影评论,仅使用适配器的完整RLHF,训练GPT-j以减少毒性,Stack-Llama例子等。
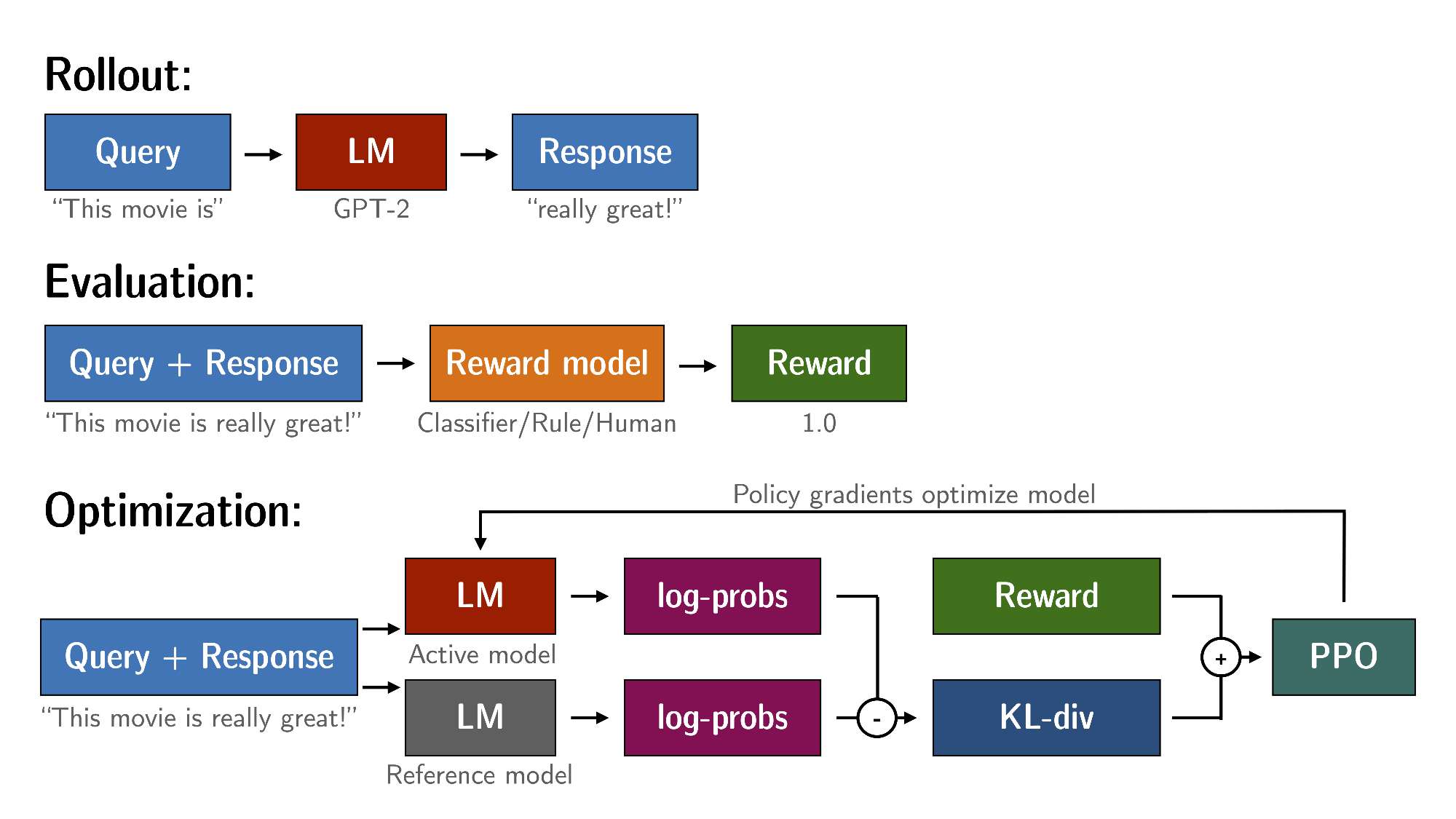
2.PPO工作原理
通过PPO对语言模型进行微调大致包括三个步骤:
(1)Rollout:语言模型根据query生成response或continuation,query可以是一个句子的开头。
(2)Evaluation:使用函数、模型、人类反馈或它们的某些组合对查询和响应进行评估。重要的是,此过程应为每个query/response对生成一个标量值。
(3)Optimization:这是最复杂的部分。在优化步骤中,query/response对用于计算序列中token的对数概率。这是使用经过训练的模型和Reference model完成的,Reference model通常是微调前的预训练模型。两个输出之间的KL散度用作额外的奖励信号,以确保生成的response不会偏离Reference model太远。然后使用PPO训练Active model。
二.TRL安装和使用方式
1.TRL安装
# 直接安装包pip install trl# 从源码安装git clone https://github.com/huggingface/trl.gitcd trl/pip install .复制2.SFTTrainer使用方式
SFTTrainer是围绕transformer Trainer的轻量级封装,可以轻松微调自定义数据集上的语言模型或适配器。如下所示:
# 导入Python包from datasets import load_datasetfrom trl import SFTTrainer# 加载imdb数据集dataset = load_dataset("imdb", split="train")# 得到trainertrainer = SFTTrainer( "facebook/opt-350m", train_dataset=dataset, dataset_text_field="text", max_seq_length=512,)# 开始训练trainer.train()复制3.RewardTrainer使用方式
RewardTrainer是围绕transformers Trainer的封装,可以轻松在自定义偏好数据集上微调奖励模型或适配器。如下所示:
# 导入Python包from transformers import AutoModelForSequenceClassification, AutoTokenizerfrom trl import RewardTrainer# 加载模型和数据集,数据集需要为指定格式model = AutoModelForSequenceClassification.from_pretrained("gpt2", num_labels=1)tokenizer = AutoTokenizer.from_pretrained("gpt2")...# 得到trainertrainer = RewardTrainer( model=model, tokenizer=tokenizer, train_dataset=dataset,)# 开始训练trainer.train()复制4.PPOTrainer使用方式
query通过语言模型输出一个response,然后对其进行评估。评估可以人类反馈,也可以是另一个模型的输出。如下所示:
# 导入Python包import torchfrom transformers import AutoTokenizerfrom trl import PPOTrainer, PPOConfig, AutoModelForCausalLMWithValueHead, create_reference_modelfrom trl.core import respond_to_batch# 首先加载模型,然后创建参考模型model = AutoModelForCausalLMWithValueHead.from_pretrained('gpt2')model_ref = create_reference_model(model)tokenizer = AutoTokenizer.from_pretrained('gpt2')# 初始化ppo配置对象ppo_config = PPOConfig( batch_size=1,)# 编码一个queryquery_txt = "This morning I went to the "query_tensor = tokenizer.encode(query_txt, return_tensors="pt")# 得到模型responseresponse_tensor = respond_to_batch(model, query_tensor)# 创建一个ppo trainerppo_trainer = PPOTrainer(ppo_config, model, model_ref, tokenizer)# 为response定义一个reward(人类反馈或模型输出奖励) reward = [torch.tensor(1.0)]# 使用ppo训练一步模型train_stats = ppo_trainer.step([query_tensor[0]], [response_tensor[0]], reward)复制参考文献:
[1]https://github.com/huggingface/trl
[2]https://huggingface.co/docs/trl/v0.7.1/en/index