什么是CUDA?CUDA(Compute Unified Device Architecture,统一计算设备架构)是NVIDIA(英伟达)提出的并行计算架构,结合了CPU和GPU的优点,主要用来处理密集型及并行计算。什么是异构计算?这里的异构主要指的是主机端的CPU和设备端的GPU,CPU更擅长逻辑控制,而GPU更擅长计算。CUDA编程难吗?干就是了。
一.异构架构编程思维
1.异构架构
一个典型的异构计算节点包括2个多核CPU插槽和2个或更多个的众核GPU。GPU通过PCIe总线与基于CPU的主机相连来进行操作。CPU是主机端,而GPU是设备端,这样一个异构应用就包含主机代码(逻辑)和设备代码(计算)。


2.CUDA平台
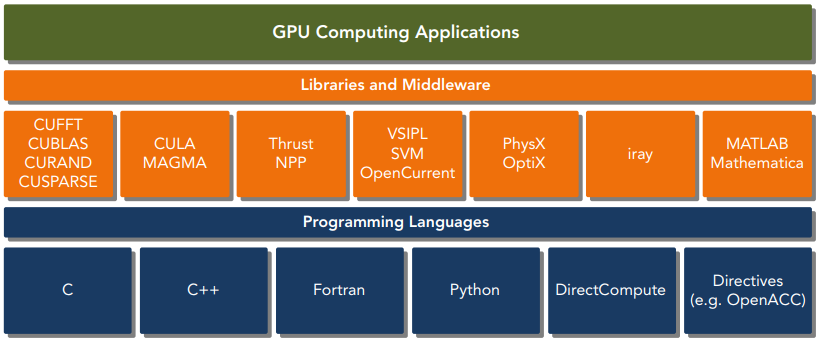
CUDA平台可以通过CUDA加速库、编译器指令、应用编程接口以及行业标准程序语言的扩展(包括C|C++|Fortran|Python等)来使用。CUDA提供了2层API来管理GPU设备和组织线程,其中驱动API是一种低级API,它相对来说较难编程,但是它对于在GPU设备使用上提供了更多的控制,每个运行时API函数都被分解为更多传给驱动API的基本运算。

二.Hello World例子实战
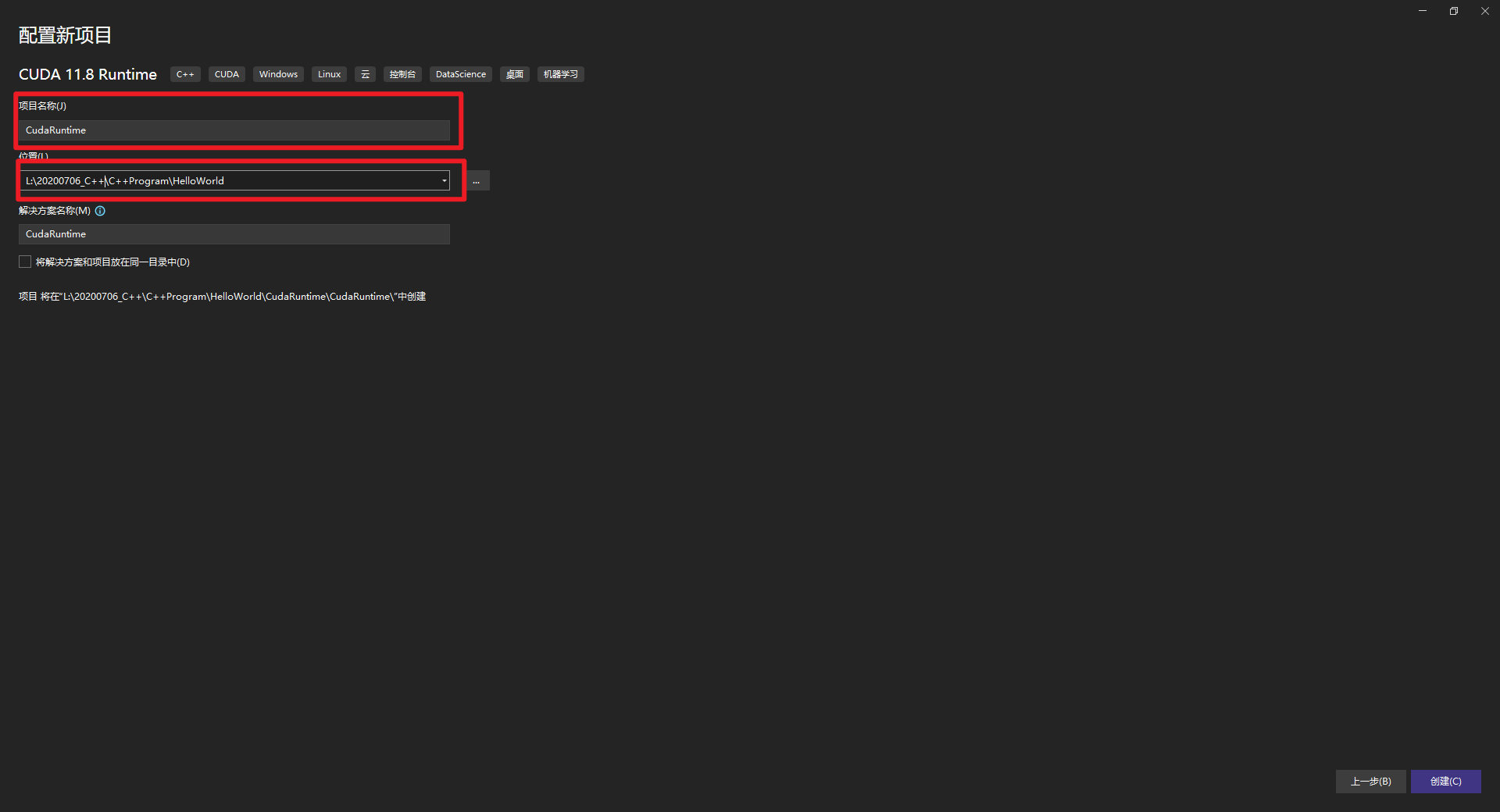
1.VS 2022开发方式
安装好VS 2022和CUDA 11.8,然后创建一个CUDA项目,如下所示:

 Hello World例子实战,如下所示:
Hello World例子实战,如下所示:
#include "cuda_runtime.h" // CUDA#include "device_launch_parameters.h"#include <stdio.h>__global__ void helloFromGPU(void){ printf("Hello World from GPU!\n");}int main(void) { // hello from cpu printf("Hello World from GPU!\n"); helloFromGPU<<<1,10>>>(); cudaDeviceReset(); return 0;}复制2.Clion开发方式(推荐)
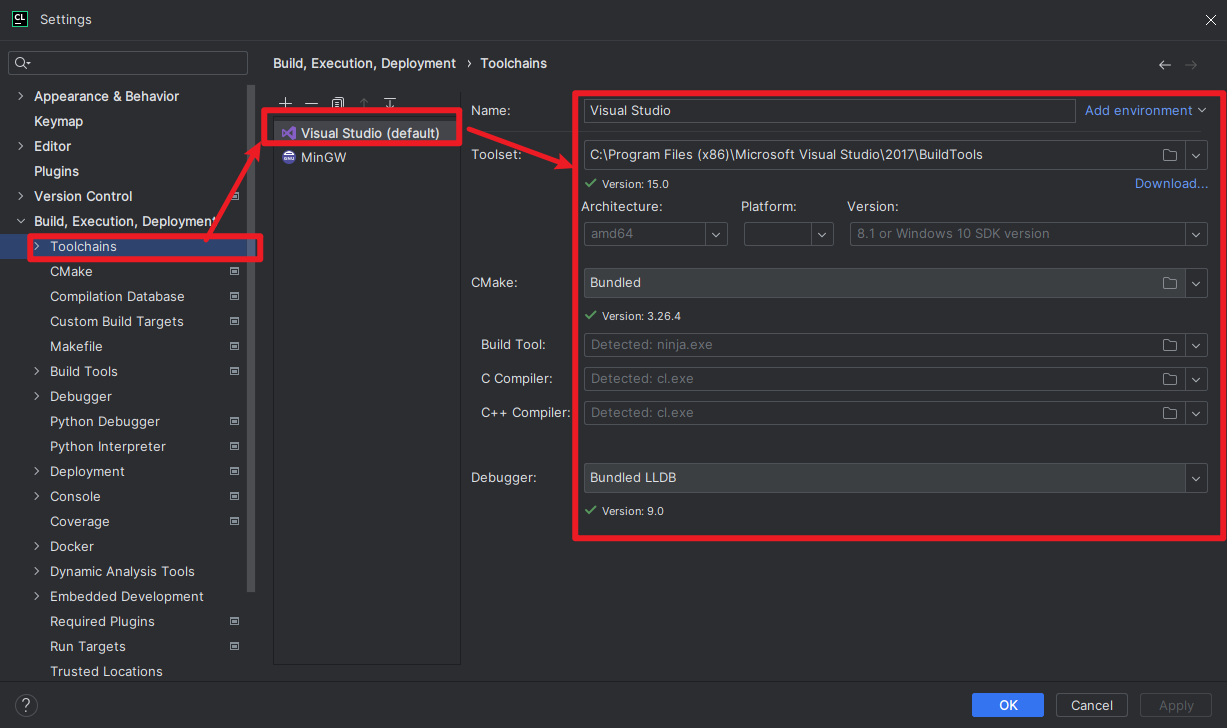
如果经常使用PyCharm进行Python编程,可能会更习惯Clion这个IDE吧。新建一个CUDA项目,使用10个线程输出"Hello World from GPU!",如下所示:


 CMakeLists.txt如下所示:
CMakeLists.txt如下所示:
cmake_minimum_required(VERSION 3.26) # CMake版本要求,VERSION是版本,3.26是3.26版本project(20231003_ClionProgram CUDA) # 项目名称,CUDA是CUDA项目set(CMAKE_CUDA_STANDARD 17) # C++标准,CMAKE_CUDA_STANDARD是C++标准,17是C++17add_executable(20231003_ClionProgram main.cu) # 可执行文件set_target_properties(20231003_ClionProgram PROPERTIES CUDA_SEPARABLE_COMPILATION ON) # 设置可分离编译,PROPERTIES是属性,CUDA_SEPARABLE_COMPILATION是可分离编译,ON是开启复制main.cu文件如下所示:
#include "cuda_runtime.h" // CUDA运行时API#include <stdio.h> // 标准输入输出__global__ void helloFromGPU(void) // GPU核函数{ printf("Hello World from GPU!\n"); //输出Hello World from GPU!}int main(void) // 主函数{ // hello from cpu printf("Hello World from GPU!\n"); //CPU主机端输出Hello World from CPU! helloFromGPU<<<1,10>>>(); // 调用GPU核函数,10个线程块,1表示每个grid中只有1个block,10表示每个block中有10个线程 cudaDeviceReset(); // 重置当前设备上的所有资源状态,清空当前设备上的所有内存 return 0;}复制参考文献:
[1]《CUDA C编程权威指南》
在CUDA程序中, 访存优化个人认为是最重要的优化项. 往往kernel会卡在数据传输而不是计算上, 为了最大限度利用GPU的计算能力, 我们需要根据GPU硬件架构对kernel访存进行合理的编写.