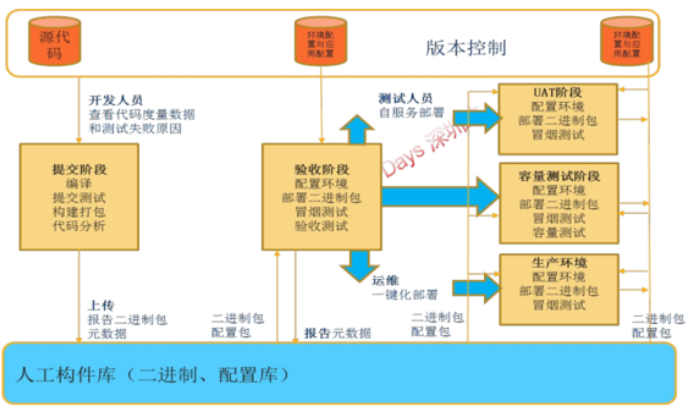
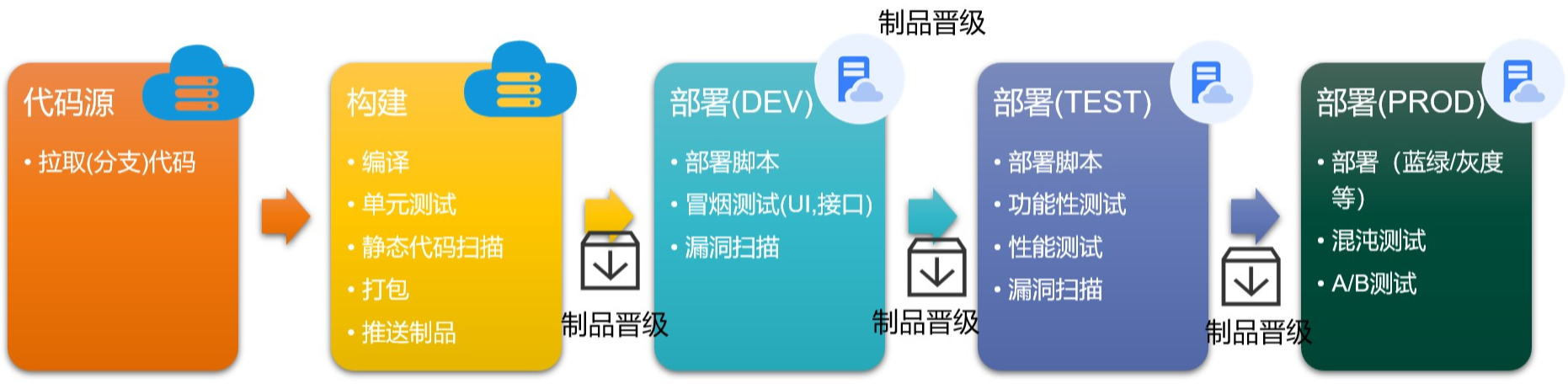
在实践中,很多团队对于DevOps 流水线没有很透彻的理解,要不就创建一大堆流水线,要不就一个流水线通吃。实际上,流水线的设计和写代码一样,需要基于“业务场景”进行一定的设计编排,特别是很多通过“开源工具”搭建的流水线,更需要如此(商业的一体化平台大部分已经把设计思想融入自己产品里了)。
清晰的代码结构,标准的环境配置,原子化的流水线任务编排,再加上团队的协作纪律,和持续优化的动作,才是真正的践行CI/CD实践
1. 确定好变量
2. 流水线变量/命名的规范化
3. 一次构建,多次部署
4. 步骤标准化/原子化
5. 快速失败
流水线分步骤实施, 从 “点” 到 “线” 结合业务需要串起来,适合自己团队协作开发节奏的流水线才是最好的。
由于产品本身的形态不同,负责研发的团队人员组成不同,代码的版本管理分支策略不同,使用的部署流水线形式也会各不相同,所以基于实际业务场景设计流水线是团队工程实践成熟的重要标志。
适用场景:每名研发工程师都创建了自己专属的流水线(一般对应个人的开发分支),用于个人在未推送代码到团队仓库之前的快速质量反馈。
注意:个人流水线并不会部署到 团队共同拥有的环境中,而是仅覆盖个人开发环节。如图所示,虚线步骤非必选
适用场景:每个团队都根据代码仓库(master/release/trunk)分支,创建产品专属的流水线,部署到 团队共同拥有的环境中e.g. dev)。
注意:如图所示,虚线步骤非必选,根据情况可通过 启动参数true/flase 跳过执行,自动化测试仅限于保证基本功能的用例。
适用场景:每个团队的测试工程师都需要专门针对提测版本的自动化部署/测试流水线,部署到团队共同拥有的环境中(e.g. test).
注意:如图所示,该条流水线的起点不是代码,而是提测的特定版本安装包;虚线步骤非必选,根据情况可通过 启动参数true/flase 跳过执行 或 裁剪。
适用场景:如果一个产品由多个组件构建而成,每个组件均有独自的代码仓库,并且每个组件由一个单独的团队负责开发与维护,那么,整个产品 的部署流水线的设计通常如下图所示。 集成部署流水线的集成打包阶段将自动从企业软件包库中获取每个组件最近成功的软件包,对其进行产品集成打包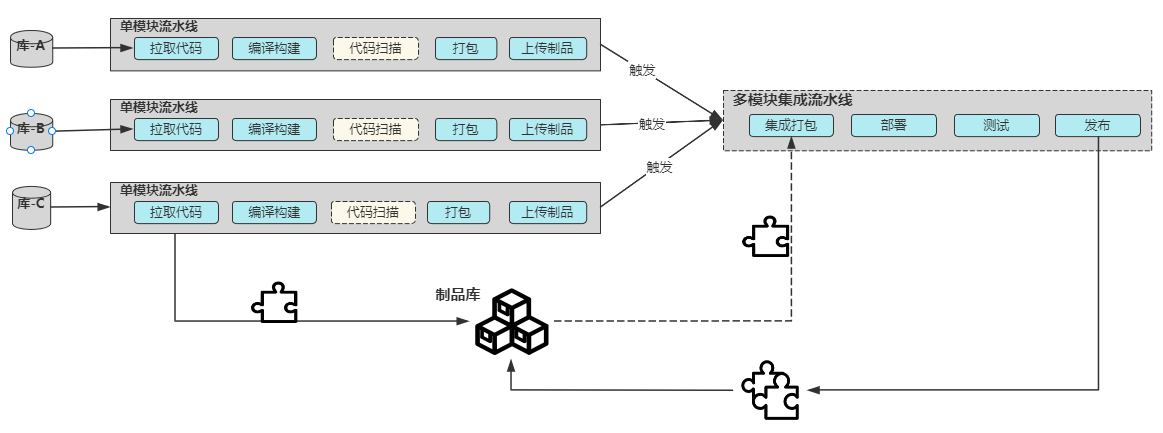
适用场景:适用于和代码变更无关的场景,不存在上面步骤复杂的编排 (也可通过上述流水线的 启动参数进行条件控制,跳过一些步骤)
适用场景:需求、代码构建、测试、部署环境内嵌自动化能力,每次提交都触发完整流水线,中间通过人工审批层次卡点,从dev环境,test环境,stage环境一直到 prod环境。 常适用于快速发布的 PASS/SASS服务,对团队各项能力和流程制度要求较高,支持快速发布(策略)和快速回滚(策略)
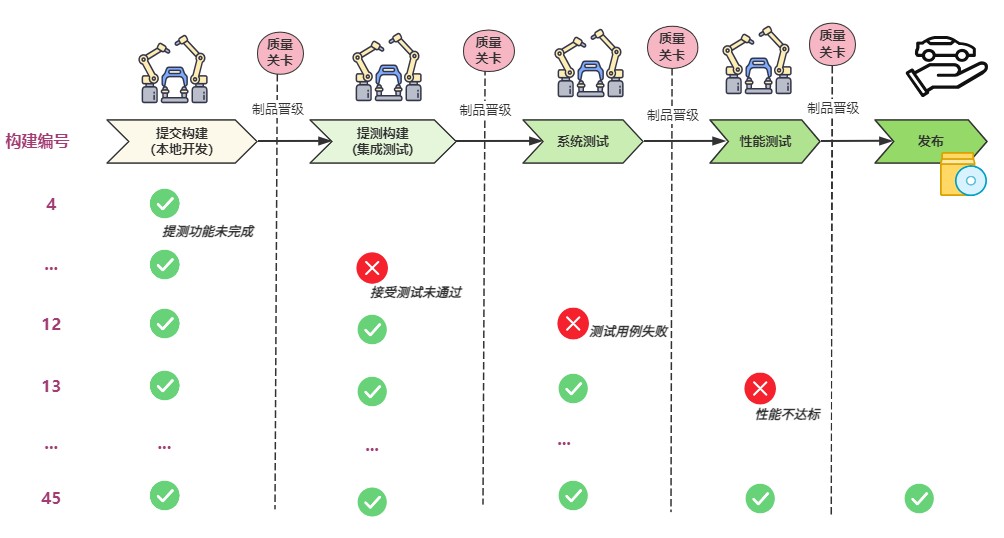
团队研发工程师每人每天都会提交一次。因此,流水线每天都会启动多次。当然并不是每次提交的变更都会走到最后的“上传发布” 。 也不是每次提交都会走到UAT 部署,因为开发人员并不是完成一个功能需求后才提交代码,而是只要做完一个开发任务,就可以提交。每个功能可能由 多个开发任务组成,研发工程师需要确保即使提交了功能尚未开发完成的代码,也不会影响已开发完成的那些功能。
制品经过一个个质量卡点,经历各种门禁验证,最终交付给客户 可以工作的软件