作者:京东物流 何小坡
面对数据的激增,相信大家也都有分库分表的一些方案,这次的这个分享,算是自己的一个想法,可以当做一个参考方案,也欢迎相互讨论。
话不多说,直接进入主题。
日常开发中,实现数据库的分库分表,在经常使用工具方面,常用的有像 sharding-sphere、TDDL、Mycat等,然后,根据主键key做数据分布,有两种常用的方案,Hash取模方案和Range范围两种方案,两种路由算法,通过指定的key值进行运算后进行数据路由。两种方案也各有各的优缺点,下面做个梳理。
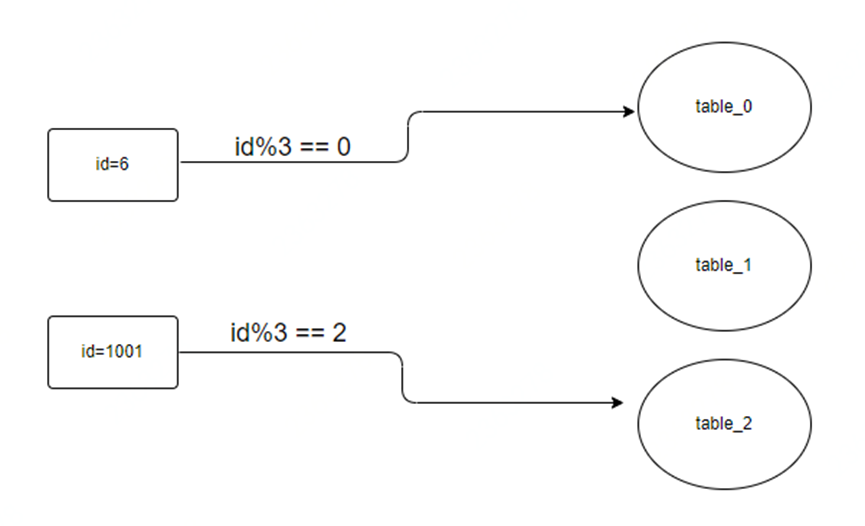
这个方案比较好理解,例如,我们假设未来几年内,数据能够增长到3000万,那,我们可以设计3张表,设表名分别为:table_0, table_1, table_2, 每张表存1000万数据,我们利用id作为路由key,进行算法处理,将hash运算后的结果与3进行取模,然后根据所得的值,可以将数据存放到对应的表中。这种方式的优点是,数据可以均匀分散的存储到对应的表中,不会造成数据全部存储到一个表中的情况,造成热点库表;但是缺点的话也很明显,就是如果以后再需要扩容的话,再新增表后,例如又新增了 table_3, table_4, table_5, 新的取模就从3变成了6,那这时候,之前的表中的数据,就需要做全量的数据迁移,因为取模的值发生了变化,按照新值取模,可能就找不到数据了。那面对大量的已有数据,数据迁移就比较麻烦了。
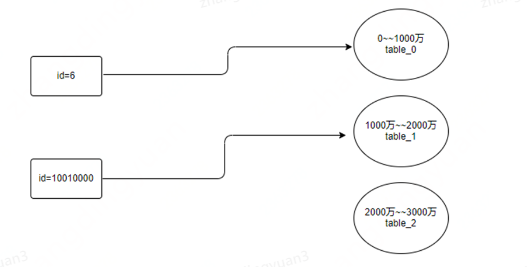
这个方案,也比较好理解,还假设业务后期数据能增长到3000万,也是可以设计3张表,设为:table_0, table_1, table_2,我看可以按照范围,将id在0—1000万的数据,存放在table_0中,id在1000万—2000万,存放在table_1中,id在2000万—3000万,存放在table_2中。这种方案的话,优点很明显,就是即使以后扩容,也很方便,直接增加新的表即可;但是缺点的话,也很明显,数据不能做分散存储,在某一段儿时间内,数据都会集中存储在特定的表中,造成单个表压力过大。
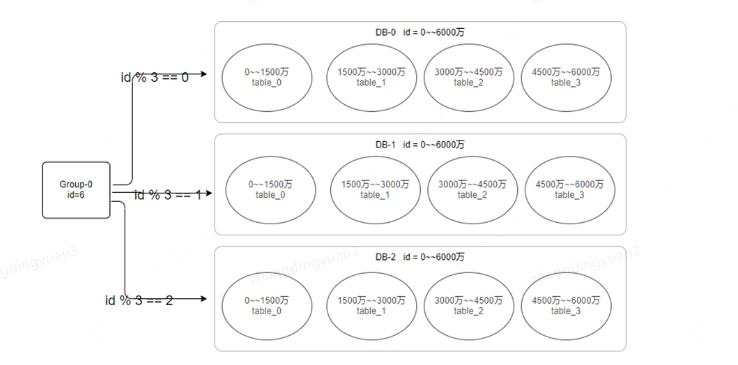
基于以上两种方式的优势和劣势,可以设计一种能够兼顾两者优势的方案,即能使数据能够分散存储,也能方便以后的扩容。以下算是一个方案。主要就是利用hash算法来实现数据的分散存储,利用range方式能够比较好的扩容,将两种方案的优势结合使用。
我们假设有一个分组的概念,假设项目初期,预期几年内的数据,数据可以达到6000万,可以做如下设计:
如果后面涉及到扩容,那只需要再直接增加一个分组即可,在分组内,实现数据的分散存储,扩容也比较方便。
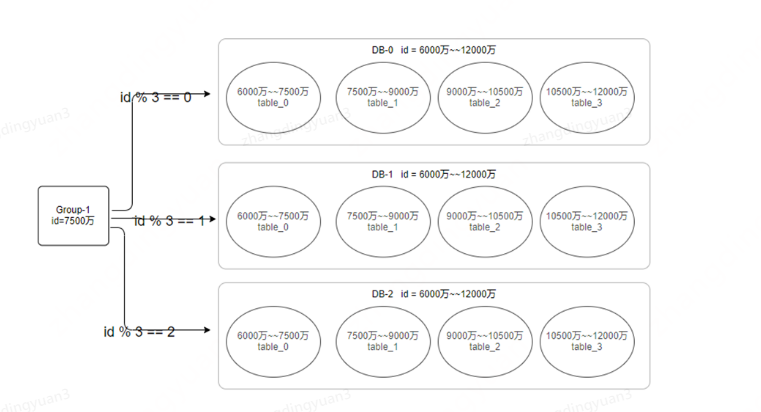
即每次扩容,只需要整体增加一个分组即可,一个分组下,可以存储将近几年的数据,所以也不用经常扩容。然后,也可以根据业务情况,将旧数据做归档处理,像现在优惠券系统的数据,旧数据就可以做整体归档处理,不影响正常业务情况,也减轻生产库的压力。
分库分表作为大型应用项目的架构实现方案,确实有一定的复杂性,可以根据当前项目的实际情况,使用适合的工具,做具体开发,最主要的还是需要结合自己的项目的实际业务情况来定,根据数据的分布以及数据的增长速度,来做结合项目场景的设计。也欢迎大伙一起讨论,如果有别的更精妙的“秘籍”,也希望不吝赐教,谢谢。