由于项目场景原因,需要将A库(MySQL)中的表a、表b、表c中的数据定时T+1 增量的同步到B库(MySQL)。这里说明一下,不是数据库的主从备份,就是普通的数据同步。经过技术调研,发现Kettle挺合适的,原因如下:
官网地址:https://sourceforge.net/projects/pentaho/files/Data%20Integration/
出现以下图片表示正在启动,如果一直没有反应,使用管理员身份运行。

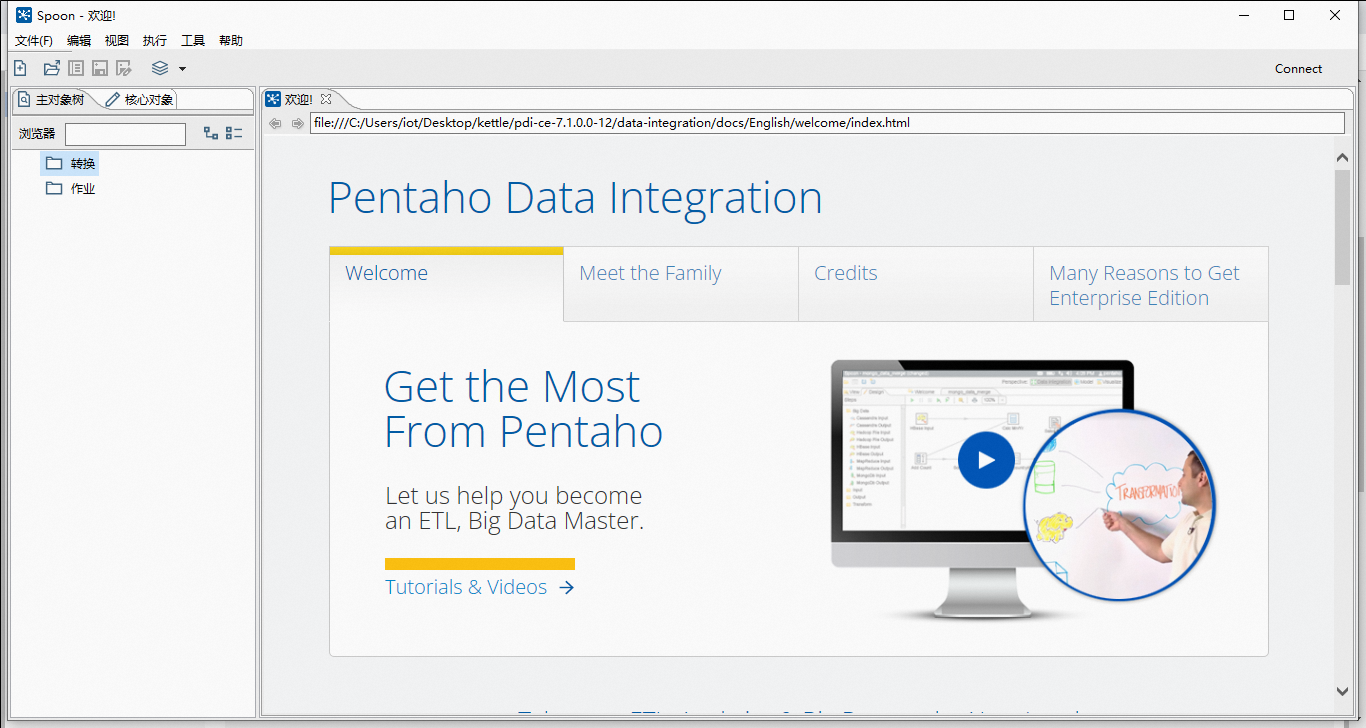
主界面如下:
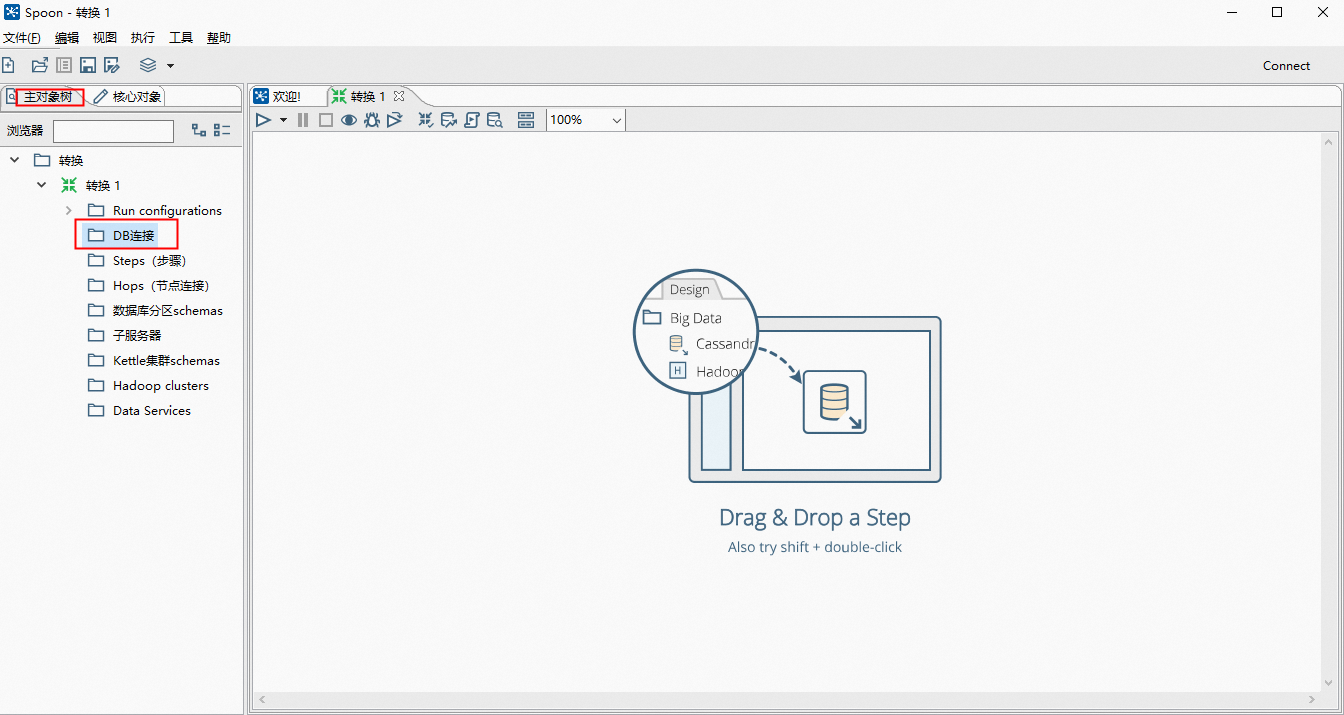
由于Kettle自身是不带任何数据库驱动包的,所以这里我们需要先自己准备好驱动包,版本最好选择5.1.49。下载好jar包后,拷贝到lib目录下(Windows和Linux同理)。如果已经启动了Kettle,则需要关掉重新启动,否则驱动包不会被加载。

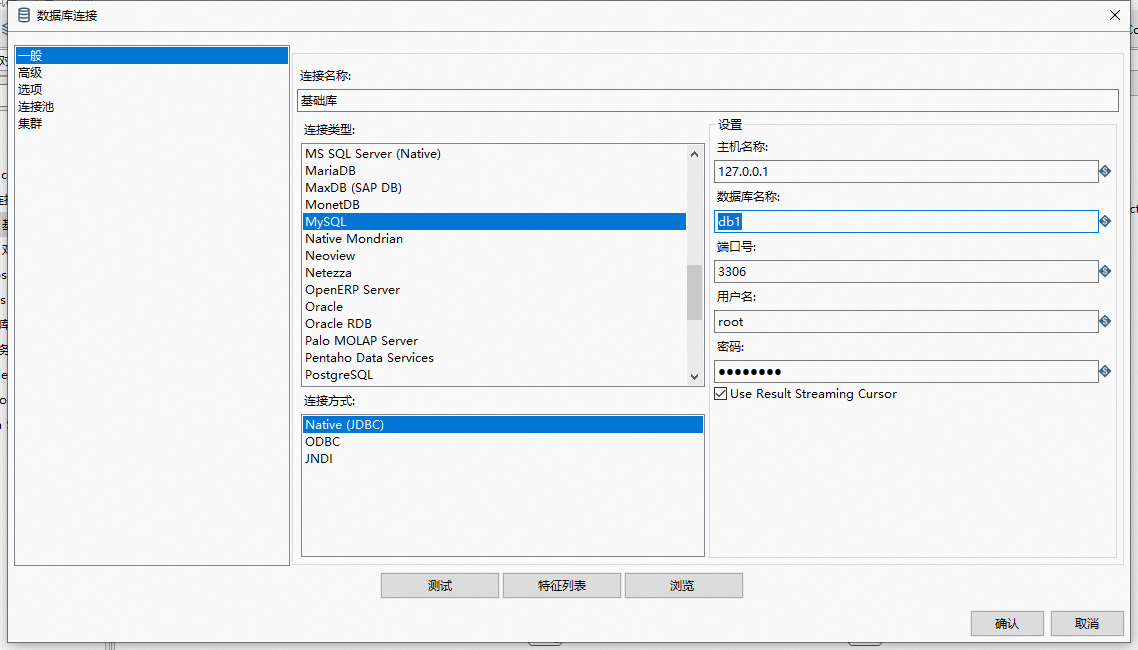
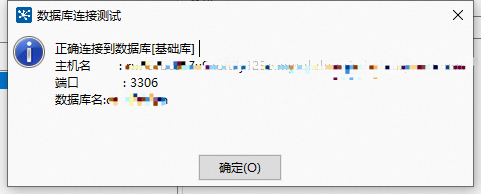
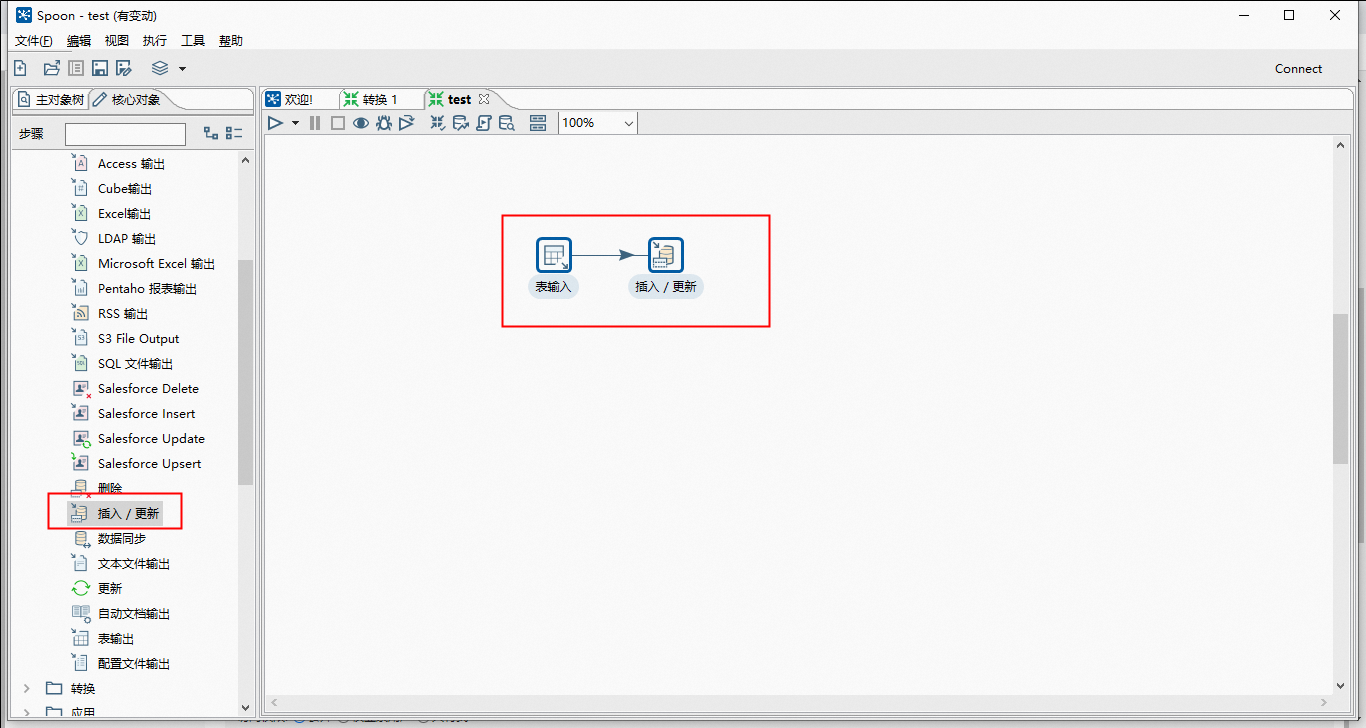
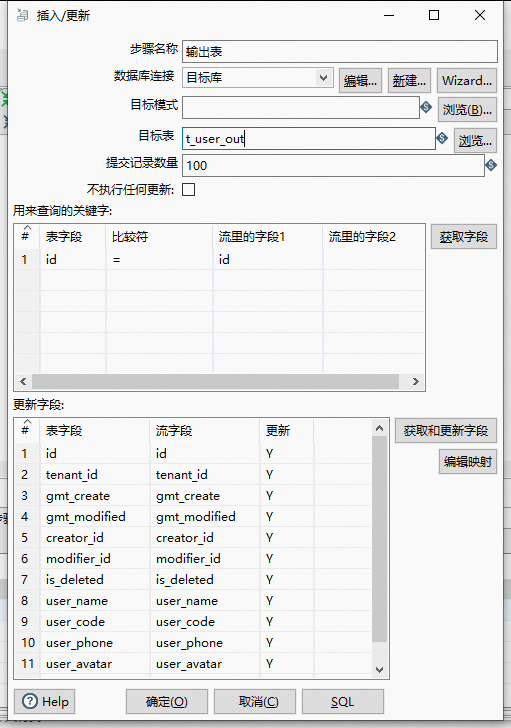
同上操作,创建好两个数据源:源数据库、目标库;目标就是将源数据库中的表数据同步到目标库中去

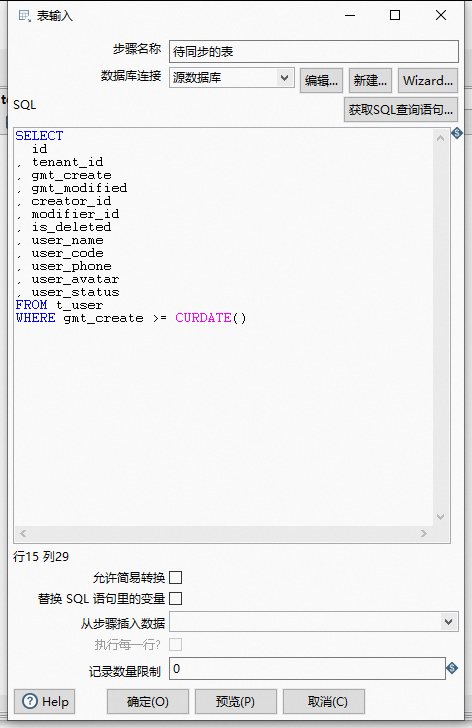
这里因为我是定时T+1 增量同步数据,所以我加了个同步条件WHERE gmt_create >= CURDATE()表示该数据创建时间大于当天才会进行查询。
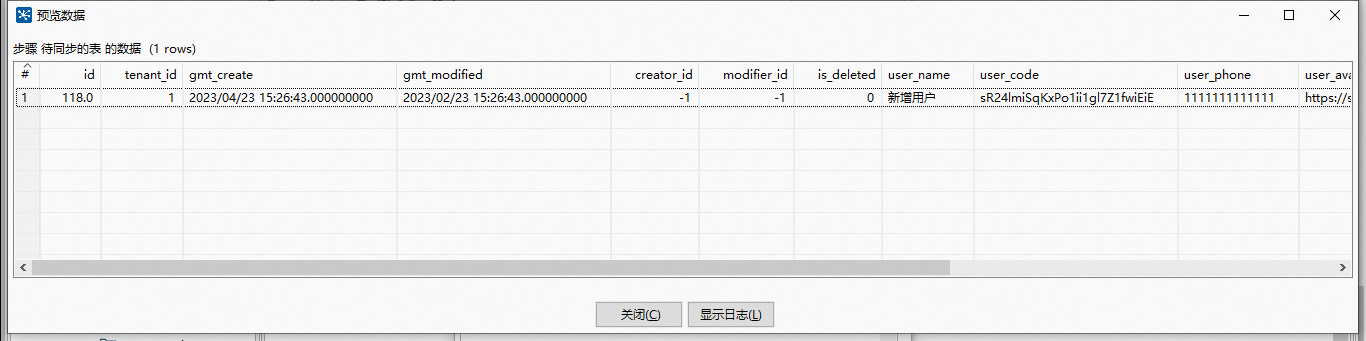
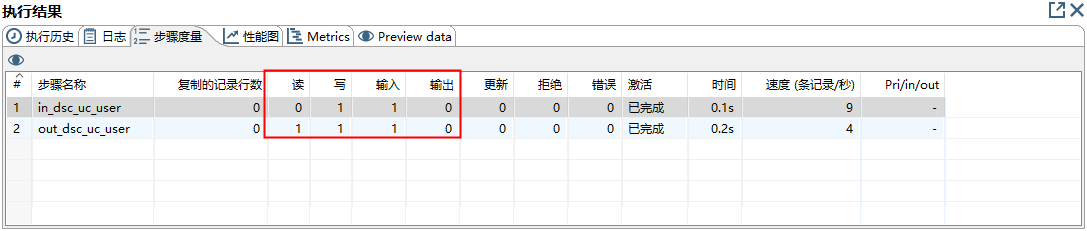
点击预览,正好有一条数据
在Linux上,ktr文件使用Kettle的pan.sh脚本运行,命令大致如下:sh /home/admin/kettle/data-integration/pan.sh -file=/home/admin/kettle/ktr/table_transfer.ktr -norep。同时为了实现定时执行这个脚本,我打算用Linux自带的corntab功能设置定时。
首先我编写了一个shell脚本,命名为cornSql.sh,用于保存ktr的执行命令,内容如下:
#!/bin/bash
export KETTLE_HOME=/home/admin/kettle/data-integration
export JAVA_HOME=/usr/java/jdk1.8.0_131
export CLASSPATH=.:${JAVA_HOME}/jre/lib/rt.jar:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar
export PATH=$PATH:${JAVA_HOME}/bin:${KETTLE_HOME}
export JRE_HOME=${JAVA_HOME}/jre
TIME=$(date "+%Y%m%d")
sh /home/admin/kettle/data-integration/pan.sh -file=/home/admin/kettle/ktr/table_transfer.ktr -norep >>/home/admin/kettle/log/transfer-"$TIME".log
复制其次,将ktr脚本拷贝到指定目录下,也就是/home/admin/kettle/ktr目录下,输入 crontab -e,再输入0 1 * * * /home/admin/kettle/cornSql.sh,这句话的意思是每天凌晨1点定时执行cornSql.sh脚本
为了检查定时配置是否生效,这里可以使用 crontab -l -u root命令,如果刚才的定时指令有打印出来,则证明配置生效。
最后,第二天检查一下执行日志文件有没有生成,在/home/admin/kettle/log目录下,这里我把每天执行的日期打印出来了,如下图:
