正文
1 背景
京喜达技术部在社区团购场景下采用JDQ+Flink+Elasticsearch架构来打造实时数据报表。随着业务的发展Elasticsearch开始暴露出一些弊端,不适合大批量的数据查询,高频次分页导出导致宕机、存储成本较高。
Elasticsearch的查询语句维护成本较高、在聚合计算场景下出现数据不精确等问题。Clickhouse是列式数据库,列式型数据库天然适合OLAP场景,类似SQL语法降低开发和学习成本,采用快速压缩算法节省存储成本,采用向量执行引擎技术大幅缩减计算耗时。所以做此对比,进行Elasticsearch切换至Clickhouse工作。
2 OLAP
OLAP意思是On-Line Analytical Processing 联机分析处理,Clickhouse就是典型的OLAP联机分析型数据库管理系统(DBMS)。OLAP主要针对数据进行复杂分析汇总操作,比如我们业务系统每天都对当天所有运输团单做汇总统计,计算出每个省区的妥投率,这个操作就属于OLAP类数据处理。与OLAP类似的还有一个OLTP类数据处理,意思是On-Line Transaction Processing 联机事务处理,在OLTP场景中用户并发操作量会很大,要求系统实时进行数据操作的响应,需要支持事务,Mysql、Oracle、SQLServer等都是OLTP型数据库。
2.1 OLTP场景的特征
- 宽表,即每个表包含着大量的列
- 对于读取,从数据库中提取相当多的行,但只提取列的一小部分。
- 查询相对较少(通常每台服务器每秒查询数百次或更少)
- 查询结果明显小于源数据。换句话说,数据经过过滤或聚合,因此结果适合于单个服务器的RAM中
- 绝大多数是读请求
- 数据以相当大的批次(> 1000行)更新,而不是单行更新;或者根本没有更新。
- 对于简单查询,允许延迟大约50毫秒
- 列中的数据相对较小:数字和短字符串(例如,每个URL 60个字节)
- 处理单个查询时需要高吞吐量(每台服务器每秒可达数十亿行)
- 事务不是必须的
- 对数据一致性要求低
3 特性
3.1 Elasticsearch
- 搜索: 适用倒排索引,每个字段都可被索引且可用于搜索,海量数据下近实时实现秒级的响应,基于Lucene的开源搜索引擎,为全文检索、高亮、搜索推荐等提供了检索能力。百度搜索、淘宝商品搜索、日志搜索等
- 数据分析: Elasticsearch提供了大量数据分析的API和丰富的聚合能力,支持在海量数据的基础上进行数据分析处理。统计订单量、爬虫爬取不同电商的某个商品数据,通过Elasticsearch进行数据分析(各个平台的历史价格、购买力等等)
3.2 Clickhouse
- 列式存储
- 压缩算法:采用lz4和zstd算法数据压缩,高压缩比降低数据大小,降低磁盘IO,降低CPU使用率。
- 索引:按照主键对数据进行排序,clickhouse能在几十毫秒内完成在大量数据对特定数据或范围数据进行查找。
- 多核心并行处理:ClickHouse会使用服务器上一切可用的资源,来全力完成一次查询。
- 支持SQL:一种基于SQL的声明式查询语言,在许多情况下与ANSI SQL标准相同。支持group by,order by,from, join,in以及非相关子查询等。
- 向量引擎:为了高效的使用CPU,数据不仅仅按列存储,同时还按向量(列的一部分)进行处理,这样可以更加高效地使用CPU。
- 实时的数据更新:数据总是已增量的方式有序的存储在MergeTree中。数据可以持续不断高效的写入到表中,不会进行任何加锁等操作。写入流量在50M-200M/s
- 适合在线查询:响应速度快延迟极低
- 丰富的聚合计算函数
4 我们的业务场景
- 大宽表,读大量行少量列进行指标聚合计算查询,结果集比较小。数据表都是通过Flink加工出来的宽表,列比较多。在对数据进行查询或者分析时,经常选择其中的少数几列作为维度列、对其他少数几列作为指标列,对全表或者一定范围内的数据做聚合计算。这个过程会扫描大量的行数据,但是只用了少数几列。
- 大量的列表分页查询与导出
- Flink中数据大批量追加写入,不做更新操作
- 有时某个指标计算需要全表扫描做聚合计算
- 很少进行全文搜索
结论:数据报表、数据分析场景是典型的OLAP场景,在业务场景上列式存储数据库Clickhouse比Elasticsearch更有优势,Elasticsearch在全文搜索上更占优势,但是我们这种全文搜索场景较少。
5 成本
- 学习成本:Clickhouse是SQL语法比Elasticsearch的DSL更简单,几乎所有后端研发都有Mysql开发经验,比较相通学习成本更低。
- 开发、测试、维护成本:Clickhouse是SQL语法,与Mysql开发模式相似,更好写单元测试。Elasticsearch是使用Java API拼接查询语句,复杂度较高,不易读不易维护。
- 运维成本:未知,互联网上在日志场景下Clickhouse比Elasticsearch成本更低。
- 服务器成本:
- Clickhouse的数据压缩比要高于Elasticsearch,相同业务数据占用的磁盘空间ES占用磁盘空间是Clickhouse的3-10倍,平均在6倍。 见图1
- Clickhouse比ES占用更少的CPU和内存
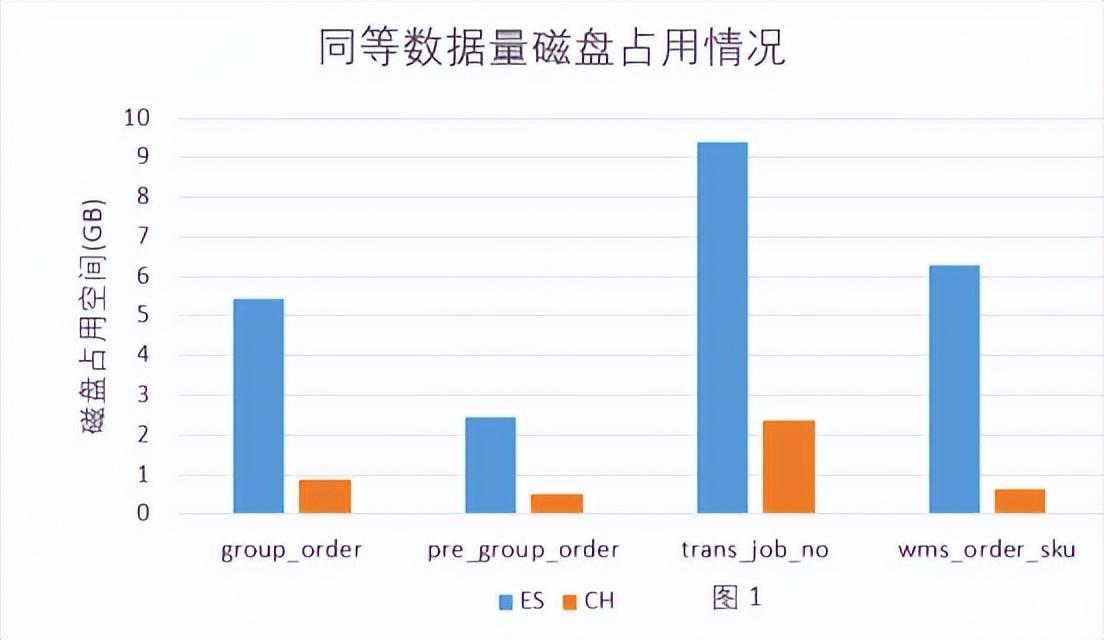
结论:同等数据量情况下,Elasticsearch使用的存储空间是Clickhouse的3-10倍,平均在6倍。综合学习、开发、测试、维护方面,Clickhouse比Elasticsearch更友好
6 测试
6.1服务器配置
以下均基于下图配置进行测试

6.2 写入压测
以下基于wms_order_sku表,通过Flink在业务平稳情况下双写Elasticsearch和Clickhouse1000W+数据进行测试得到的结果
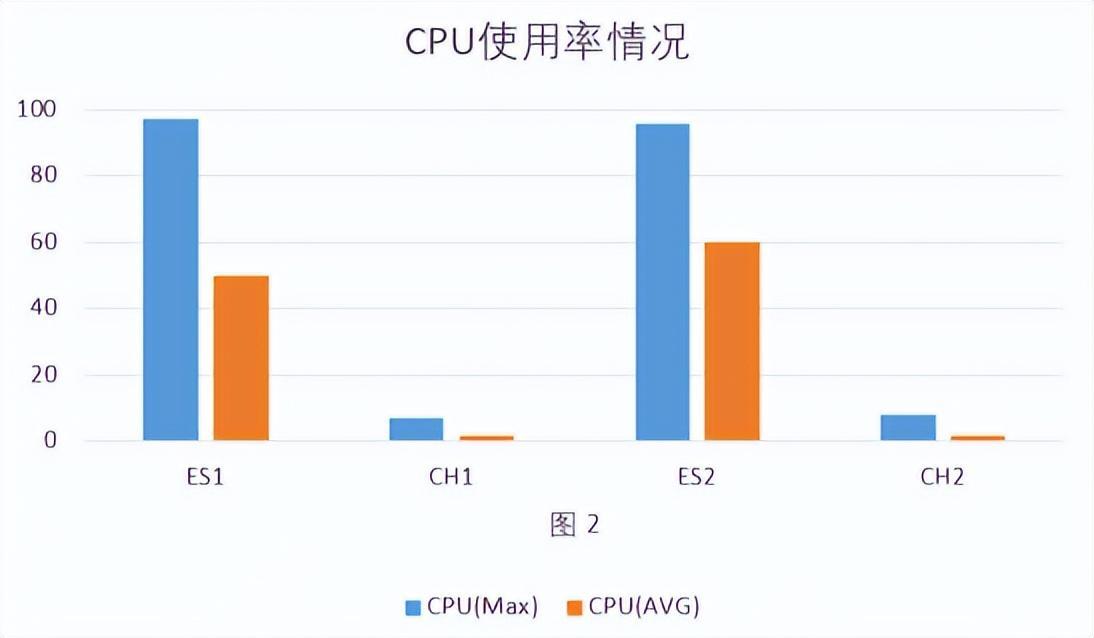
- 占用CPU情况:Elasticsearch CPU一直占用很高,Clickhouse占用很少CPU。见 图2
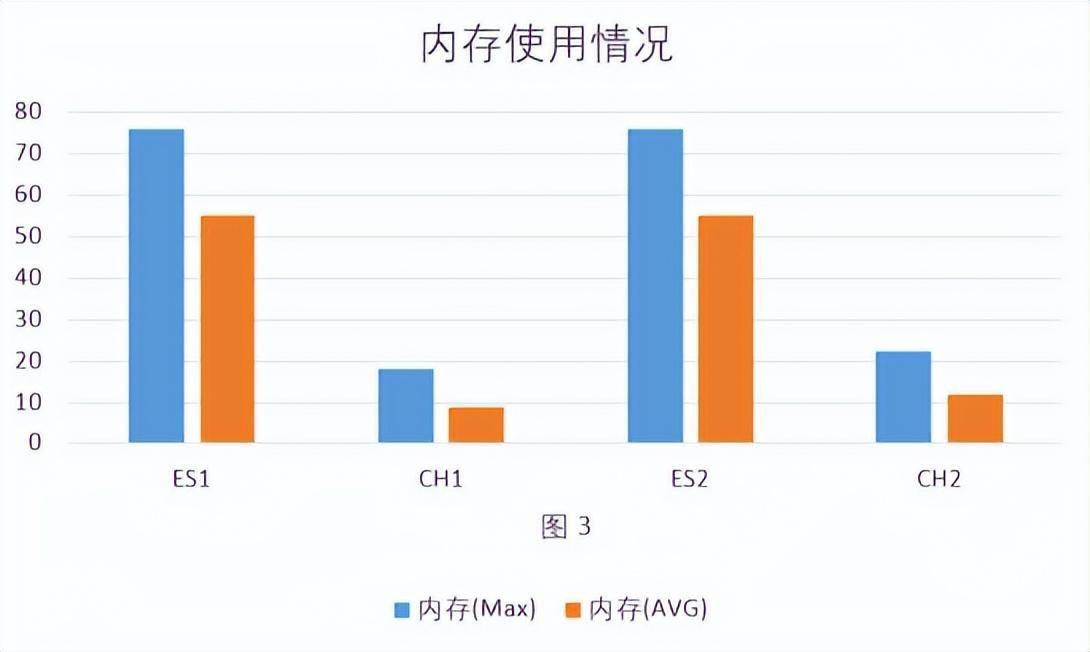
- 占用内存情况:Elasticsearch 内存升高频繁GC,Clickhouse占用内存较低,比较平稳。见 图3
- 写入吞吐量:CH单机写入速度大约为50~200MB/s,如果写入的数据每行为1kb,写入速度为5-20W/s,图 4(写入吞吐量)为互联网上Elasticsearch与Clickhouse写入数据的对比图,同等数据样本的情况下CH写入性能是Elasticsearch的5倍。由于我们目前Flink任务为双写,考虑到会互相影响,后续补充压测结果。
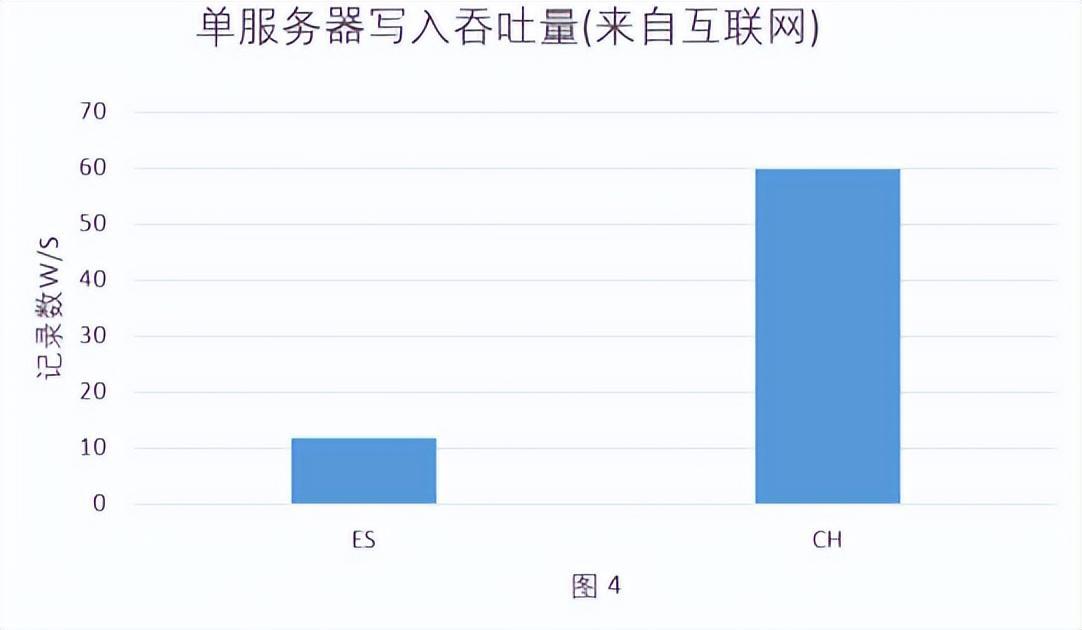
结论:批量写入数据时Elasticsearch比Clickhouse更吃内存和CPU,Elasticsearch消耗的内存是Clickhouse的5.3倍,消耗的CPU是Clickhouse的27.5倍。吞吐量是Elasticsearch的5倍
6.3 查询性能(单并发测试)
以下场景是我们数据报表以及数据分析中出现的高频场景,所以基于此进行查询性能测试
数据对比情况
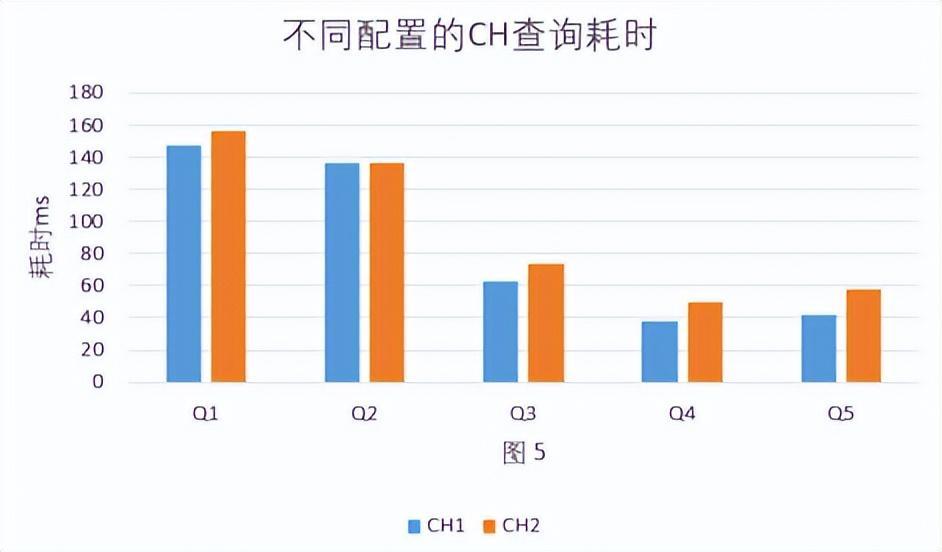
- Clickhouse自身在集群配置差一倍的情况下查询性能差异不是很大,CH2(48C 182GB)比CH1(80C 320GB)平均慢14%。见图 5
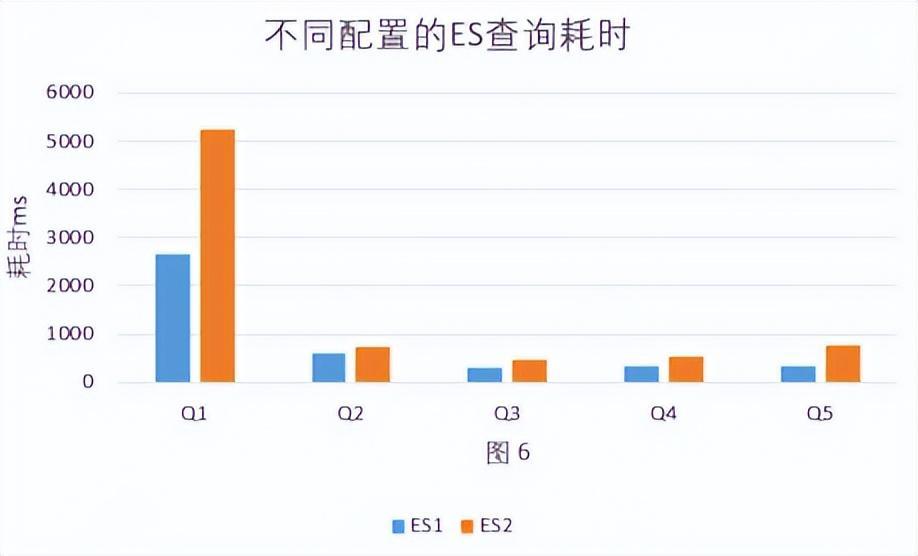
- Elasticsearch在集群配置差一倍的情况下查询性能受影响较大,ES2(46C 320GB)比ES1(78C 576GB)平均慢40%。见图 6
- ES2(46C 320GB)与CH2(48C 182GB)相比,ES2与CH2 CPU核数相近,ES2内存是CH2 1.75倍的情况下,CH2的响应速度是ES2的响应速度的的12.7倍。见图 7
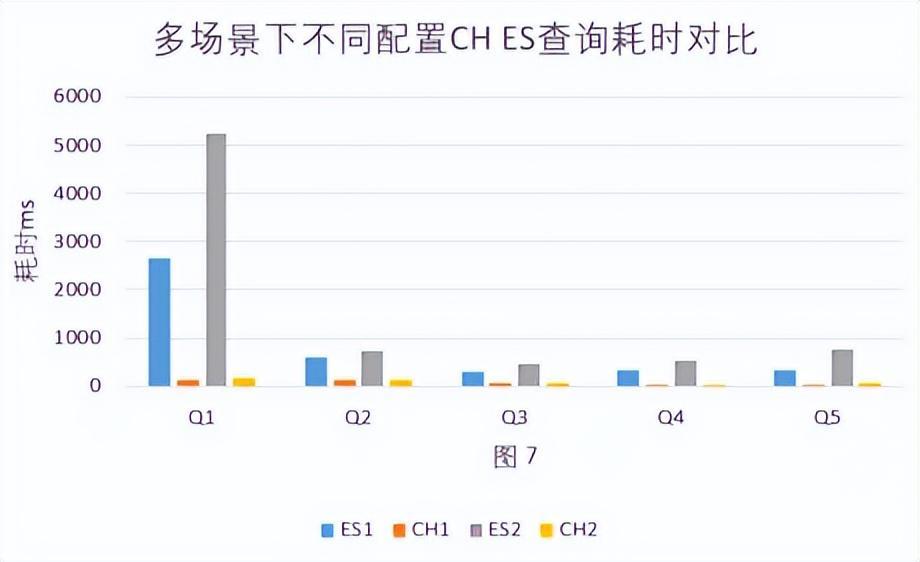
结论:查询数据时Elasticsearch比Clickhouse慢,在配置相近的情况下Clickhouse的响应速度是Elasticsearch的12.7倍,特别是基于时间的多字段进行聚合查询是Clickhouse比Elasticsearch快32倍。Clickhouse的查询响应素速度受集群配置大小的影响较小。
6.4 查询压测(高并发测试,数据来源于互联网)
由于准备高并发测试比较复杂耗时多,后续会基于我们的业务数据以及业务场景进行查询压力测试。以下数据来源于互联网在用户画像场景(数据量262933269)下进行的测试,与我们的场景非常类似。
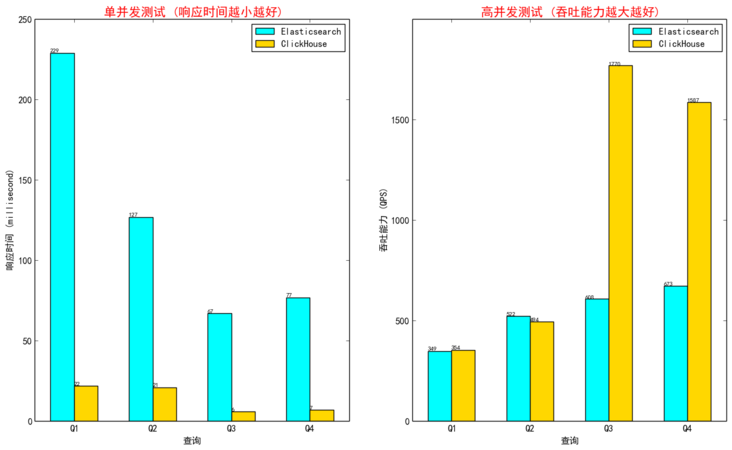
结论:Clickhouse对于高并发支持的不够,官方建议最大QPS为100。高并发情况下吞吐量不如Elasticsearch更友好
7 总结
Clickhouse与Elasticsearch对比Clickhouse的优缺点。
优点:
- 硬件资源成本更低,同等场景下,Clickhouse占用的资源更小。
- 人力成本更低,新人学习、开发单测以及测试方面都更加友好,更容易介入。
- OLAP场景下Clickhouse比Elasticsearch更适合,聚合计算比Elasticsearch更精缺、更快,更节省服务器计算资源。
- 写入性能更高,同等情况下是Elasticsearch的5倍,写入时消耗的服务器资源更小。
- Elasticsearch在大量导出情况下频繁GC,严重可能导致宕机,不如Clickhouse稳定。
- 查询性能平均是Elasticsearch的12.7倍,Clickhouse的查询性能受服务器配置影响较小
- 月服务器消费相同情况Clickhouse能够得到更好的性能。
缺点:
- 在全文搜索上不如Elasticsearch支持的更好,在高并发查询上支持的不如Elasticsearch支持的更好
作者:京东物流 马红岩
内容来源:京东云开发者社区