每一年都进行大促前压测,每一次都需要再次关注到一些基础资源的使用问题,订单中心这边数据库比较多,最近频繁报数据库异常,所以对数据库一些配置问题也进行了研究,本文给出一些常见的数据库配置,说明这些配置对我们数据库使用的影响。目前,MySQL服务端配置对使用方来说是不可更改的,需要联系DBA进行操作。这些配置操作对我们来说是一个黑盒,但是了解核心配置可以帮助我们快速定位数据库问题原因。
数据库服务端配置:max_connections
这个问题我们这边线上遇到过,对于同一个数据库,有多个系统都连接了数据库,导致连接数据库的机器比较多,在数据库qps比较大时,创建的连接数比较大,导致连接的总数超过了数据库服务端连接的限制阈值,从而报了这个错误。
举个栗子:如果max_connections设置为1000,我们这边有200台机器,每台机器最大连接数为20,在连接比较大时,可能大致连接的总数为200 * 20 = 4000 > 1000,超过数据库的限制。
下面让我们在本地演示一下这种错误:
首先查询当前服务端最大连接数:

如果这个参数太大,不好演示的话,可以通过如下参数,将这个数值改小些
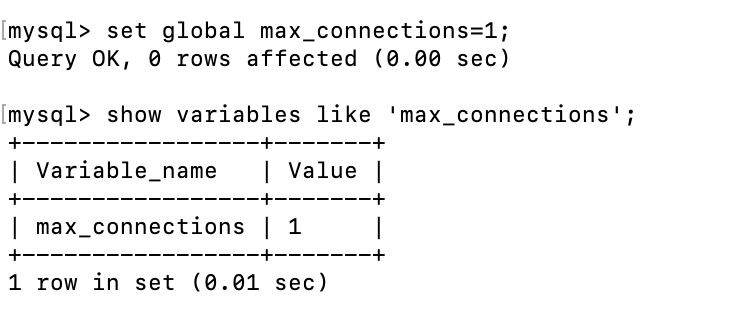
下面通过客户端尝试连接数据库,可以看到,直接报错了

对于这种问题有两种解决办法:
第一种:联系DBA将max_connections设置的大一些,DBA之前反馈max_connections这个参数有自动增长的逻辑;
第二种方法:如果数据库操作qps并不是很大,可以将每台机器的数据库连接最大值设置小一些,如果设置了初始化连接大小,要考虑机器数的增长,随着机器数的增长,连接的总数肯定会递增的。
数据库库服务端配置:max_execution_time
之前写了一篇文章聊了一下如何在客户端配置参数解决慢日志长时间执行问题,这个在本地验证是没有问题的,但是由于我们线上环境使用的是JED,JED的架构多了中间代理层,在客户端执行KILL QUERY CONNECTION_ID会提示失败,导致没法停止慢sql(这个好坑,据说JED后期会优化这个问题)。
既然目前客户端没法控制慢sql停止,从官网上看了一下mysql服务端的配置参数,发现有一个参数能够控制服务端主动超时停止sql,参数变量:max_execution_time,本地环境验证如下:
首先将sql执行超时时间设置为2s:

然后执行一个sleep函数,让执行时间达到10s,可以看出来执行直接中断了,因为超过了2s的最大超时时间:

数据库库服务端配置:wait_timeout
之前线上用的是mysql,通过mysql驱动包直连数据库,数据库服务端默认连接空闲时间是8小时,后来响应公司号召,将传统的mysql切到了jed(底层也是mysql), jed由于网关层的存在,客户端是通过mysql驱动包跟网关层进行直连,网关这一层数据库空闲连接超时时间仅仅10分钟,当时在客户端进行空闲连接探活时间超过10分钟,导致数据库报错频繁。现在已经找不到历史的数据库异常日志了,本地模拟了一下,验证如下:
先将本地空闲连接超时设置为10s

验证源码如下,让两条sql执行时间超过10s,可以发现第二次执行sql时执行报错了
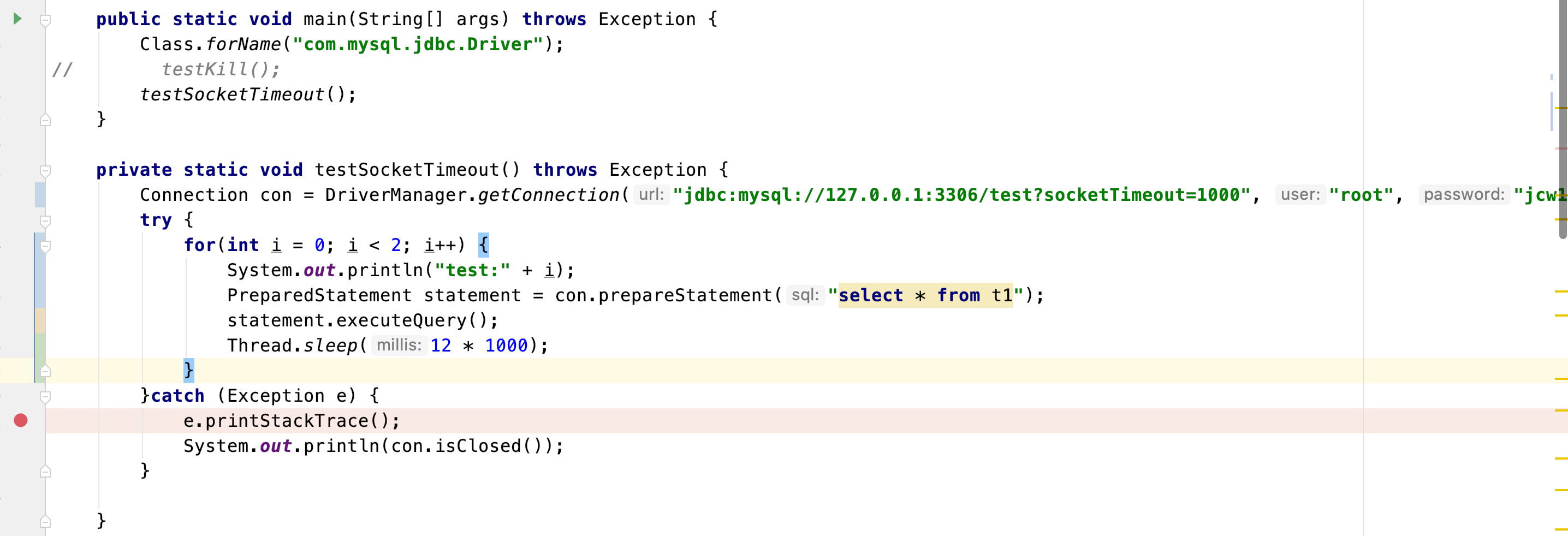

所以,如果换了数据源,需要确认下服务端的空闲连接超时时间设置,免得配置的值和客户端检测空闲连接健康性检测间隔不匹配,出现意料不到的结果。
注:我们这边使用的是DBCP数据源连接池,配置如下:
<bean id="abstractParallelProductWriteDataSource" class="org.apache.commons.dbcp.BasicDataSource" abstract="true" destroy-method="close" init-method="createDataSource">
<property name="driverClassName" value="com.mysql.jdbc.Driver" />
<property name="username" value="${db.online.write.username}" />
<property name="password" value="${db.online.write.password}" />
<property name="initialSize" value="3" />
<property name="minIdle" value="3" /><!--最小链接数 -->
<property name="maxIdle" value="3" /><!--最大链接数 -->
<property name="maxActive" value="8" /><!--最大活跃链接数 -->
<property name="maxWait" value="200" />
<property name="validationQuery" value="select 1" />
<property name="testOnBorrow" value="false" />
<property name="removeAbandonedTimeout" value="10" />
<property name="removeAbandoned" value="true" />
<!-- 池中的连接空闲10分钟后被回收,默认值就是30分钟 -->
<property name="minEvictableIdleTimeMillis" value="600000" />
<!-- 每5分钟运行一次空闲连接回收器 -->
<property name="timeBetweenEvictionRunsMillis" value="300000" />
<!--指明连接是否被空闲连接回收器(如果有)进行检验.如果检测失败,则连接将被从池中去除 -->
<property name="testWhileIdle" value="true"/>
<!--在每次空闲连接回收器线程(如果有)运行时检查的连接数量,默认值是3 -->
<property name="numTestsPerEvictionRun" value="5"/>
</bean>
复制timeBetweenEvictionRunsMillis这个参数配置的是检测空闲连接的间隔时间,如果服务端空闲连接10分钟就断开了,这个时间需要小于10分钟。minEvictableIdleTimeMillis这个时间是判断当前连接已经空闲了多久了,目前配置的是10分钟。
thread_handling
配置了服务端的线程处理模型,主要的值有no-threads、one-thread-per-connection、loaded-dynamically。其中no-threads表示同一时刻只能有一个连接被一个线程处理。one-thread-per-connection表示对于每一个连接请求都有一个线程来处理。loaded-dynamically是mysql的线程池模式,目前默认的是one-thread-per-connection,所以连接太多的话,也会导致创建的线程快速增加,消耗系统的资源。
slow_query_log
用来控制是否打印慢日志,如果需要分析系统性能情况,可以打开这个开关,进行慢日志分析。
profiling
是否启用sql查询性能分析,类似于debug日志,线上环境需要关闭,比较耗性能,这个参数后面mysql版本会废弃掉,现在还是可以先使用着,新的使用方式可以参考:https://dev.mysql.com/doc/refman/8.0/en/performance-schema-query-profiling.html。
由于这个参数线上是关闭着,只能让DBA临时帮忙查询下分析结果,平常也没咋用,感觉还是一个不错的工具,分析结果类似下面截图:

mysql服务端配置太多,目前工作中主要接触了上述这些配置,感觉还不错的,在平常分析数据库问题上能够给予一定的帮助,大家也可以去多了解一下,更多的配置可以参考官方文档:mysql服务端配置官网
作者:京东零售 姜昌伟
来源:京东云开发者社区 转载请注明来源
MySQL服务端配置对使用方来说是不可更改的,需要联系DBA进行操作。这些配置操作对我们来说是一个黑盒,但是了解核心配置可以帮助我们快速定位数据库问题原因。