作者:vivo 互联网搜索团队- Deng Jie
随着技术的不断的发展,在大数据领域出现了越来越多的技术框架。而为了降低大数据的学习成本和难度,越来越多的大数据技术和应用开始支持SQL进行数据查询。SQL作为一个学习成本很低的语言,支持SQL进行数据查询可以降低用户使用大数据的门槛,让更多的用户能够使用大数据。
本篇文章主要介绍如何实现一个SQL解析器来应用的业务当中,同时结合具体的案例来介绍SQL解析器的实践过程。
在设计项目系统架构时,我们通常会做一些技术调研。我们会去考虑为什么需要SQL解析器?怎么判断选择的 SQL 解析器可以满足当前的技术要求?
传统的SQL查询,依赖完整的数据库协议。比如数据存储在MySQL、Oracle等关系型数据库中,有标准的SQL语法。我们可以通过不同的SQL语句来实现业务需求,如下图所示:
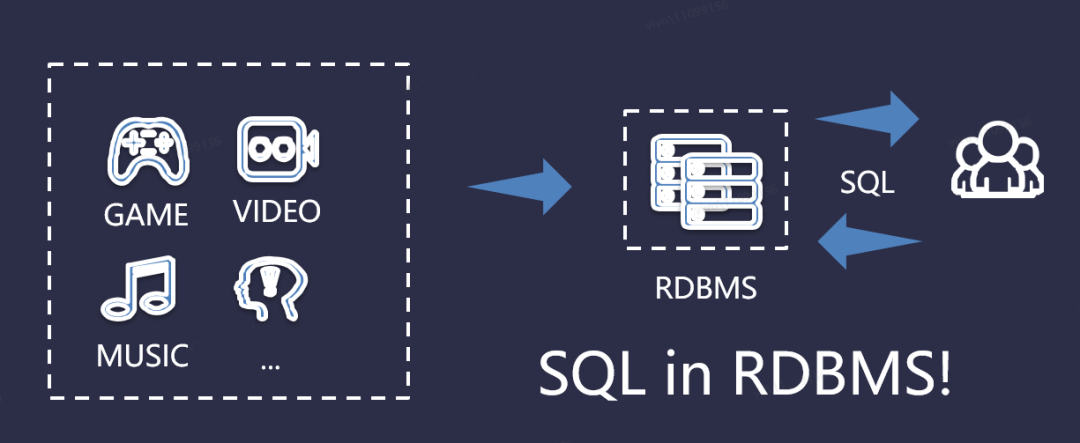
但是,在处理海量数据的时候,关系型数据库是难以满足实际的业务需求的,我们需要借助大数据生态圈的技术组件来解决实际的业务需求。
在使用大数据生态圈的技术组件时,有些技术组件是自带SQL的,比如Hive、Spark、Flink等;而有些技术组件本身是不带SQL的,比如Kafka、HBase。下面,我们可以通过对比不带SQL和使用SQL解析器后的场景,如下图所示:
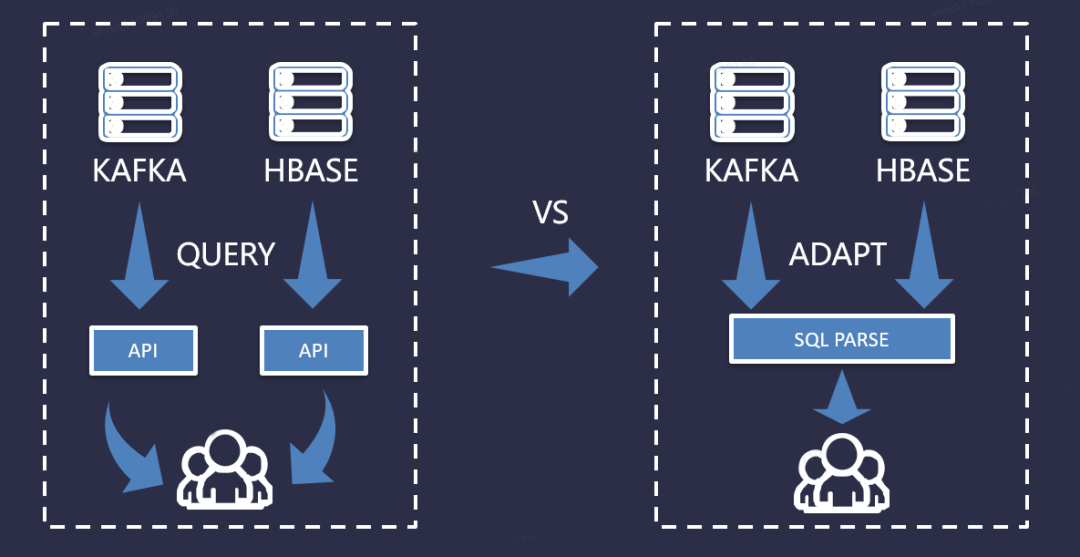
从上图中,我们可以看到,图左边在我们使用不带SQL的技术组件时,实现一个查询时,需要我们编写不同的业务逻辑接口,来与Kafka、HBase这些技术组件来进行数据交互。如果随着这类组件的增加,查询功能复杂度的增加,那边每套接口的复杂度也会随之增加,对于后续的扩展和维护也是很不方便的。而图右边在我们引入SQL解析器后,只需要一套接口来完成业务逻辑,对于不同的技术组件进行适配即可。
在选择SQL解析器应用到我们实际的业务场景之前,我们先来了解一下SQL解析器的核心知识点。
在使用SQL解析器时,解析SQL的步骤与我们解析Java/Python程序的步骤是非常的相似的,比如:
在我们使用解析器的过程当中,通常解析器主要包括三部分,它们分别是:词法解析、语法解析、语义解析。
如何理解词法解析呢?词法解析我们可以这么来进行理解,在启动词法解析任务时,它将从左到右把字符一个个的读取并加载到解析程序里面,然后对字节流进行扫描,接着根据构词规则识别字符并切割成一个个的词条,切词的规则是遇到空格进行分割,遇到分号时结束词法解析。比如一个简单的SQL如下所示:
SQL示例


如何理解语法解析呢?语法解析我们可以这么来进行理解,在启动语法解析任务时,语法分析的任务会在词法分析的结果上将词条序列组合成不同语法短句,组成的语法短句将与相应的语法规则进行适配,若适配成功则生成对应的抽象语法树,否则报会抛出语法错误异常。比如如下SQL语句:
SQL示例
SELECT name FROM tab WHERE id=1001;复制
约定规则如下:
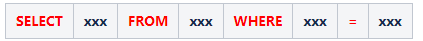
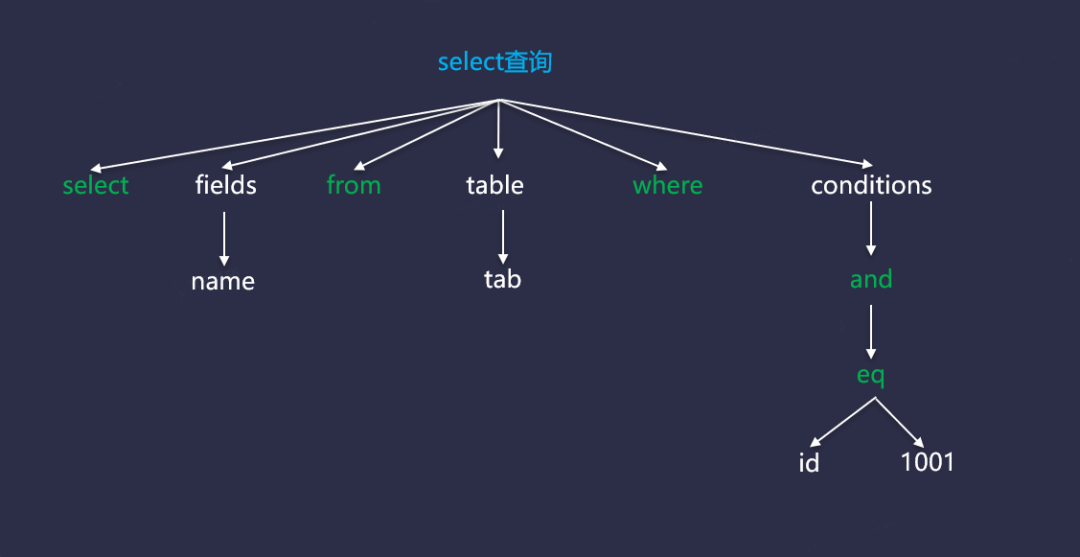
上表中,红色的内容通常表示终结符,它们一般是大写的关键字或者符号等,小写的内容是非终结符,一般用作规则的命名,比如字段、表名等。具体AST数据结构如下图所示:
如何理解语义解析呢?语义解析我们可以这么来进行理解,语义分析的任务是对语法解析得到的抽象语法树进行有效的校验,比如字段、字段类型、函数、表等进行检查。比如如下语句:
SQL示例
SELECT name FROM tab WHERE id=1001;复制
上述SQL语句,语义分析任务会做如下检查:
上述检查结束后,语义解析会生成对应的表达式供优化器去使用。
在了解了解析器的核心知识点后,如何选择合适的SQL解析器来应用到我们的实际业务当中呢?下面,我们来对比一下主流的两种SQL解析器。它们分别是ANTLR和Calcite。
ANTLR是一款功能强大的语法分析器生成器,可以用来读取、处理、执行和转换结构化文本或者二进制文件。在大数据的一些SQL框架里面有有广泛的应用,比如Hive的词法文件是ANTLR3写的,Presto词法文件也是ANTLR4实现的,SparkSQLambda词法文件也是用Presto的词法文件改写的,另外还有HBase的SQL工具Phoenix也是用ANTLR工具进行SQL解析的。
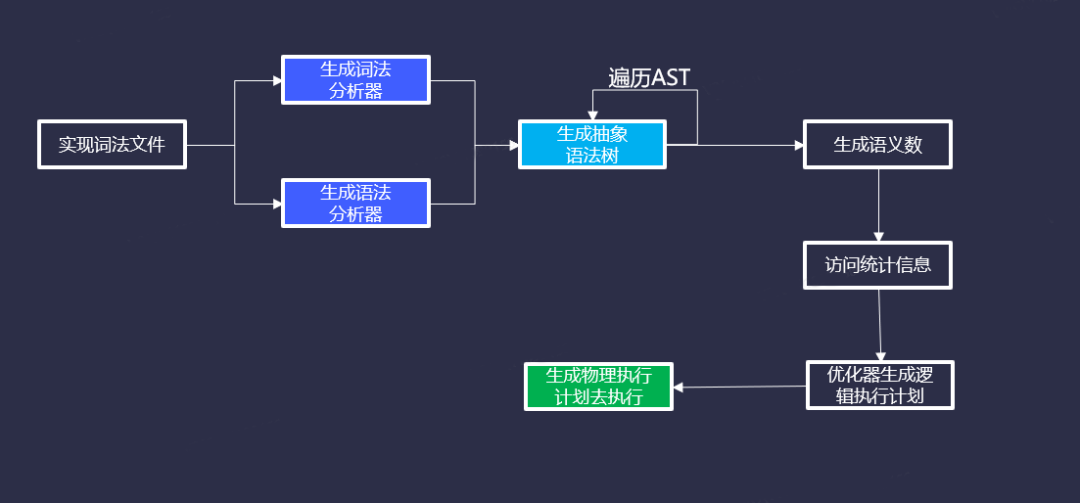
使用ANTLR来实现一条SQL,执行或者实现的过程大致是这样的,实现词法文件(.g4),生成词法分析器和语法分析器,生成抽象语法树(也就是我常说的AST),然后再遍历抽象语法树,生成语义树,访问统计信息,优化器生成逻辑执行计划,再生成物理执行计划去执行。
官网示例:
ANTLR表达式
assign : ID '=' expr ';' ;复制
解析器的代码类似于下面这样:
ANTLR解析器代码
void assign() {
match(ID);
match('=');
expr();
match(';');
}复制
Parser是用来识别语言的程序,其本身包含两个部分:词法分析器和语法分析器。词法分析阶段主要解决的问题是关键字以及各种标识符,比如INT(类型关键字)和ID(变量标识符)。语法分析主要是基于词法分析的结果,构造一颗语法分析数,流程大致如下:
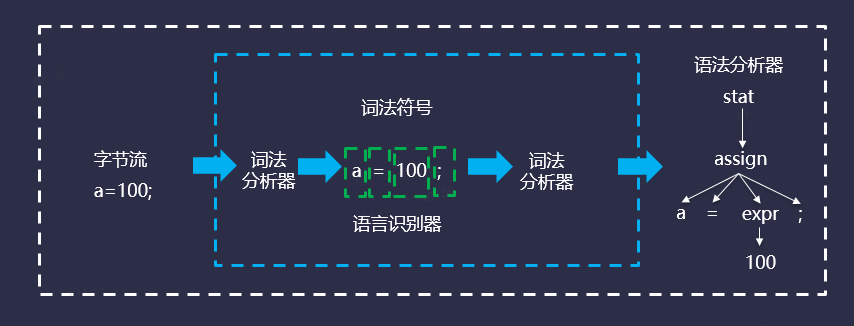
因此,为了让词法分析和语法分析能够正常工作,在使用ANTLR4的时候,需要定义语法(Grammar)。
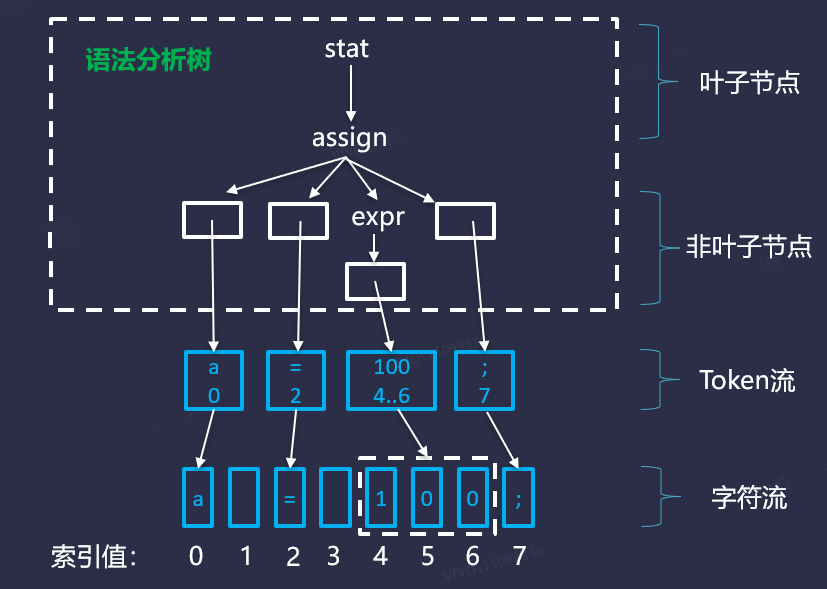
我们可以把字符流(CharStream),转换成一棵语法分析树,字符流经过词法分析会变成Token流。Token流再最终组装成一棵语法分析树,其中包含叶子节点(TerminalNode)和非叶子节点(RuleNode)。具体语法分析树如下图所示:
ANTLR官方提供了很多常用的语言的语法文件,可以进行修改后直接进行复用:https://github.com/antlr/grammars-v4
在使用语法的时候,需要注意以下事项:
下面通过简单示例,说明ANTLR4的用法,需要实现的功能效果如下:
ANTLR示例
1+2 => 1+2=3 1+2*4 => 1+2*4=9 1+2*4-5 => 1+2*4-5=4 1+2*4-5+20/5 => 1+2*4-5+20/5=8 (1+2)*4 => (1+2)*4=12复制
通过ANTLR处理流程如下图所示:
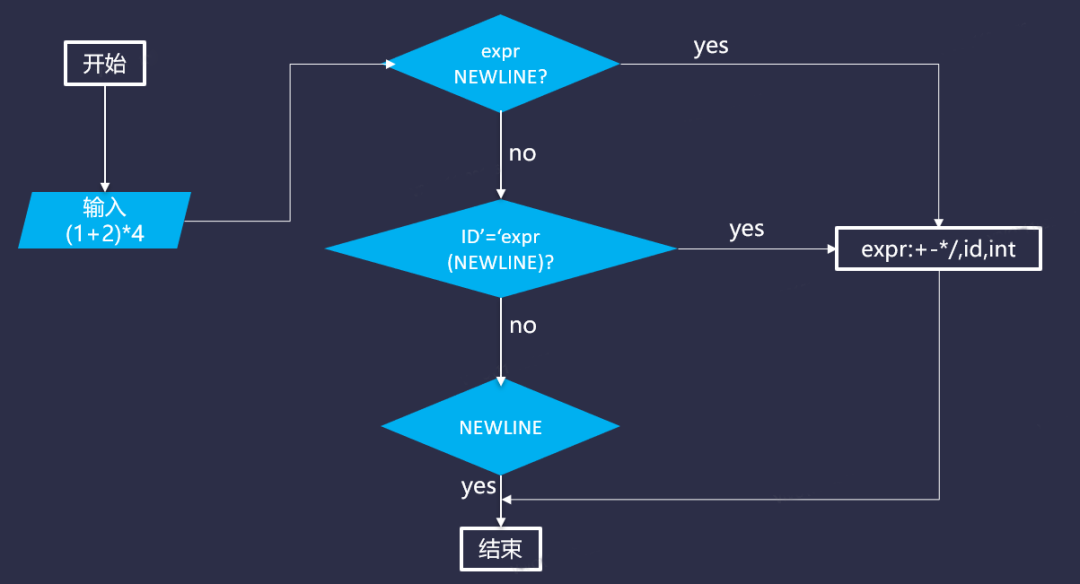
整体来说一个原则,递归下降。即定义一个表达式(如expr),可以循环调用直接也可以调用其他表达式,但是最终肯定会有一个最核心的表达式不能再继续往下调用了。
步骤一:定义词法规则文件(CommonLexerRules.g4)
CommonLexerRules.g4
// 定义词法规则
lexer grammar CommonLexerRules;
//////// 定义词法
// 匹配ID
ID : [a-zA-Z]+ ;
// 匹配INT
INT : [0-9]+ ;
// 匹配换行符
NEWLINE: '\n'('\r'?);
// 跳过空格、跳格、换行符
WS : [ \t\n\r]+ -> skip;
//////// 运算符
DIV:'/';
MUL:'*';
ADD:'+';
SUB:'-';
EQU:'=';复制
步骤二:定义语法规则文件(LibExpr.g4)
LibExpr.g4
// 定于语法规则
grammar LibExpr;
// 导入词法规则
import CommonLexerRules;
// 词法根
prog:stat+ EOF?;
// 定义声明
stat:expr (NEWLINE)? # printExpr
| ID '=' expr (NEWLINE)? # assign
| NEWLINE # blank
;
// 定义表达式
expr:expr op=('*'|'/') expr # MulDiv
|expr op=('+'|'-') expr # AddSub
|'(' expr ')' # Parens
|ID # Id
|INT # Int
;复制
步骤三:编译生成文件
如果是Maven工程,这里在pom文件中添加如下依赖:
ANTLR依赖JAR
<dependencies>
<dependency>
<groupId>org.antlr</groupId>
<artifactId>antlr4</artifactId>
<version>4.9.3</version>
</dependency>
<dependency>
<groupId>org.antlr</groupId>
<artifactId>antlr4-runtime</artifactId>
<version>4.9.3</version>
</dependency>
</dependencies>复制
然后,执行Maven编译命令即可:
Maven编译命令
mvn generate-sources复制
步骤四:编写简单的示例代码
待预算的示例文本:
示例文本
1+2 1+2*4 1+2*4-5 1+2*4-5+20/5 (1+2)*4复制
加减乘除逻辑类:
逻辑实现类
package com.vivo.learn.sql;
import java.util.HashMap;
import java.util.Map;
/**
* 重写访问器规则,实现数据计算功能
* 目标:
* 1+2 => 1+2=3
* 1+2*4 => 1+2*4=9
* 1+2*4-5 => 1+2*4-5=4
* 1+2*4-5+20/5 => 1+2*4-5+20/5=8
* (1+2)*4 => (1+2)*4=12
*/
public class LibExprVisitorImpl extends LibExprBaseVisitor<Integer> {
// 定义数据
Map<String,Integer> data = new HashMap<String,Integer>();
// expr (NEWLINE)? # printExpr
@Override
public Integer visitPrintExpr(LibExprParser.PrintExprContext ctx) {
System.out.println(ctx.expr().getText()+"="+visit(ctx.expr()));
return visit(ctx.expr());
}
// ID '=' expr (NEWLINE)? # assign
@Override
public Integer visitAssign(LibExprParser.AssignContext ctx) {
// 获取id
String id = ctx.ID().getText();
// // 获取value
int value = Integer.valueOf(visit(ctx.expr()));
// 缓存ID数据
data.put(id,value);
// 打印日志
System.out.println(id+"="+value);
return value;
}
// NEWLINE # blank
@Override
public Integer visitBlank(LibExprParser.BlankContext ctx) {
return 0;
}
// expr op=('*'|'/') expr # MulDiv
@Override
public Integer visitMulDiv(LibExprParser.MulDivContext ctx) {
// 左侧数字
int left = Integer.valueOf(visit(ctx.expr(0)));
// 右侧数字
int right = Integer.valueOf(visit(ctx.expr(1)));
// 操作符号
int opType = ctx.op.getType();
// 调试
// System.out.println("visitMulDiv>>>>> left:"+left+",opType:"+opType+",right:"+right);
// 判断是否为乘法
if(LibExprParser.MUL==opType){
return left*right;
}
// 判断是否为除法
return left/right;
}
// expr op=('+'|'-') expr # AddSub
@Override
public Integer visitAddSub(LibExprParser.AddSubContext ctx) {
// 获取值和符号
// 左侧数字
int left = Integer.valueOf(visit(ctx.expr(0)));
// 右侧数字
int right = Integer.valueOf(visit(ctx.expr(1)));
// 操作符号
int opType = ctx.op.getType();
// 调试
// System.out.println("visitAddSub>>>>> left:"+left+",opType:"+opType+",right:"+right);
// 判断是否为加法
if(LibExprParser.ADD==opType){
return left+right;
}
// 判断是否为减法
return left-right;
}
// '(' expr ')' # Parens
@Override
public Integer visitParens(LibExprParser.ParensContext ctx) {
// 递归下调
return visit(ctx.expr());
}
// ID # Id
@Override
public Integer visitId(LibExprParser.IdContext ctx) {
// 获取id
String id = ctx.ID().getText();
// 判断ID是否被定义
if(data.containsKey(id)){
// System.out.println("visitId>>>>> id:"+id+",value:"+data.get(id));
return data.get(id);
}
return 0;
}
// INT # Int
@Override
public Integer visitInt(LibExprParser.IntContext ctx) {
// System.out.println("visitInt>>>>> int:"+ctx.INT().getText());
return Integer.valueOf(ctx.INT().getText());
}
}复制
Main函数打印输出结果类:
package com.vivo.learn.sql;
import org.antlr.v4.runtime.tree.ParseTree;
import java.io.FileNotFoundException;
import java.io.IOException;
import org.antlr.v4.runtime.*;
/**
* 打印语法树
*/
public class TestLibExprPrint {
// 打印语法树 input -> lexer -> tokens -> parser -> tree -> print
public static void main(String args[]){
printTree("E:\\smartloli\\hadoop\\sql-parser-example\\src\\main\\resources\\testCase.txt");
}
/**
* 打印语法树 input -> lexer -> token -> parser -> tree
* @param fileName
*/
private static void printTree(String fileName){
// 定义输入流
ANTLRInputStream input = null;
// 判断文件名是否为空,若不为空,则读取文件内容,若为空,则读取输入流
if(fileName!=null){
try{
input = new ANTLRFileStream(fileName);
}catch(FileNotFoundException fnfe){
System.out.println("文件不存在,请检查后重试!");
}catch(IOException ioe){
System.out.println("文件读取异常,请检查后重试!");
}
}else{
try{
input = new ANTLRInputStream(System.in);
}catch(FileNotFoundException fnfe){
System.out.println("文件不存在,请检查后重试!");
}catch(IOException ioe){
System.out.println("文件读取异常,请检查后重试!");
}
}
// 定义词法规则分析器
LibExprLexer lexer = new LibExprLexer(input);
// 生成通用字符流
CommonTokenStream tokens = new CommonTokenStream(lexer);
// 语法解析
LibExprParser parser = new LibExprParser(tokens);
// 生成语法树
ParseTree tree = parser.prog();
// 打印语法树
// System.out.println(tree.toStringTree(parser));
// 生命访问器
LibExprVisitorImpl visitor = new LibExprVisitorImpl();
visitor.visit(tree);
}
}复制
执行代码,最终输出结果如下图所示:

上述ANTLR内容演示了词法分析和语法分析的简单流程,但是由于ANTLR要实现SQL查询,需要自己定义词法和语法相关文件,然后再使用ANTLR的插件对文件进行编译,然后再生成代码(与Thrift的使用类似,也是先定义接口,然后编译成对应的语言文件,最后再继承或者实现这些生成好的类或者接口)。
而Apache Calcite的出现,大大简化了这些复杂的工程。Calcite可以让用户很方便的给自己的系统套上一个SQL的外壳,并且提供足够高效的查询性能优化。
上述这五个功能,通常是数据库系统包含的常用功能。Calcite在设计的时候就确定了自己只关注绿色的三个部分,而把下面数据管理和数据存储留给各个外部的存储或计算引擎。
数据管理和数据存储,尤其是数据存储是很复杂的,也会由于数据本身的特性导致实现上的多样性。Calcite抛弃这两部分的设计,而是专注于上层更加通用的模块,使得自己能够足够的轻量化,系统复杂性得到控制,开发人员的精力也不至于耗费的太多。
同时,Calcite也没有重复去早轮子,能复用的东西,都是直接拿来复用。这也是让开发者能够接受去使用它的一个原因。比如,如下两个例子:
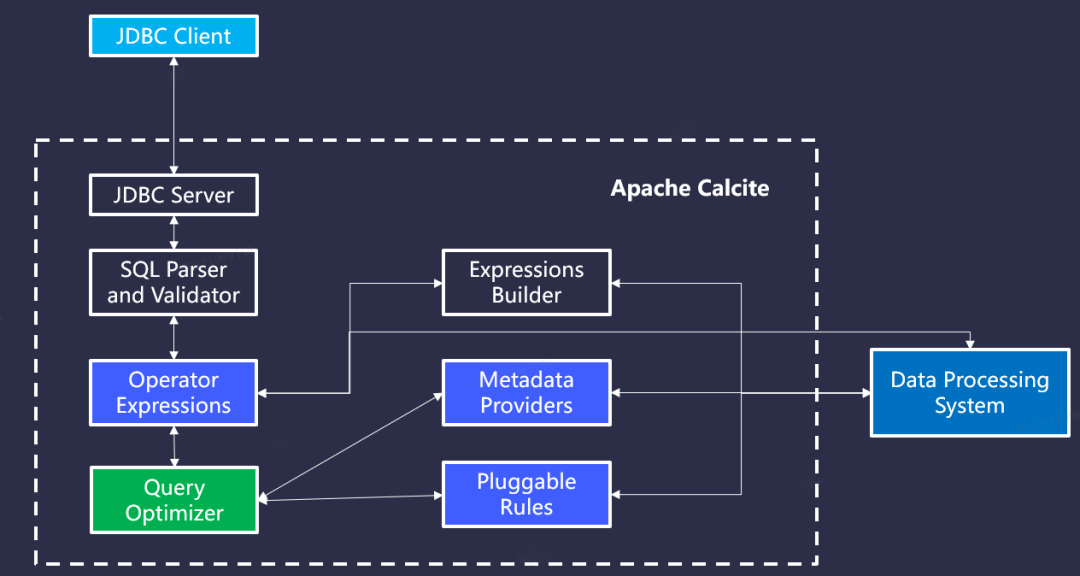
上面的图是Calcite官方给出的架构图,从图中我们可以获取到的信息是,一方面印证了我们上面提到的,Calcite足够的简单,没有做自己不该做的事情;另一方面,也是更重要的,Calcite被设计的足够模块化和可插拔。
功能模块的划分足够合理,也足够独立,使得不用完整集成,而是可以只选择其中的一部分使用,而基本上每个模块都支持自定义,也使得用户能够更多的定制系统。
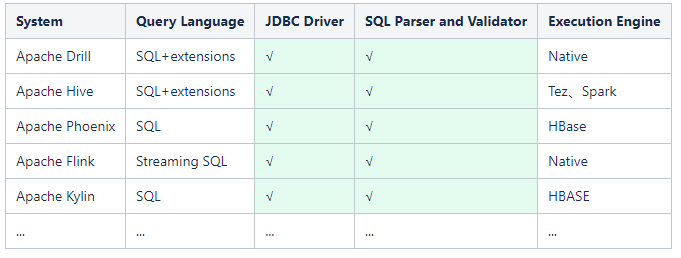
上面列举的这些大数据常用的组件都Calcite均有集成,可以看到Hive就是自己做了SQL解析,只使用了Calcite的查询优化功能。而像Flink则是从解析到优化都直接使用了Calcite。
上面介绍的Calcite集成方法,都是把Calcite的模块当做库来使用。如果觉得太重量级,可以选择更简单的适配器功能。通过类似Spark这些框架里自定义的Source或Sink的方式,来实现和外部系统的数据交互操作。
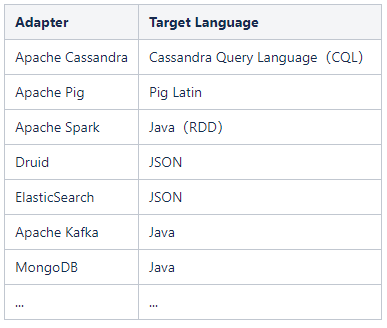
上图就是比较典型的适配器用法,比如通过Kafka的适配器就能直接在应用层通过SQL,而底层自动转换成Java和Kafka进行数据交互(后面部分有个案例操作)。
参考了EFAK(原Kafka Eagle开源项目)的SQL实现,来查询Kafka中Topic里面的数据。
1.常规SQL查询
SQL查询
select * from video_search_query where partition in (0) limit 10复制
预览截图:
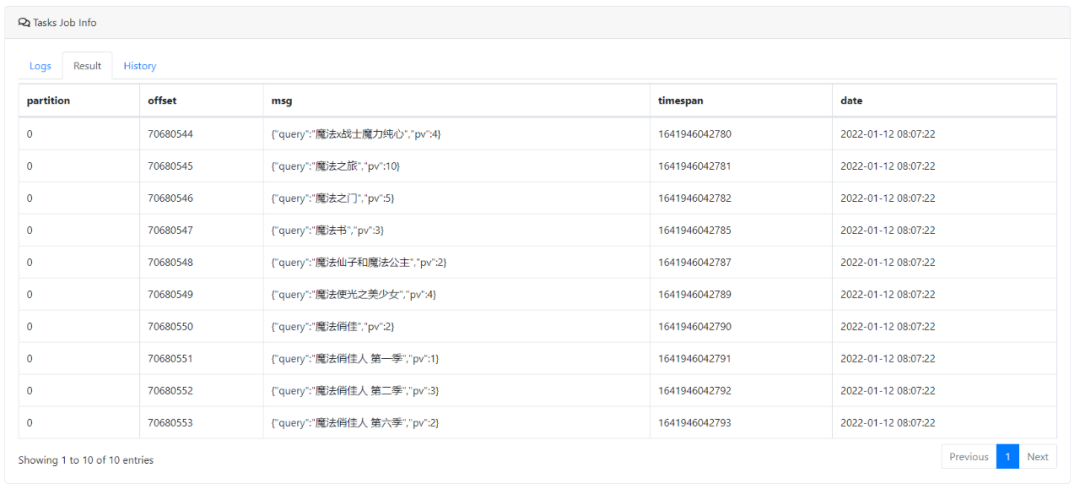
2.UDF查询
SQL查询
select JSON(msg,'query') as query,JSON(msg,'pv') as pv from video_search_query where `partition` in (0) limit 10复制
预览截图:
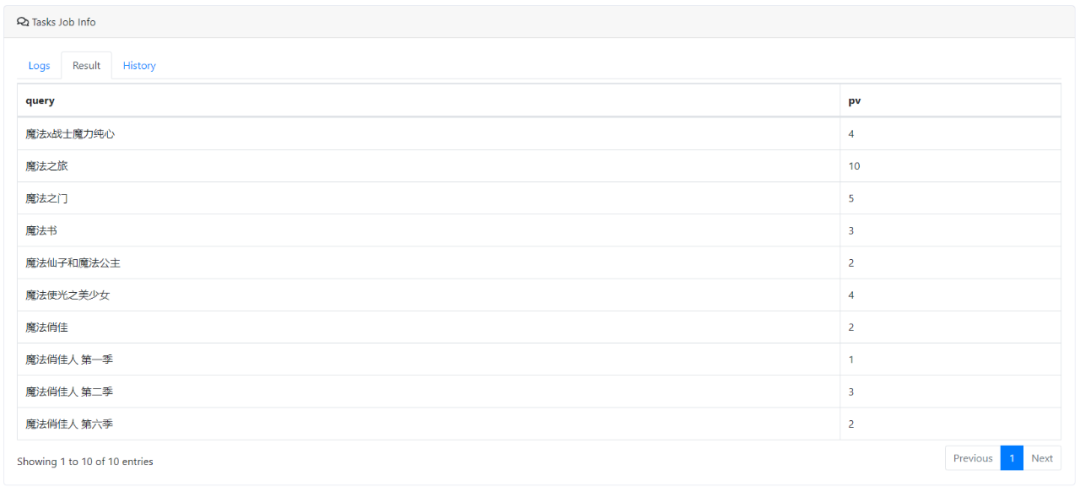
ANTLR4解析SQL的主要流程包含:定义词法和语法文件、编写SQL解析逻辑类、主服务调用SQL逻辑类。
1.定义词法和语法文件
可参考官网提供的开源地址:详情
2.编写SQL解析逻辑类
这里,我们编写一个实现解析SQL表名的类,具体实现代码如下所示:
解析表名
public class TableListener extends antlr4.sql.MySqlParserBaseListener {
private String tableName = null;
public void enterQueryCreateTable(antlr4.sql.MySqlParser.QueryCreateTableContext ctx) {
List<MySqlParser.TableNameContext> tableSourceContexts = ctx.getRuleContexts(antlr4.sql.MySqlParser.TableNameContext.class);
for (antlr4.sql.MySqlParser.TableNameContext tableSource : tableSourceContexts) {
// 获取表名
tableName = tableSource.getText();
}
}
public String getTableName() {
return tableName;
}
}复制
3.主服务调用SQL逻辑类
对实现SQL解析的逻辑类进行调用,具体代码如下所示:
主服务
public class AntlrClient {
public static void main(String[] args) {
// antlr4 格式化SQL
antlr4.sql.MySqlLexer lexer = new antlr4.sql.MySqlLexer(CharStreams.fromString("create table table2 select tid from table1;"));
antlr4.sql.MySqlParser parser = new antlr4.sql.MySqlParser(new CommonTokenStream(lexer));
// 定义TableListener
TableListener listener = new TableListener();
ParseTreeWalker.DEFAULT.walk(listener, parser.sqlStatements());
// 获取表名
String tableName= listener.getTableName();
// 输出表名
System.out.println(tableName);
}
} 复制
Calcite解析SQL的流程相比较ANTLR是比较简单的,开发中无需关注词法和语法文件的定义和编写,只需关注具体的业务逻辑实现。比如实现一个SQL的COUNT操作,Calcite实现步骤如下所示。
1.pom依赖
Calcite依赖JAR
<dependencies>
<!-- 这里对Calcite适配依赖进行封装,引入下列包即可 -->
<dependency>
<groupId>org.smartloli</groupId>
<artifactId>jsql-client</artifactId>
<version>1.0.0</version>
</dependency>
</dependencies> 复制
2.实现代码
Calcite示例代码
package com.vivo.learn.sql.calcite;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import org.smartloli.util.JSqlUtils;
public class JSqlClient {
public static void main(String[] args) {
JSONObject tabSchema = new JSONObject();
tabSchema.put("id","integer");
tabSchema.put("name","varchar");
JSONArray datasets = JSON.parseArray("[{\"id\":1,\"name\":\"aaa\",\"age\":20},{\"id\":2,\"name\":\"bbb\",\"age\":21},{\"id\":3,\"name\":\"ccc\",\"age\":22}]");
String tabName = "userinfo";
String sql = "select count(*) as cnt from \"userinfo\"";
try{
String result = JSqlUtils.query(tabSchema,tabName,datasets,sql);
System.out.println("result: "+result);
}catch (Exception e){
e.printStackTrace();
}
}
}复制
3.预览截图

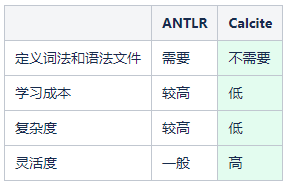
综合对比,我们从对两种技术的学习成本、使用复杂度、以及灵活度来对比,可以优先选择Calcite来作为SQL解析器来处理实际的业务需求。
另外,在单机模式的情况下,执行计划可以较为简单的翻译成执行代码,但是在分布式领域中,因为计算引擎多种多样,因此,还需要一个更加贴近具体计算引擎的描述,也就是物理计划。换言之,逻辑计划只是抽象的一层描述,而物理计划则和具体的计算引擎直接挂钩。
满足上述场景,通常都可以引入SQL解析器:
参考资料: