作者:vivo 互联网数据库团队- Du Ting
在Redis运维过程中,由于Bigkey 的存在,会影响业务程序的响应速度,严重的还会造成可用性损失,DBA也一直和业务开发方强调 Bigkey 的规避方法以及危害。
在Redis运维过程中,由于Bigkey的存在,会影响业务程序的响应速度,严重的还会造成可用性损失,DBA也一直和业务开发方强调 Bigkey 的规避方法以及危害,但是Bigkey一直没有完全避免。全网Redis集群有2200个以上,实例数量达到4.5万以上,在当前阶段进行一次全网 Bigkey检查,估计需要以年为时间单位,非常耗时。我们需要新的思路去解决Bigkey问题。
在Redis中,一个字符串类型最大可以到512MB,一个二级数据结构(比如hash、list、set、zset等)可以存储大约40亿个(2^32-1)个元素,但实际上不会达到这么大的值,一般情况下如果达到下面的情况,就可以认为它是Bigkey了。
我们遇到的Bigkey一般都是由于程序设计不当或者对于数据规模预料不清楚造成的,比如以下的情况。
这三种情况,都是我们实际运维中遇到的,需要谨慎使用,合理优化。
我们在运维中,遇到Bigkey的情况下,会导致一些问题,会触发监控报警,严重的还会影响Redis实例可用性,进而影响业务可用性,在需要水平扩容时候,可能导致水平扩容失败。
内存空间不均匀会不利于集群对内存的统一管理,有数据丢失风险。下图中的三个节点是同属于一个集群,它们的key的数量比较接近,但内存容量相差比较多,存在Bigkey的实例占用的内存多了4G以上了。
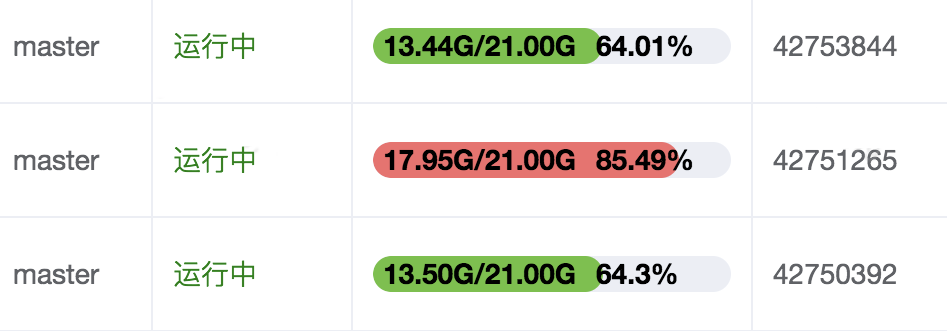
可以使用Daas平台“工具集-操作项管理”,选择对应的slave实例执行分析,找出具体的Bigkey。
Redis是单线程工作的,通俗点讲就是同一时间只能处理一个Redis的访问命令,操作Bigkey的命令通常比较耗时,这段时间Redis不能处理其他命令,其他命令只能阻塞等待,这样会造成客户端阻塞,导致客户端访问超时,更严重的会造成master-slave的故障切换。造成阻塞的操作不仅仅是业务程序的访问,还有key的自动过期的删除、del删除命令,对于Bigkey,这些操作也需要谨慎使用。
超时阻塞案例
我们遇到一个这样超时阻塞的案例,业务方反映程序访问Redis集群出现超时现象,hkeys访问Redis的平均响应时间在200毫秒左右,最大响应时间达到了500毫秒以上,如下图。
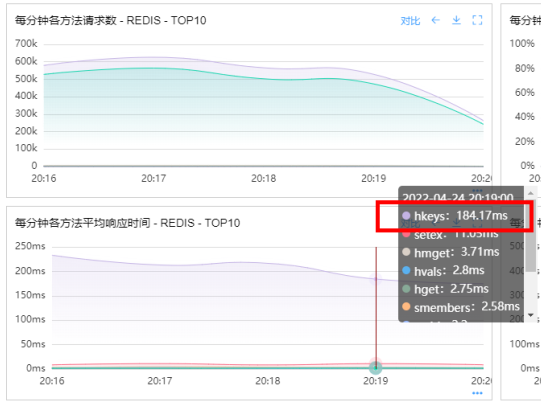
hkeys是获取所有哈希表中的字段的命令,分析应该是集群中某些实例存在hash类型的Bigkey,导致hkeys命令执行时间过长,发生了阻塞现象。
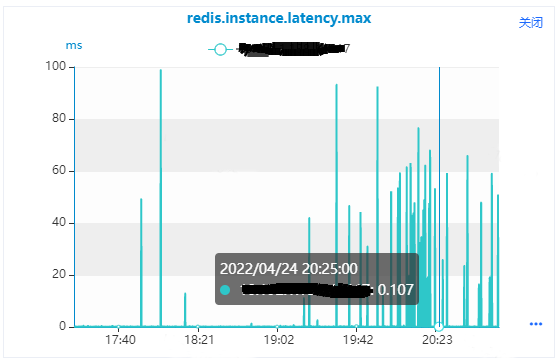
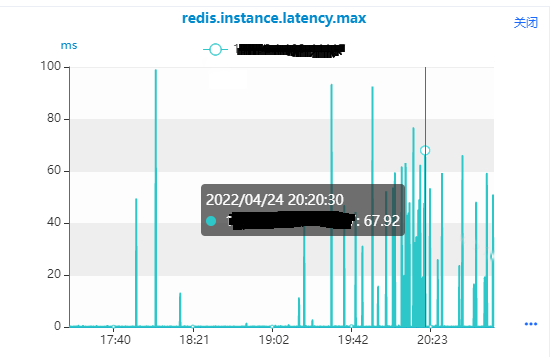
1.使用Daas平台“服务监控-数据库实例监控”,选择master节点,选择Redis响应时间监控指标“redis.instance.latency.max”,如下图所示,从监控图中我们可以看到
(1)正常情况下,该实例的响应时间在0.1毫秒左右。
(2)监控指标上面有很多突刺,该实例的响应时间到了70毫秒左右,最大到了100毫秒左右,这种情况就是该实例会有100毫秒都在处理Bigkey的访问命令,不能处理其他命令。
通过查看监控指标,验证了我们分析是正确的,是这些监控指标的突刺造成了hkeys命令的响应时间比较大,我们找到了具体的master实例,然后使用master实例的slave去分析下Bigkey情况。
2.使用Daas平台“工具集-操作项管理”,选择slave实例执行分析,分析结果如下图,有一个hash类型key有12102218个fields。
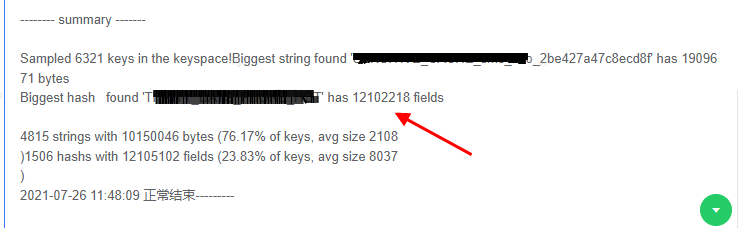
3. 和业务沟通,这个Bigkey是连续存放了30天的业务数据了,建议根据二次hash方式拆分成多个key,也可把30天的数据根据分钟级别拆分成多个key,把每个key的元素数量控制在5000以内,目前业务正在排期优化中。优化后,监控指标的响应时间的突刺就会消失了。
Bigkey的value比较大,也意味着每次获取要产生的网络流量较大,假设一个Bigkey为10MB,客户端每秒访问量为100,那么每秒产生1000MB的流量,对于普通的千兆网卡(按照字节算是128MB/s)的服务器来说简直是灭顶之灾。而且我们现在的Redis服务器是采用单机多实例的方式来部署Redis实例的,也就是说一个Bigkey可能会对同一个服务器上的其他Redis集群实例造成影响,影响到其他的业务。
我们在运维中经常做的变更操作是水平扩容,就是增加Redis集群的节点数量来达到扩容的目的,这个水平扩容操作就会涉及到key的迁移,把原实例上的key迁移到新扩容的实例上。当要对key进行迁移时,是通过migrate命令来完成的,migrate实际上是通过dump + restore + del三个命令组合成原子命令完成,它在执行的时候会阻塞进行迁移的两个实例,直到以下任意结果发生才会释放:迁移成功,迁移失败,等待超时。如果key的迁移过程中遇到Bigkey,会长时间阻塞进行迁移的两个实例,可能造成客户端阻塞,导致客户端访问超时;也可能迁移时间太长,造成迁移超时导致迁移失败,水平扩容失败。
迁移失败案例
我们也遇到过一些因为Bigkey扩容迁移失败的案例,如下图所示,是一个Redis集群水平扩容的工单,需要进行key的迁移,当工单执行到60%的时候,迁移失败了。
1. 进入工单找到失败的实例,使用失败实例的slave节点,在Daas平台的“工具集-操作项管理”进行Bigkey分析。
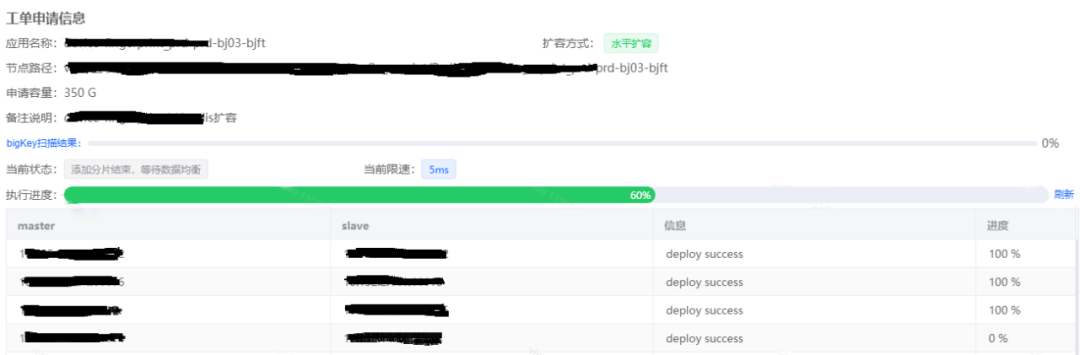
2. 经过分析找出了hash类型的Bigkey有8421874个fields,正是这个Bigkey导致迁移时间太长,超过了迁移时间限制,导致工单失败了。

3.和业务沟通,这些key是记录用户访问系统的某个功能模块的ip地址的,访问该功能模块的所有ip都会记录到给key里面,随着时间的积累,这个key变的越来越大。同样是采用拆分的方式进行优化,可以考虑按照时间日期维度来拆分,就是一段时间段的访问ip记录到一个key中。
4.Bigkey优化后,扩容的工单可以重试,完成集群扩容操作。
Bigkey首先需要重源头治理,防止Bigkey的产生;其次是需要能够及时的发现,发现后及时处理。分析Bigkey的方法不少,这里介绍两种比较常用的方法,也是Daas平台分析Bigkey使用的两种方式,分别是Bigkeys命令分析法、RDB文件分析法。
Redis4.0及以上版本提供了--Bigkeys命令,可以分析出实例中每种数据结构的top 1的Bigkey,同时给出了每种数据类型的键值个数以及平均大小。执行--Bigkeys命令时候需要注意以下几点:
Daas平台集成了基于原生--Bigkeys代码实现的查询Bigkey的方式,这个方式的缺点是只能计算每种数据结构的top1,如果有些数据结构有比较多的Bigkey,是查找不出来的。该方式相对比较安全,已经开放出来给业务开发同学使用。
借助开源的工具,比如rdb-tools,分析Redis实例的RDB文件,找出其中的Bigkey,这种方式需要生成RDB文件,需要注意以下几点:
Daas平台集成了基于RDB文件分析代码实现的查询Bigkey的方式,可以根据实际需求自定义填写N,分析的top N个Bigkey。该方式相对有一定风险,只有DBA有权限执行分析。
通过巡检,可以暴露出隐患,提前解决,避免故障的发生,进行全网Bigkey的巡检,是避免Bigkey故障的比较好的方法。由于全网Redis实例数量非常大,分析的速度比较慢,使用当前的分析方法很难完成。为了解决这个问题,存储研发组分布式数据库同学计划开发一个高效的RDB解析工具,然后通过大规模解析RDB文件来分析Bigkey,可以提高分析速度,实现Bigkey的巡检。
优化Bigkey的原则就是string减少字符串长度,list、hash、set、zset等减少元素数量。当我们知道哪些key是Bigkey时,可以把单个key拆分成多个key,比如以下拆分方式可以参考。
我们全网Redis集群有2200以上,实例数量达到4.5万以上,有的比较大的集群的实例数量达到了1000以上,前面提到的两种Bigkey分析工具还都是实例维度分析,对于实例数量比较大的集群,进行全集群分析也是比较耗时的,为了提高分析效率,从以下几个方面进行优化:
目前情况,我们有一些Bigkey的发现是被动的,一些是在水平扩容时候发现的,由于Bigkey的存在导致扩容失败了,严重的还触发了master-slave的故障切换,这个时候可能已经造成业务程序访问超时,导致了可用性下降。
我们分析了Daas平台的水平扩容时迁移key的过程及影响参数,内容如下:
(1)【cluster-node-timeout】:控制集群的节点切换参数,master堵塞超过cluster-node-timeout/2这个时间,就会主观判定该节点下线pfail状态,如果迁移Bigkey阻塞时间超过cluster-node-timeout/2,就可能会导致master-slave发生切换。
(2)【migrate timeout】:控制迁移io的超时时间,超过这个时间迁移没有完成,迁移就会中断。
(3)【迁移重试周期】:迁移的重试周期是由水平扩容的节点数决定的,比如一个集群扩容10个节点,迁移失败后的重试周期就是10次。
(4)【一个迁移重试周期内的重试次数】:在一个起迁移重试周期内,会有3次重试迁移,每一次的migrate timeout的时间分别是10秒、20秒、30秒,每次重试之间无间隔。
比如一个集群扩容10个节点,迁移时候遇到一个Bigkey,第一次迁移的migrate timeout是10秒,10秒后没有完成迁移,就会设置migrate timeout为20秒重试,如果再次失败,会设置migrate timeout为30秒重试,如果还是失败,程序会迁移其他新9个的节点,但是每次在迁移其他新的节点之前还会分别设置migrate timeout为10秒、20秒、30秒重试迁移那个迁移失败的Bigkey。这个重试过程,每个重试周期阻塞(10+20+30)秒,会重试10个周期,共阻塞600秒。其实后面的9个重试周期都是无用的,每次重试之间没有间隔,会连续阻塞了Redis实例。
(5)【迁移失败日志】:迁移失败后,记录的日志没有包括迁移节点、solt、key信息,不能根据日志立即定位到问题key。
我们对这个迁移过程做了优化,具体如下:
(1)【cluster-node-timeout】:默认是60秒,在迁移之前设置为15分钟,防止由于迁移Bigkey阻塞导致master-slave故障切换。
(2)【migrate timeout】:为了最大限度减少实例阻塞时间,每次重试的超时时间都是10秒,3次重试之间间隔30秒,这样最多只会连续阻塞Redis实例10秒。
(3)【重试次数】:迁移失败后,只重试3次(重试是为了避免网络抖动等原因造成的迁移失败),每次重试间隔30秒,重试3次后都失败了,会暂停迁移,日志记录下Bigkey,去掉了其他节点迁移的重试。
(4)【优化日志记录】:迁移失败日志记录迁移节点、solt、key信息,可以立即定位到问题节点及key。
本文通过对Bigkey的分析,重点介绍了在运维中对bigkey问题的处理思路、解决方式。首先是需要从源头治理,防止Bigkey形成,DBA应该加强对业务开发同学bigkey相关问题的宣导;其次是需要具备及时发现的能力,这个也是我们现在的不足之处。我们后面会从Bigkey巡检、Bigkey分析工具的这两个方面,提高Bigkey发现能力。
参考资料: